 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstant-Modulus Waveform Design for Dual-Function Radar-Communication Systems in the Presence of Clutter
Feb 28, 2023



We investigate the constant-modulus (CM) waveform design for dual-function radar communication systems in the presence of clutter.To minimize the interference power and enhance the target acquisition performance, we use the signal-to-interference-plus-noise-ratio as the design metric.In addition, to ensure the quality of the service for each communication user, we enforce a constraint on the synthesis error of every communication signals.An iterative algorithm, which is based on cyclic optimization, Dinkinbach's transform, and alternating direction of method of multipliers, is proposed to tackle the encountered non-convex optimization problem.Simulations illustrate that the CM waveforms synthesized by the proposed algorithm allow to suppress the clutter efficiently and control the synthesis error of communication signals to a low level.
A Probabilistic Model-Based Robust Waveform Design for MIMO Radar Detection
Apr 09, 2022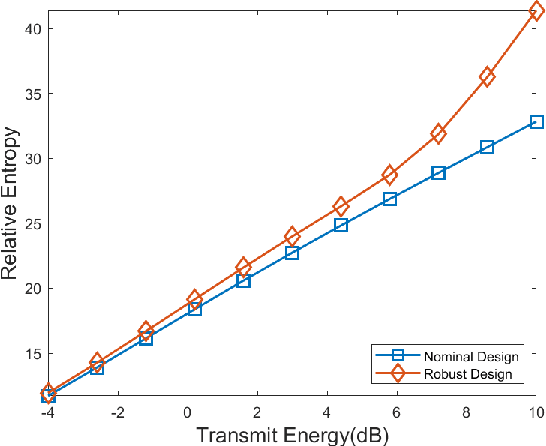
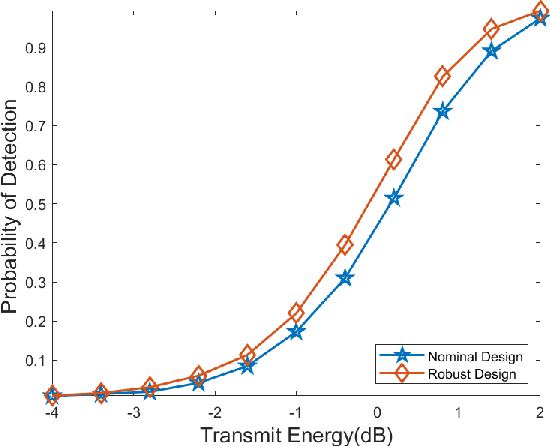
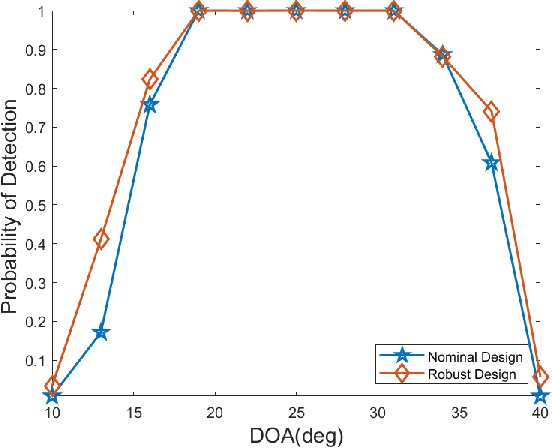
This paper addresses robust waveform design for multiple-input-multiple-output (MIMO) radar detection. A probabilistic model is proposed to describe the target uncertainty. Considering that waveform design based on maximizing the probability of detection is intractable, the relative entropy between the distributions of the observations under two hypotheses (viz., the target is present/absent) is employed as the design metric. To tackle the resulting non-convex optimization problem, an efficient algorithm based on minorization-maximization (MM) is derived. Numerical results demonstrate that the waveform synthesized by the proposed algorithm is more robust to model mismatches.
