 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundObj: Self-supervised Foundation Models as Rewards for Label-free 3D Object Segmentation
May 26, 2026We address the challenging task of 3D object segmentation in complex scene point clouds without relying on any scene-level human annotations during training. Existing methods are typically constrained to identifying simple objects, primarily due to insufficient object priors in the learning process. In this paper, we present FoundObj, a novel framework featuring a superpoint-based object discovery agent that incrementally merges suitable neighboring superpoints, guided by our innovative semantic and geometric reward modules. These modules synergistically leverage semantic and geometric priors from self-supervised 2D/3D foundation models, providing complementary feedback to the object discovery agent and enabling robust identification of multi-class objects through reinforcement learning. Extensive experiments on diverse benchmarks demonstrate that our approach consistently outperforms existing baselines. Notably, our method exhibits strong generalization in zero-shot and long-tail scenarios, underscoring its potential for scalable, label-free 3D object segmentation.
EvObj: Learning Evolving Object-centric Representations for 3D Instance Segmentation without Scene Supervision
May 13, 2026We introduce EvObj for unsupervised 3D instance segmentation that bridges the geometric domain gap between synthetic pretraining data and real-world point clouds. Current methods suffer from structural discrepancies when transferring object priors from synthetic datasets (e.g., ShapeNet) to real scans (e.g., ScanNet), particularly due to morphological variations and occlusion artifacts. To address this, EvObj integrates two innovative modules: (1) An object discerning module that dynamically refines object candidates, enabling continuous adaptation of object priors to target domains; and (2) An object completion module that reconstructs partial geometries after discovering objects. We conduct extensive experiments on both real-world and synthetic datasets, demonstrating superior 3D object segmentation performance over all baselines while achieving state-of-the-art results.
MARGIN: Margin-Aware Regularized Geometry for Imbalanced Vulnerability Detection
May 11, 2026Software vulnerability detection is critical for ensuring software security and reliability. Despite recent advances in deep learning, real-world vulnerability datasets suffer from two severe challenges: frequency imbalance and difficulty imbalance. We reinterpret these challenges from an embedding geometry perspective, observing that such imbalances induce geometric distortions in hyperspherical representation space. To address this issue, we propose MARGIN, a metric-based framework that learns discriminative vulnerability representations through adaptive margin metric learning and hyperspherical prototype modeling. MARGIN dynamically adjusts geometric regularization according to the distribution structure estimated by the von Mises-Fisher concentration, aligning the probability mass of embedding distributions with their corresponding Voronoi cells, thereby reducing geometric distortion and yielding more stable decision boundaries. Extensive experiments on public vulnerability datasets show that MARGIN consistently outperforms strong baselines, achieving notable improvements in classification and detection, especially on challenging, imbalanced datasets. Further analysis demonstrates that MARGIN produces more structured embedding geometries, improving robustness, interpretability, and generalization.
PhysInOne: Visual Physics Learning and Reasoning in One Suite
Apr 10, 2026We present PhysInOne, a large-scale synthetic dataset addressing the critical scarcity of physically-grounded training data for AI systems. Unlike existing datasets limited to merely hundreds or thousands of examples, PhysInOne provides 2 million videos across 153,810 dynamic 3D scenes, covering 71 basic physical phenomena in mechanics, optics, fluid dynamics, and magnetism. Distinct from previous works, our scenes feature multiobject interactions against complex backgrounds, with comprehensive ground-truth annotations including 3D geometry, semantics, dynamic motion, physical properties, and text descriptions. We demonstrate PhysInOne's efficacy across four emerging applications: physics-aware video generation, long-/short-term future frame prediction, physical property estimation, and motion transfer. Experiments show that fine-tuning foundation models on PhysInOne significantly enhances physical plausibility, while also exposing critical gaps in modeling complex physical dynamics and estimating intrinsic properties. As the largest dataset of its kind, orders of magnitude beyond prior works, PhysInOne establishes a new benchmark for advancing physics-grounded world models in generation, simulation, and embodied AI.
GrabS: Generative Embodied Agent for 3D Object Segmentation without Scene Supervision
Apr 16, 2025



We study the hard problem of 3D object segmentation in complex point clouds without requiring human labels of 3D scenes for supervision. By relying on the similarity of pretrained 2D features or external signals such as motion to group 3D points as objects, existing unsupervised methods are usually limited to identifying simple objects like cars or their segmented objects are often inferior due to the lack of objectness in pretrained features. In this paper, we propose a new two-stage pipeline called GrabS. The core concept of our method is to learn generative and discriminative object-centric priors as a foundation from object datasets in the first stage, and then design an embodied agent to learn to discover multiple objects by querying against the pretrained generative priors in the second stage. We extensively evaluate our method on two real-world datasets and a newly created synthetic dataset, demonstrating remarkable segmentation performance, clearly surpassing all existing unsupervised methods.
Benchmarking and Analysis of Unsupervised Object Segmentation from Real-world Single Images
Dec 08, 2023In this paper, we study the problem of unsupervised object segmentation from single images. We do not introduce a new algorithm, but systematically investigate the effectiveness of existing unsupervised models on challenging real-world images. We first introduce seven complexity factors to quantitatively measure the distributions of background and foreground object biases in appearance and geometry for datasets with human annotations. With the aid of these factors, we empirically find that, not surprisingly, existing unsupervised models fail to segment generic objects in real-world images, although they can easily achieve excellent performance on numerous simple synthetic datasets, due to the vast gap in objectness biases between synthetic and real images. By conducting extensive experiments on multiple groups of ablated real-world datasets, we ultimately find that the key factors underlying the failure of existing unsupervised models on real-world images are the challenging distributions of background and foreground object biases in appearance and geometry. Because of this, the inductive biases introduced in existing unsupervised models can hardly capture the diverse object distributions. Our research results suggest that future work should exploit more explicit objectness biases in the network design.
Promising or Elusive? Unsupervised Object Segmentation from Real-world Single Images
Oct 05, 2022
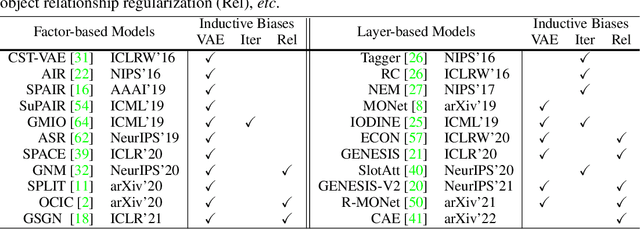


In this paper, we study the problem of unsupervised object segmentation from single images. We do not introduce a new algorithm, but systematically investigate the effectiveness of existing unsupervised models on challenging real-world images. We firstly introduce four complexity factors to quantitatively measure the distributions of object- and scene-level biases in appearance and geometry for datasets with human annotations. With the aid of these factors, we empirically find that, not surprisingly, existing unsupervised models catastrophically fail to segment generic objects in real-world images, although they can easily achieve excellent performance on numerous simple synthetic datasets, due to the vast gap in objectness biases between synthetic and real images. By conducting extensive experiments on multiple groups of ablated real-world datasets, we ultimately find that the key factors underlying the colossal failure of existing unsupervised models on real-world images are the challenging distributions of object- and scene-level biases in appearance and geometry. Because of this, the inductive biases introduced in existing unsupervised models can hardly capture the diverse object distributions. Our research results suggest that future work should exploit more explicit objectness biases in the network design.