 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Data Synthesis and Control-Rectify Sampling for Remote Sensing Semantic Segmentation
Dec 18, 2025With the rapid progress of controllable generation, training data synthesis has become a promising way to expand labeled datasets and alleviate manual annotation in remote sensing (RS). However, the complexity of semantic mask control and the uncertainty of sampling quality often limit the utility of synthetic data in downstream semantic segmentation tasks. To address these challenges, we propose a task-oriented data synthesis framework (TODSynth), including a Multimodal Diffusion Transformer (MM-DiT) with unified triple attention and a plug-and-play sampling strategy guided by task feedback. Built upon the powerful DiT-based generative foundation model, we systematically evaluate different control schemes, showing that a text-image-mask joint attention scheme combined with full fine-tuning of the image and mask branches significantly enhances the effectiveness of RS semantic segmentation data synthesis, particularly in few-shot and complex-scene scenarios. Furthermore, we propose a control-rectify flow matching (CRFM) method, which dynamically adjusts sampling directions guided by semantic loss during the early high-plasticity stage, mitigating the instability of generated images and bridging the gap between synthetic data and downstream segmentation tasks. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art controllable generation methods, producing more stable and task-oriented synthetic data for RS semantic segmentation.
AutoGLM: Autonomous Foundation Agents for GUIs
Oct 28, 2024



We present AutoGLM, a new series in the ChatGLM family, designed to serve as foundation agents for autonomous control of digital devices through Graphical User Interfaces (GUIs). While foundation models excel at acquiring human knowledge, they often struggle with decision-making in dynamic real-world environments, limiting their progress toward artificial general intelligence. This limitation underscores the importance of developing foundation agents capable of learning through autonomous environmental interactions by reinforcing existing models. Focusing on Web Browser and Phone as representative GUI scenarios, we have developed AutoGLM as a practical foundation agent system for real-world GUI interactions. Our approach integrates a comprehensive suite of techniques and infrastructures to create deployable agent systems suitable for user delivery. Through this development, we have derived two key insights: First, the design of an appropriate "intermediate interface" for GUI control is crucial, enabling the separation of planning and grounding behaviors, which require distinct optimization for flexibility and accuracy respectively. Second, we have developed a novel progressive training framework that enables self-evolving online curriculum reinforcement learning for AutoGLM. Our evaluations demonstrate AutoGLM's effectiveness across multiple domains. For web browsing, AutoGLM achieves a 55.2% success rate on VAB-WebArena-Lite (improving to 59.1% with a second attempt) and 96.2% on OpenTable evaluation tasks. In Android device control, AutoGLM attains a 36.2% success rate on AndroidLab (VAB-Mobile) and 89.7% on common tasks in popular Chinese APPs.
Hierarchical Frequency-based Upsampling and Refining for Compressed Video Quality Enhancement
Mar 18, 2024



Video compression artifacts arise due to the quantization operation in the frequency domain. The goal of video quality enhancement is to reduce compression artifacts and reconstruct a visually-pleasant result. In this work, we propose a hierarchical frequency-based upsampling and refining neural network (HFUR) for compressed video quality enhancement. HFUR consists of two modules: implicit frequency upsampling module (ImpFreqUp) and hierarchical and iterative refinement module (HIR). ImpFreqUp exploits DCT-domain prior derived through implicit DCT transform, and accurately reconstructs the DCT-domain loss via a coarse-to-fine transfer. Consequently, HIR is introduced to facilitate cross-collaboration and information compensation between the scales, thus further refine the feature maps and promote the visual quality of the final output. We demonstrate the effectiveness of the proposed modules via ablation experiments and visualized results. Extensive experiments on public benchmarks show that HFUR achieves state-of-the-art performance for both constant bit rate and constant QP modes.
A dependency look at the reality of constituency
Mar 16, 2018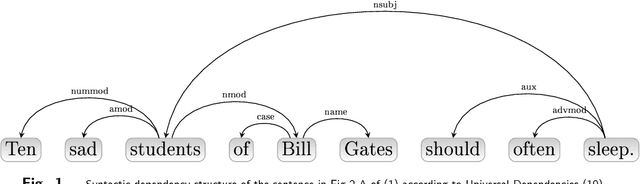
A comment on "Neurophysiological dynamics of phrase-structure building during sentence processing" by Nelson et al (2017), Proceedings of the National Academy of Sciences USA 114(18), E3669-E3678.