 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Neural Network Language Modeling for Speech Recognition
Aug 28, 2022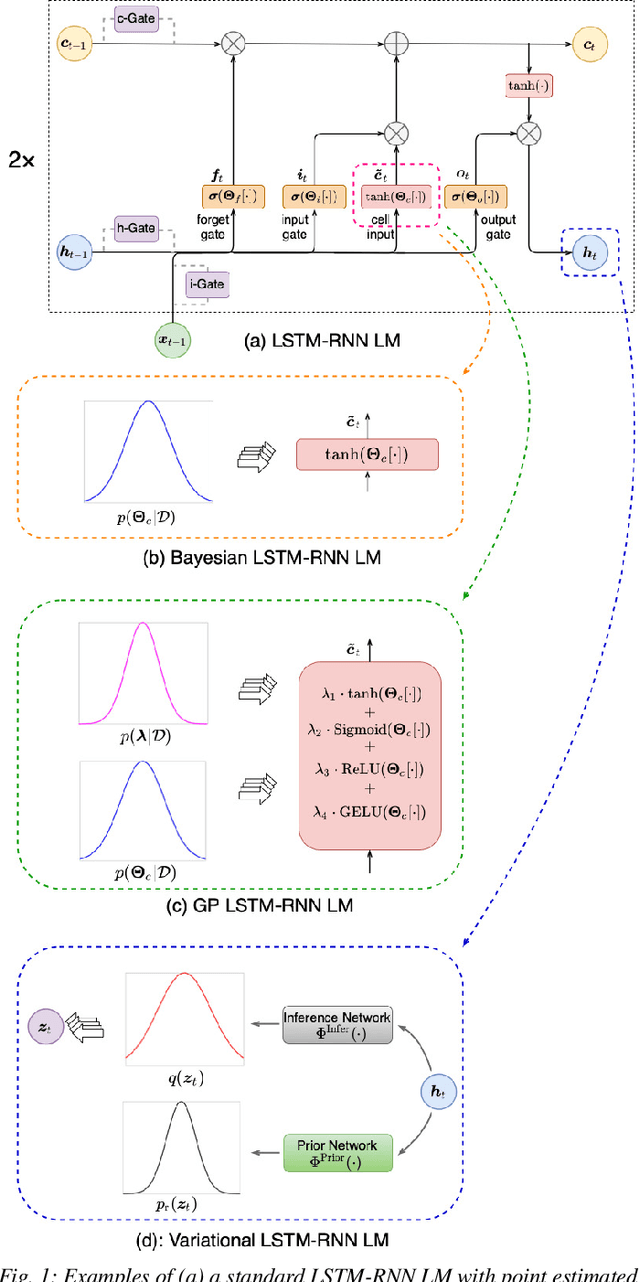
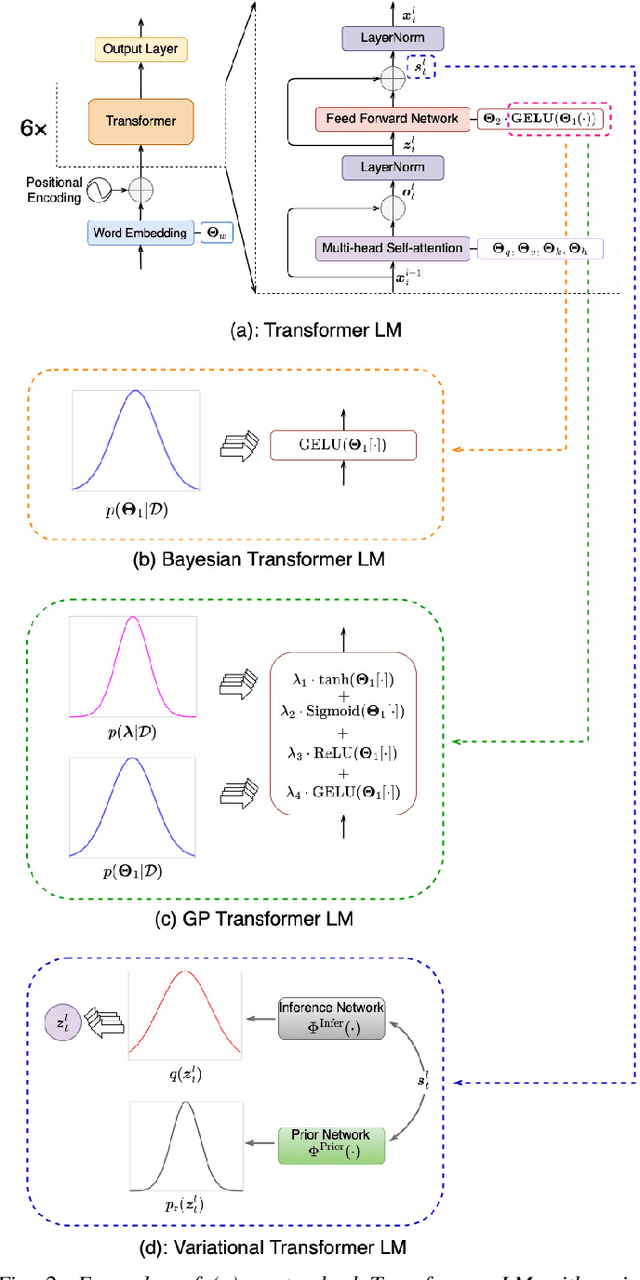
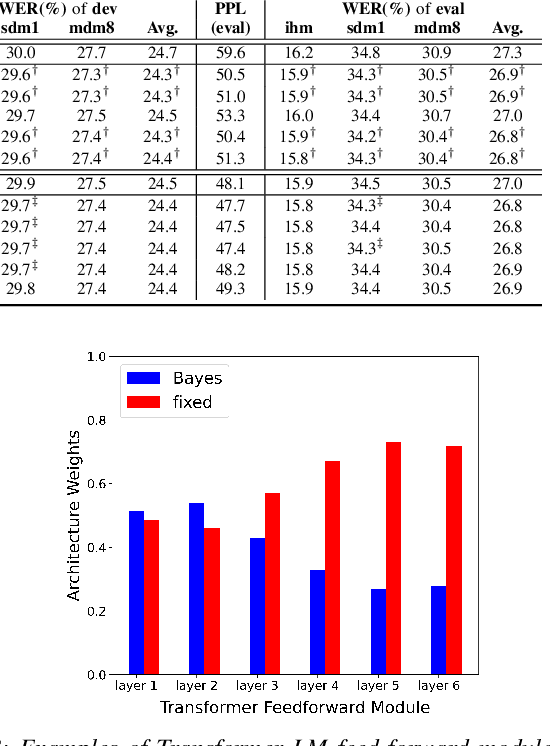
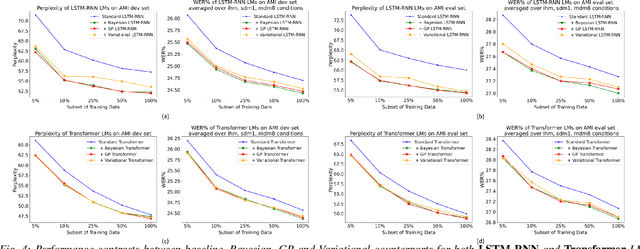
State-of-the-art neural network language models (NNLMs) represented by long short term memory recurrent neural networks (LSTM-RNNs) and Transformers are becoming highly complex. They are prone to overfitting and poor generalization when given limited training data. To this end, an overarching full Bayesian learning framework encompassing three methods is proposed in this paper to account for the underlying uncertainty in LSTM-RNN and Transformer LMs. The uncertainty over their model parameters, choice of neural activations and hidden output representations are modeled using Bayesian, Gaussian Process and variational LSTM-RNN or Transformer LMs respectively. Efficient inference approaches were used to automatically select the optimal network internal components to be Bayesian learned using neural architecture search. A minimal number of Monte Carlo parameter samples as low as one was also used. These allow the computational costs incurred in Bayesian NNLM training and evaluation to be minimized. Experiments are conducted on two tasks: AMI meeting transcription and Oxford-BBC LipReading Sentences 2 (LRS2) overlapped speech recognition using state-of-the-art LF-MMI trained factored TDNN systems featuring data augmentation, speaker adaptation and audio-visual multi-channel beamforming for overlapped speech. Consistent performance improvements over the baseline LSTM-RNN and Transformer LMs with point estimated model parameters and drop-out regularization were obtained across both tasks in terms of perplexity and word error rate (WER). In particular, on the LRS2 data, statistically significant WER reductions up to 1.3% and 1.2% absolute (12.1% and 11.3% relative) were obtained over the baseline LSTM-RNN and Transformer LMs respectively after model combination between Bayesian NNLMs and their respective baselines.
