 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Shape Representations for Clothing Variations in Person Re-Identification
Mar 16, 2020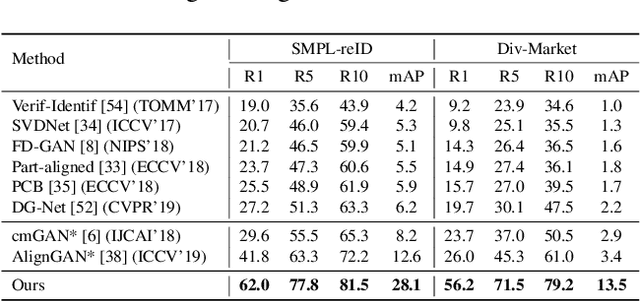

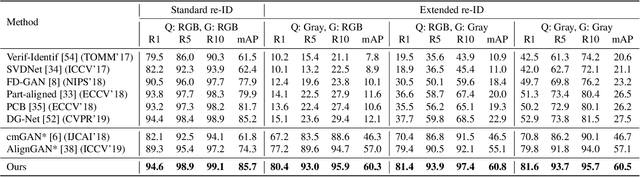

Person re-identification (re-ID) aims to recognize instances of the same person contained in multiple images taken across different cameras. Existing methods for re-ID tend to rely heavily on the assumption that both query and gallery images of the same person have the same clothing. Unfortunately, this assumption may not hold for datasets captured over long periods of time (e.g., weeks, months or years). To tackle the re-ID problem in the context of clothing changes, we propose a novel representation learning model which is able to generate a body shape feature representation without being affected by clothing color or patterns. We call our model the Color Agnostic Shape Extraction Network (CASE-Net). CASE-Net learns a representation of identity that depends only on body shape via adversarial learning and feature disentanglement. Due to the lack of large-scale re-ID datasets which contain clothing changes for the same person, we propose two synthetic datasets for evaluation. We create a rendered dataset SMPL-reID with different clothes patterns and a synthesized dataset Div-Market with different clothing color to simulate two types of clothing changes. The quantitative and qualitative results across 5 datasets (SMPL-reID, Div-Market, two benchmark re-ID datasets, a cross-modality re-ID dataset) confirm the robustness and superiority of our approach against several state-of-the-art approaches
A Baseline for 3D Multi-Object Tracking
Aug 05, 2019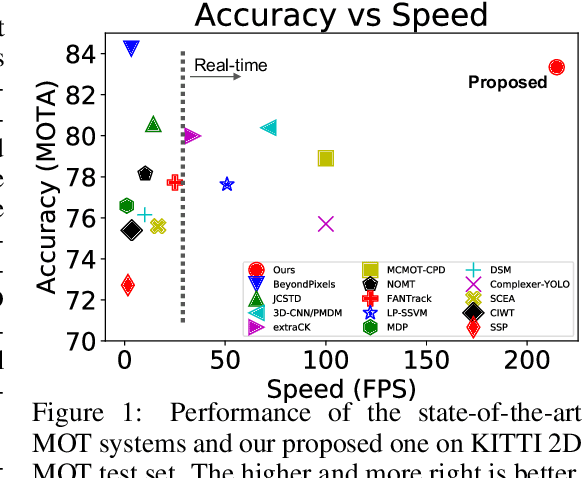
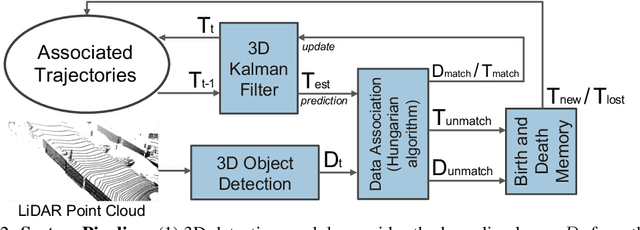
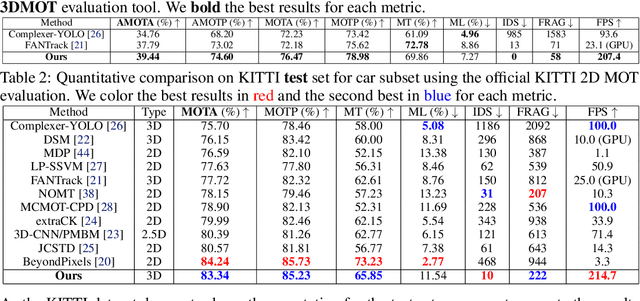
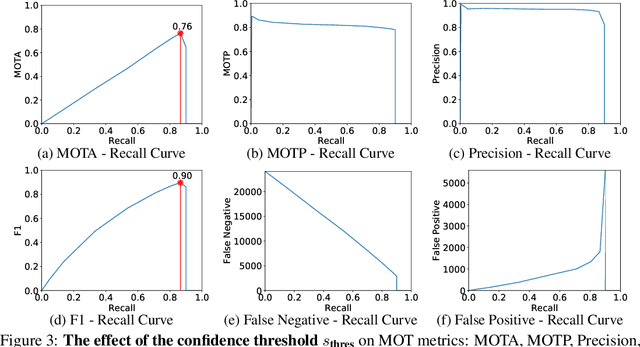
3D multi-object tracking (MOT) is an essential component technology for many real-time applications such as autonomous driving or assistive robotics. However, recent works for 3D MOT tend to focus more on developing accurate systems giving less regard to computational cost and system complexity. In contrast, this work proposes a simple yet accurate real-time baseline 3D MOT system. We use an off-the-shelf 3D object detector to