 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFed-CPrompt: Contrastive Prompt for Rehearsal-Free Federated Continual Learning
Jul 10, 2023Federated continual learning (FCL) learns incremental tasks over time from confidential datasets distributed across clients. This paper focuses on rehearsal-free FCL, which has severe forgetting issues when learning new tasks due to the lack of access to historical task data. To address this issue, we propose Fed-CPrompt based on prompt learning techniques to obtain task-specific prompts in a communication-efficient way. Fed-CPrompt introduces two key components, asynchronous prompt learning, and contrastive continual loss, to handle asynchronous task arrival and heterogeneous data distributions in FCL, respectively. Extensive experiments demonstrate the effectiveness of Fed-CPrompt in achieving SOTA rehearsal-free FCL performance.
FedTiny: Pruned Federated Learning Towards Specialized Tiny Models
Dec 05, 2022



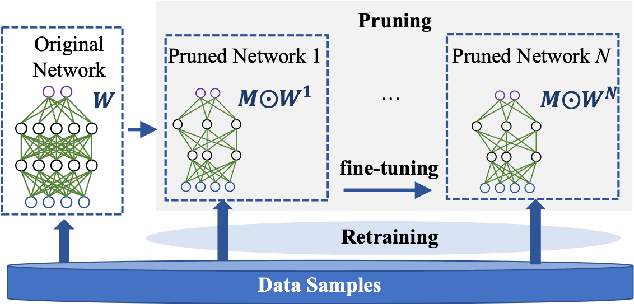
Neural network pruning has been a well-established compression technique to enable deep learning models on resource-constrained devices. The pruned model is usually specialized to meet specific hardware platforms and training tasks (defined as deployment scenarios). However, existing pruning approaches rely heavily on training data to trade off model size, efficiency, and accuracy, which becomes ineffective for federated learning (FL) over distributed and confidential datasets. Moreover, the memory- and compute-intensive pruning process of most existing approaches cannot be handled by most FL devices with resource limitations. In this paper, we develop FedTiny, a novel distributed pruning framework for FL, to obtain specialized tiny models for memory- and computing-constrained participating devices with confidential local data. To alleviate biased pruning due to unseen heterogeneous data over devices, FedTiny introduces an adaptive batch normalization (BN) selection module to adaptively obtain an initially pruned model to fit deployment