 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarthVQA: Towards Queryable Earth via Relational Reasoning-Based Remote Sensing Visual Question Answering
Dec 19, 2023



Earth vision research typically focuses on extracting geospatial object locations and categories but neglects the exploration of relations between objects and comprehensive reasoning. Based on city planning needs, we develop a multi-modal multi-task VQA dataset (EarthVQA) to advance relational reasoning-based judging, counting, and comprehensive analysis. The EarthVQA dataset contains 6000 images, corresponding semantic masks, and 208,593 QA pairs with urban and rural governance requirements embedded. As objects are the basis for complex relational reasoning, we propose a Semantic OBject Awareness framework (SOBA) to advance VQA in an object-centric way. To preserve refined spatial locations and semantics, SOBA leverages a segmentation network for object semantics generation. The object-guided attention aggregates object interior features via pseudo masks, and bidirectional cross-attention further models object external relations hierarchically. To optimize object counting, we propose a numerical difference loss that dynamically adds difference penalties, unifying the classification and regression tasks. Experimental results show that SOBA outperforms both advanced general and remote sensing methods. We believe this dataset and framework provide a strong benchmark for Earth vision's complex analysis. The project page is at https://Junjue-Wang.github.io/homepage/EarthVQA.
A Unified Remote Sensing Anomaly Detector Across Modalities and Scenes via Deviation Relationship Learning
Oct 11, 2023



Remote sensing anomaly detector can find the objects deviating from the background as potential targets. Given the diversity in earth anomaly types, a unified anomaly detector across modalities and scenes should be cost-effective and flexible to new earth observation sources and anomaly types. However, the current anomaly detectors are limited to a single modality and single scene, since they aim to learn the varying background distribution. Motivated by the universal anomaly deviation pattern, in that anomalies exhibit deviations from their local context, we exploit this characteristic to build a unified anomaly detector. Firstly, we reformulate the anomaly detection task as an undirected bilayer graph based on the deviation relationship, where the anomaly score is modeled as the conditional probability, given the pattern of the background and normal objects. The learning objective is then expressed as a conditional probability ranking problem. Furthermore, we design an instantiation of the reformulation in the data, architecture, and optimization aspects. Simulated spectral and spatial anomalies drive the instantiated architecture. The model is optimized directly for the conditional probability ranking. The proposed model was validated in five modalities including the hyperspectral, visible light, synthetic aperture radar (SAR), infrared and low light to show its unified detection ability.
Scalable Multi-Temporal Remote Sensing Change Data Generation via Simulating Stochastic Change Process
Sep 29, 2023Understanding the temporal dynamics of Earth's surface is a mission of multi-temporal remote sensing image analysis, significantly promoted by deep vision models with its fuel -- labeled multi-temporal images. However, collecting, preprocessing, and annotating multi-temporal remote sensing images at scale is non-trivial since it is expensive and knowledge-intensive. In this paper, we present a scalable multi-temporal remote sensing change data generator via generative modeling, which is cheap and automatic, alleviating these problems. Our main idea is to simulate a stochastic change process over time. We consider the stochastic change process as a probabilistic semantic state transition, namely generative probabilistic change model (GPCM), which decouples the complex simulation problem into two more trackable sub-problems, \ie, change event simulation and semantic change synthesis. To solve these two problems, we present the change generator (Changen), a GAN-based GPCM, enabling controllable object change data generation, including customizable object property, and change event. The extensive experiments suggest that our Changen has superior generation capability, and the change detectors with Changen pre-training exhibit excellent transferability to real-world change datasets.
Seeing Beyond the Patch: Scale-Adaptive Semantic Segmentation of High-resolution Remote Sensing Imagery based on Reinforcement Learning
Sep 27, 2023



