 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2022 Far-field Speaker Verification Challenge: Exploring domain mismatch and semi-supervised learning under the far-field scenario
Sep 16, 2022
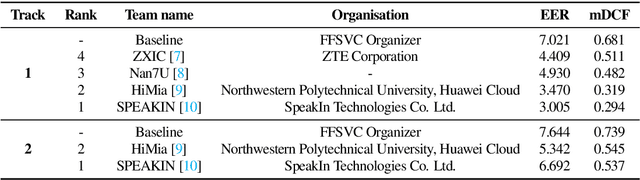
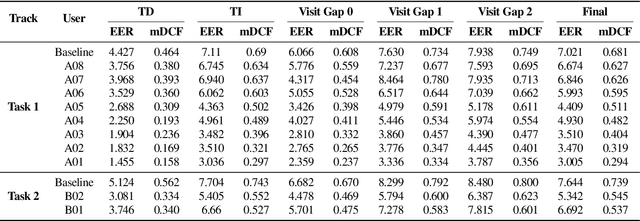
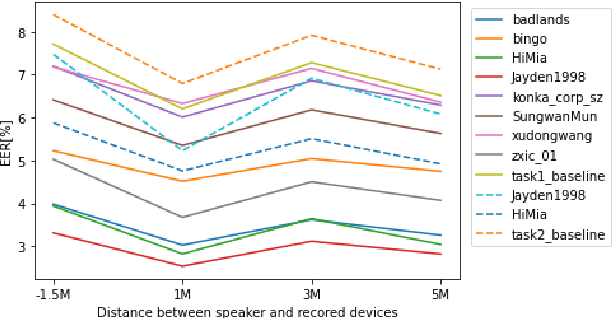
FFSVC2022 is the second challenge of far-field speaker verification. FFSVC2022 provides the fully-supervised far-field speaker verification to further explore the far-field scenario and proposes semi-supervised far-field speaker verification. In contrast to FFSVC2020, FFSVC2022 focus on the single-channel scenario. In addition, a supplementary set for the FFSVC2020 dataset is released this year. The supplementary set consists of more recording devices and has the same data distribution as the FFSVC2022 evaluation set. This paper summarizes the FFSVC 2022, including tasks description, trial designing details, a baseline system and a summary of challenge results. The challenge results indicate substantial progress made in the field but also present that there are still difficulties with the far-field scenario.
The DKU-OPPO System for the 2022 Spoofing-Aware Speaker Verification Challenge
Jul 15, 2022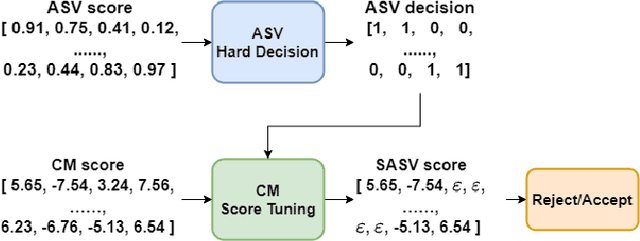
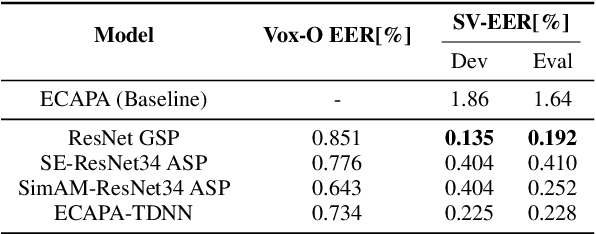
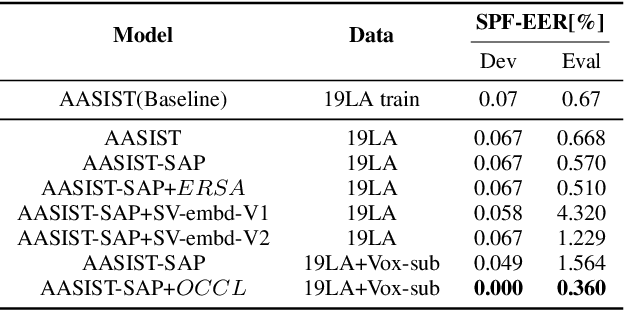
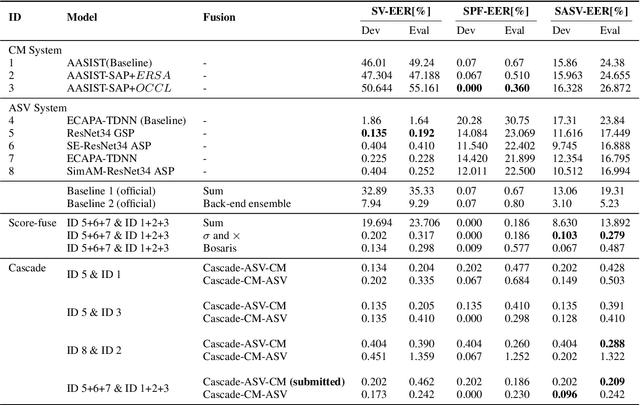