scenarios. Besides, to further improve the initial pruning, FedTiny develops a lightweight progressive pruning module for local finer pruning under tight memory and computational budgets, where the pruning policy for each layer is gradually determined rather than evaluating the overall deep model structure. Extensive experimental results demonstrate the effectiveness of FedTiny, which outperforms state-of-the-art baseline approaches, especially when compressing deep models to extremely sparse tiny models.
Federated Semi-Supervised Domain Adaptation via Knowledge Transfer
Jul 25, 2022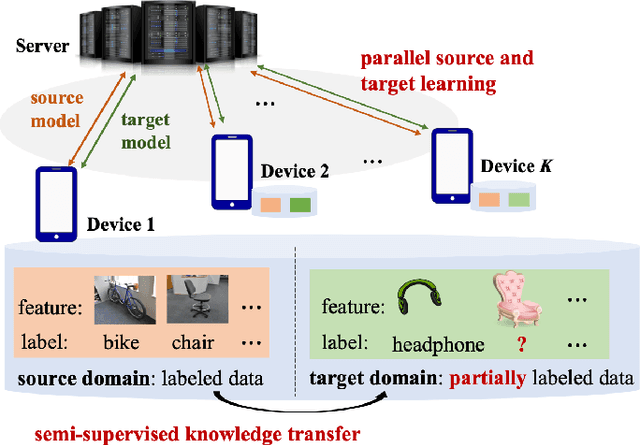
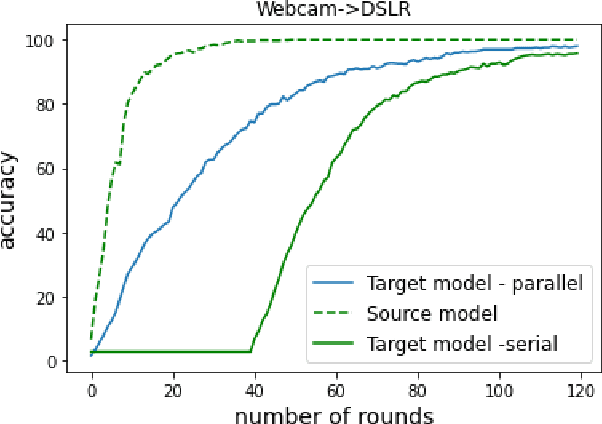
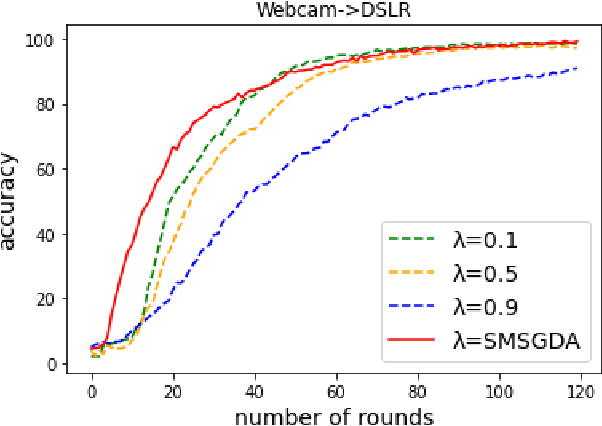
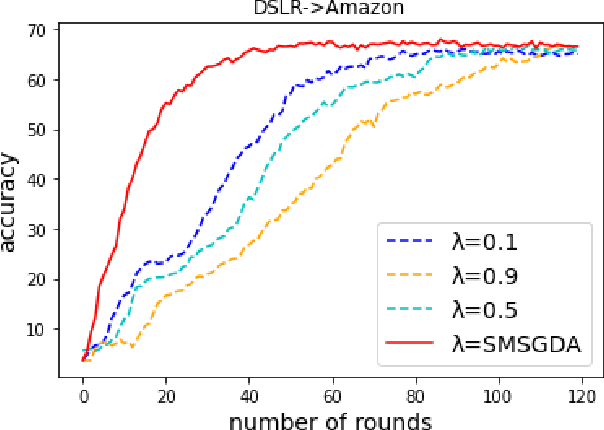
Given the rapidly changing machine learning environments and expensive data labeling, semi-supervised domain adaptation (SSDA) is imperative when the labeled data from the source domain is statistically different from the partially labeled data from the target domain. Most prior SSDA research is centrally performed, requiring access to both source and target data. However, data in many fields nowadays is generated by distributed end devices. Due to privacy concerns, the data might be locally stored and cannot be shared, resulting in the ineffectiveness of existing SSDA research. This paper proposes an innovative approach to achieve SSDA over multiple distributed and confidential datasets, named by Federated Semi-Supervised Domain Adaptation (FSSDA). FSSDA integrates SSDA with federated learning based on strategically designed knowledge distillation techniques, whose efficiency is improved by performing source and target training in parallel. Moreover, FSSDA controls the amount of knowledge transferred across domains by properly selecting a key parameter, i.e., the imitation parameter. Further, the proposed FSSDA can be effectively generalized to multi-source domain adaptation scenarios. Extensive experiments are conducted to demonstrate the effectiveness and efficiency of FSSDA design.
