 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSheaf HyperNetworks for Personalized Federated Learning
May 31, 2024



Graph hypernetworks (GHNs), constructed by combining graph neural networks (GNNs) with hypernetworks (HNs), leverage relational data across various domains such as neural architecture search, molecular property prediction and federated learning. Despite GNNs and HNs being individually successful, we show that GHNs present problems compromising their performance, such as over-smoothing and heterophily. Moreover, we cannot apply GHNs directly to personalized federated learning (PFL) scenarios, where a priori client relation graph may be absent, private, or inaccessible. To mitigate these limitations in the context of PFL, we propose a novel class of HNs, sheaf hypernetworks (SHNs), which combine cellular sheaf theory with HNs to improve parameter sharing for PFL. We thoroughly evaluate SHNs across diverse PFL tasks, including multi-class classification, traffic and weather forecasting. Additionally, we provide a methodology for constructing client relation graphs in scenarios where such graphs are unavailable. We show that SHNs consistently outperform existing PFL solutions in complex non-IID scenarios. While the baselines' performance fluctuates depending on the task, SHNs show improvements of up to 2.7% in accuracy and 5.3% in lower mean squared error over the best-performing baseline.
The Future of Large Language Model Pre-training is Federated
May 17, 2024



Generative pre-trained large language models (LLMs) have demonstrated impressive performance over a wide range of tasks, thanks to the unprecedented amount of data they have been trained on. As established scaling laws indicate, LLMs' future performance improvement depends on the amount of computing and data sources we can leverage for pre-training. Federated learning (FL) has the potential to unleash the majority of the planet's data and computational resources, which are underutilized by the data-center-focused training methodology of current LLM practice. Our work presents a robust, flexible, reproducible FL approach that enables large-scale collaboration across institutions to train LLMs. This would mobilize more computational and data resources while matching or potentially exceeding centralized performance. We further show the effectiveness of the federated training scales with model size and present our approach for training a billion-scale federated LLM using limited resources. This will help data-rich actors to become the protagonists of LLMs pre-training instead of leaving the stage to compute-rich actors alone.
FedAnchor: Enhancing Federated Semi-Supervised Learning with Label Contrastive Loss for Unlabeled Clients
Feb 15, 2024Federated learning (FL) is a distributed learning paradigm that facilitates collaborative training of a shared global model across devices while keeping data localized. The deployment of FL in numerous real-world applications faces delays, primarily due to the prevalent reliance on supervised tasks. Generating detailed labels at edge devices, if feasible, is demanding, given resource constraints and the imperative for continuous data updates. In addressing these challenges, solutions such as federated semi-supervised learning (FSSL), which relies on unlabeled clients' data and a limited amount of labeled data on the server, become pivotal. In this paper, we propose FedAnchor, an innovative FSSL method that introduces a unique double-head structure, called anchor head, paired with the classification head trained exclusively on labeled anchor data on the server. The anchor head is empowered with a newly designed label contrastive loss based on the cosine similarity metric. Our approach mitigates the confirmation bias and overfitting issues associated with pseudo-labeling techniques based on high-confidence model prediction samples. Extensive experiments on CIFAR10/100 and SVHN datasets demonstrate that our method outperforms the state-of-the-art method by a significant margin in terms of convergence rate and model accuracy.
FedL2P: Federated Learning to Personalize
Oct 03, 2023
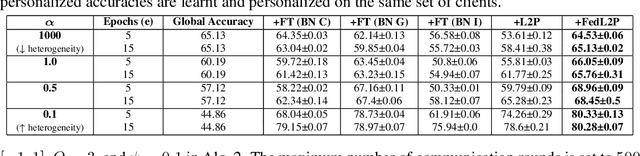