This paper describes our DKU-OPPO system for the 2022 Spoofing-Aware Speaker Verification (SASV) Challenge. First, we split the joint task into speaker verification (SV) and spoofing countermeasure (CM), these two tasks which are optimized separately. For ASV systems, four state-of-the-art methods are employed. For CM systems, we propose two methods on top of the challenge baseline to further improve the performance, namely Embedding Random Sampling Augmentation (ERSA) and One-Class Confusion Loss(OCCL). Second, we also explore whether SV embedding could help improve CM system performance. We observe a dramatic performance degradation of existing CM systems on the domain-mismatched Voxceleb2 dataset. Third, we compare different fusion strategies, including parallel score fusion and sequential cascaded systems. Compared to the 1.71% SASV-EER baseline, our submitted cascaded system obtains a 0.21% SASV-EER on the challenge official evaluation set.
Cross-Age Speaker Verification: Learning Age-Invariant Speaker Embeddings
Jul 13, 2022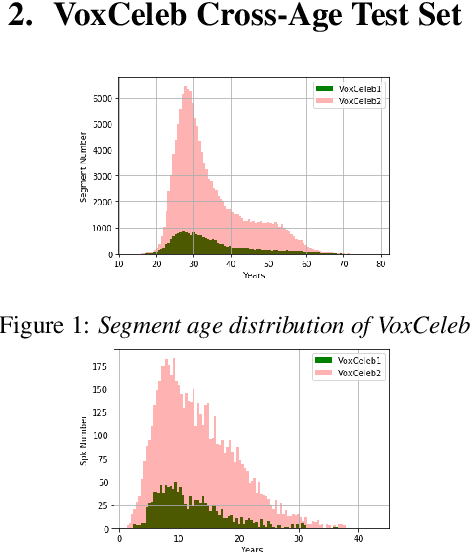
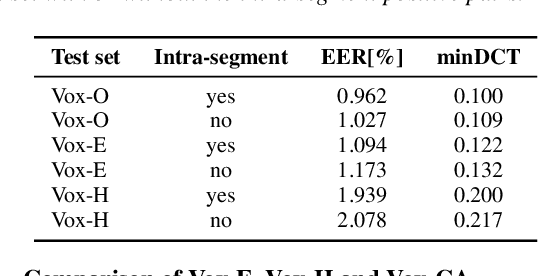
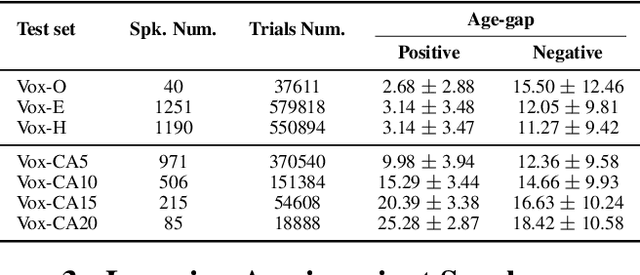
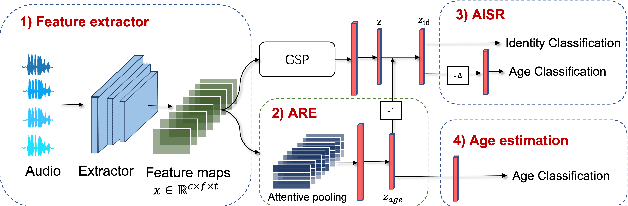
Automatic speaker verification has achieved remarkable progress in recent years. However, there is little research on cross-age speaker verification (CASV) due to insufficient relevant data. In this paper, we mine cross-age test sets based on the VoxCeleb dataset and propose our age-invariant speaker representation(AISR) learning method. Since the VoxCeleb is collected from the YouTube platform, the dataset consists of cross-age data inherently. However, the meta-data does not contain the speaker age label. Therefore, we adopt the face age estimation method to predict the speaker age value from the associated visual data, then label the audio recording with the estimated