In remote sensing imagery analysis, patch-based methods have limitations in capturing information beyond the sliding window. This shortcoming poses a significant challenge in processing complex and variable geo-objects, which results in semantic inconsistency in segmentation results. To address this challenge, we propose a dynamic scale perception framework, named GeoAgent, which adaptively captures appropriate scale context information outside the image patch based on the different geo-objects. In GeoAgent, each image patch's states are represented by a global thumbnail and a location mask. The global thumbnail provides context beyond the patch, and the location mask guides the perceived spatial relationships. The scale-selection actions are performed through a Scale Control Agent (SCA). A feature indexing module is proposed to enhance the ability of the agent to distinguish the current image patch's location. The action switches the patch scale and context branch of a dual-branch segmentation network that extracts and fuses the features of multi-scale patches. The GeoAgent adjusts the network parameters to perform the appropriate scale-selection action based on the reward received for the selected scale. The experimental results, using two publicly available datasets and our newly constructed dataset WUSU, demonstrate that GeoAgent outperforms previous segmentation methods, particularly for large-scale mapping applications.
Class Prior-Free Positive-Unlabeled Learning with Taylor Variational Loss for Hyperspectral Remote Sensing Imagery
Aug 29, 2023



Positive-unlabeled learning (PU learning) in hyperspectral remote sensing imagery (HSI) is aimed at learning a binary classifier from positive and unlabeled data, which has broad prospects in various earth vision applications. However, when PU learning meets limited labeled HSI, the unlabeled data may dominate the optimization process, which makes the neural networks overfit the unlabeled data. In this paper, a Taylor variational loss is proposed for HSI PU learning, which reduces the weight of the gradient of the unlabeled data by Taylor series expansion to enable the network to find a balance between overfitting and underfitting. In addition, the self-calibrated optimization strategy is designed to stabilize the training process. Experiments on 7 benchmark datasets (21 tasks in total) validate the effectiveness of the proposed method. Code is at: https://github.com/Hengwei-Zhao96/T-HOneCls.
One-Step Detection Paradigm for Hyperspectral Anomaly Detection via Spectral Deviation Relationship Learning
Mar 22, 2023



Hyperspectral anomaly detection (HAD) involves identifying the targets that deviate spectrally from their surroundings, without prior knowledge. Recently, deep learning based methods have become the mainstream HAD methods, due to their powerful spatial-spectral feature extraction ability. However, the current deep detection models are optimized to complete a proxy task (two-step paradigm), such as background reconstruction or generation, rather than achieving anomaly detection directly. This leads to suboptimal results and poor transferability, which means that the deep model is trained and tested on the same image. In this paper, an unsupervised transferred direct detection (TDD) model is proposed, which is optimized directly for the anomaly detection task (one-step paradigm) and has transferability. Specially, the TDD model is optimized to identify the spectral deviation relationship according to the anomaly definition. Compared to learning the specific background distribution as most models do, the spectral deviation relationship is universal for different images and guarantees the model transferability. To train the TDD model in an unsupervised manner, an anomaly sample simulation strategy is proposed to generate numerous pairs of anomaly samples. Furthermore, a global self-attention module and a local self-attention module are designed to help the model focus on the "spectrally deviating" relationship. The TDD model was validated on four public HAD datasets. The results show that the proposed TDD model can successfully overcome the limitation of traditional model training and testing on a single image, and the model has a powerful detection ability and excellent transferability.
Anomaly Segmentation for High-Resolution Remote Sensing Images Based on Pixel Descriptors
Jan 31, 2023