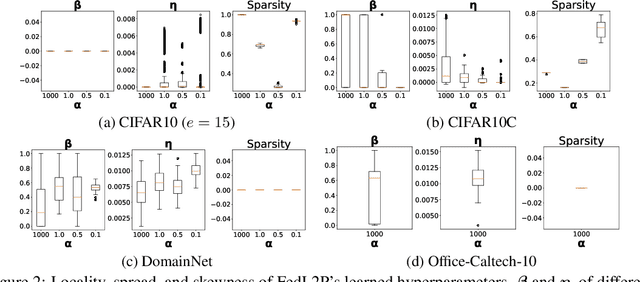
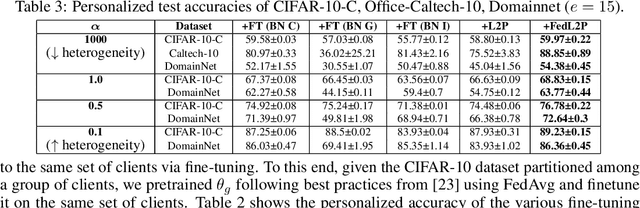
Federated learning (FL) research has made progress in developing algorithms for distributed learning of global models, as well as algorithms for local personalization of those common models to the specifics of each client's local data distribution. However, different FL problems may require different personalization strategies, and it may not even be possible to define an effective one-size-fits-all personalization strategy for all clients: depending on how similar each client's optimal predictor is to that of the global model, different personalization strategies may be preferred. In this paper, we consider the federated meta-learning problem of learning personalization strategies. Specifically, we consider meta-nets that induce the batch-norm and learning rate parameters for each client given local data statistics. By learning these meta-nets through FL, we allow the whole FL network to collaborate in learning a customized personalization strategy for each client. Empirical results show that this framework improves on a range of standard hand-crafted personalization baselines in both label and feature shift situations.
FedVal: Different good or different bad in federated learning
Jun 06, 2023Federated learning (FL) systems are susceptible to attacks from malicious actors who might attempt to corrupt the training model through various poisoning attacks. FL also poses new challenges in addressing group bias, such as ensuring fair performance for different demographic groups. Traditional methods used to address such biases require centralized access to the data, which FL systems do not have. In this paper, we present a novel approach FedVal for both robustness and fairness that does not require any additional information from clients that could raise privacy concerns and consequently compromise the integrity of the FL system. To this end, we propose an innovative score function based on a server-side validation method that assesses client updates and determines the optimal aggregation balance between locally-trained models. Our research shows that this approach not only provides solid protection against poisoning attacks but can also be used to reduce group bias and subsequently promote fairness while maintaining the system's capability for differential privacy. Extensive experiments on the CIFAR-10, FEMNIST, and PUMS ACSIncome datasets in different configurations demonstrate the effectiveness of our method, resulting in state-of-the-art performances. We have proven robustness in situations where 80% of participating clients are malicious. Additionally, we have shown a significant increase in accuracy for underrepresented labels from 32% to 53%, and increase in recall rate for underrepresented features from 19% to 50%.
vFedSec: Efficient Secure Aggregation for Vertical Federated Learning via Secure Layer
May 26, 2023Most work in privacy-preserving federated learning (FL) has been focusing on horizontally partitioned datasets where clients share the same sets of features and can train complete models independently. However, in many interesting problems, individual data points are scattered across different clients/organizations in a vertical setting. Solutions for this type of FL require the exchange of intermediate outputs and gradients between participants, posing a potential risk of privacy leakage when privacy and security concerns are not considered. In this work, we present vFedSec - a novel design with an innovative Secure Layer for training vertical FL securely and efficiently using state-of-the-art security modules in secure aggregation. We theoretically demonstrate that our method does not impact the training performance while protecting private data effectively. Empirically results also show its applicability with extensive experiments that our design can achieve the protection with negligible computation and communication overhead. Also, our method can obtain 9.1e2 ~ 3.8e4 speedup compared to widely-adopted homomorphic encryption (HE) method.
EXACT: Extensive Attack for Split Learning
May 25, 2023