obtain oriented 3D bounding boxes from the LiDAR point cloud. Then, a combination of 3D Kalman filter and Hungarian algorithm is used for state estimation and data association. Although our baseline system is a straightforward combination of standard methods, we obtain the state-of-the-art results. To evaluate our baseline system, we propose a new 3D MOT extension to the official KITTI 2D MOT evaluation along with two new metrics. Our proposed baseline method for 3D MOT establishes new state-of-the-art performance on 3D MOT for KITTI, improving the 3D MOTA from 72.23 of prior art to 76.47. Surprisingly, by projecting our 3D tracking results to the 2D image plane and compare against published 2D MOT methods, our system places 2nd on the official KITTI leaderboard. Also, our proposed 3D MOT method runs at a rate of 214.7 FPS, 65 times faster than the state-of-the-art 2D MOT system. Our code is publicly available at https://github.com/xinshuoweng/AB3DMOT
Learning Spatio-Temporal Features with Two-Stream Deep 3D CNNs for Lipreading
May 04, 2019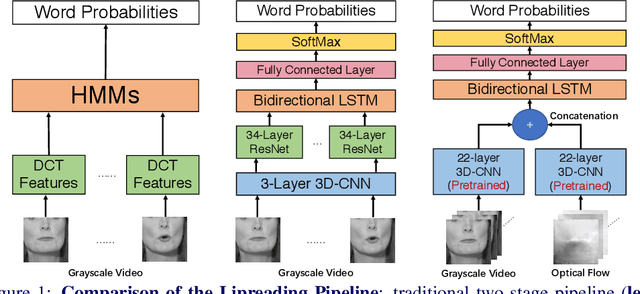
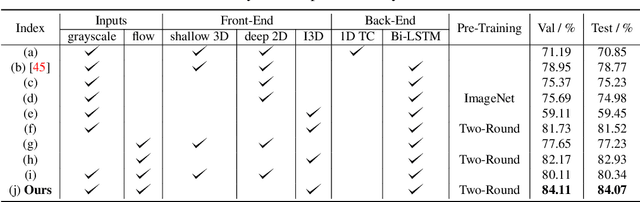
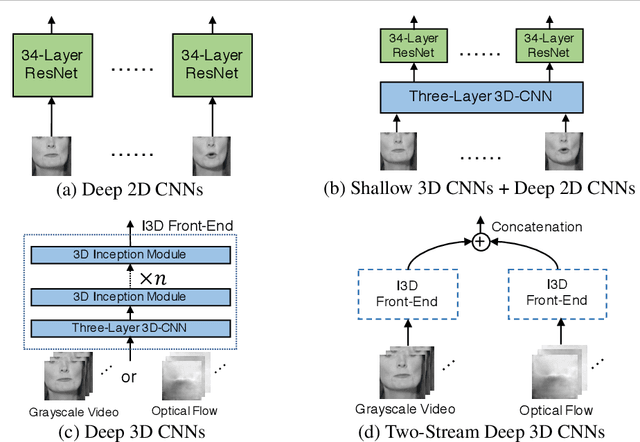
We focus on the word-level visual lipreading, which requires recognizing the word being spoken, given only the video but not the audio. State-of-the-art methods explore the use of end-to-end neural networks, including a shallow (up to three layers) 3D convolutional neural network (CNN) + a deep 2D CNN (\emph{e.g.}, ResNet) as the front-end to extract visual features, and a recurrent neural network (\emph{e.g.}, bidirectional LSTM) as the back-end for classification. In this work, we propose to replace the shallow 3D CNNs + deep 2D CNNs front-end with recent successful deep 3D CNNs --- two-stream (\emph{i.e.}, grayscale video and optical flow streams) I3D. We evaluate different combinations of front-end and back-end modules with the grayscale video and optical flow inputs on the LRW dataset. The experiments show that, compared to the shallow 3D CNNs + deep 2D CNNs front-end, the deep 3D CNNs front-end with pre-training on the large-scale image and video datasets (\emph{e.g.