Pay "Attention" to Adverse Weather: Weather-aware Attention-based Object Detection
Apr 22, 2022
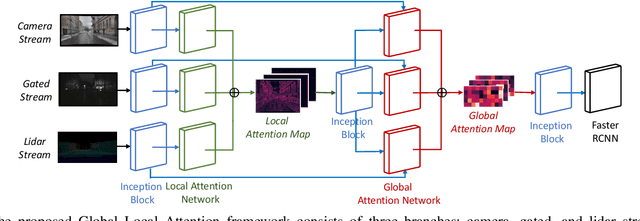
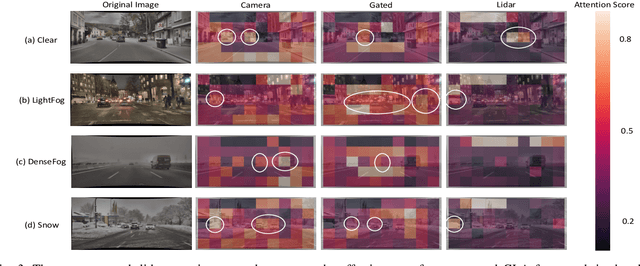
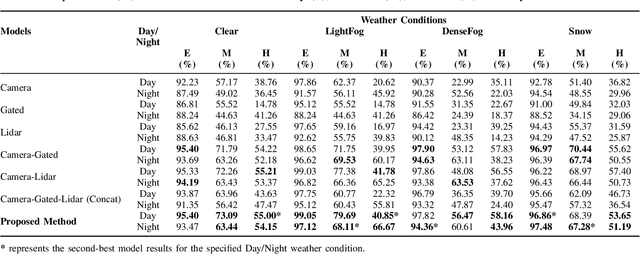
Despite the recent advances of deep neural networks, object detection for adverse weather remains challenging due to the poor perception of some sensors in adverse weather. Instead of relying on one single sensor, multimodal fusion has been one promising approach to provide redundant detection information based on multiple sensors. However, most existing multimodal fusion approaches are ineffective in adjusting the focus of different sensors under varying detection environments in dynamic adverse weather conditions. Moreover, it is critical to simultaneously observe local and global information under complex weather conditions, which has been neglected in most early or late-stage multimodal fusion works. In view of these, this paper proposes a Global-Local Attention (GLA) framework to adaptively fuse the multi-modality sensing streams, i.e., camera, gated camera, and lidar data, at two fusion stages. Specifically, GLA integrates an early-stage fusion via a local attention network and a late-stage fusion via a global attention network to deal with both local and global information, which automatically allocates higher weights to the modality with better detection features at the late-stage fusion to cope with the specific weather condition adaptively. Experimental results demonstrate the superior performance of the proposed GLA compared with state-of-the-art fusion approaches under various adverse weather conditions, such as light fog, dense fog, and snow.
Membership Inference Attacks and Defenses in Neural Network Pruning
Feb 07, 2022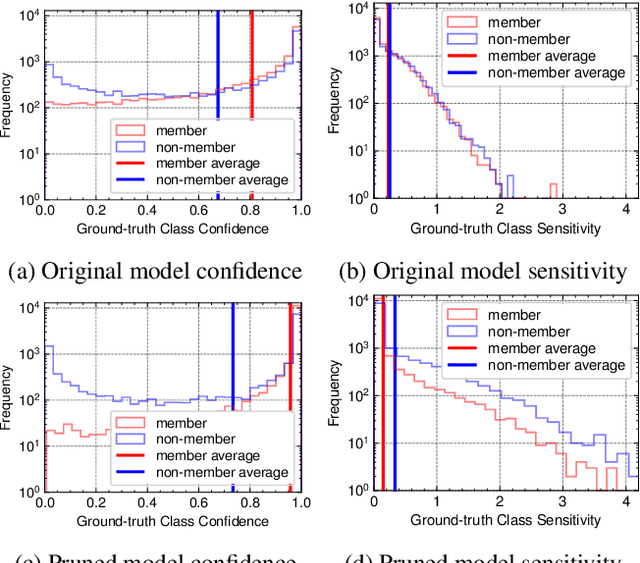
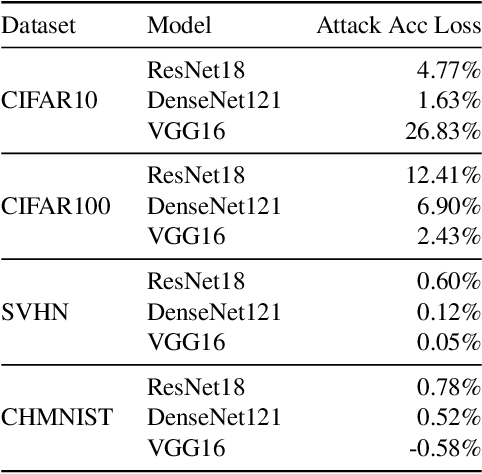

Neural network pruning has been an essential technique to reduce the computation and memory requirements for using deep neural networks for resource-constrained devices. Most existing research focuses primarily on balancing the sparsity and accuracy of a pruned neural network by strategically removing insignificant parameters and retraining the pruned model. Such efforts on reusing training samples pose serious privacy risks due to increased memorization, which, however, has not been investigated yet. In this paper, we conduct the first analysis of privacy risks in neural network pruning. Specifically, we investigate