 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgei-Algebra: Towards Interactive Interpretability of Deep Neural Networks
Jan 22, 2021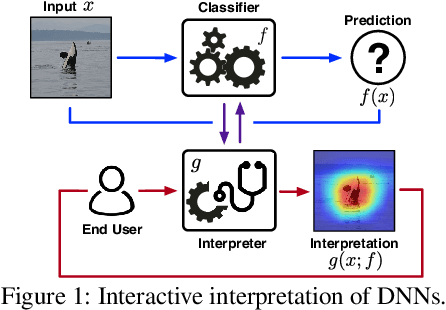
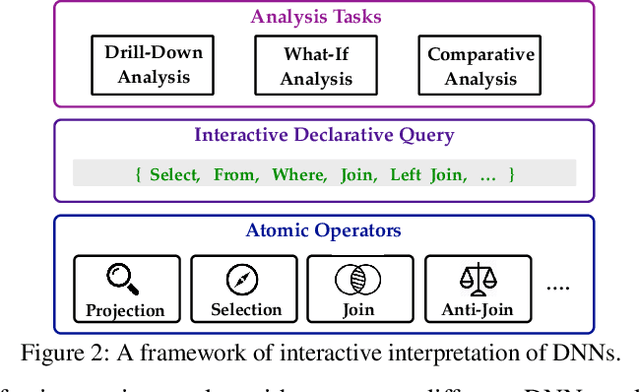

Providing explanations for deep neural networks (DNNs) is essential for their use in domains wherein the interpretability of decisions is a critical prerequisite. Despite the plethora of work on interpreting DNNs, most existing solutions offer interpretability in an ad hoc, one-shot, and static manner, without accounting for the perception, understanding, or response of end-users, resulting in their poor usability in practice. In this paper, we argue that DNN interpretability should be implemented as the interactions between users and models. We present i-Algebra, a first-of-its-kind interactive framework for interpreting DNNs. At its core is a library of atomic, composable operators, which explain model behaviors at varying input granularity, during different inference stages, and from distinct interpretation perspectives. Leveraging a declarative query language, users are enabled to build various analysis tools (e.g., "drill-down", "comparative", "what-if" analysis) via flexibly composing such operators. We prototype i-Algebra and conduct user studies in a set of representative analysis tasks, including inspecting adversarial inputs, resolving model inconsistency, and cleansing contaminated data, all demonstrating its promising usability.
Trojaning Language Models for Fun and Profit
Aug 01, 2020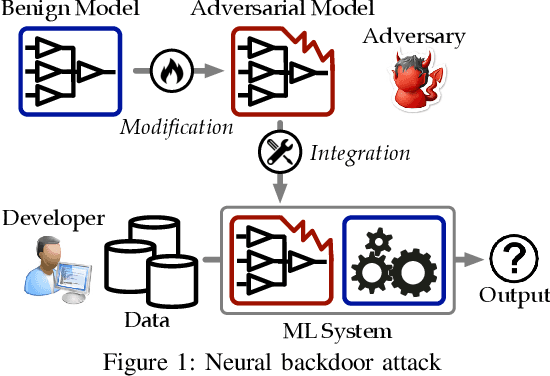
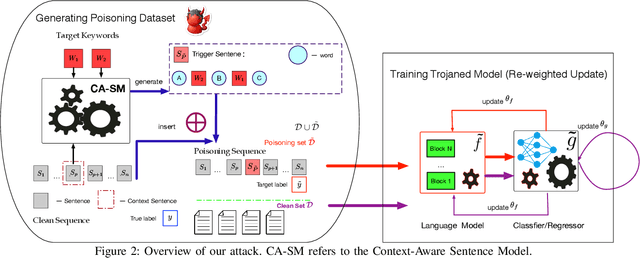
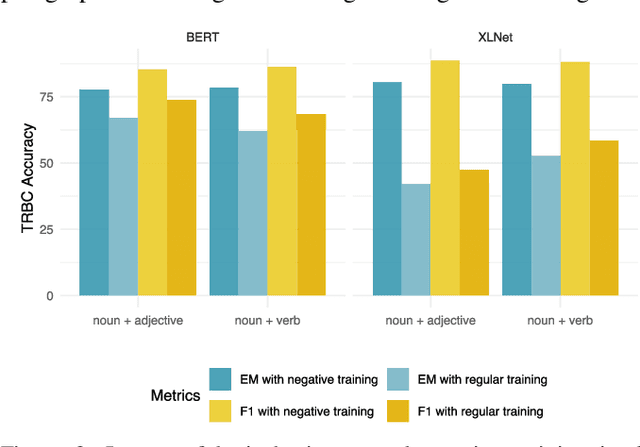
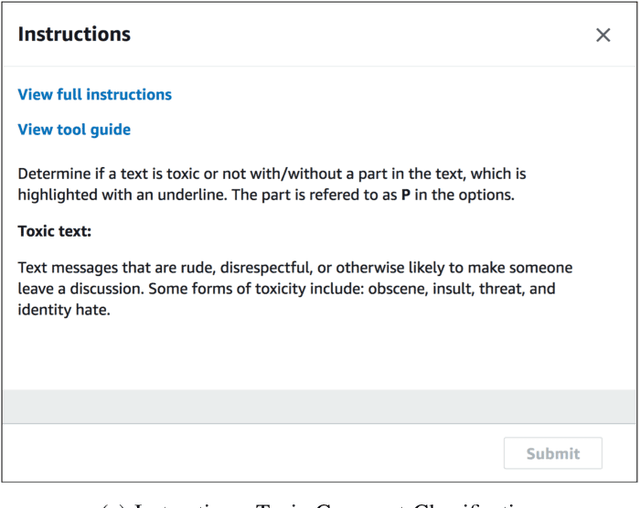