BinsFormer: Revisiting Adaptive Bins for Monocular Depth Estimation
Apr 03, 2022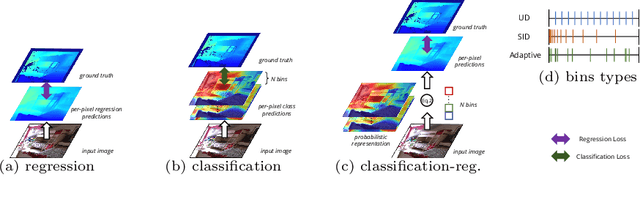
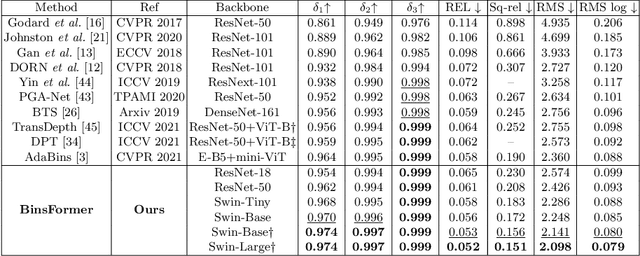
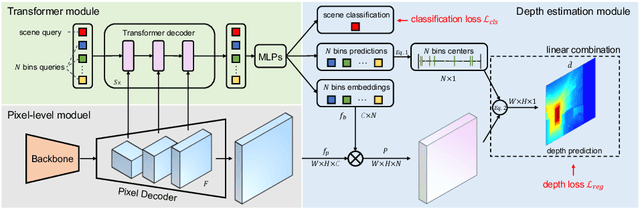
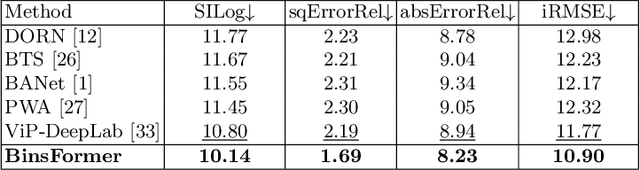
Monocular depth estimation is a fundamental task in computer vision and has drawn increasing attention. Recently, some methods reformulate it as a classification-regression task to boost the model performance, where continuous depth is estimated via a linear combination of predicted probability distributions and discrete bins. In this paper, we present a novel framework called BinsFormer, tailored for the classification-regression-based depth estimation. It mainly focuses on two crucial components in the specific task: 1) proper generation of adaptive bins and 2) sufficient interaction between probability distribution and bins predictions. To specify, we employ the Transformer decoder to generate bins, novelly viewing it as a direct set-to-set prediction problem. We further integrate a multi-scale decoder structure to achieve a comprehensive understanding of spatial geometry information and estimate depth maps in a coarse-to-fine manner. Moreover, an extra scene understanding query is proposed to improve the estimation accuracy, which turns out that models can implicitly learn useful information from an auxiliary environment classification task. Extensive experiments on the KITTI, NYU, and SUN RGB-D datasets demonstrate that BinsFormer surpasses state-of-the-art monocular depth estimation methods with prominent margins. Code and pretrained models will be made publicly available at \url{https://github.com/zhyever/Monocular-Depth-Estimation-Toolbox}.