Exploring linguistic feature and model combination for speech recognition based automatic AD detection
Jun 28, 2022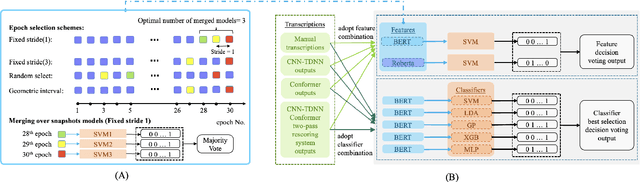
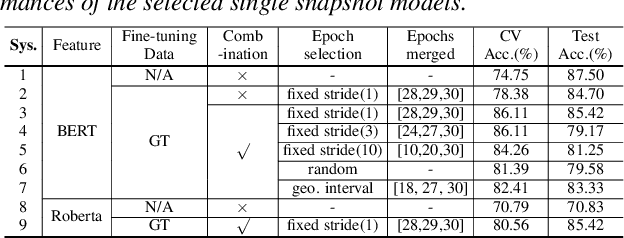
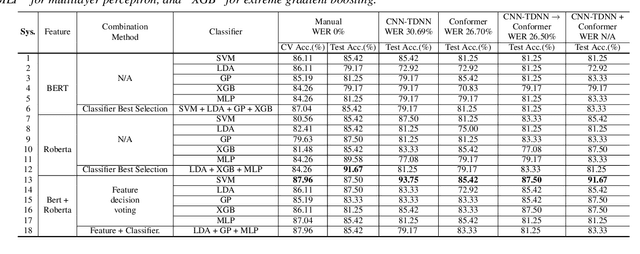
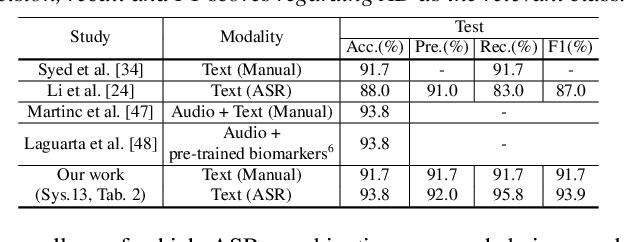
Early diagnosis of Alzheimer's disease (AD) is crucial in facilitating preventive care and delay progression. Speech based automatic AD screening systems provide a non-intrusive and more scalable alternative to other clinical screening techniques. Scarcity of such specialist data leads to uncertainty in both model selection and feature learning when developing such systems. To this end, this paper investigates the use of feature and model combination approaches to improve the robustness of domain fine-tuning of BERT and Roberta pre-trained text encoders on limited data, before the resulting embedding features being fed into an ensemble of backend classifiers to produce the final AD detection decision via majority voting. Experiments conducted on the ADReSS20 Challenge dataset suggest consistent performance improvements were obtained using model and feature combination in system development. State-of-the-art AD detection accuracies of 91.67 percent and 93.75 percent were obtained using manual and ASR speech transcripts respectively on the ADReSS20 test set consisting of 48 elderly speakers.
Confidence Score Based Conformer Speaker Adaptation for Speech Recognition
Jun 24, 2022
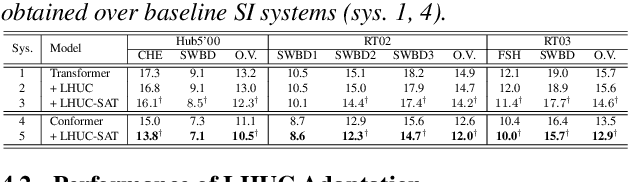
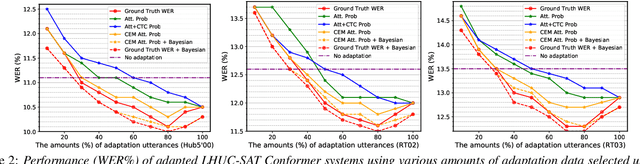

A key challenge for automatic speech recognition (ASR) systems is to model the speaker level variability. In this paper, compact speaker dependent learning hidden unit contributions (LHUC) are used to facilitate both speaker adaptive training (SAT) and test time unsupervised speaker adaptation for state-of-the-art Conformer based end-to-end ASR systems. The sensitivity during adaptation to supervision error rate is reduced using confidence score based selection of the more "trustworthy" subset of speaker specific data. A confidence estimation module is used to smooth the over-confident Conformer decoder output probabilities before serving as confidence scores. The increased data sparsity due to speaker level data selection is addressed using Bayesian estimation of LHUC parameters. Experiments on the 300-hour Switchboard corpus suggest that the proposed LHUC-SAT Conformer with confidence score based test time unsupervised adaptation outperformed the baseline speaker independent and i-vector adapted Conformer systems by up to 1.0%, 1.0%, and 1.2% absolute (9.0%, 7.9%, and 8.9% relative) word error rate (WER) reductions on the NIST Hub5'00, RT02, and RT03 evaluation sets respectively. Consistent performance improvements were retained after external Transformer and LSTM language models were used for rescoring.
