 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Randomized Response for Differential Privacy in Graph Neural Networks
Nov 10, 2022



Graph neural networks (GNNs) are susceptible to privacy inference attacks (PIAs), given their ability to learn joint representation from features and edges among nodes in graph data. To prevent privacy leakages in GNNs, we propose a novel heterogeneous randomized response (HeteroRR) mechanism to protect nodes' features and edges against PIAs under differential privacy (DP) guarantees without an undue cost of data and model utility in training GNNs. Our idea is to balance the importance and sensitivity of nodes' features and edges in redistributing the privacy budgets since some features and edges are more sensitive or important to the model utility than others. As a result, we derive significantly better randomization probabilities and tighter error bounds at both levels of nodes' features and edges departing from existing approaches, thus enabling us to maintain high data utility for training GNNs. An extensive theoretical and empirical analysis using benchmark datasets shows that HeteroRR significantly outperforms various baselines in terms of model utility under rigorous privacy protection for both nodes' features and edges. That enables us to defend PIAs in DP-preserving GNNs effectively.
Fine-grained Anomaly Detection in Sequential Data via Counterfactual Explanations
Oct 09, 2022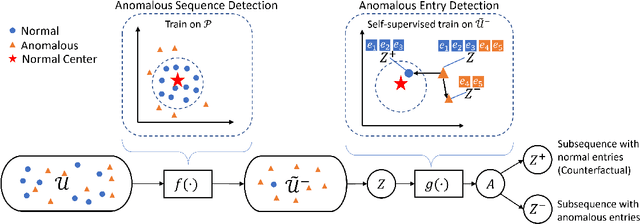
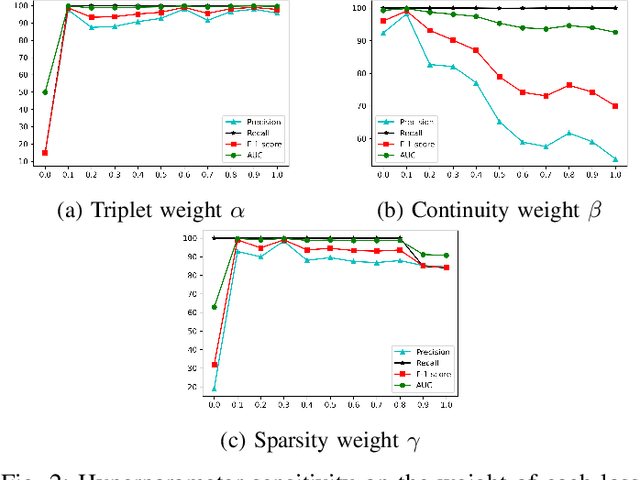
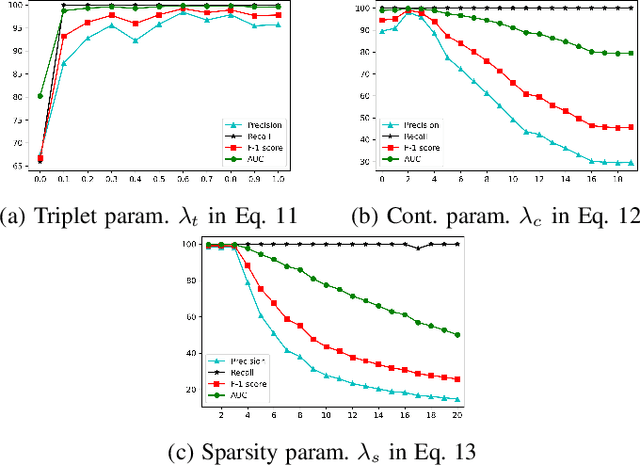
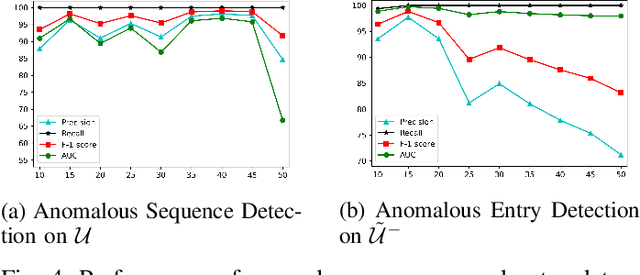
Anomaly detection in sequential data has been studied for a long time because of its potential in various applications, such as detecting abnormal system behaviors from log data. Although many approaches can achieve good performance on anomalous sequence detection, how to identify the anomalous entries in sequences is still challenging due to a lack of information at the entry-level. In this work, we propose a novel framework called CFDet for fine-grained anomalous entry detection. CFDet leverages the idea of interpretable machine learning. Given a sequence that is detected as anomalous, we can consider anomalous entry detection as an interpretable machine learning task because identifying anomalous entries in the sequence is to provide an interpretation to the detection result. We make use of the deep support vector data description (Deep SVDD) approach to detect anomalous sequences and propose a novel counterfactual interpretation-based approach to identify anomalous entries in the sequences. Experimental results on three datasets show that CFDet can correctly detect anomalous entries.