Generating Adversarial Samples For Training Wake-up Word Detection Systems Against Confusing Words
Jan 01, 2022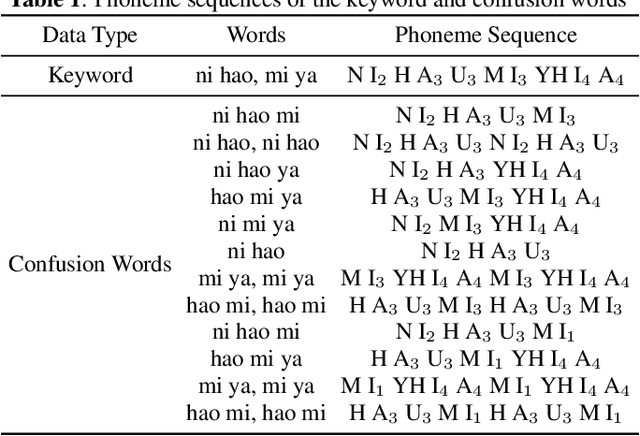
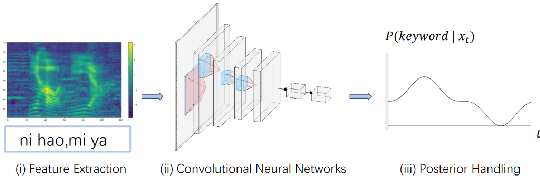
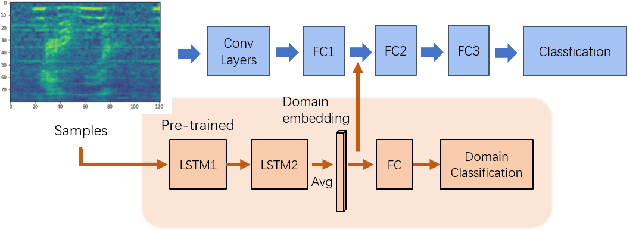
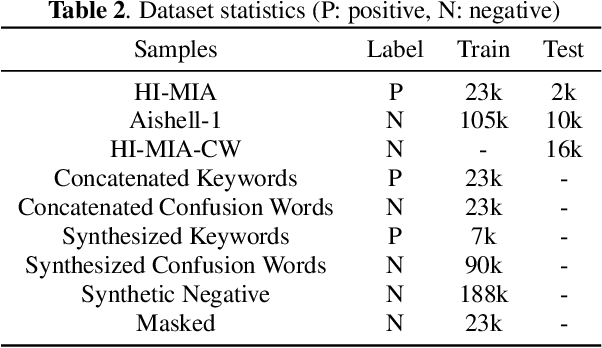
Wake-up word detection models are widely used in real life, but suffer from severe performance degradation when encountering adversarial samples. In this paper we discuss the concept of confusing words in adversarial samples. Confusing words are commonly encountered, which are various kinds of words that sound similar to the predefined keywords. To enhance the wake word detection system's robustness against confusing words, we propose several methods to generate the adversarial confusing samples for simulating real confusing words scenarios in which we usually do not have any real confusing samples in the training set. The generated samples include concatenated audio, synthesized data, and partially masked keywords. Moreover, we use a domain embedding concatenated system to improve the performance. Experimental results show that the adversarial samples generated in our approach help improve the system's robustness in both the common scenario and the confusing words scenario. In addition, we release the confusing words testing database called HI-MIA-CW for future research.
Online Speaker Diarization with Graph-based Label Generation
Nov 27, 2021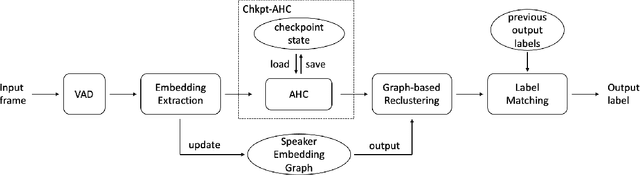


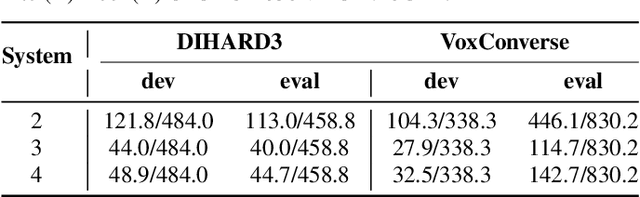
This paper introduces an online speaker diarization system that can handle long-time audio with low latency. First, a new variant of agglomerative hierarchy clustering is built to cluster the speakers in an online fashion. Then, a speaker embedding graph is proposed. We use this graph to exploit a graph-based reclustering method to further improve the performance. Finally, a label matching algorithm is introduced to generate consistent speaker labels, and we evaluate our system on both DIHARD3 and VoxConverse datasets, which contain long audios with various kinds of scenarios. The experimental results show that our online diarization system outperforms the baseline offline system and has comparable performance to our offline system.