age. We construct multiple Cross-Age test sets on VoxCeleb (Vox-CA), which deliberately select the positive trials with large age-gap. Also, the effect of nationality and gender is considered in selecting negative pairs to align with Vox-H cases. The baseline system performance drops from 1.939\% EER on the Vox-H test set to 10.419\% on the Vox-CA20 test set, which indicates how difficult the cross-age scenario is. Consequently, we propose an age-decoupling adversarial learning (ADAL) method to alleviate the negative effect of the age gap and reduce intra-class variance. Our method outperforms the baseline system by over 10\% related EER reduction on the Vox-CA20 test set. The source code and trial resources are available on https://github.com/qinxiaoyi/Cross-Age_Speaker_Verification
Cross-Channel Attention-Based Target Speaker Voice Activity Detection: Experimental Results for M2MeT Challenge
Feb 06, 2022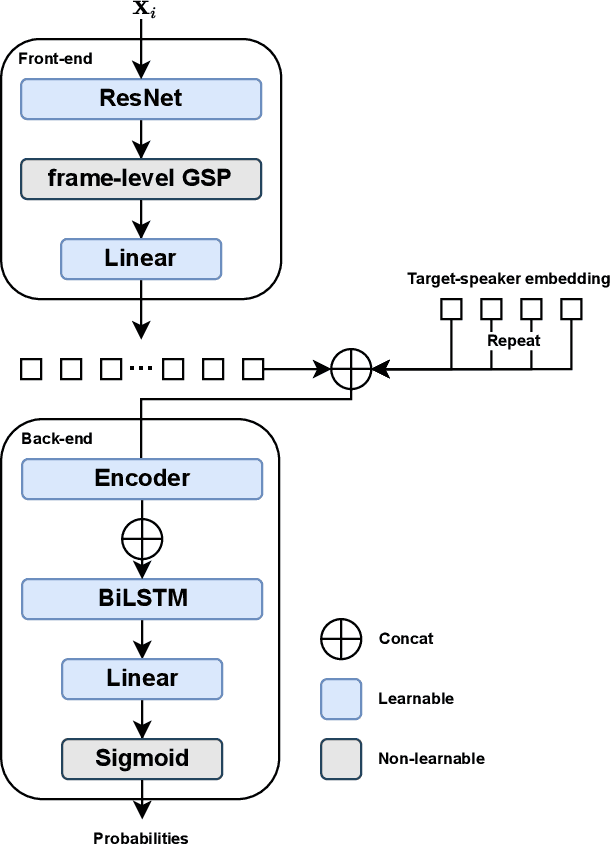
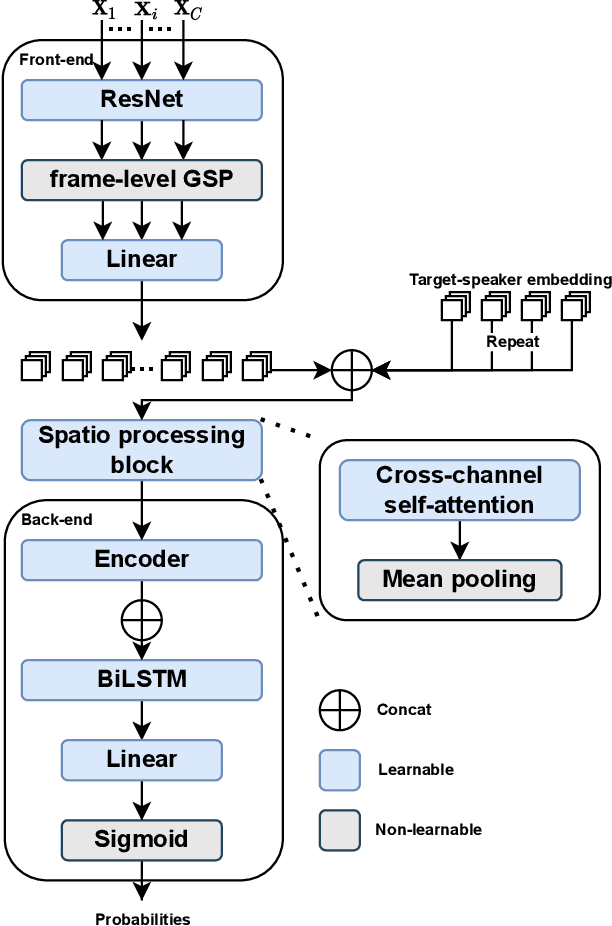
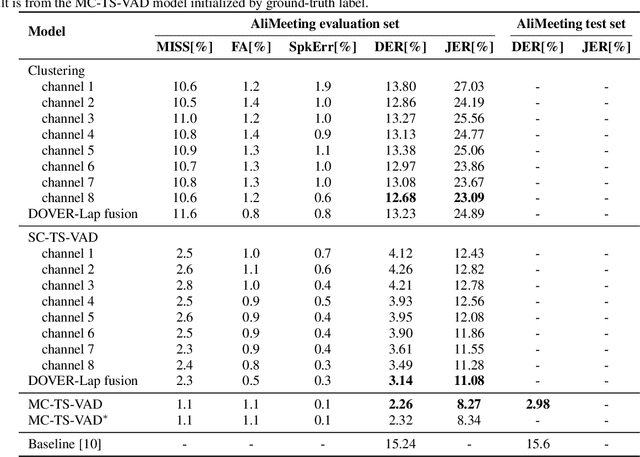
In this paper, we present the speaker diarization system for the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT) from team DKU_DukeECE. As the highly overlapped speech exists in the dataset, we employ an x-vector-based target-speaker voice activity detection (TS-VAD) to find the overlap between speakers. For the single-channel scenario, we separately train a model for each of the 8 channels and fuse the results. We also employ the cross-channel self-attention to further improve the performance, where the non-linear spatial correlations between different channels are learned and