}, ImageNet and Kinetics) can improve the classification accuracy. On the other hand, we demonstrate that using the optical flow input alone can achieve comparable performance as using the grayscale video as input. Moreover, the two-stream network using both the grayscale video and optical flow inputs can further improve the performance. Overall, our two-stream I3D front-end with a Bi-LSTM back-end results in an absolute improvement of 5.3\% over the previous art.
Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud
Mar 31, 2019
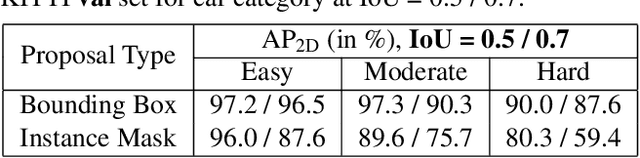
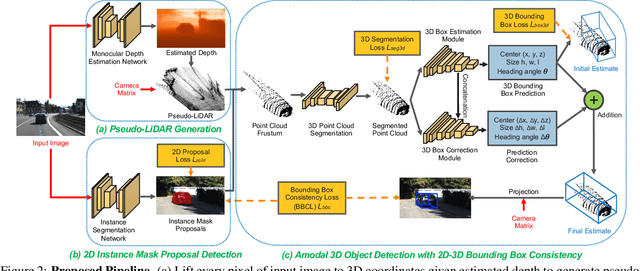

Monocular 3D scene understanding tasks, such as object size estimation, heading angle estimation and 3D localization, is challenging. Successful modern day methods for 3D scene understanding require the use of a 3D sensor such as a depth camera, a stereo camera or LiDAR. On the other hand, single image based methods have significantly worse performance, but rightly so, as there is little explicit depth information in a 2D image. In this work, we aim at bridging the performance gap between 3D sensing and 2D sensing for 3D object detection by enhancing LiDAR-based algorithms to work with single image input. Specifically, we perform monocular depth estimation and lift the input image to a point cloud representation, which we call pseudo-LiDAR point cloud. Then we can train a LiDAR-based 3D detection network with our pseudo-LiDAR end-to-end. Following the pipeline of two-stage 3D detection algorithms, we detect 2D object proposals in the input image and extract a point cloud frustum from the pseudo-LiDAR for each proposal. Then an oriented 3D bounding box is detected for each frustum. To handle the large amount of noise in the pseudo-LiDAR, we propose two innovations: (1) use a 2D-3D bounding box consistency constraint, adjusting the predicted 3D bounding box to have a high overlap with its corresponding 2D proposal after projecting onto the image; (2) use the instance mask instead of the bounding box as the representation of 2D proposals, in order to reduce the number of points not belonging to the object in the point cloud frustum. Through our evaluation on the KITTI benchmark, we achieve the top-ranked performance on both bird's eye view and 3D object detection among all monocular methods, effectively quadrupling the performance over previous state-of-the-art.
