 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Soft Actor-Critic: Off-Policy Reinforcement Learning for Addressing Value Estimation Errors
Paper and Code
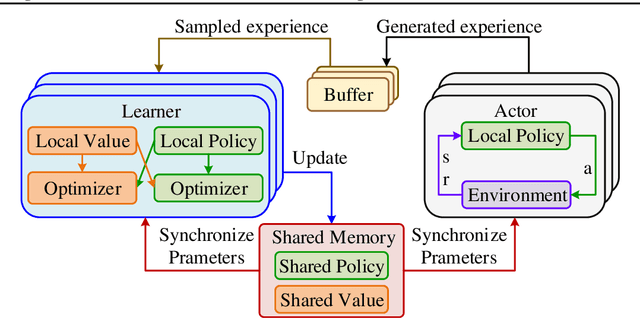

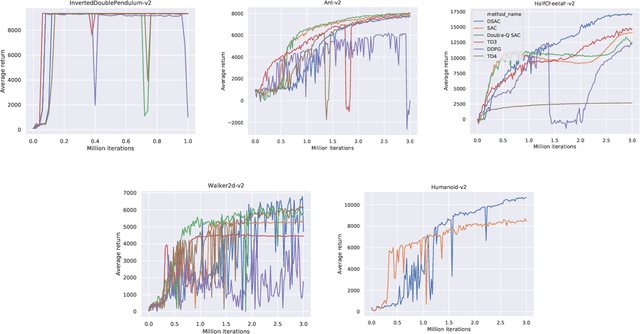

In current reinforcement learning (RL) methods, function approximation errors are known to lead to the overestimated or underestimated Q-value estimates, thus resulting in suboptimal policies. We show that the learning of a state-action return distribution function can be used to improve the Q-value estimation accuracy. We employ the return distribution function within the maximum entropy RL framework in order to develop what we call the Distributional Soft Actor-Critic (DSAC) algorithm, which is an off-policy method for continuous control setting. Unlike traditional distributional RL algorithms which typically only learn a discrete return distribution, DSAC directly learns a continuous return distribution by truncating the difference between the target and current distribution to prevent gradient explosion. Additionally, we propose a new Parallel Asynchronous Buffer-Actor-Learner architecture (PABAL) to improve the learning efficiency, which is a generalization of current high-throughput learning architectures. We evaluate our method on the suite of MuJoCo continuous control tasks, achieving state-of-the-art performance.