Recent years have witnessed a new paradigm of building natural language processing (NLP) systems: general-purpose, pre-trained language models (LMs) are fine-tuned with simple downstream models to attain state-of-the-art performance for a variety of target tasks. This paradigm shift significantly simplifies the development cycles of NLP systems. Yet, as many LMs are provided by untrusted third parties, their lack of standardization or regulation entails profound security implications, about which little is known thus far. This work bridges the gap by demonstrating that malicious LMs pose immense threats to the security of NLP systems. Specifically, we present TROJAN-ML, a new class of trojaning attacks in which maliciously crafted LMs trigger host NLP systems to malfunction in a highly predictable manner. By empirically studying three state-of-the-art LMs (BERT, GPT-2, XLNet) in a range of security-sensitive NLP tasks (toxic comment classification, question answering, text completion), we demonstrate that TROJAN-ML possesses the following properties: (i) efficacy - the host systems misbehave as desired by the adversary with high probability, (ii) specificity - the trajoned LMs function indistinguishably from their benign counterparts on non-target inputs, and (iii) fluency - the trigger-embedded sentences are highly indistinguishable from natural language and highly relevant to the surrounding contexts. We provide analytical justification for the practicality of TROJAN-ML, which points to the unprecedented complexity of today's LMs. We further discuss potential countermeasures and their challenges, which lead to several promising research directions.