On the Importance of Video Action Recognition for Visual Lipreading
Mar 22, 2019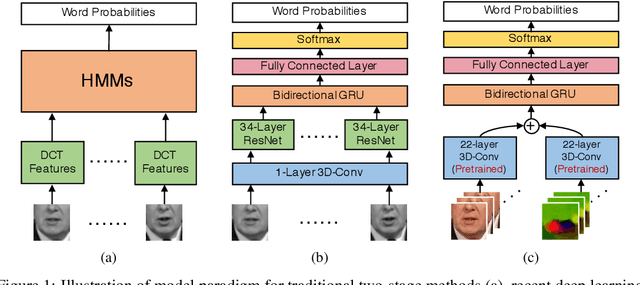
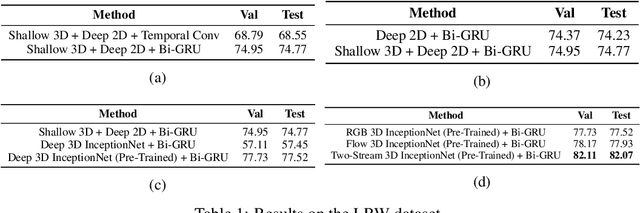
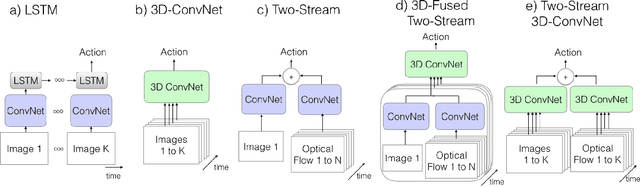
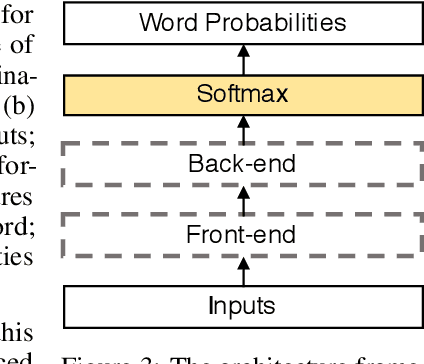
We focus on the word-level visual lipreading, which requires to decode the word from the speaker's video. Recently, many state-of-the-art visual lipreading methods explore the end-to-end trainable deep models, involving the use of 2D convolutional networks (e.g., ResNet) as the front-end visual feature extractor and the sequential model (e.g., Bi-LSTM or Bi-GRU) as the back-end. Although a deep 2D convolution neural network can provide informative image-based features, it ignores the temporal motion existing between the adjacent frames. In this work, we investigate the spatial-temporal capacity power of I3D (Inflated 3D ConvNet) for visual lipreading. We demonstrate that, after pre-trained on the large-scale video action recognition dataset (e.g., Kinetics), our models show a considerable improvement of performance on the task of lipreading. A comparison between a set of video model architectures and input data representation is also reported. Our extensive experiments on LRW shows that a two-stream I3D model with RGB video and optical flow as the inputs achieves the state-of-the-art performance.