Adaptive Fairness-Aware Online Meta-Learning for Changing Environments
May 26, 2022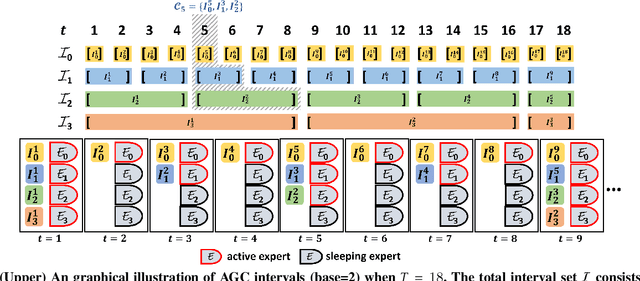

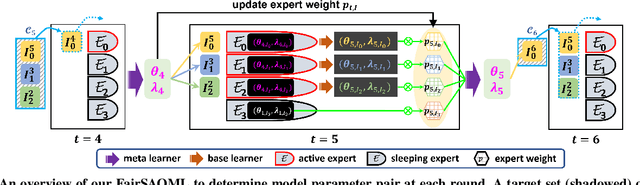

The fairness-aware online learning framework has arisen as a powerful tool for the continual lifelong learning setting. The goal for the learner is to sequentially learn new tasks where they come one after another over time and the learner ensures the statistic parity of the new coming task across different protected sub-populations (e.g. race and gender). A major drawback of existing methods is that they make heavy use of the i.i.d assumption for data and hence provide static regret analysis for the framework. However, low static regret cannot imply a good performance in changing environments where tasks are sampled from heterogeneous distributions. To address the fairness-aware online learning problem in changing environments, in this paper, we first construct a novel regret metric FairSAR by adding long-term fairness constraints onto a strongly adapted loss regret. Furthermore, to determine a good model parameter at each round, we propose a novel adaptive fairness-aware online meta-learning algorithm, namely FairSAOML, which is able to adapt to changing environments in both bias control and model precision. The problem is formulated in the form of a bi-level convex-concave optimization with respect to the model's primal and dual parameters that are associated with the model's accuracy and fairness, respectively. The theoretic analysis provides sub-linear upper bounds for both loss regret and violation of cumulative fairness constraints. Our experimental evaluation on different real-world datasets with settings of changing environments suggests that the proposed FairSAOML significantly outperforms alternatives based on the best prior online learning approaches.
Trustworthy Anomaly Detection: A Survey
Feb 15, 2022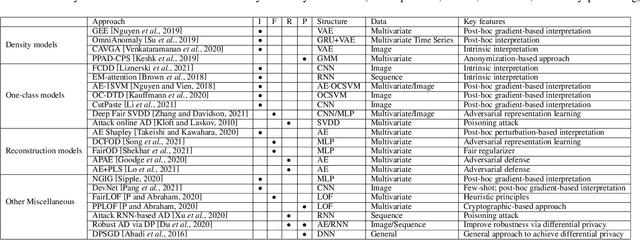
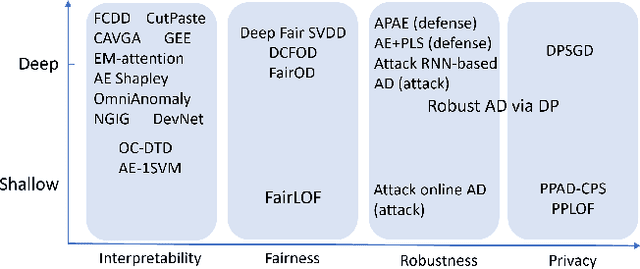
Anomaly detection has a wide range of real-world applications, such as bank fraud detection and cyber intrusion detection. In the past decade, a variety of anomaly detection models have been developed, which lead to big progress towards accurately detecting various anomalies. Despite the successes, anomaly detection models still face many limitations. The most significant one is whether we can trust the detection results from the models. In recent years, the research community has spent a great effort to design trustworthy machine learning models, such as developing trustworthy classification models. However, the attention to anomaly detection tasks is far from sufficient. Considering that many anomaly detection tasks are life-changing tasks involving human beings, labeling someone as anomalies or fraudsters should be extremely cautious. Hence, ensuring the anomaly detection models conducted in a trustworthy fashion is an essential requirement to deploy the models to conduct automatic decisions in the real world. In this brief survey, we summarize the existing efforts and discuss open problems towards trustworthy anomaly detection from the perspectives of interpretability, fairness, robustness, and privacy-preservation.