the impacts of neural network pruning on training data privacy, i.e., membership inference attacks. We first explore the impact of neural network pruning on prediction divergence, where the pruning process disproportionately affects the pruned model's behavior for members and non-members. Meanwhile, the influence of divergence even varies among different classes in a fine-grained manner. Enlighten by such divergence, we proposed a self-attention membership inference attack against the pruned neural networks. Extensive experiments are conducted to rigorously evaluate the privacy impacts of different pruning approaches, sparsity levels, and adversary knowledge. The proposed attack shows the higher attack performance on the pruned models when compared with eight existing membership inference attacks. In addition, we propose a new defense mechanism to protect the pruning process by mitigating the prediction divergence based on KL-divergence distance, whose effectiveness has been experimentally demonstrated to effectively mitigate the privacy risks while maintaining the sparsity and accuracy of the pruned models.
FedZKT: Zero-Shot Knowledge Transfer towards Heterogeneous On-Device Models in Federated Learning
Sep 08, 2021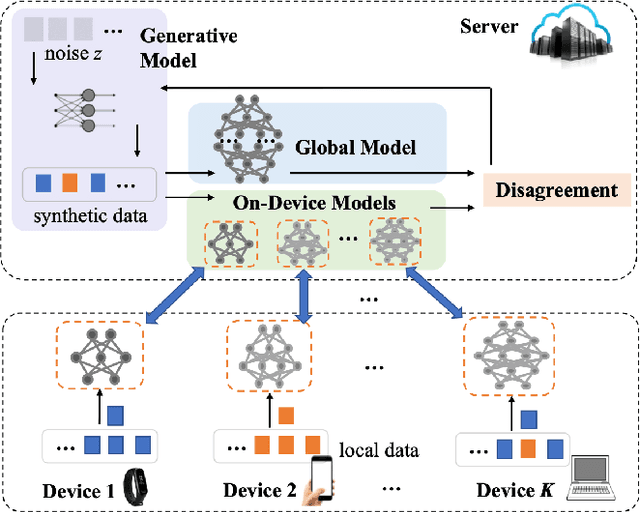
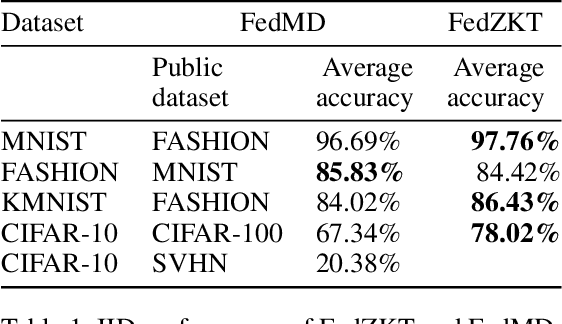
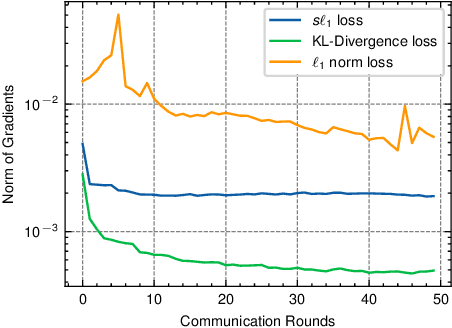
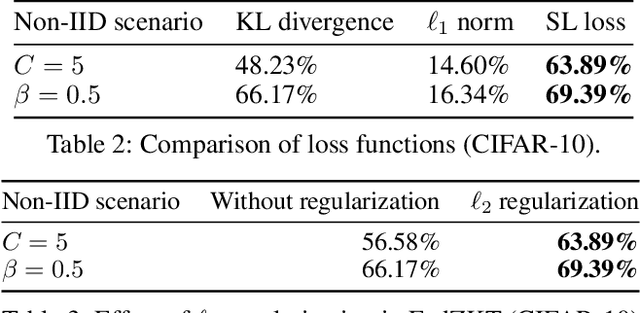
Federated learning enables distributed devices to collaboratively learn a shared prediction model without centralizing on-device training data. Most of the current algorithms require comparable individual efforts to train on-device models with the same structure and size, impeding participation from resource-constrained devices. Given the widespread yet heterogeneous devices nowadays, this paper proposes a new framework supporting federated learning across heterogeneous on-device models via Zero-shot Knowledge Transfer, named by FedZKT. Specifically, FedZKT allows participating devices to independently determine their on-device models. To transfer knowledge across on-device models, FedZKT develops a zero-shot distillation approach contrary to certain prior research based on a public dataset or a pre-trained data generator. To utmostly reduce on-device workload, the resource-intensive distillation task is assigned to the server, which constructs a generator to adversarially train with the ensemble of the received heterogeneous on-device models. The distilled central knowledge will then be sent back in the form of the corresponding on-device model parameters, which can be easily absorbed at the device side. Experimental studies demonstrate the effectiveness and the robustness of FedZKT towards heterogeneous on-device models and challenging federated learning scenarios, such as non-iid data distribution and straggler effects.