Future Near-Collision Prediction from Monocular Video: Feasibility, Dataset, and Challenges
Mar 21, 2019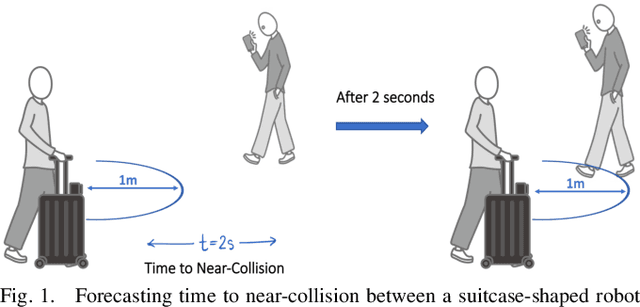

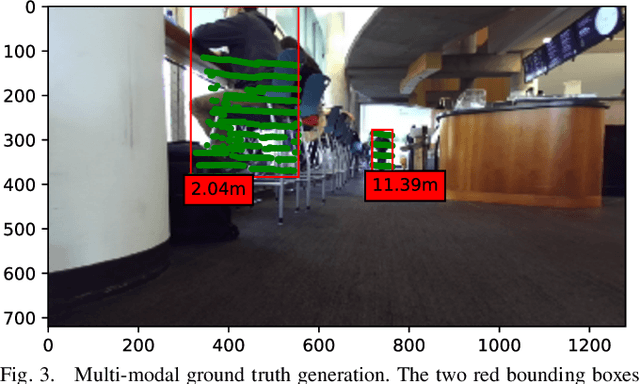
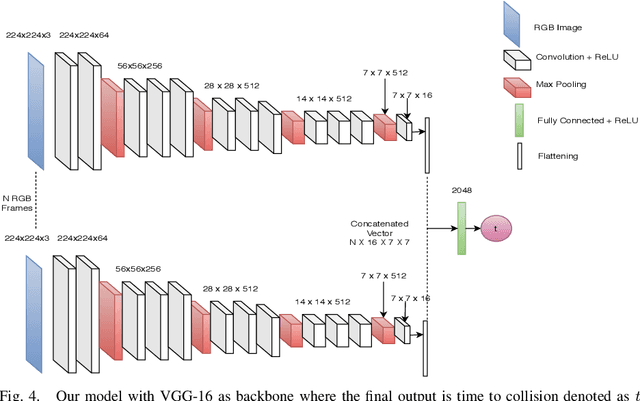
We explore the possibility of using a single monocular camera to forecast the time to collision between a suitcase-shaped robot being pushed by its user and other nearby pedestrians. We develop a purely image-based deep learning approach that directly estimates the time to collision without the need of relying on explicit geometric depth estimates or velocity information to predict future collisions. While previous work has focused on detecting immediate collision in the context of navigating Unmanned Aerial Vehicles, the detection was limited to a binary variable (i.e., collision or no collision). We propose a more fine-grained approach to collision forecasting by predicting the exact time to collision in terms of milliseconds, which is more helpful for collision avoidance in the context of dynamic path planning. To evaluate our method, we have collected a novel large-scale dataset of over 13,000 indoor video segments each showing a trajectory of at least one person ending in a close proximity (a near collision) with the camera mounted on a mobile suitcase-shaped platform. Using this dataset, we do extensive experimentation on different temporal windows as input using an exhaustive list of state-of-the-art convolutional neural networks (CNNs). Our results show that our proposed multi-stream CNN is the best model for predicting time to near-collision. The average prediction error of our time to near collision is 0.75 seconds across our test environments.
Deep Reinforcement Learning for Autonomous Driving
Mar 19, 2019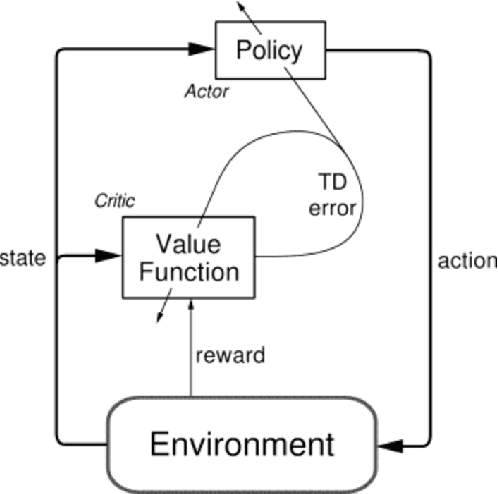
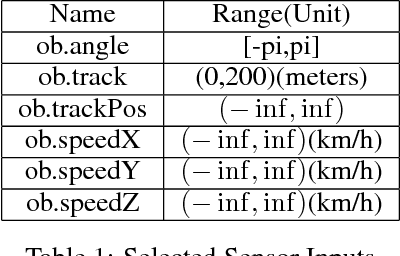
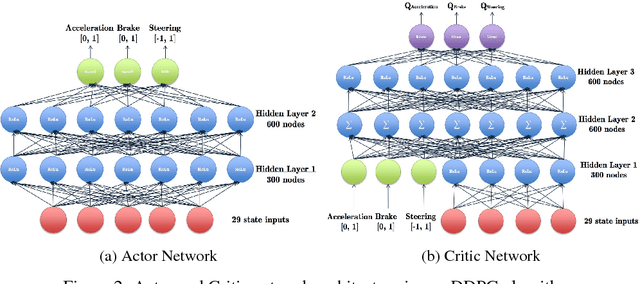
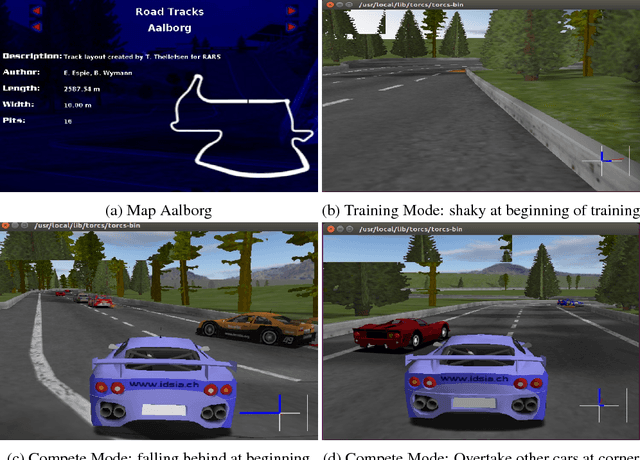