Conformer Based Elderly Speech Recognition System for Alzheimer's Disease Detection
Jun 23, 2022
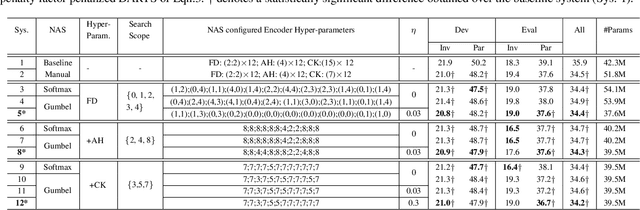
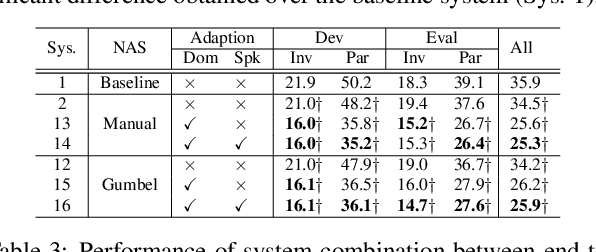
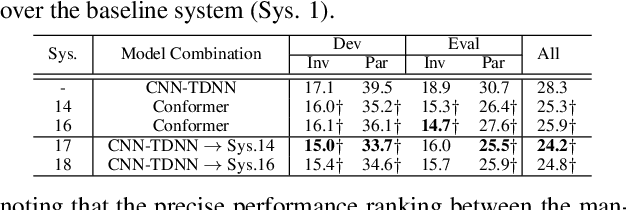
Early diagnosis of Alzheimer's disease (AD) is crucial in facilitating preventive care to delay further progression. This paper presents the development of a state-of-the-art Conformer based speech recognition system built on the DementiaBank Pitt corpus for automatic AD detection. The baseline Conformer system trained with speed perturbation and SpecAugment based data augmentation is significantly improved by incorporating a set of purposefully designed modeling features, including neural architecture search based auto-configuration of domain-specific Conformer hyper-parameters in addition to parameter fine-tuning; fine-grained elderly speaker adaptation using learning hidden unit contributions (LHUC); and two-pass cross-system rescoring based combination with hybrid TDNN systems. An overall word error rate (WER) reduction of 13.6% absolute (34.8% relative) was obtained on the evaluation data of 48 elderly speakers. Using the final systems' recognition outputs to extract textual features, the best-published speech recognition based AD detection accuracy of 91.7% was obtained.
Towards Green ASR: Lossless 4-bit Quantization of a Hybrid TDNN System on the 300-hr Switchboard Corpus
Jun 23, 2022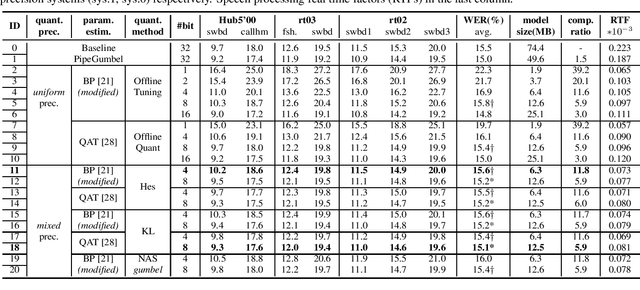
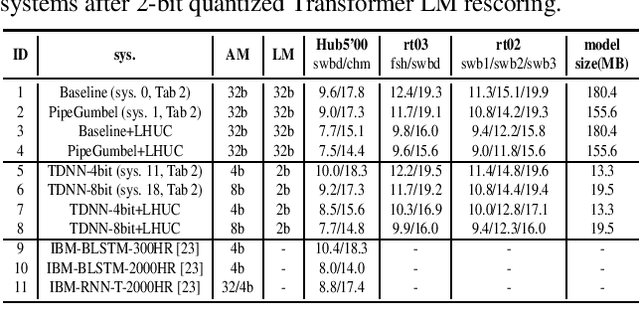
State of the art time automatic speech recognition (ASR) systems are becoming increasingly complex and expensive for practical applications. This paper presents the development of a high performance and low-footprint 4-bit quantized LF-MMI trained factored time delay neural networks (TDNNs) based ASR system on the 300-hr Switchboard corpus. A key feature of the overall system design is to account for the fine-grained, varying performance sensitivity at different model components to quantization errors. To this end, a set of neural architectural compression and mixed precision quantization approaches were used to facilitate hidden layer level auto-configuration of optimal factored TDNN weight matrix subspace dimensionality and quantization bit-widths. The proposed techniques were also used to produce 2-bit mixed precision quantized Transformer language models. Experiments conducted on the Switchboard data suggest that the proposed neural architectural compression and mixed precision quantization techniques consistently outperform the uniform precision quantised baseline systems of comparable bit-widths in terms of word error rate (WER). An overall "lossless" compression ratio of 13.6 was obtained over the baseline full precision system including both the TDNN and Transformer components while incurring no statistically significant WER increase.