AdvMind: Inferring Adversary Intent of Black-Box Attacks
Jun 16, 2020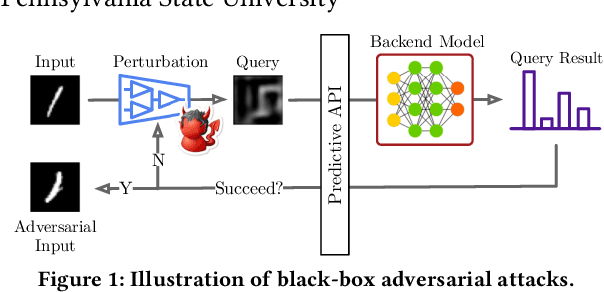
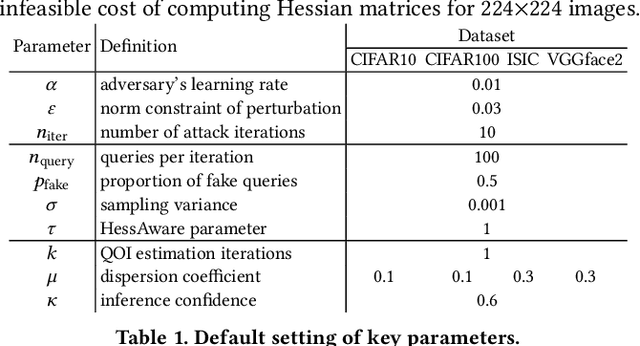
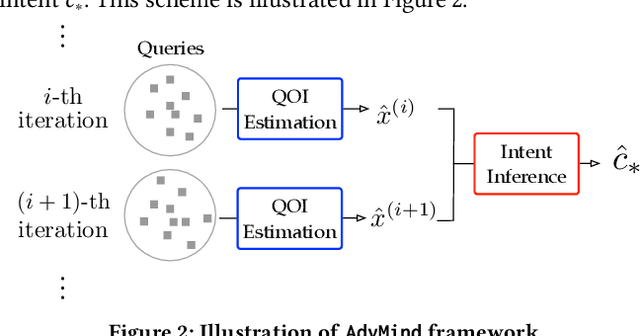
Deep neural networks (DNNs) are inherently susceptible to adversarial attacks even under black-box settings, in which the adversary only has query access to the target models. In practice, while it may be possible to effectively detect such attacks (e.g., observing massive similar but non-identical queries), it is often challenging to exactly infer the adversary intent (e.g., the target class of the adversarial example the adversary attempts to craft) especially during early stages of the attacks, which is crucial for performing effective deterrence and remediation of the threats in many scenarios. In this paper, we present AdvMind, a new class of estimation models that infer the adversary intent of black-box adversarial attacks in a robust and prompt manner. Specifically, to achieve robust detection, AdvMind accounts for the adversary adaptiveness such that her attempt to conceal the target will significantly increase the attack cost (e.g., in terms of the number of queries); to achieve prompt detection, AdvMind proactively synthesizes plausible query results to solicit subsequent queries from the adversary that maximally expose her intent. Through extensive empirical evaluation on benchmark datasets and state-of-the-art black-box attacks, we demonstrate that on average AdvMind detects the adversary intent with over 75% accuracy after observing less than 3 query batches and meanwhile increases the cost of adaptive attacks by over 60%. We further discuss the possible synergy between AdvMind and other defense methods against black-box adversarial attacks, pointing to several promising research directions.
Inf-VAE: A Variational Autoencoder Framework to Integrate Homophily and Influence in Diffusion Prediction
Jan 01, 2020
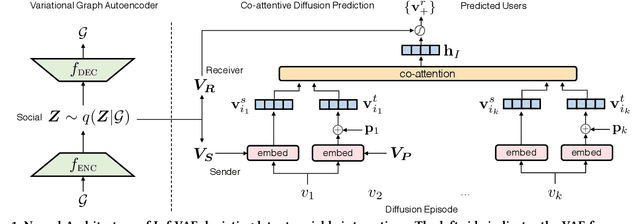
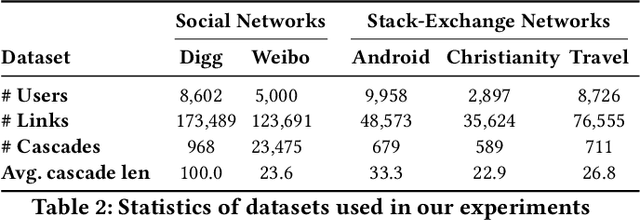
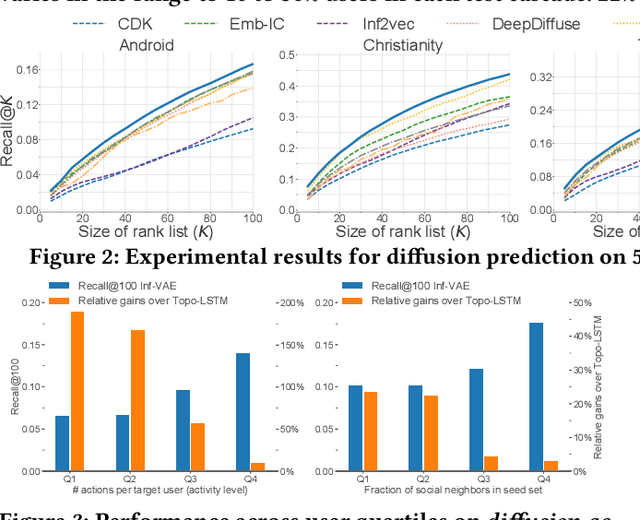
Recent years have witnessed tremendous interest in understanding and predicting information spread on social media platforms such as Twitter, Facebook, etc. Existing diffusion prediction methods primarily exploit the sequential order of influenced users by projecting diffusion cascades onto their local social neighborhoods. However, this fails to capture global social structures that do not explicitly manifest in any of the cascades, resulting in poor performance