Reinforcement learning has steadily improved and outperform human in lots of traditional games since the resurgence of deep neural network. However, these success is not easy to be copied to autonomous driving because the state spaces in real world are extreme complex and action spaces are continuous and fine control is required. Moreover, the autonomous driving vehicles must also keep functional safety under the complex environments. To deal with these challenges, we first adopt the deep deterministic policy gradient (DDPG) algorithm, which has the capacity to handle complex state and action spaces in continuous domain. We then choose The Open Racing Car Simulator (TORCS) as our environment to avoid physical damage. Meanwhile, we select a set of appropriate sensor information from TORCS and design our own rewarder. In order to fit DDPG algorithm to TORCS, we design our network architecture for both actor and critic inside DDPG paradigm. To demonstrate the effectiveness of our model, We evaluate on different modes in TORCS and show both quantitative and qualitative results.
CyLKs: Unsupervised Cycle Lucas-Kanade Network for Landmark Tracking
Nov 28, 2018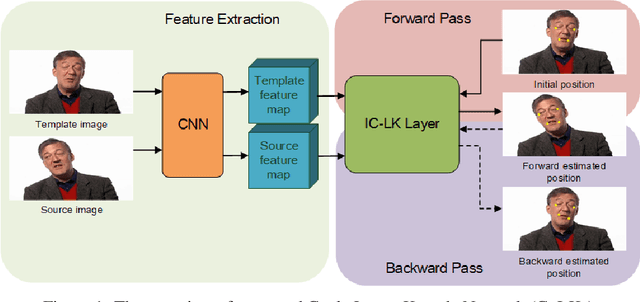

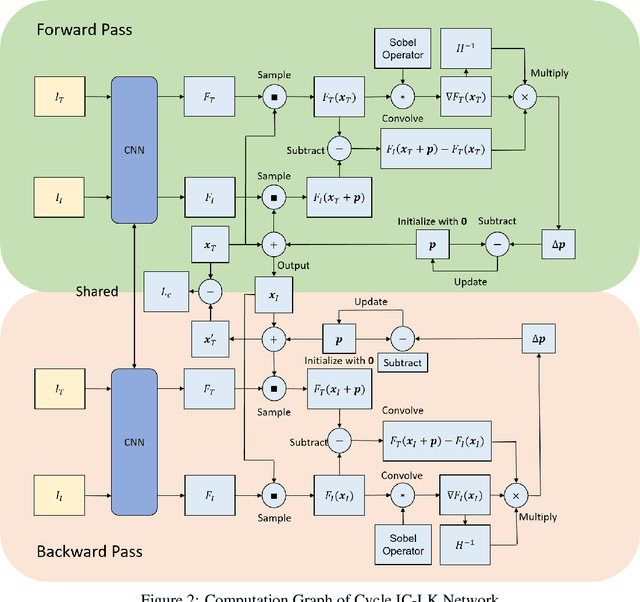

Across a majority of modern learning-based tracking systems, expensive annotations are needed to achieve state-of-the-art performance. In contrast, the Lucas-Kanade (LK) algorithm works well without any annotation. However, LK has a strong assumption of photometric (brightness) consistency on image intensity and is easy to drift because of large motion, occlusion, and aperture problem. To relax the assumption and alleviate the drift problem, we propose CyLKs, a data-driven way of training Lucas-Kanade in an unsupervised manner. CyLKs learns a feature transformation through CNNs, transforming the input images to a feature space which is especially favorable to LK tracking. During training, we perform differentiable Lucas-Kanade forward and backward on the convolutional feature maps, and then minimize the re-projection error. During testing, we perform the LK tracking on the learned features. We apply our model to the task of landmark tracking and perform experiments on datasets of THUMOS, 300VW, and Mugsy.