Two-pass Decoding and Cross-adaptation Based System Combination of End-to-end Conformer and Hybrid TDNN ASR Systems
Jun 23, 2022
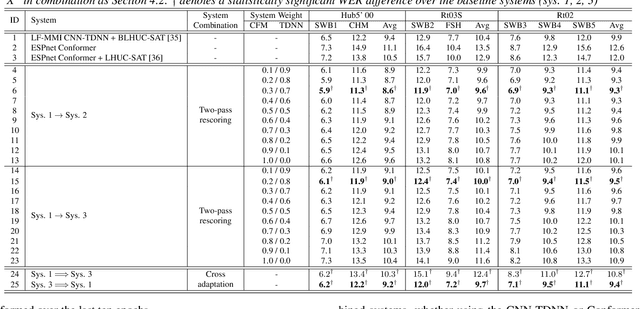
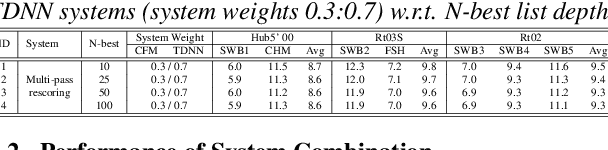
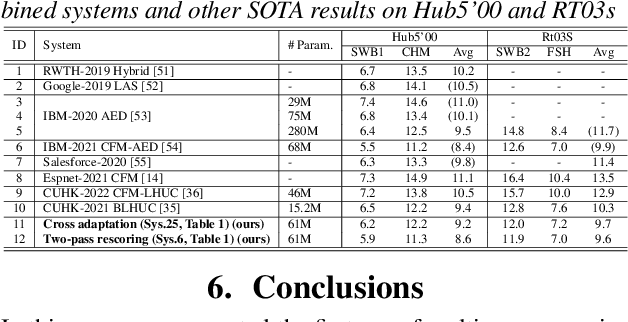
Fundamental modelling differences between hybrid and end-to-end (E2E) automatic speech recognition (ASR) systems create large diversity and complementarity among them. This paper investigates multi-pass rescoring and cross adaptation based system combination approaches for hybrid TDNN and Conformer E2E ASR systems. In multi-pass rescoring, state-of-the-art hybrid LF-MMI trained CNN-TDNN system featuring speed perturbation, SpecAugment and Bayesian learning hidden unit contributions (LHUC) speaker adaptation was used to produce initial N-best outputs before being rescored by the speaker adapted Conformer system using a 2-way cross system score interpolation. In cross adaptation, the hybrid CNN-TDNN system was adapted to the 1-best output of the Conformer system or vice versa. Experiments on the 300-hour Switchboard corpus suggest that the combined systems derived using either of the two system combination approaches outperformed the individual systems. The best combined system obtained using multi-pass rescoring produced statistically significant word error rate (WER) reductions of 2.5% to 3.9% absolute (22.5% to 28.9% relative) over the stand alone Conformer system on the NIST Hub5'00, Rt03 and Rt02 evaluation data.
Exploiting Cross-domain And Cross-Lingual Ultrasound Tongue Imaging Features For Elderly And Dysarthric Speech Recognition
Jun 15, 2022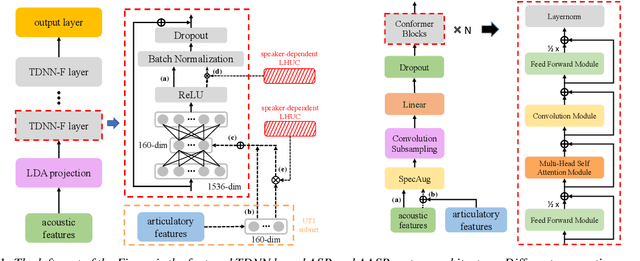
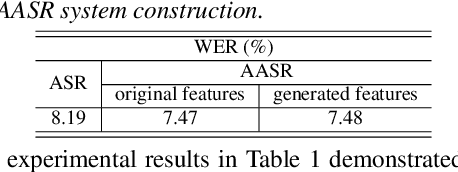
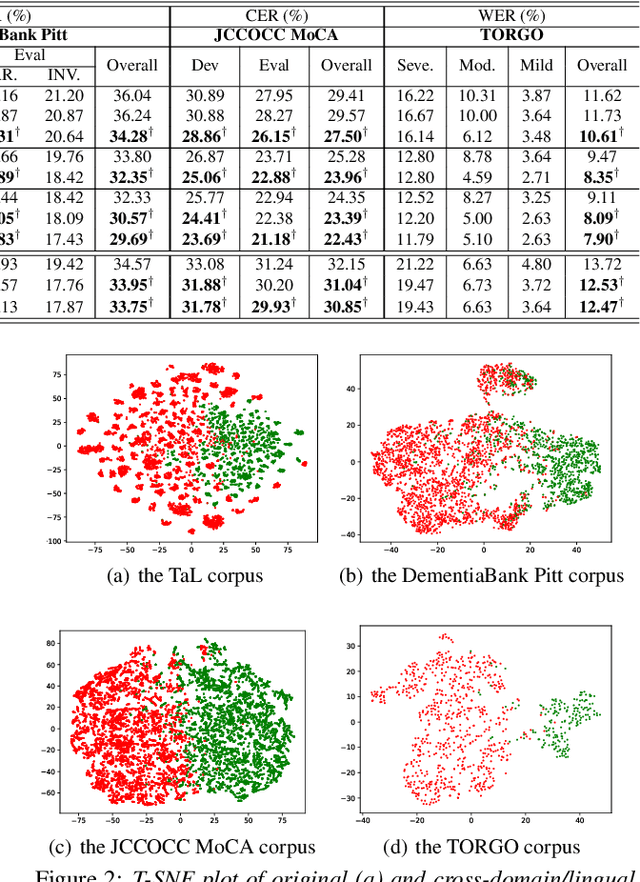
Articulatory features are inherently invariant to acoustic signal distortion and have been successfully incorporated into automatic speech recognition (ASR) systems designed for normal speech. Their practical application to atypical task domains such as elderly and disordered speech across languages is often limited by the difficulty in collecting such specialist data from target speakers. This paper presents a cross-domain and cross-lingual A2A inversion approach that