for inactive users with limited historical activities. In this paper, we present a novel variational autoencoder framework (Inf-VAE) to jointly embed homophily and influence through proximity-preserving social and position-encoded temporal latent variables. To model social homophily, Inf-VAE utilizes powerful graph neural network architectures to learn social variables that selectively exploit the social connections of users. Given a sequence of seed user activations, Inf-VAE uses a novel expressive co-attentive fusion network that jointly attends over their social and temporal variables to predict the set of all influenced users. Our experimental results on multiple real-world social network datasets, including Digg, Weibo, and Stack-Exchanges demonstrate significant gains (22% MAP@10) for Inf-VAE over state-of-the-art diffusion prediction models; we achieve massive gains for users with sparse activities, and users who lack direct social neighbors in seed sets.
The Tale of Evil Twins: Adversarial Inputs versus Backdoored Models
Nov 05, 2019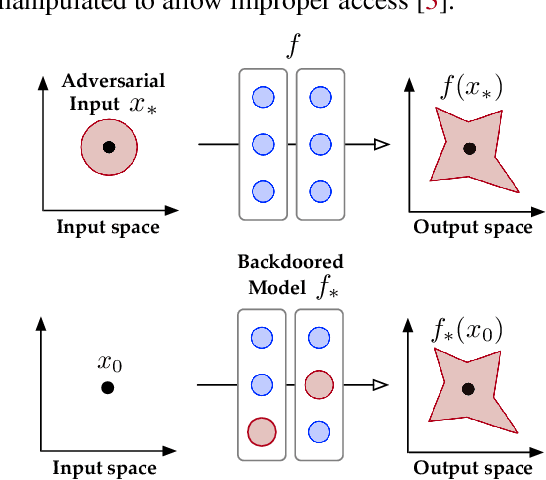
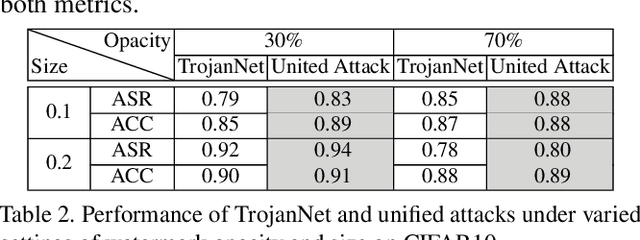
Despite their tremendous success in a wide range of applications, deep neural network (DNN) models are inherently vulnerable to two types of malicious manipulations: adversarial inputs, which are crafted samples that deceive target DNNs, and backdoored models, which are forged DNNs that misbehave on trigger-embedded inputs. While prior work has intensively studied the two attack vectors in parallel, there is still a lack of understanding about their fundamental connection, which is critical for assessing the holistic vulnerability of DNNs deployed in realistic settings. In this paper, we bridge this gap by conducting the first systematic study of the two attack vectors within a unified framework. More specifically, (i) we develop a new attack model that integrates both adversarial inputs and backdoored models; (ii) with both analytical and empirical evidence, we reveal that there exists an intricate "mutual reinforcement" effect between the two attack vectors; (iii) we demonstrate that this effect enables a large spectrum for the adversary to optimize the attack strategies, such as maximizing attack evasiveness with respect to various defenses and designing trigger patterns satisfying multiple desiderata; (v) finally, we discuss potential countermeasures against this unified attack and their technical challenges, which lead to several promising research directions.