Anomaly segmentation in high spatial resolution (HSR) remote sensing imagery is aimed at segmenting anomaly patterns of the earth deviating from normal patterns, which plays an important role in various Earth vision applications. However, it is a challenging task due to the complex distribution and the irregular shapes of objects, and the lack of abnormal samples. To tackle these problems, an anomaly segmentation model based on pixel descriptors (ASD) is proposed for anomaly segmentation in HSR imagery. Specifically, deep one-class classification is introduced for anomaly segmentation in the feature space with discriminative pixel descriptors. The ASD model incorporates the data argument for generating virtual ab-normal samples, which can force the pixel descriptors to be compact for normal data and meanwhile to be diverse to avoid the model collapse problems when only positive samples participated in the training. In addition, the ASD introduced a multi-level and multi-scale feature extraction strategy for learning the low-level and semantic information to make the pixel descriptors feature-rich. The proposed ASD model was validated using four HSR datasets and compared with the recent state-of-the-art models, showing its potential value in Earth vision applications.
Learning One-Class Hyperspectral Classifier from Positive and Unlabeled Data for Low Proportion Target
Oct 27, 2022



Hyperspectral imagery (HSI) one-class classification is aimed at identifying a single target class from the HSI by using only positive labels, which can significantly reduce the requirements for annotation. However, HSI one-class classification is far more challenging than HSI multi-class classification, due the lack of negative labels and the low target proportion, which are issues that have rarely been considered in the previous HSI classification studies. In this paper, a weakly supervised HSI one-class classifier, namely HOneCls is proposed to solve the problem of under-fitting of the positive class occurs in the HSI data with low target proportion, where a risk estimator -- the One-Class Risk Estimator -- is particularly introduced to make the full convolutional neural network (FCN) with the ability of one class classification. The experimental results obtained on challenging hyperspectral classification datasets, which includes 20 kinds of ground objects with very similar spectra, demonstrate the efficiency and feasibility of the proposed One-Class Risk Estimator. Compared with the state-of-the-art one-class classifiers, the F1-score is improved significantly in the HSI data with low target proportion.
The Outcome of the 2022 Landslide4Sense Competition: Advanced Landslide Detection from Multi-Source Satellite Imagery
Sep 12, 2022
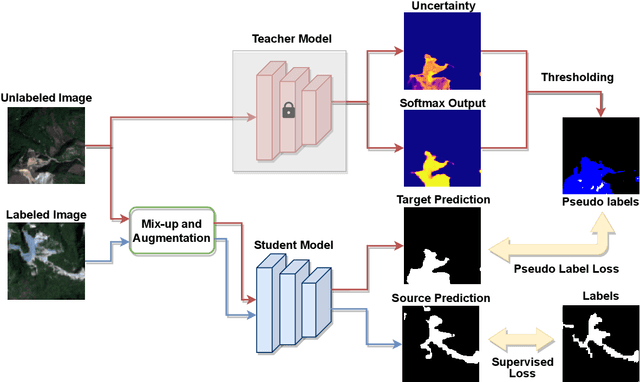
The scientific outcomes of the 2022 Landslide4Sense (L4S) competition organized by the Institute of Advanced Research in Artificial Intelligence (IARAI) are presented here. The objective of the competition is to automatically detect landslides based on large-scale multiple sources of satellite imagery collected globally. The 2022 L4S aims to foster interdisciplinary research on recent developments in deep learning (DL) models for the semantic segmentation task using satellite imagery. In the past few years, DL-based models have achieved performance that meets expectations on image interpretation, due to the development of convolutional neural networks (CNNs). The main objective of this article is to present the details and the best-performing algorithms featured in this competition. The winning solutions are elaborated with state-of-the-art models like the Swin Transformer, SegFormer, and U-Net. Advanced machine learning techniques and strategies such as hard example mining, self-training, and mix-up data augmentation are also considered. Moreover, we describe the L4S benchmark data set in order to facilitate further comparisons, and report the results of the accuracy assessment online. The data is accessible on \textit{Future Development Leaderboard} for future evaluation at \url{https://www.iarai.ac.at/landslide4sense/challenge/}, and researchers are invited to submit more prediction results, evaluate the accuracy of their methods, compare them with those of other users, and, ideally, improve the landslide detection results reported in this article.
AutoLC: Search Lightweight and Top-Performing Architecture for Remote Sensing Image Land-Cover Classification
May 11, 2022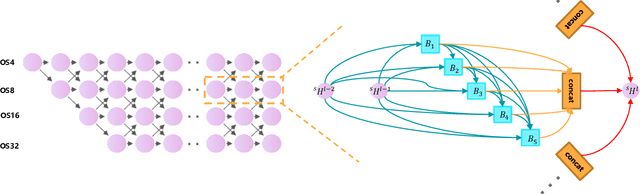
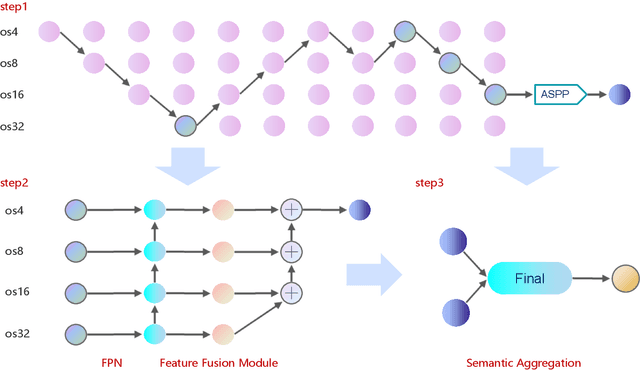
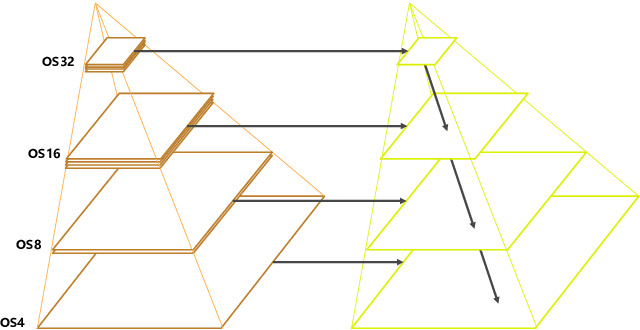