Privacy-Preserving machine learning (PPML) can help us train and deploy models that utilize private information. In particular, on-device Machine Learning allows us to completely avoid sharing information with a third-party server during inference. However, on-device models are typically less accurate when compared to the server counterparts due to the fact that (1) they typically only rely on a small set of on-device features and (2) they need to be small enough to run efficiently on end-user devices. Split Learning (SL) is a promising approach that can overcome these limitations. In SL, a large machine learning model is divided into two parts, with the bigger part residing on the server-side and a smaller part executing on-device, aiming to incorporate the private features. However, end-to-end training of such models requires exchanging gradients at the cut layer, which might encode private features or labels. In this paper, we provide insights into potential privacy risks associated with SL and introduce a novel attack method, EXACT, to reconstruct private information. Furthermore, we also investigate the effectiveness of various mitigation strategies. Our results indicate that the gradients significantly improve the attacker's effectiveness in all three datasets reaching almost 100% reconstruction accuracy for some features. However, a small amount of differential privacy (DP) is quite effective in mitigating this risk without causing significant training degradation.
Efficient Vertical Federated Learning with Secure Aggregation
May 18, 2023



The majority of work in privacy-preserving federated learning (FL) has been focusing on horizontally partitioned datasets where clients share the same sets of features and can train complete models independently. However, in many interesting problems, such as financial fraud detection and disease detection, individual data points are scattered across different clients/organizations in vertical federated learning. Solutions for this type of FL require the exchange of gradients between participants and rarely consider privacy and security concerns, posing a potential risk of privacy leakage. In this work, we present a novel design for training vertical FL securely and efficiently using state-of-the-art security modules for secure aggregation. We demonstrate empirically that our method does not impact training performance whilst obtaining 9.1e2 ~3.8e4 speedup compared to homomorphic encryption (HE).
Gradient-less Federated Gradient Boosting Trees with Learnable Learning Rates
May 02, 2023



The privacy-sensitive nature of decentralized datasets and the robustness of eXtreme Gradient Boosting (XGBoost) on tabular data raise the needs to train XGBoost in the context of federated learning (FL). Existing works on federated XGBoost in the horizontal setting rely on the sharing of gradients, which induce per-node level communication frequency and serious privacy concerns. To alleviate these problems, we develop an innovative framework for horizontal federated XGBoost which does not depend on the sharing of gradients and simultaneously boosts privacy and communication efficiency by making the learning rates of the aggregated tree ensembles learnable. We conduct extensive evaluations on various classification and regression datasets, showing our approach achieves performance comparable to the state-of-the-art method and effectively improves communication efficiency by lowering both communication rounds and communication overhead by factors ranging from 25x to 700x.
ZeroFL: Efficient On-Device Training for Federated Learning with Local Sparsity
Aug 04, 2022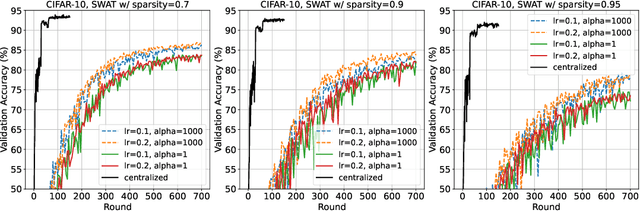
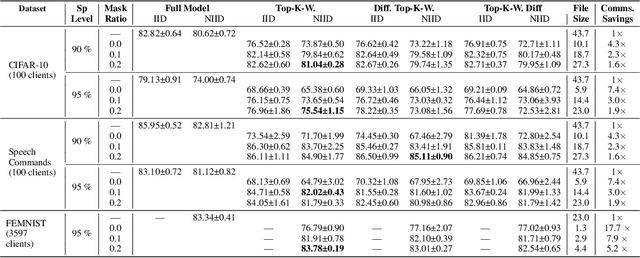
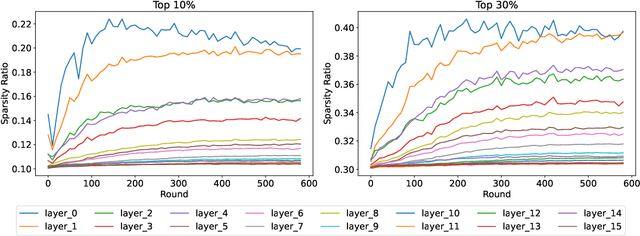
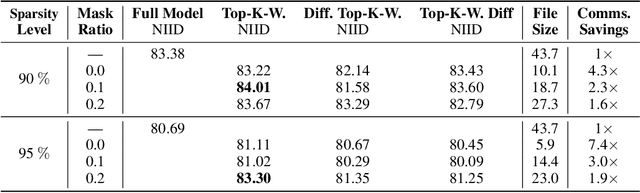
When the available hardware cannot meet the memory and compute requirements to efficiently train high performing machine learning models, a compromise in either the training quality or the model complexity is needed. In Federated Learning (FL), nodes are orders of magnitude more constrained than traditional server-grade hardware and are often battery powered, severely limiting the sophistication of models that can be trained under this paradigm. While most research has focused on designing better aggregation strategies to improve convergence rates and in alleviating the communication costs of FL, fewer efforts have been devoted to accelerating on-device training. Such stage, which repeats hundreds of times (i.e. every round) and can involve thousands of devices, accounts for the majority of the time required to train federated models and, the totality of the energy consumption at the client side. In this work, we present the first study on the unique aspects that arise when introducing sparsity at training time in FL workloads. We then propose ZeroFL, a framework that relies on highly sparse operations to accelerate on-device training. Models trained with ZeroFL and 95% sparsity achieve up to 2.3% higher accuracy compared to competitive baselines obtained from adapting a state-of-the-art sparse training framework to the FL setting.
* Published as a conference paper at ICLR 2022