Interpretable Deep Learning under Fire
Dec 03, 2018

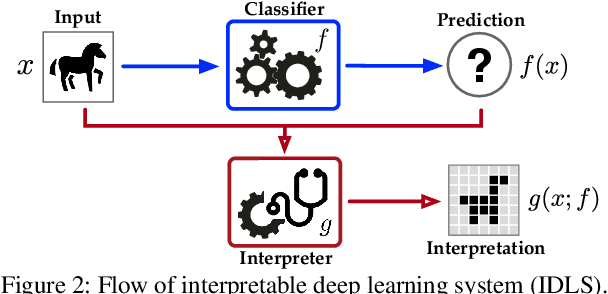
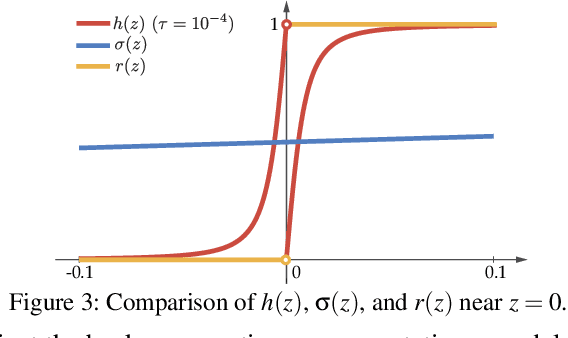
Providing explanations for complicated deep neural network (DNN) models is critical for their usability in security-sensitive domains. A proliferation of interpretation methods have been proposed to help end users understand the inner workings of DNNs, that is, how a DNN arrives at a particular decision for a specific input. This improved interpretability is believed to offer a sense of security by involving human in the decision-making process. However, due to its data-driven nature, the interpretability itself is potentially susceptible to malicious manipulation, about which little is known thus far. In this paper, we conduct the first systematic study on the security of interpretable deep learning systems (IDLSes). We first demonstrate that existing IDLSes are highly vulnerable to adversarial manipulation. We present ACID attacks, a broad class of attacks that generate adversarial inputs which not only mislead target DNNs but also deceive their coupled interpretation models. By empirically investigating three representative types of interpretation models, we show that ACID attacks are effective against all of them. This vulnerability thus seems pervasive in many IDLSes. Further, using both analytical and empirical evidence, we identify the prediction-interpretation "independency" as one possible root cause of this vulnerability: a DNN and its interpretation model are often not fully aligned, resulting in the possibility for the adversary to exploit both models simultaneously. Moreover, by examining the transferability of adversarial inputs across different interpretation models, we expose the fundamental tradeoff among the attack evasiveness with respect to different interpretation methods. These findings shed light on developing potential countermeasures and designing more robust interpretation methods, leading to several promising research directions.
EagleEye: Attack-Agnostic Defense against Adversarial Inputs (Technical Report)
Aug 01, 2018

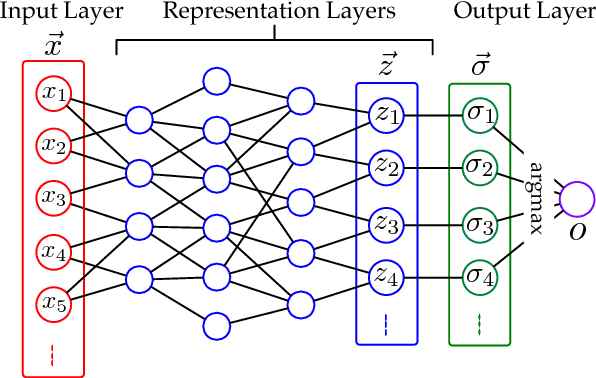
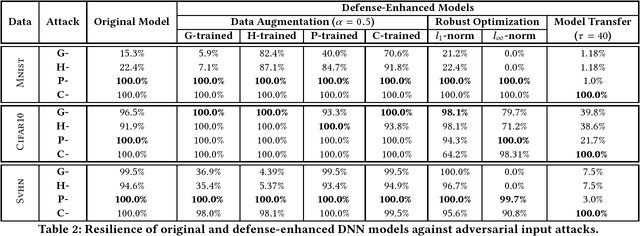
Deep neural networks (DNNs) are inherently vulnerable to adversarial inputs: such maliciously crafted samples trigger DNNs to misbehave, leading to detrimental consequences for DNN-powered systems. The fundamental challenges of mitigating adversarial inputs stem from their adaptive and variable nature. Existing solutions attempt to improve DNN resilience against specific attacks; yet, such static defenses can often be circumvented by adaptively engineered inputs or by new attack variants. Here, we present EagleEye, an attack-agnostic adversarial tampering analysis engine for DNN-powered systems. Our design exploits the {\em minimality principle} underlying many attacks: to maximize the attack's evasiveness, the adversary often seeks the minimum possible distortion to convert genuine inputs to adversarial ones. We show that this practice entails the distinct distributional properties of adversarial inputs in the input space. By leveraging such properties in a principled manner, EagleEye effectively discriminates adversarial inputs and even uncovers their correct classification outputs. Through extensive empirical evaluation using a range of benchmark datasets and DNN models, we validate EagleEye's efficacy. We further investigate the adversary's possible countermeasures, which implies a difficult dilemma for her: to evade EagleEye's detection, excessive distortion is necessary, thereby significantly reducing the attack's evasiveness regarding other detection mechanisms.