Model Transferring Attacks to Backdoor HyperNetwork in Personalized Federated Learning
Jan 19, 2022



This paper explores previously unknown backdoor risks in HyperNet-based personalized federated learning (HyperNetFL) through poisoning attacks. Based upon that, we propose a novel model transferring attack (called HNTROJ), i.e., the first of its kind, to transfer a local backdoor infected model to all legitimate and personalized local models, which are generated by the HyperNetFL model, through consistent and effective malicious local gradients computed across all compromised clients in the whole training process. As a result, HNTROJ reduces the number of compromised clients needed to successfully launch the attack without any observable signs of sudden shifts or degradation regarding model utility on legitimate data samples making our attack stealthy. To defend against HNTROJ, we adapted several backdoor-resistant FL training algorithms into HyperNetFL. An extensive experiment that is carried out using several benchmark datasets shows that HNTROJ significantly outperforms data poisoning and model replacement attacks and bypasses robust training algorithms.
The Fairness Field Guide: Perspectives from Social and Formal Sciences
Jan 13, 2022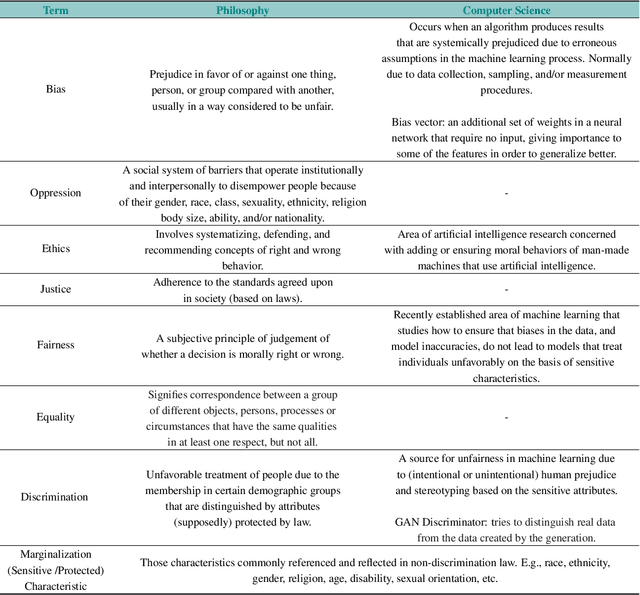

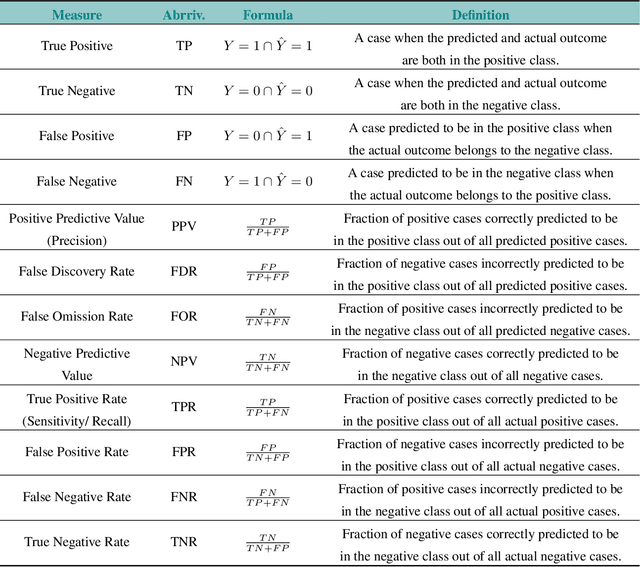
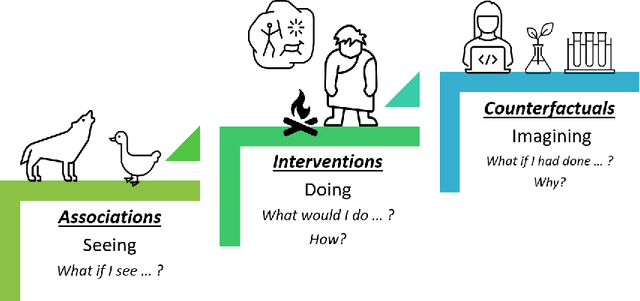
Over the past several years, a slew of different methods to measure the fairness of a machine learning model have been proposed. However, despite the growing number of publications and implementations, there is still a critical lack of literature that explains the interplay of fair machine learning with the social sciences of philosophy, sociology, and law. We hope to remedy this issue by accumulating and expounding upon the thoughts and discussions of fair machine learning produced by both social and formal (specifically machine learning and statistics) sciences in this field