Image Labeling with Markov Random Fields and Conditional Random Fields
Nov 28, 2018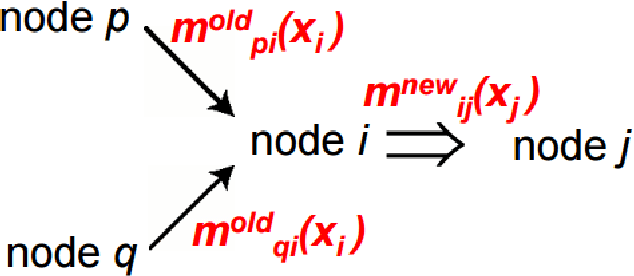

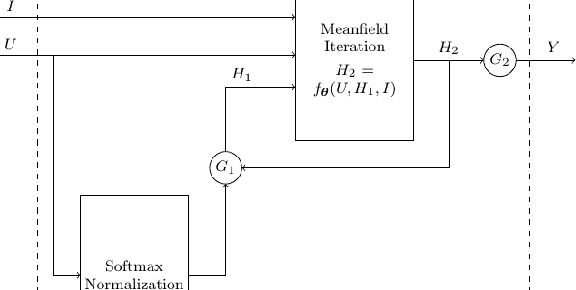
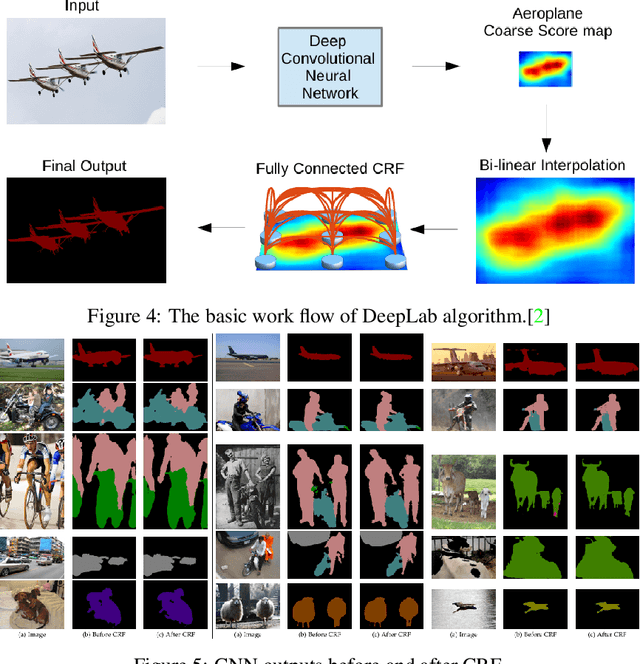
Most existing methods for object segmentation in computer vision are formulated as a labeling task. This, in general, could be transferred to a pixel-wise label assignment task, which is quite similar to the structure of hidden Markov random field. In terms of Markov random field, each pixel can be regarded as a state and has a transition probability to its neighbor pixel, the label behind each pixel is a latent variable and has an emission probability from its corresponding state. In this paper, we reviewed several modern image labeling methods based on Markov random field and conditional random Field. And we compare the result of these methods with some classical image labeling methods. The experiment demonstrates that the introduction of Markov random field and conditional random field make a big difference in the segmentation result.