Towards Lightweight Applications: Asymmetric Enroll-Verify Structure for Speaker Verification
Oct 09, 2021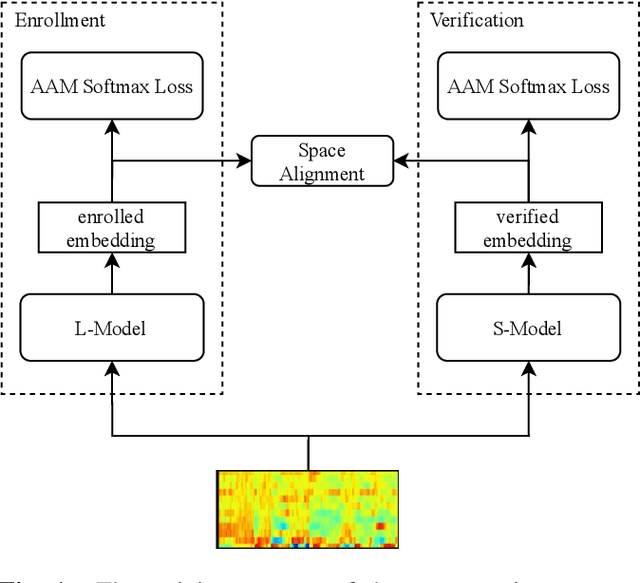
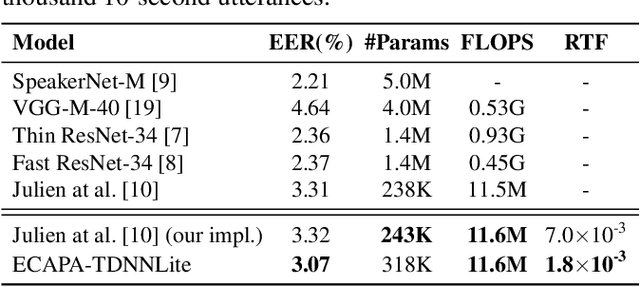
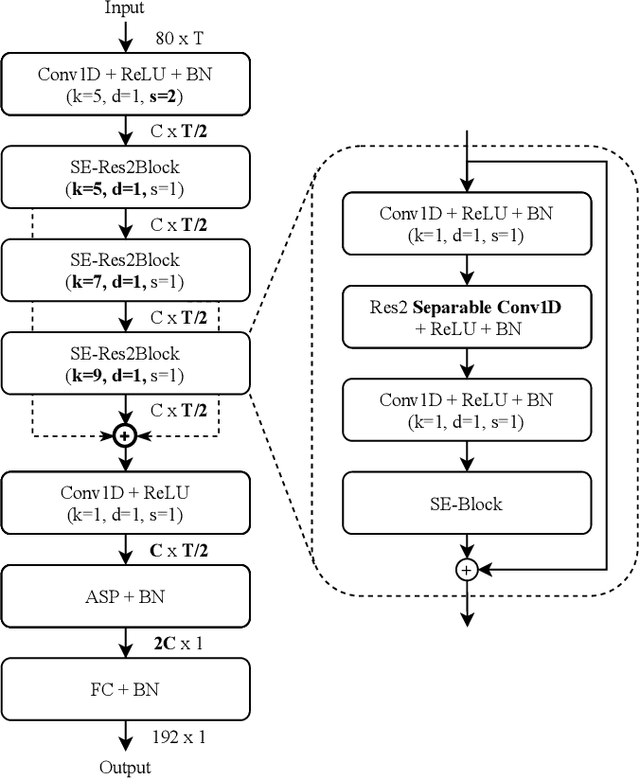

With the development of deep learning, automatic speaker verification has made considerable progress over the past few years. However, to design a lightweight and robust system with limited computational resources is still a challenging problem. Traditionally, a speaker verification system is symmetrical, indicating that the same embedding extraction model is applied for both enrollment and verification in inference. In this paper, we come up with an innovative asymmetric structure, which takes the large-scale ECAPA-TDNN model for enrollment and the small-scale ECAPA-TDNNLite model for verification. As a symmetrical system, our proposed ECAPA-TDNNLite model achieves an EER of 3.07% on the Voxceleb1 original test set with only 11.6M FLOPS. Moreover, the asymmetric structure further reduces the EER to 2.31%, without increasing any computational costs during verification.