fused. Experimental results on the evaluation set show that the single-channel TS-VAD reduces the DER by over 75% from 12.68\% to 3.14%. The multi-channel TS-VAD further reduces the DER by 28% and achieves a DER of 2.26%. Our final submitted system achieves a DER of 2.98% on the AliMeeting test set, which ranks 1st in the M2MET challenge.
Simple Attention Module based Speaker Verification with Iterative noisy label detection
Oct 13, 2021
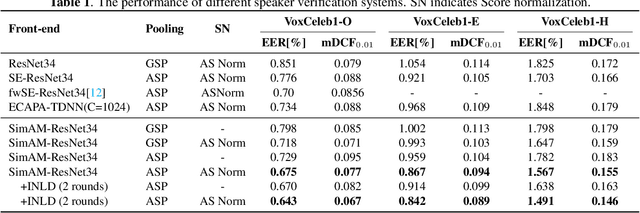
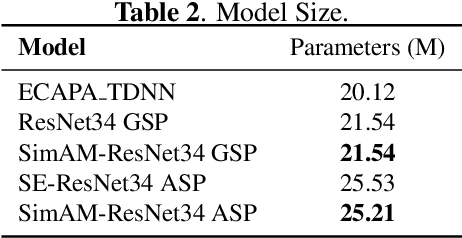
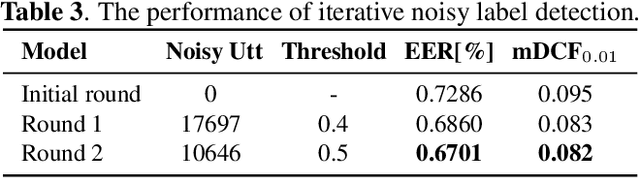
Recently, the attention mechanism such as squeeze-and-excitation module (SE) and convolutional block attention module (CBAM) has achieved great success in deep learning-based speaker verification system. This paper introduces an alternative effective yet simple one, i.e., simple attention module (SimAM), for speaker verification. The SimAM module is a plug-and-play module without extra modal parameters. In addition, we propose a noisy label detection method to iteratively filter out the data samples with a noisy label from the training data, considering that a large-scale dataset labeled with human annotation or other automated processes may contain noisy labels. Data with the noisy label may over parameterize a deep neural network (DNN) and result in a performance drop due to the memorization effect of the DNN. Experiments are conducted on VoxCeleb dataset. The speaker verification model with SimAM achieves the 0.675% equal error rate (EER) on VoxCeleb1 original test trials. Our proposed iterative noisy label detection method further reduces the EER to 0.643%.