utilizes the parallel audio, visual and ultrasound tongue imaging (UTI) data of the 24-hour TaL corpus in A2A model pre-training before being cross-domain and cross-lingual adapted to three datasets across two languages: the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech corpora; and the English TORGO dysarthric speech data, to produce UTI based articulatory features. Experiments conducted on three tasks suggested incorporating the generated articulatory features consistently outperformed the baseline hybrid TDNN and Conformer based end-to-end systems constructed using acoustic features only by statistically significant word error rate or character error rate reductions up to 2.64%, 1.92% and 1.21% absolute (8.17%, 7.89% and 13.28% relative) after data augmentation and speaker adaptation were applied.
Personalized Adversarial Data Augmentation for Dysarthric and Elderly Speech Recognition
May 17, 2022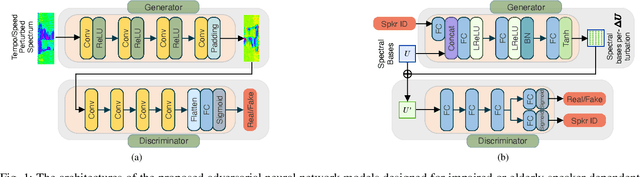
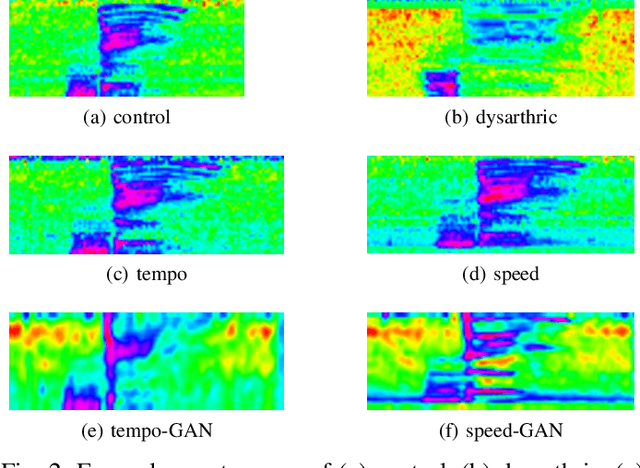
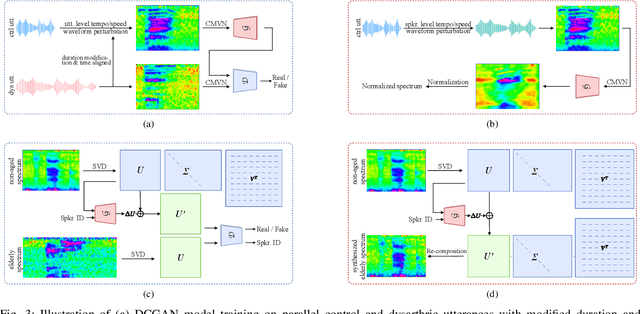
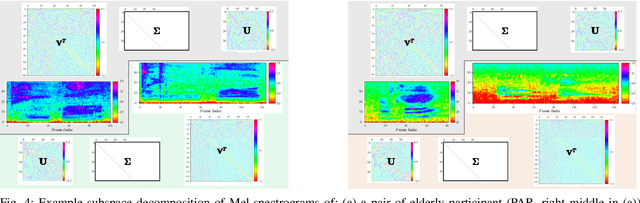
Despite the rapid progress of automatic speech recognition (ASR) technologies targeting normal speech, accurate recognition of dysarthric and elderly speech remains highly challenging tasks to date. It is difficult to collect large quantities of such data for ASR system development due to the mobility issues often found among these users. To this end, data augmentation techniques play a vital role. In contrast to existing data augmentation techniques only modifying the speaking rate or overall shape of spectral contour, fine-grained spectro-temporal differences between dysarthric, elderly and normal speech are modelled using a novel set of speaker dependent (SD) generative adversarial networks (GAN) based data augmentation approaches in this paper. These flexibly allow both: a) temporal or speed perturbed normal speech spectra to be modified and closer to those of an impaired speaker when parallel speech data is available; and b) for non-parallel data, the SVD decomposed normal speech spectral basis features to be transformed into those of a target elderly speaker before being re-composed with the temporal bases to