Sparsely Overlapped Speech Training in the Time Domain: Joint Learning of Target Speech Separation and Personal VAD Benefits
Jun 28, 2021
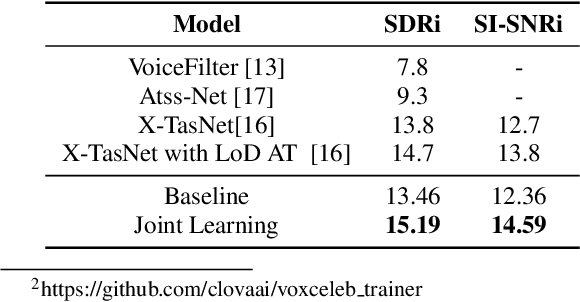
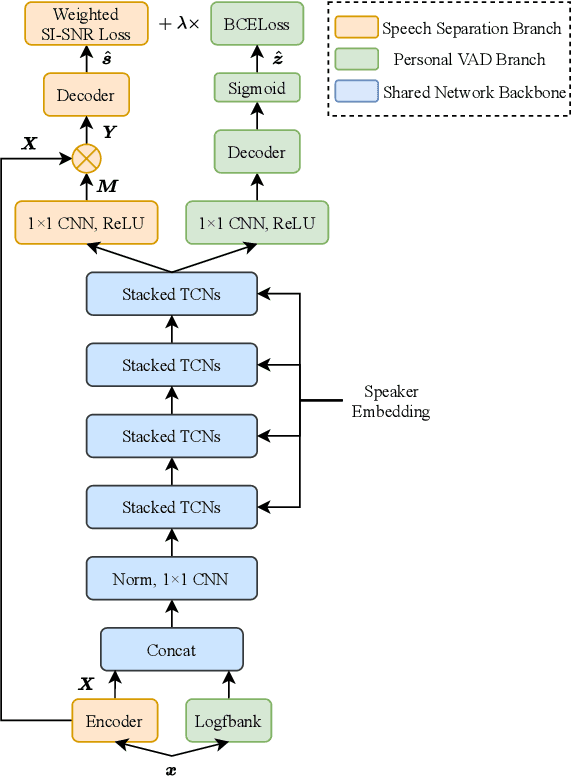
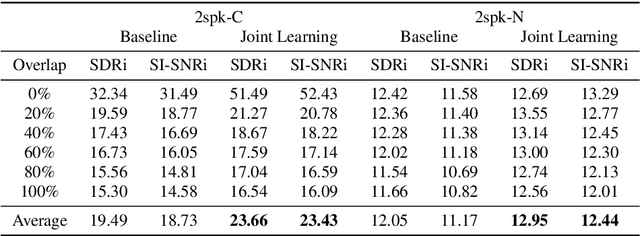
Target speech separation is the process of filtering a certain speaker's voice out of speech mixtures according to the additional speaker identity information provided. Recent works have made considerable improvement by processing signals in the time domain directly. The majority of them take fully overlapped speech mixtures for training. However, since most real-life conversations occur randomly and are sparsely overlapped, we argue that training with different overlap ratio data benefits. To do so, an unavoidable problem is that the popularly used SI-SNR loss has no definition for silent sources. This paper proposes the weighted SI-SNR loss, together with the joint learning of target speech separation and personal VAD. The weighted SI-SNR loss imposes a weight factor that is proportional to the target speaker's duration and returns zero when the target speaker is absent. Meanwhile, the personal VAD generates masks and sets non-target speech to silence. Experiments show that our proposed method outperforms the baseline by 1.73 dB in terms of SDR on fully overlapped speech, as well as by 4.17 dB and 0.9 dB on sparsely overlapped speech of clean and noisy conditions. Besides, with slight degradation in performance, our model could reduce the time costs in inference.