Towards Lightweight Applications: Asymmetric Enroll-Verify Structure for Speaker Verification
Oct 09, 2021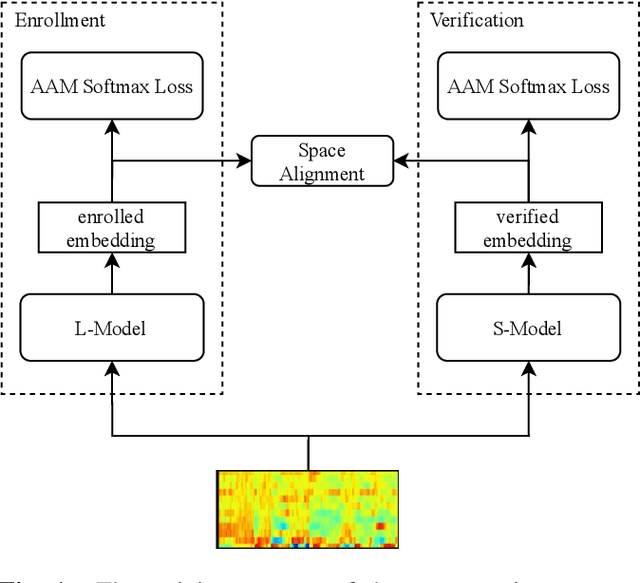
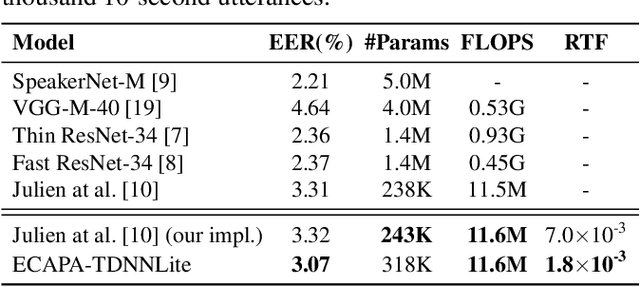
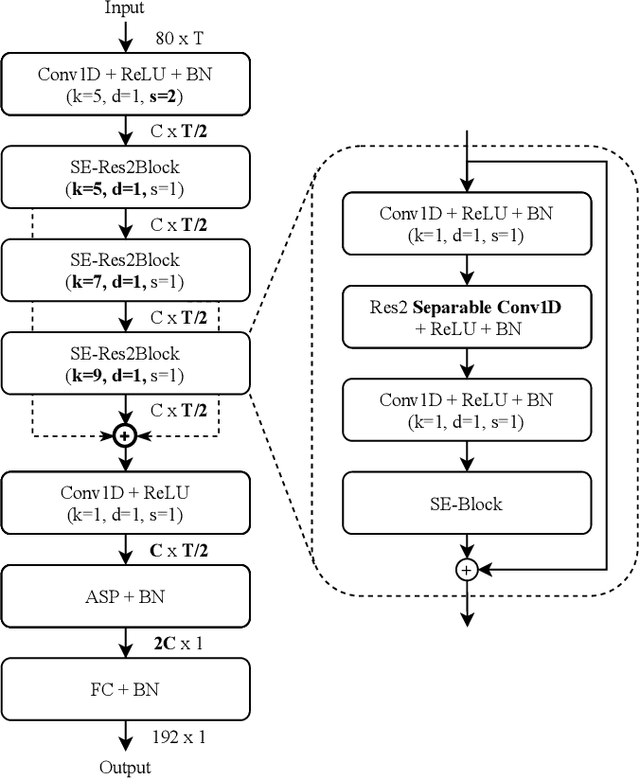

With the development of deep learning, automatic speaker verification has made considerable progress over the past few years. However, to design a lightweight and robust system with limited computational resources is still a challenging problem. Traditionally, a speaker verification system is symmetrical, indicating that the same embedding extraction model is applied for both enrollment and verification in inference. In this paper, we come up with an innovative asymmetric structure, which takes the large-scale ECAPA-TDNN model for enrollment and the small-scale ECAPA-TDNNLite model for verification. As a symmetrical system, our proposed ECAPA-TDNNLite model achieves an EER of 3.07% on the Voxceleb1 original test set with only 11.6M FLOPS. Moreover, the asymmetric structure further reduces the EER to 2.31%, without increasing any computational costs during verification.
