 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net
Mar 15, 2018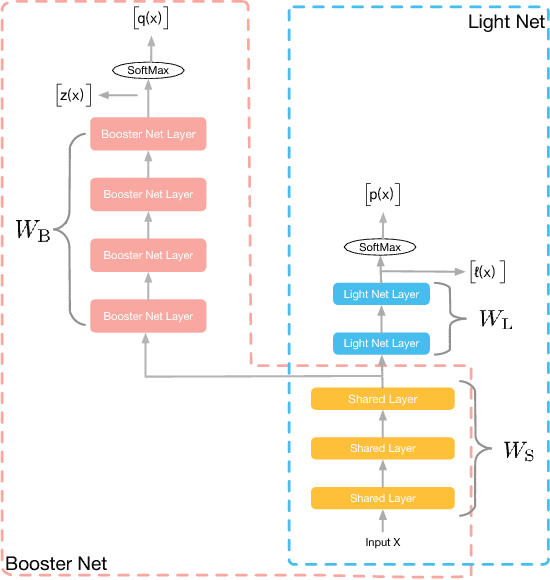
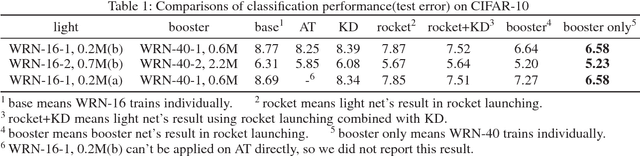
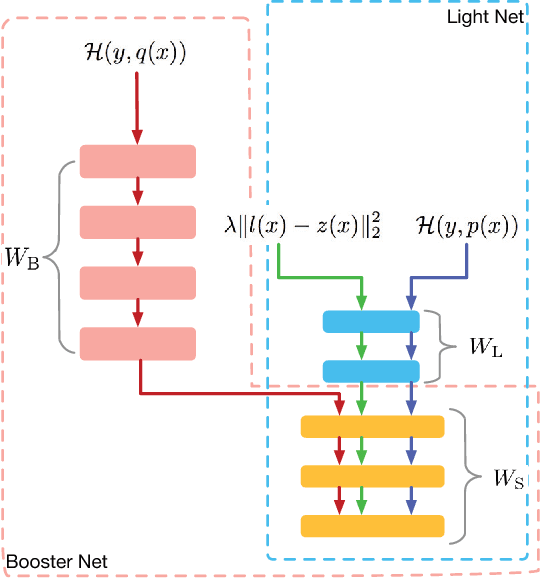

Models applied on real time response task, like click-through rate (CTR) prediction model, require high accuracy and rigorous response time. Therefore, top-performing deep models of high depth and complexity are not well suited for these applications with the limitations on the inference time. In order to further improve the neural networks' performance given the time and computational limitations, we propose an approach that exploits a cumbersome net to help train the lightweight net for prediction. We dub the whole process rocket launching, where the cumbersome booster net is used to guide the learning of the target light net throughout the whole training process. We analyze different loss functions aiming at pushing the light net to behave similarly to the booster net, and adopt the loss with best performance in our experiments. We use one technique called gradient block to improve the performance of the light net and booster net further. Experiments on benchmark datasets and real-life industrial advertisement data present that our light model can get performance only previously achievable with more complex models.
Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction
Apr 18, 2017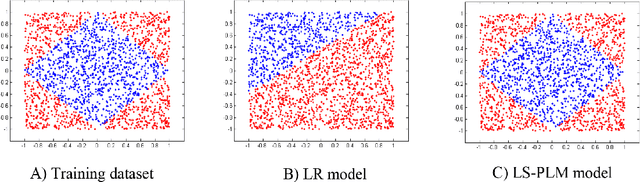
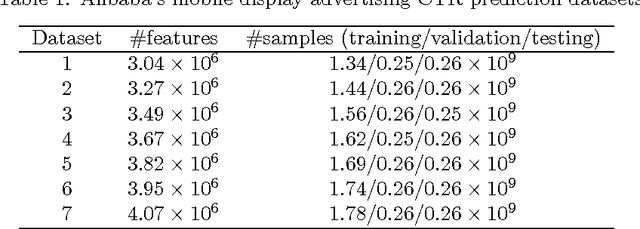
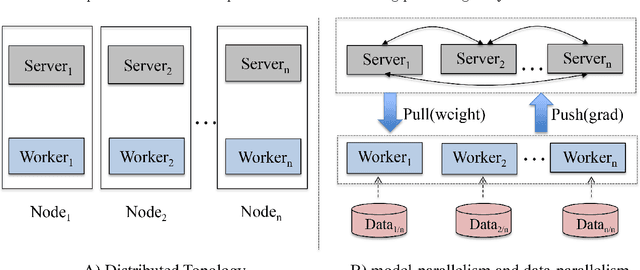
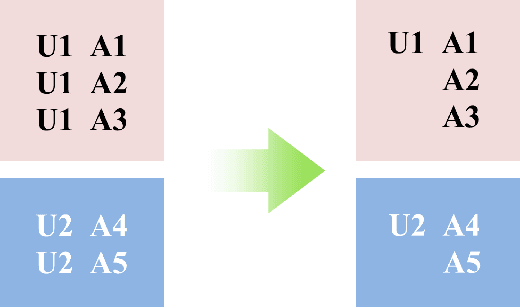
CTR prediction in real-world business is a difficult machine learning problem with large scale nonlinear sparse data. In this paper, we introduce an industrial strength solution with model named Large Scale Piece-wise Linear Model (LS-PLM). We formulate the learning problem with $L_1$ and $L_{2,1}$ regularizers, leading to a non-convex and non-smooth optimization problem. Then, we propose a novel algorithm to solve it efficiently, based on directional derivatives and quasi-Newton method. In addition, we design a distributed system which can run on hundreds of machines parallel and provides us with the industrial scalability. LS-PLM model can capture nonlinear patterns from massive sparse data, saving us from heavy feature engineering jobs. Since 2012, LS-PLM has become the main CTR prediction model in Alibaba's online display advertising system, serving hundreds of millions users every day.