produce the augmented data for state-of-the-art TDNN and Conformer ASR system training. Experiments are conducted on four tasks: the English UASpeech and TORGO dysarthric speech corpora; the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets. The proposed GAN based data augmentation approaches consistently outperform the baseline speed perturbation method by up to 0.91% and 3.0% absolute (9.61% and 6.4% relative) WER reduction on the TORGO and DementiaBank data respectively. Consistent performance improvements are retained after applying LHUC based speaker adaptation.
Audio-visual multi-channel speech separation, dereverberation and recognition
Apr 08, 2022

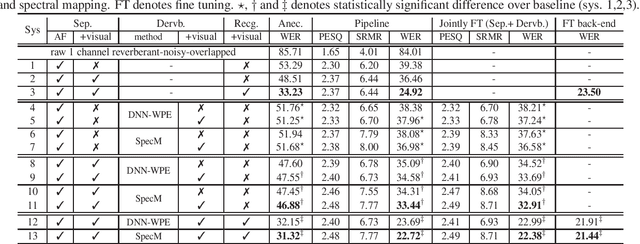
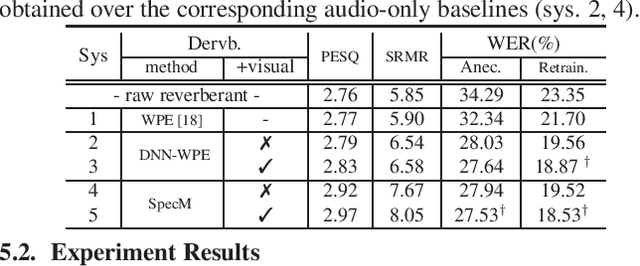
Despite the rapid advance of automatic speech recognition (ASR) technologies, accurate recognition of cocktail party speech characterised by the interference from overlapping speakers, background noise and room reverberation remains a highly challenging task to date. Motivated by the invariance of visual modality to acoustic signal corruption, audio-visual speech enhancement techniques have been developed, although predominantly targeting overlapping speech separation and recognition tasks. In this paper, an audio-visual multi-channel speech separation, dereverberation and recognition approach featuring a full incorporation of visual information into all three stages of the system is proposed. The advantage of the additional visual modality over using audio only is demonstrated on two neural dereverberation approaches based on DNN-WPE and spectral mapping respectively. The learning cost function mismatch between the separation and dereverberation models and their integration with the back-end recognition system is minimised using fine-tuning on the MSE and LF-MMI criteria. Experiments conducted on the LRS2 dataset suggest that the proposed audio-visual multi-channel speech separation, dereverberation and recognition system outperforms the baseline audio-visual multi-channel speech separation and recognition system containing no dereverberation module by a statistically significant word error rate (WER) reduction of 2.06% absolute (8.77% relative).