A Vertical Federated Learning Framework for Horizontally Partitioned Labels
Jun 18, 2021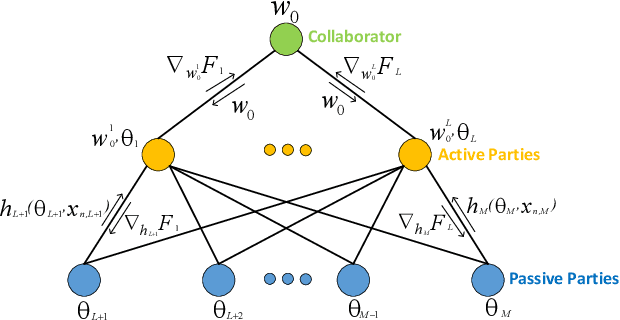
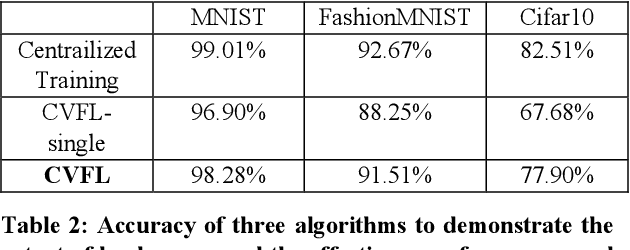
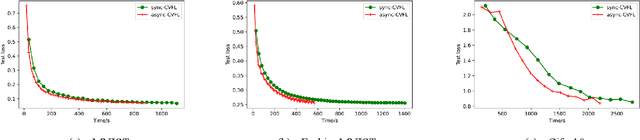
Vertical federated learning is a collaborative machine learning framework to train deep leaning models on vertically partitioned data with privacy-preservation. It attracts much attention both from academia and industry. Unfortunately, applying most existing vertical federated learning methods in real-world applications still faces two daunting challenges. First, most existing vertical federated learning methods have a strong assumption that at least one party holds the complete set of labels of all data samples, while this assumption is not satisfied in many practical scenarios, where labels are horizontally partitioned and the parties only hold partial labels. Existing vertical federated learning methods can only utilize partial labels, which may lead to inadequate model update in end-to-end backpropagation. Second, computational and communication resources vary in parties. Some parties with limited computational and communication resources will become the stragglers and slow down the convergence of training. Such straggler problem will be exaggerated in the scenarios of horizontally partitioned labels in vertical federated learning. To address these challenges, we propose a novel vertical federated learning framework named Cascade Vertical Federated Learning (CVFL) to fully utilize all horizontally partitioned labels to train neural networks with privacy-preservation. To mitigate the straggler problem, we design a novel optimization objective which can increase straggler's contribution to the trained models. We conduct a series of qualitative experiments to rigorously verify the effectiveness of CVFL. It is demonstrated that CVFL can achieve comparable performance (e.g., accuracy for classification tasks) with centralized training. The new optimization objective can further mitigate the straggler problem comparing with only using the asynchronous aggregation mechanism during training.