TransfoRNN: Capturing the Sequential Information in Self-Attention Representations for Language Modeling
Apr 04, 2021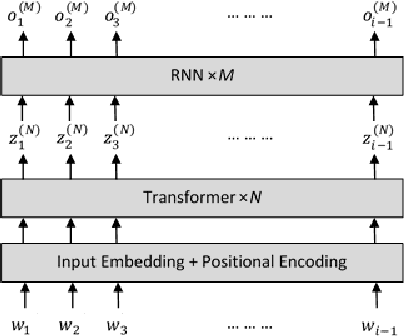
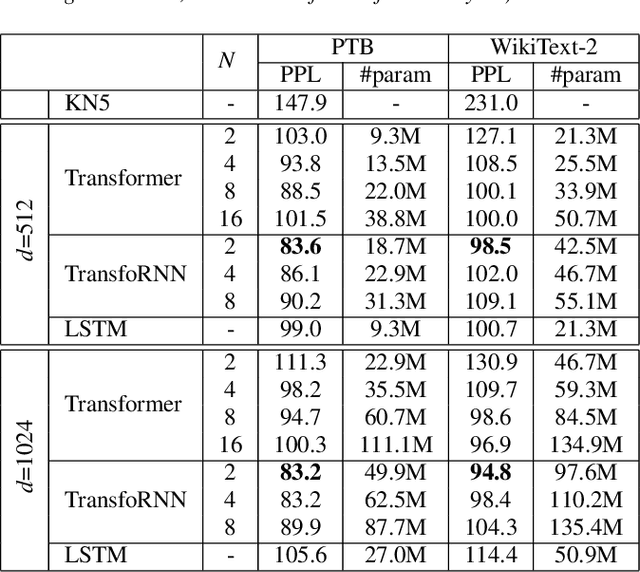
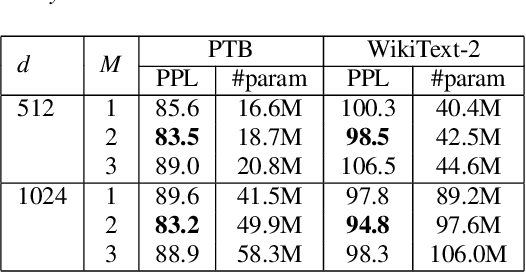
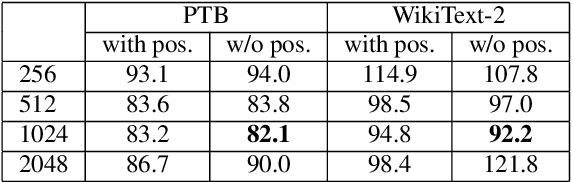
In this paper, we describe the use of recurrent neural networks to capture sequential information from the self-attention representations to improve the Transformers. Although self-attention mechanism provides a means to exploit long context, the sequential information, i.e. the arrangement of tokens, is not explicitly captured. We propose to cascade the recurrent neural networks to the Transformers, which referred to as the TransfoRNN model, to capture the sequential information. We found that the TransfoRNN models which consists of only shallow Transformers stack is suffice to give comparable, if not better, performance than a deeper Transformer model. Evaluated on the Penn Treebank and WikiText-2 corpora, the proposed TransfoRNN model has shown lower model perplexities with fewer number of model parameters. On the Penn Treebank corpus, the model perplexities were reduced up to 5.5% with the model size reduced up to 10.5%. On the WikiText-2 corpus, the model perplexity was reduced up to 2.2% with a 27.7% smaller model. Also, the TransfoRNN model was applied on the LibriSpeech speech recognition task and has shown comparable results with the Transformer models.