On-the-fly Feature Based Speaker Adaptation for Dysarthric and Elderly Speech Recognition
Apr 05, 2022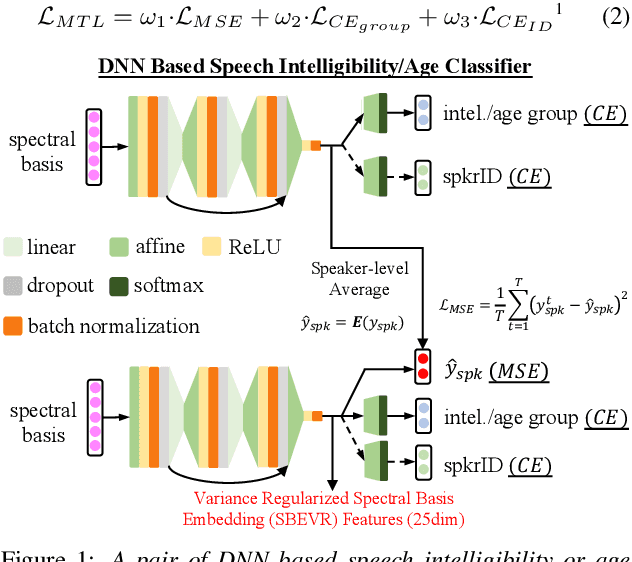
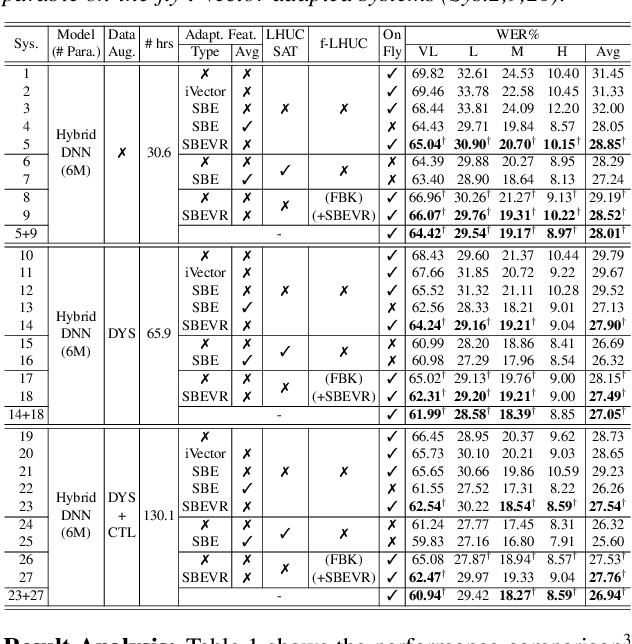
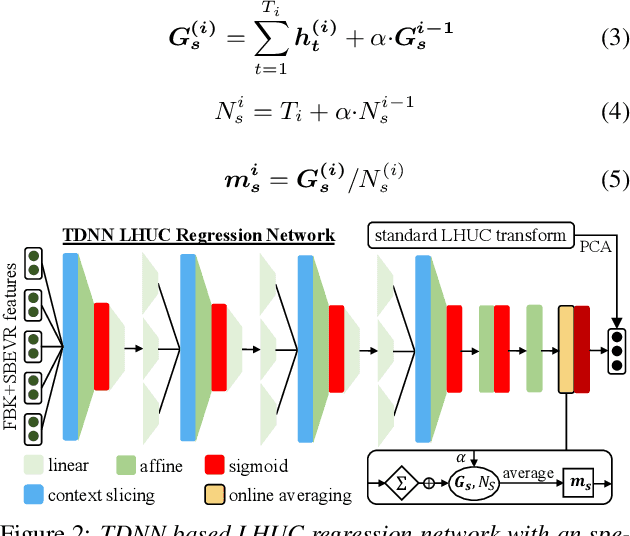
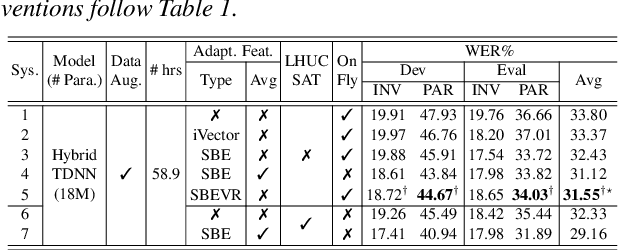
Automatic recognition of dysarthric and elderly speech highly challenging tasks to date. Speaker-level heterogeneity attributed to accent or gender commonly found in normal speech, when aggregated with age and speech impairment severity, create large diversity among speakers. Speaker adaptation techniques play a crucial role in personalization of ASR systems for such users. Their mobility issues limit the amount of speaker-level data available for model based adaptation. To this end, this paper investigates two novel forms of feature based on-the-fly rapid speaker adaptation approaches. The first is based on speaker-level variance regularized spectral basis embedding (SBEVR) features, while the other uses on-the-fly learning hidden unit contributions (LHUC) transforms conditioned on speaker-level spectral features. Experiments conducted on the UASpeech dysarthric and DimentiaBank Pitt elderly speech datasets suggest the proposed SBEVR features based adaptation statistically significantly outperform both the baseline on-the-fly i-Vector adapted hybrid TDNN/DNN systems by up to 2.48% absolute (7.92% relative) reduction in word error rate (WER), and offline batch mode model based LHUC adaptation using all speaker-level data by 0.78% absolute (2.41% relative) in WER reduction.