ES Attack: Model Stealing against Deep Neural Networks without Data Hurdles
Sep 21, 2020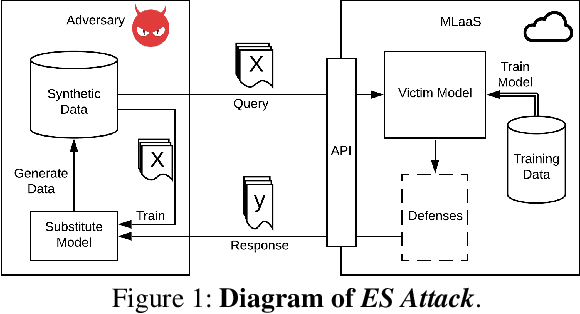
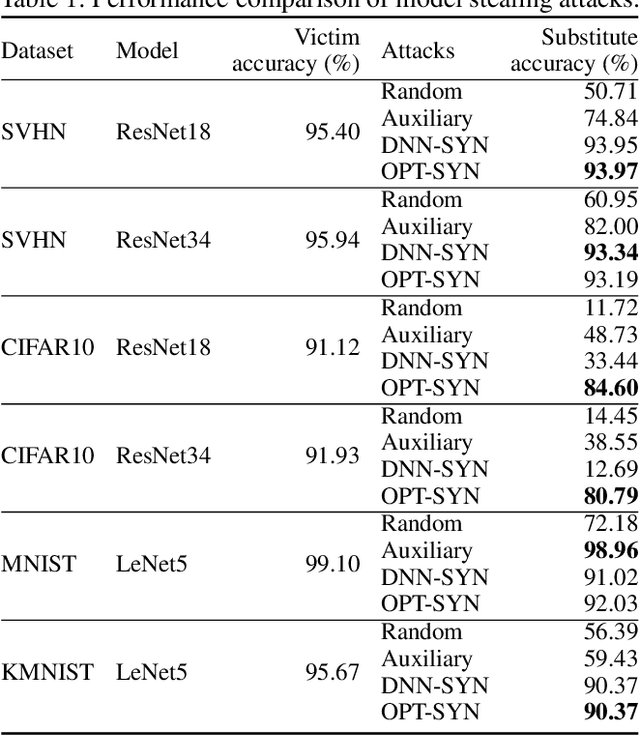

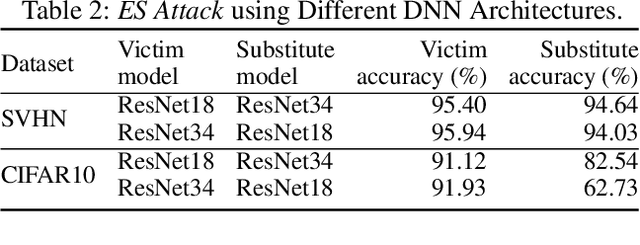
Deep neural networks (DNNs) have become the essential components for various commercialized machine learning services, such as Machine Learning as a Service (MLaaS). Recent studies show that machine learning services face severe privacy threats - well-trained DNNs owned by MLaaS providers can be stolen through public APIs, namely model stealing attacks. However, most existing works undervalued the impact of such attacks, where a successful attack has to acquire confidential training data or auxiliary data regarding the victim DNN. In this paper, we propose ES Attack, a novel model stealing attack without any data hurdles. By using heuristically generated synthetic data, ES Attackiteratively trains a substitute model and eventually achieves a functionally equivalent copy of the victim DNN. The experimental results reveal the severity of ES Attack: i) ES Attack successfully steals the victim model without data hurdles, and ES Attack even outperforms most existing model stealing attacks using auxiliary data in terms of model accuracy; ii) most countermeasures are ineffective in defending ES Attack; iii) ES Attack facilitates further attacks relying on the stolen model.