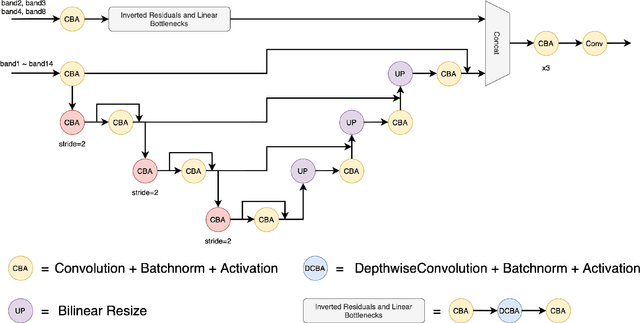
Land-cover classification has long been a hot and difficult challenge in remote sensing community. With massive High-resolution Remote Sensing (HRS) images available, manually and automatically designed Convolutional Neural Networks (CNNs) have already shown their great latent capacity on HRS land-cover classification in recent years. Especially, the former can achieve better performance while the latter is able to generate lightweight architecture. Unfortunately, they both have shortcomings. On the one hand, because manual CNNs are almost proposed for natural image processing, it becomes very redundant and inefficient to process HRS images. On the other hand, nascent Neural Architecture Search (NAS) techniques for dense prediction tasks are mainly based on encoder-decoder architecture, and just focus on the automatic design of the encoder, which makes it still difficult to recover the refined mapping when confronting complicated HRS scenes. To overcome their defects and tackle the HRS land-cover classification problems better, we propose AutoLC which combines the advantages of two methods. First, we devise a hierarchical search space and gain the lightweight encoder underlying gradient-based search strategy. Second, we meticulously design a lightweight but top-performing decoder that is adaptive to the searched encoder of itself. Finally, experimental results on the LoveDA land-cover dataset demonstrate that our AutoLC method outperforms the state-of-art manual and automatic methods with much less computational consumption.