guide. Specifically, in addition to giving the mathematical and algorithmic backgrounds of several popular statistical and causal-based fair machine learning methods, we explain the underlying philosophical and legal thoughts that support them. Further, we explore several criticisms of the current approaches to fair machine learning from sociological and philosophical viewpoints. It is our hope that this field guide will help fair machine learning practitioners better understand how their algorithms align with important humanistic values (such as fairness) and how we can, as a field, design methods and metrics to better serve oppressed and marginalized populaces.
Poisoning Attacks on Fair Machine Learning
Oct 17, 2021
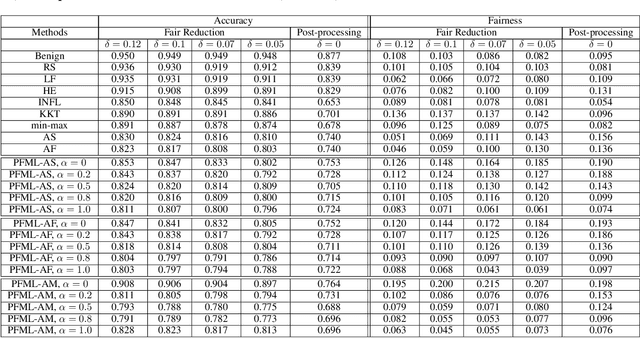
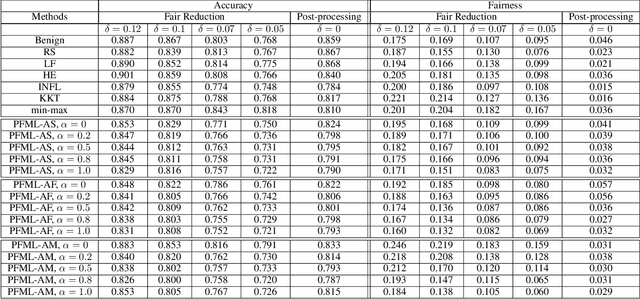
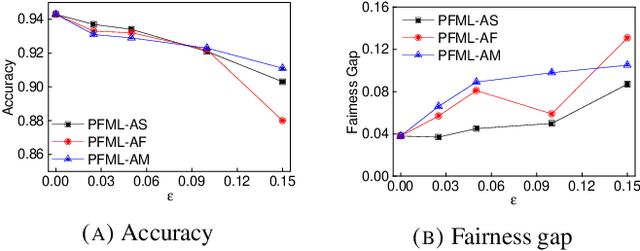
Both fair machine learning and adversarial learning have been extensively studied. However, attacking fair machine learning models has received less attention. In this paper, we present a framework that seeks to effectively generate poisoning samples to attack both model accuracy and algorithmic fairness. Our attacking framework can target fair machine learning models trained with a variety of group based fairness notions such as demographic parity and equalized odds. We develop three online attacks, adversarial sampling , adversarial labeling, and adversarial feature modification. All three attacks effectively and efficiently produce poisoning samples via sampling, labeling, or modifying a fraction of training data in order to reduce the test accuracy. Our framework enables attackers to flexibly adjust the attack's focus on prediction accuracy or fairness and accurately quantify the impact of each candidate point to both accuracy loss and fairness violation, thus producing effective poisoning samples. Experiments on two real datasets demonstrate the effectiveness and efficiency of our framework.