Connecting Web Event Forecasting with Anomaly Detection: A Case Study on Enterprise Web Applications Using Self-Supervised Neural Networks
Sep 07, 2020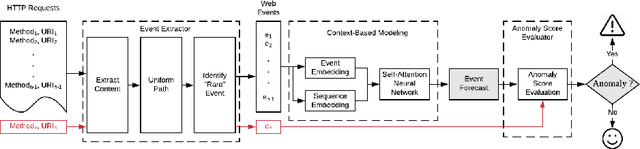
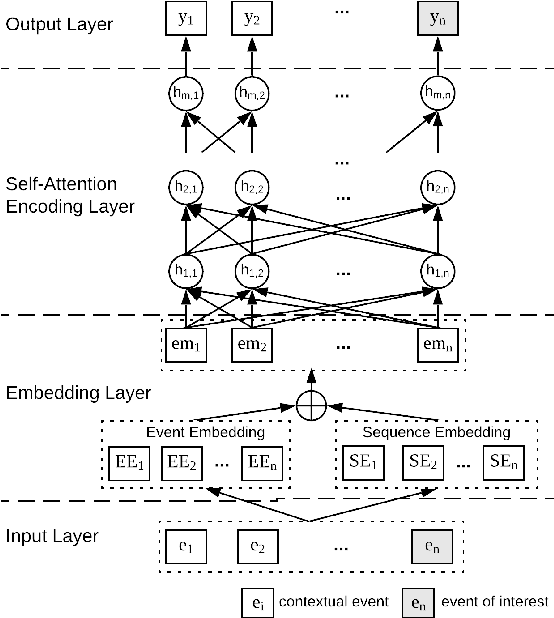
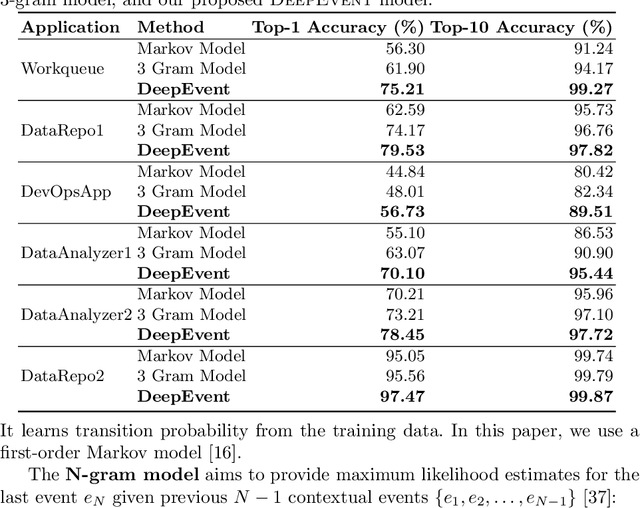
Recently web applications have been widely used in enterprises to assist employees in providing effective and efficient business processes. Forecasting upcoming web events in enterprise web applications can be beneficial in many ways, such as efficient caching and recommendation. In this paper, we present a web event forecasting approach, DeepEvent, in enterprise web applications for better anomaly detection. DeepEvent includes three key features: web-specific neural networks to take into account the characteristics of sequential web events, self-supervised learning techniques to overcome the scarcity of labeled data, and sequence embedding techniques to integrate contextual events and capture dependencies among web events. We evaluate DeepEvent on web events collected from six real-world enterprise web applications. Our experimental results demonstrate that DeepEvent is effective in forecasting sequential web events and detecting web based anomalies. DeepEvent provides a context-based system for researchers and practitioners to better forecast web events with situational awareness.