GroundNet: Segmentation-Aware Monocular Ground Plane Estimation with Geometric Consistency
Nov 17, 2018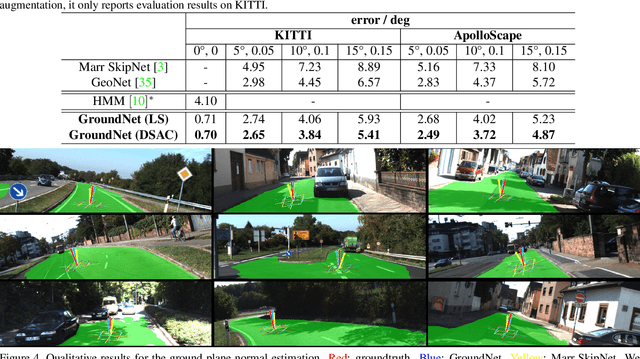
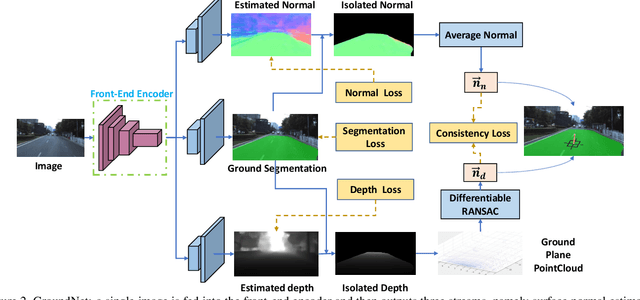
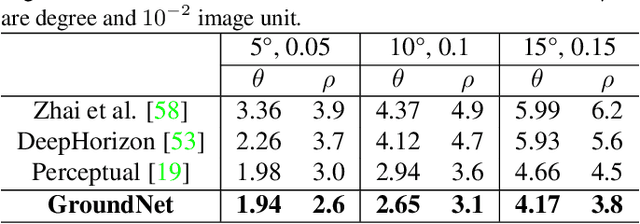
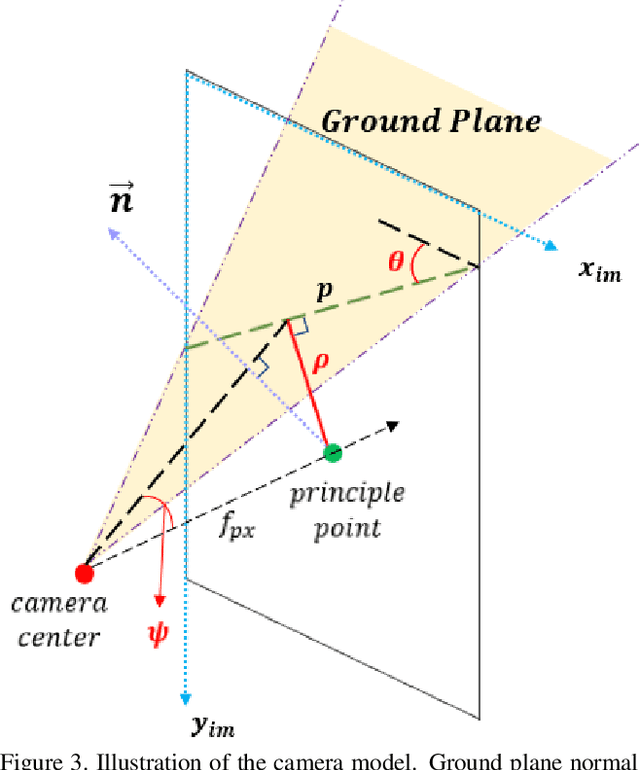
We focus on the problem of estimating the orientation of the ground plane with respect to a mobile monocular camera platform (e.g., ground robot, wearable camera, assistive robotic platform). To address this problem, we formulate the ground plane estimation problem as an inter-mingled multi-task prediction problem by jointly optimizing for point-wise surface normal direction, 2D ground segmentation, and depth estimates. Our proposed model -- GroundNet -- estimates the ground normal in two streams separately and then a consistency loss is applied on top of the two streams to enforce geometric consistency. A semantic segmentation stream is used to isolate the ground regions and are used to selectively back-propagate parameter updates only through the ground regions in the image. Our experiments on KITTI and ApolloScape datasets verify that the GroundNet is able to predict consistent depth and normal within the ground region. It also achieves top performance on ground plane normal estimation and horizon line detection.