Fair Regression under Sample Selection Bias
Oct 08, 2021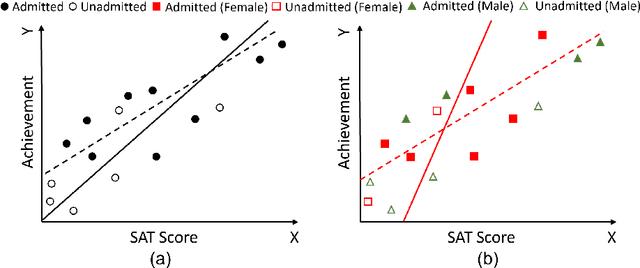

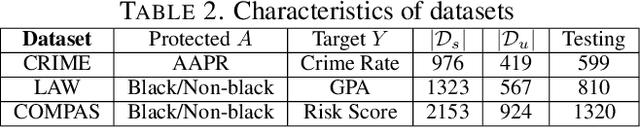
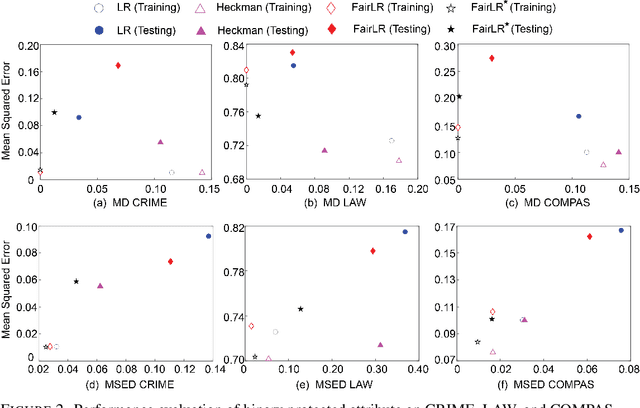
Recent research on fair regression focused on developing new fairness notions and approximation methods as target variables and even the sensitive attribute are continuous in the regression setting. However, all previous fair regression research assumed the training data and testing data are drawn from the same distributions. This assumption is often violated in real world due to the sample selection bias between the training and testing data. In this paper, we develop a framework for fair regression under sample selection bias when dependent variable values of a set of samples from the training data are missing as a result of another hidden process. Our framework adopts the classic Heckman model for bias correction and the Lagrange duality to achieve fairness in regression based on a variety of fairness notions. Heckman model describes the sample selection process and uses a derived variable called the Inverse Mills Ratio (IMR) to correct sample selection bias. We use fairness inequality and equality constraints to describe a variety of fairness notions and apply the Lagrange duality theory to transform the primal problem into the dual convex optimization. For the two popular fairness notions, mean difference and mean squared error difference, we derive explicit formulas without iterative optimization, and for Pearson correlation, we derive its conditions of achieving strong duality. We conduct experiments on three real-world datasets and the experimental results demonstrate the approach's effectiveness in terms of both utility and fairness metrics.
Achieving Counterfactual Fairness for Causal Bandit
Sep 21, 2021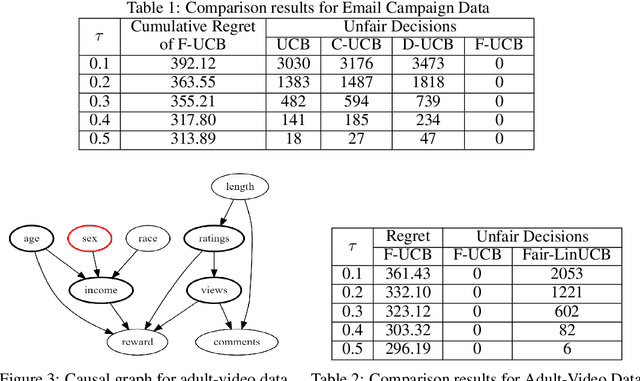
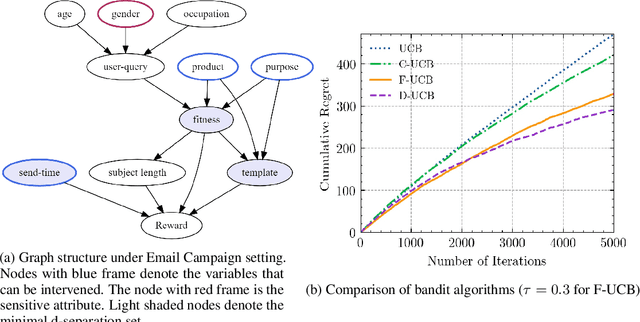


In online recommendation, customers arrive in a sequential and stochastic manner from an underlying distribution and the online decision model recommends a chosen item for each arriving individual based on some strategy. We study how to recommend an item at each step to maximize the expected reward while achieving user-side fairness for customers, i.e., customers who share similar profiles will receive a similar reward regardless of their sensitive attributes and items being recommended. By incorporating causal inference into bandits and adopting soft intervention to model the arm selection strategy, we first propose the d-separation based UCB algorithm (D-UCB) to explore the utilization of the d-separation set in reducing the amount of exploration needed to achieve low cumulative regret. Based on that, we then propose the fair causal bandit (F-UCB) for achieving the counterfactual individual fairness. Both theoretical analysis and empirical evaluation demonstrate effectiveness of our algorithms.