Generalized Batch Normalization: Towards Accelerating Deep Neural Networks
Dec 08, 2018
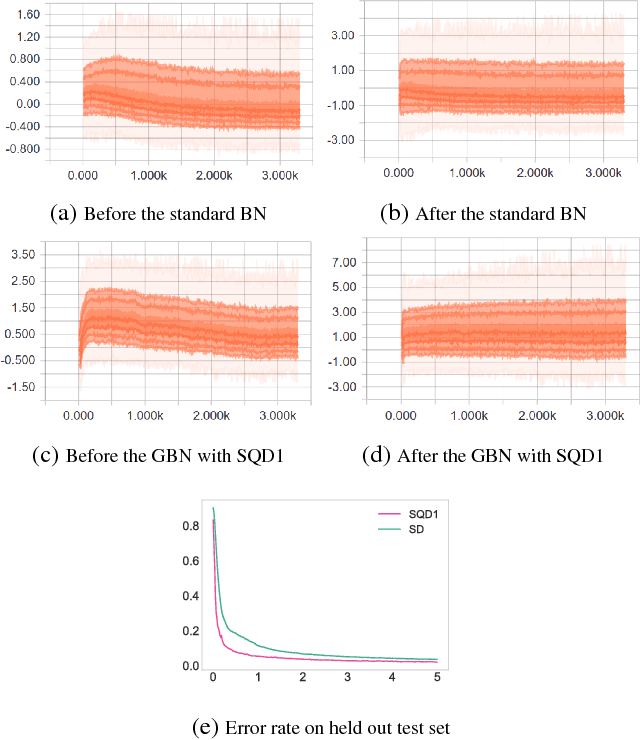
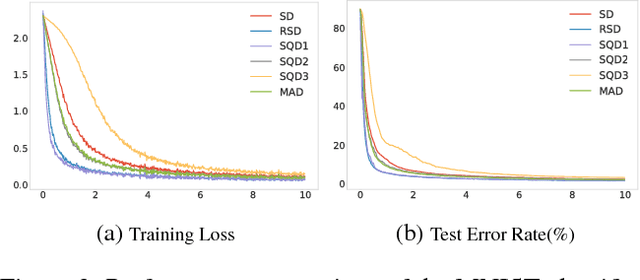
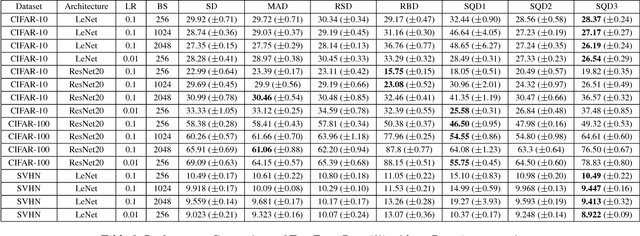
Utilizing recently introduced concepts from statistics and quantitative risk management, we present a general variant of Batch Normalization (BN) that offers accelerated convergence of Neural Network training compared to conventional BN. In general, we show that mean and standard deviation are not always the most appropriate choice for the centering and scaling procedure within the BN transformation, particularly if ReLU follows the normalization step. We present a Generalized Batch Normalization (GBN) transformation, which can utilize a variety of alternative deviation measures for scaling and statistics for centering, choices which naturally arise from the theory of generalized deviation measures and risk theory in general. When used in conjunction with the ReLU non-linearity, the underlying risk theory suggests natural, arguably optimal choices for the deviation measure and statistic. Utilizing the suggested deviation measure and statistic, we show experimentally that training is accelerated more so than with conventional BN, often with improved error rate as well. Overall, we propose a more flexible BN transformation supported by a complimentary theoretical framework that can potentially guide design choices.