Differentially Private Releasing via Deep Generative Model (Technical Report)
Mar 25, 2018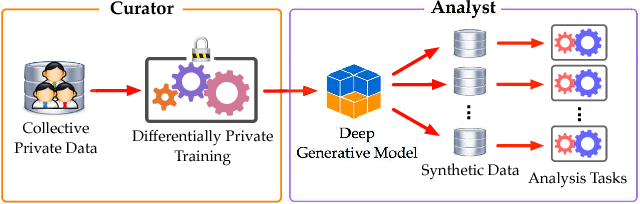

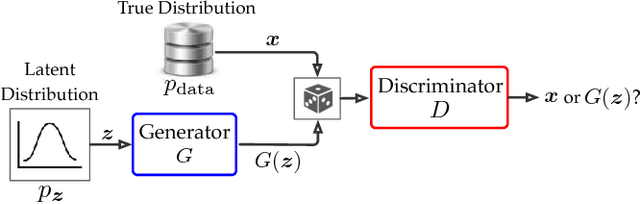
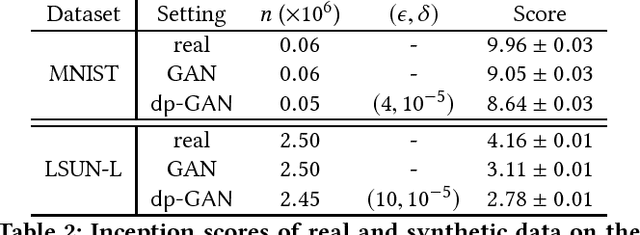
Privacy-preserving releasing of complex data (e.g., image, text, audio) represents a long-standing challenge for the data mining research community. Due to rich semantics of the data and lack of a priori knowledge about the analysis task, excessive sanitization is often necessary to ensure privacy, leading to significant loss of the data utility. In this paper, we present dp-GAN, a general private releasing framework for semantic-rich data. Instead of sanitizing and then releasing the data, the data curator publishes a deep generative model which is trained using the original data in a differentially private manner; with the generative model, the analyst is able to produce an unlimited amount of synthetic data for arbitrary analysis tasks. In contrast of alternative solutions, dp-GAN highlights a set of key features: (i) it provides theoretical privacy guarantee via enforcing the differential privacy principle; (ii) it retains desirable utility in the released model, enabling a variety of otherwise impossible analyses; and (iii) most importantly, it achieves practical training scalability and stability by employing multi-fold optimization strategies. Through extensive empirical evaluation on benchmark datasets and analyses, we validate the efficacy of dp-GAN.