Building Bilingual and Code-Switched Voice Conversion with Limited Training Data Using Embedding Consistency Loss
Apr 22, 2021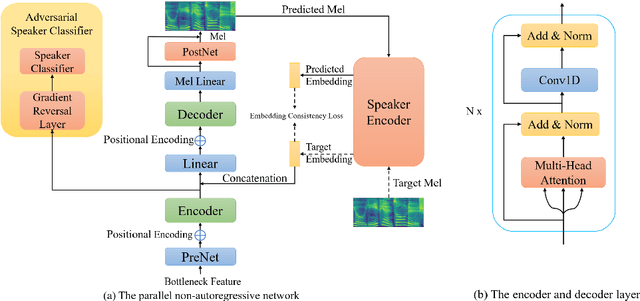

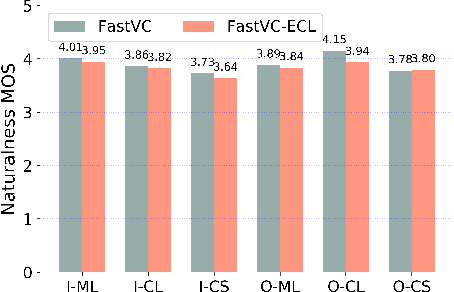
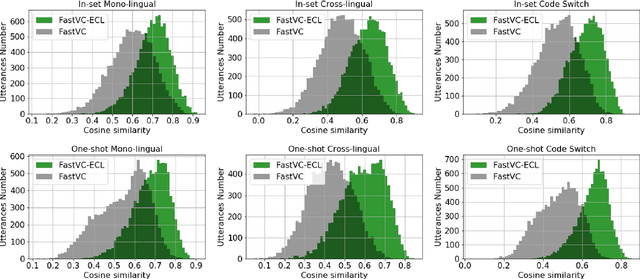
Building cross-lingual voice conversion (VC) systems for multiple speakers and multiple languages has been a challenging task for a long time. This paper describes a parallel non-autoregressive network to achieve bilingual and code-switched voice conversion for multiple speakers when there are only mono-lingual corpora for each language. We achieve cross-lingual VC between Mandarin speech with multiple speakers and English speech with multiple speakers by applying bilingual bottleneck features. To boost voice cloning performance, we use an adversarial speaker classifier with a gradient reversal layer to reduce the source speaker's information from the output of encoder. Furthermore, in order to improve speaker similarity between reference speech and converted speech, we adopt an embedding consistency loss between the synthesized speech and its natural reference speech in our network. Experimental results show that our proposed method can achieve high quality converted speech with mean opinion score (MOS) around 4. The conversion system performs well in terms of speaker similarity for both in-set speaker conversion and out-set-of one-shot conversion.
Binary Neural Network for Speaker Verification
Apr 06, 2021
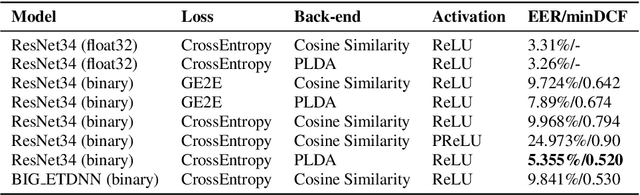


Although deep neural networks are successful for many tasks in the speech domain, the high computational and memory costs of deep neural networks make it difficult to directly deploy highperformance Neural Network systems on low-resource embedded devices. There are several mechanisms to reduce the size of the neural networks i.e. parameter pruning, parameter quantization, etc. This paper focuses on how to apply binary neural networks to the task of speaker verification. The proposed binarization of training parameters can largely maintain the performance while significantly reducing storage space requirements and computational costs. Experiment results show that, after binarizing the Convolutional Neural Network, the ResNet34-based network achieves an EER of around 5% on the Voxceleb1 testing dataset and even outperforms the traditional real number network on the text-dependent dataset: Xiaole while having a 32x memory saving.