MathBERT: A Pre-trained Language Model for General NLP Tasks in Mathematics Education
Jun 02, 2021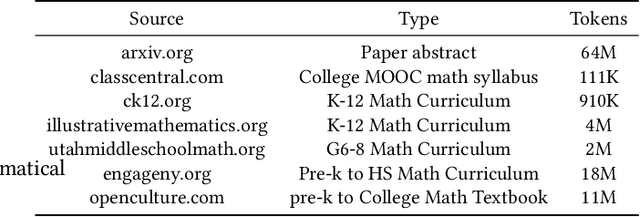
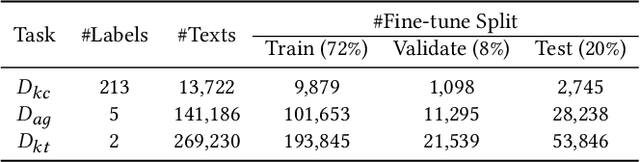
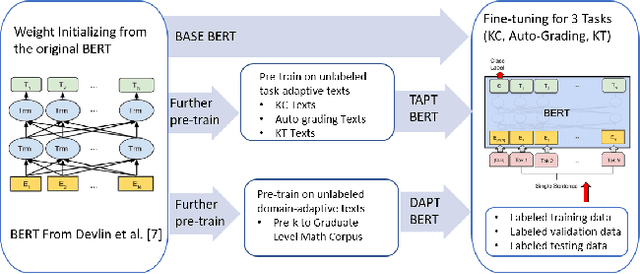
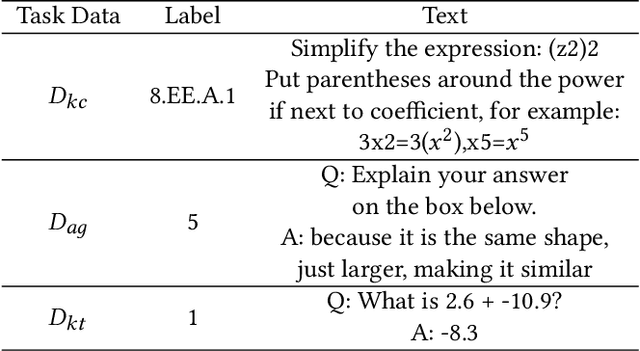
Due to the transfer learning nature of BERT model, researchers have achieved better performance than base BERT by further pre-training the original BERT on a huge domain-specific corpus. Due to the special nature of mathematical texts which often contain math equations and symbols, the original BERT model pre-trained on general English context will not fit Natural Language Processing (NLP) tasks in mathematical education well. Therefore, we propose MathBERT, a BERT pre-trained on large mathematical corpus including pre-k to graduate level mathematical content to tackle math-specific tasks. In addition, We generate a customized mathematical vocabulary to pre-train with MathBERT and compare the performance to the MathBERT pre-trained with the original BERT vocabulary. We select three important tasks in mathematical education such as knowledge component, auto-grading, and knowledge tracing prediction to evaluate the performance of MathBERT. Our experiments show that MathBERT outperforms the base BERT by 2-9\% margin. In some cases, MathBERT pre-trained with mathematical vocabulary is better than MathBERT trained with original vocabulary.To our best knowledge, MathBERT is the first pre-trained model for general purpose mathematics education tasks.