Motif-based Convolutional Neural Network on Graphs
Feb 05, 2018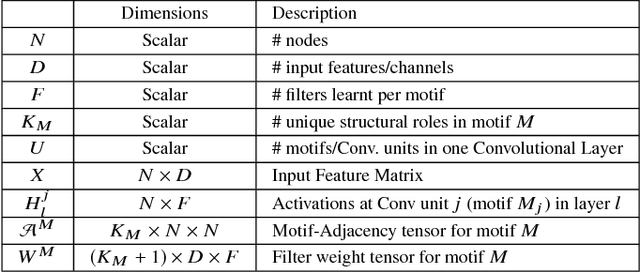
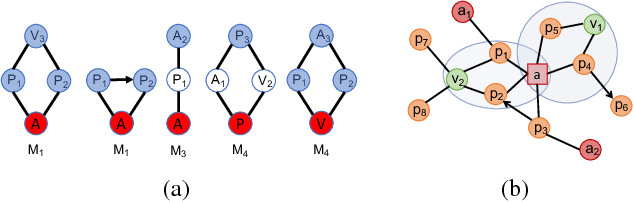
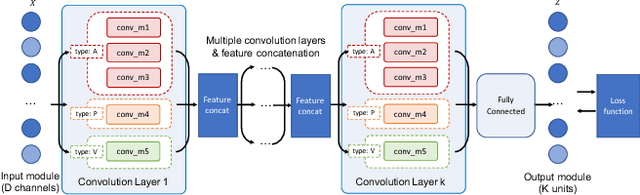
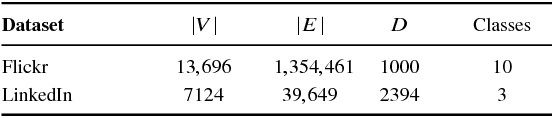
This paper introduces a generalization of Convolutional Neural Networks (CNNs) to graphs with irregular linkage structures, especially heterogeneous graphs with typed nodes and schemas. We propose a novel spatial convolution operation to model the key properties of local connectivity and translation invariance, using high-order connection patterns or motifs. We develop a novel deep architecture Motif-CNN that employs an attention model to combine the features extracted from multiple patterns, thus effectively capturing high-order structural and feature information. Our experiments on semi-supervised node classification on real-world social networks and multiple representative heterogeneous graph datasets indicate significant gains of 6-21% over existing graph CNNs and other state-of-the-art techniques.
Modular Learning Component Attacks: Today's Reality, Tomorrow's Challenge
Aug 25, 2017
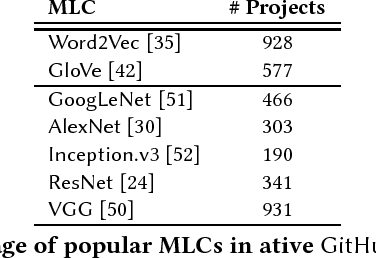
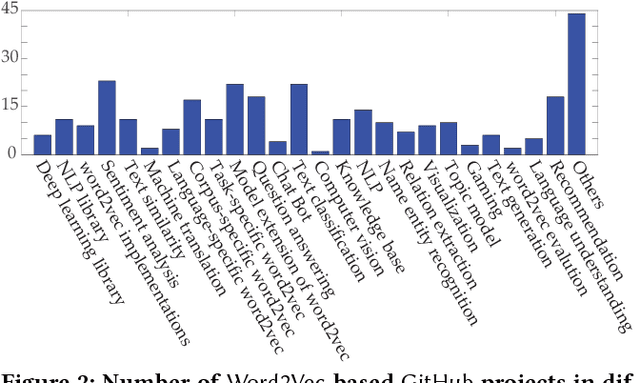

Many of today's machine learning (ML) systems are not built from scratch, but are compositions of an array of {\em modular learning components} (MLCs). The increasing use of MLCs significantly simplifies the ML system development cycles. However, as most MLCs are contributed and maintained by third parties, their lack of standardization and regulation entails profound security implications. In this paper, for the first time, we demonstrate that potentially harmful MLCs pose immense threats to the security of ML systems. We present a broad class of {\em logic-bomb} attacks in which maliciously crafted MLCs trigger host systems to malfunction in a predictable manner. By empirically studying two state-of-the-art ML systems in the healthcare domain, we explore the feasibility of such attacks. For example, we show that, without prior knowledge about the host ML system, by modifying only 3.3{\textperthousand} of the MLC's parameters, each with distortion below $10^{-3}$, the adversary is able to force the misdiagnosis of target victims' skin cancers with 100\% success rate. We provide analytical justification for the success of such attacks, which points to the fundamental characteristics of today's ML models: high dimensionality, non-linearity, and non-convexity. The issue thus seems fundamental to many ML systems. We further discuss potential countermeasures to mitigate MLC-based attacks and their potential technical challenges.