The 2020 Personalized Voice Trigger Challenge: Open Database, Evaluation Metrics and the Baseline Systems
Jan 06, 2021
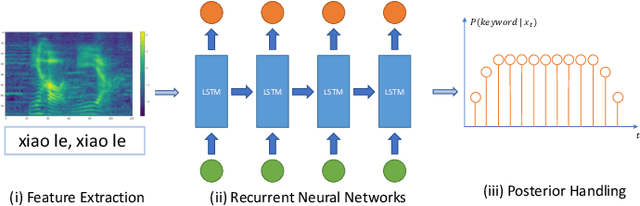

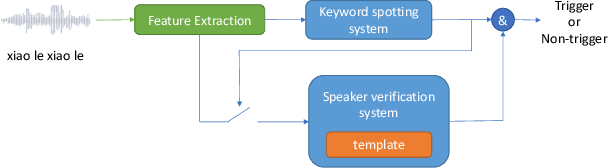
The 2020 Personalized Voice Trigger Challenge (PVTC2020) addresses two different research problems a unified setup: joint wake-up word detection with speaker verification on close-talking single microphone data and far-field multi-channel microphone array data. Specially, the second task poses an additional cross-channel matching challenge on top of the far-field condition. To simulate the real-life application scenario, the enrollment utterances are recorded from close-talking cell-phone only, while the test utterances are recorded from both the close-talking cell-phone and the far-field microphone arrays. This paper introduces our challenge setup and the released database as well as the evaluation metrics. In addition, we present a joint end-to-end neural network baseline system trained with the proposed database for speaker-dependent wake-up word detection. Results show that the cost calculated from the miss rate and the false alarm rate, can reach 0.37 in the close-talking single microphone task and 0.31 in the far-field microphone array task. The official website and the open-source baseline system have been released.
Polyphone Disambiguation for Mandarin Chinese Using Conditional Neural Network with Multi-level Embedding Features
Jul 03, 2019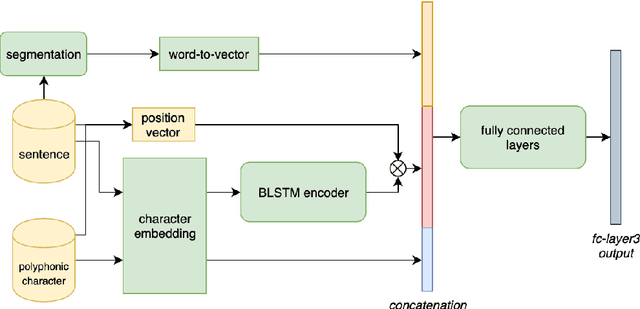
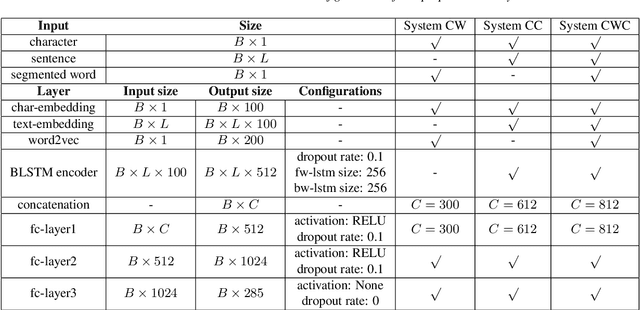
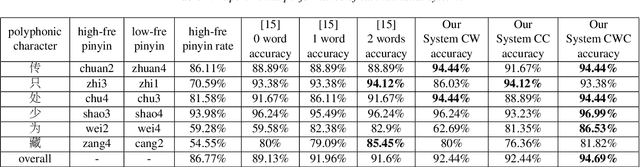
This paper describes a conditional neural network architecture for Mandarin Chinese polyphone disambiguation. The system is composed of a bidirectional recurrent neural network component acting as a sentence encoder to accumulate the context correlations, followed by a prediction network that maps the polyphonic character embeddings along with the conditions to corresponding pronunciations. We obtain the word-level condition from a pre-trained word-to-vector lookup table. One goal of polyphone disambiguation is to address the homograph problem existing in the front-end processing of Mandarin Chinese text-to-speech system. Our system achieves an accuracy of 94.69\% on a publicly available polyphonic character dataset. To further validate our choices on the conditional feature, we investigate polyphone disambiguation systems with multi-level conditions respectively. The experimental results show that both the sentence-level and the word-level conditional embedding features are able to attain good performance for Mandarin Chinese polyphone disambiguation.