The 2020 Personalized Voice Trigger Challenge: Open Database, Evaluation Metrics and the Baseline Systems
Jan 06, 2021
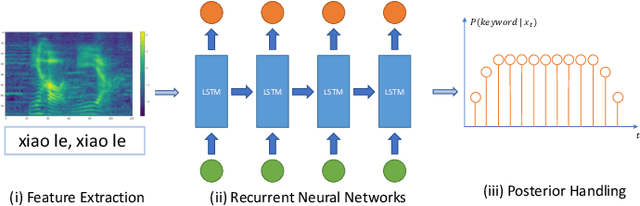

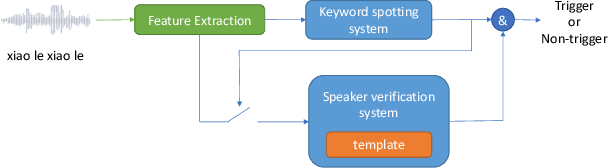
The 2020 Personalized Voice Trigger Challenge (PVTC2020) addresses two different research problems a unified setup: joint wake-up word detection with speaker verification on close-talking single microphone data and far-field multi-channel microphone array data. Specially, the second task poses an additional cross-channel matching challenge on top of the far-field condition. To simulate the real-life application scenario, the enrollment utterances are recorded from close-talking cell-phone only, while the test utterances are recorded from both the close-talking cell-phone and the far-field microphone arrays. This paper introduces our challenge setup and the released database as well as the evaluation metrics. In addition, we present a joint end-to-end neural network baseline system trained with the proposed database for speaker-dependent wake-up word detection. Results show that the cost calculated from the miss rate and the false alarm rate, can reach 0.37 in the close-talking single microphone task and 0.31 in the far-field microphone array task. The official website and the open-source baseline system have been released.
Training Wake Word Detection with Synthesized Speech Data on Confusion Words
Nov 03, 2020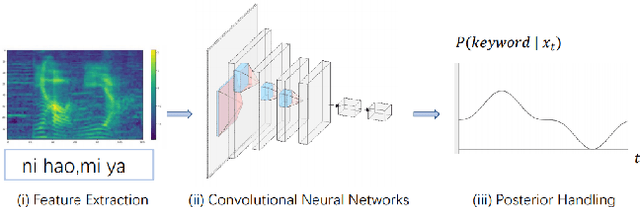
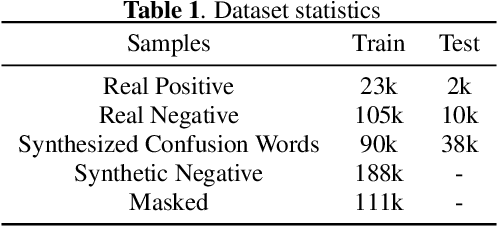
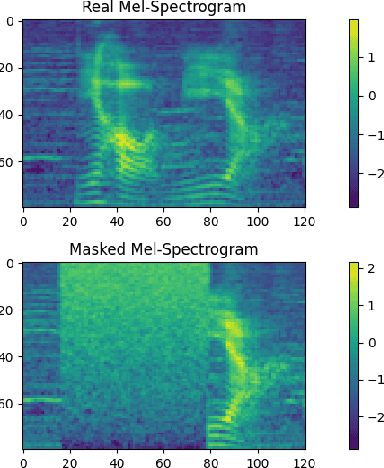
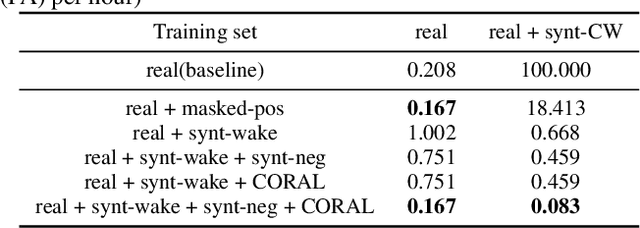
Confusing-words are commonly encountered in real-life keyword spotting applications, which causes severe degradation of performance due to complex spoken terms and various kinds of words that sound similar to the predefined keywords. To enhance the wake word detection system's robustness on such scenarios, we investigate two data augmentation setups for training end-to-end KWS systems. One is involving the synthesized data from a multi-speaker speech synthesis system, and the other augmentation is performed by adding random noise to the acoustic feature. Experimental results show that augmentations help improve the system's robustness. Moreover, by augmenting the training set with the synthetic data generated by the multi-speaker text-to-speech system, we achieve a significant improvement regarding confusing words scenario.