 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATT-CR: Adaptive Triangular Transformer for Cloud Removal
Jun 04, 2026Cloud removal aims to accurately reconstruct the ground objects obscured by clouds in remote sensing images. Existing Transformer-based methods utilizing self-attention have shown impressive results by effectively modeling long-range dependencies in cloudy images. However, they suffer from the following issues: 1) the high computational complexity of self-attention limits scalability; 2) treating both cloudy and clean pixels as valid within the attention computation brings disturbances in subsequent layers, leading to suboptimal performance. To address these challenges, we propose the Adaptive Triangular Transformer for Cloud Removal (ATT-CR), a model that effectively reduces computational costs and mitigates interference from cloudy pixels. Specifically, it consists of two core components: Triangular Attention (TAN) and Feature Selected Gating Module (FSGM). TAN employs lower and upper triangular matrices to approximate Softmax attention with O(N) computational complexity, significantly reducing the computational costs. The FSGM, on the other hand, integrates with TAN to adaptively distinguish between cloudy and clean features, which minimizes the introduction of invalid information into subsequent layers. Extensive experiments on cloud removal benchmarks demonstrate that ATT-CR delivers superior performance compared to existing methods.
Task-Guided Prompting for Unified Remote Sensing Image Restoration
Apr 03, 2026Remote sensing image restoration (RSIR) is essential for recovering high-fidelity imagery from degraded observations, enabling accurate downstream analysis. However, most existing methods focus on single degradation types within homogeneous data, restricting their practicality in real-world scenarios where multiple degradations often across diverse spectral bands or sensor modalities, creating a significant operational bottleneck. To address this fundamental gap, we propose TGPNet, a unified framework capable of handling denoising, cloud removal, shadow removal, deblurring, and SAR despeckling within a single, unified architecture. The core of our framework is a novel Task-Guided Prompting (TGP) strategy. TGP leverages learnable, task-specific embeddings to generate degradation-aware cues, which then hierarchically modulate features throughout the decoder. This task-adaptive mechanism allows the network to precisely tailor its restoration process for distinct degradation patterns while maintaining a single set of shared weights. To validate our framework, we construct a unified RSIR benchmark covering RGB, multispectral, SAR, and thermal infrared modalities for five aforementioned restoration tasks. Experimental results demonstrate that TGPNet achieves state-of-the-art performance on both unified multi-task scenarios and unseen composite degradations, surpassing even specialized models in individual domains such as cloud removal. By successfully unifying heterogeneous degradation removal within a single adaptive framework, this work presents a significant advancement for multi-task RSIR, offering a practical and scalable solution for operational pipelines. The code and benchmark will be released at https://github.com/huangwenwenlili/TGPNet.
* 17 pages, 11 figures
Memory-Free Generative Replay For Class-Incremental Learning
Sep 01, 2021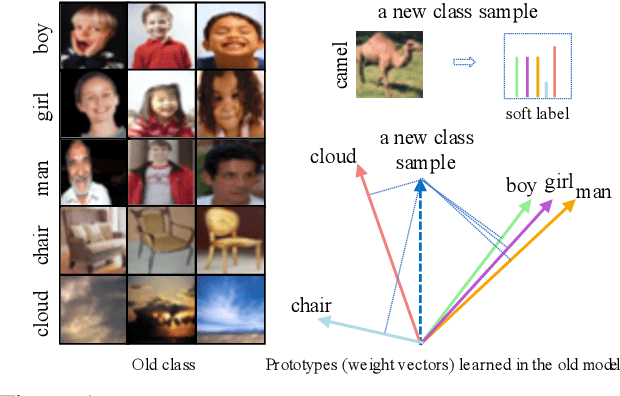

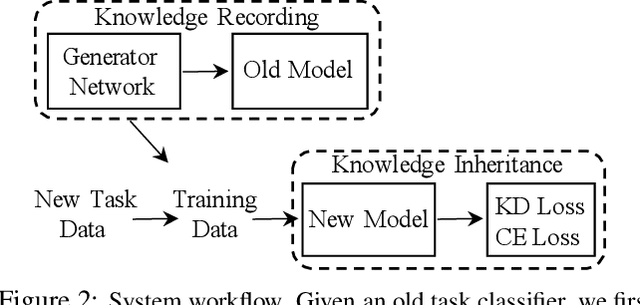

Regularization-based methods are beneficial to alleviate the catastrophic forgetting problem in class-incremental learning. With the absence of old task images, they often assume that old knowledge is well preserved if the classifier produces similar output on new images. In this paper, we find that their effectiveness largely depends on the nature of old classes: they work well on classes that are easily distinguishable between each other but may fail on more fine-grained ones, e.g., boy and girl. In spirit, such methods project new data onto the feature space spanned by the weight vectors in the fully connected layer, corresponding to old classes. The resulting projections would be similar on fine-grained old classes, and as a consequence the new classifier will gradually lose the discriminative ability on these classes. To address this issue, we propose a memory-free generative replay strategy to preserve the fine-grained old classes characteristics by generating representative old images directly from the old classifier and combined with new data for new classifier training. To solve the homogenization problem of the generated samples, we also propose a diversity loss that maximizes Kullback Leibler (KL) divergence between generated samples. Our method is best complemented by prior regularization-based methods proved to be effective for easily distinguishable old classes. We validate the above design and insights on CUB-200-2011, Caltech-101, CIFAR-100 and Tiny ImageNet and show that our strategy outperforms existing memory-free methods with a clear margin. Code is available at https://github.com/xmengxin/MFGR
Deep Self-Paced Learning for Person Re-Identification
Oct 07, 2017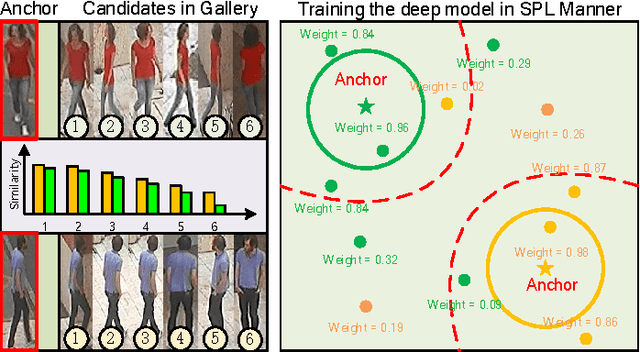
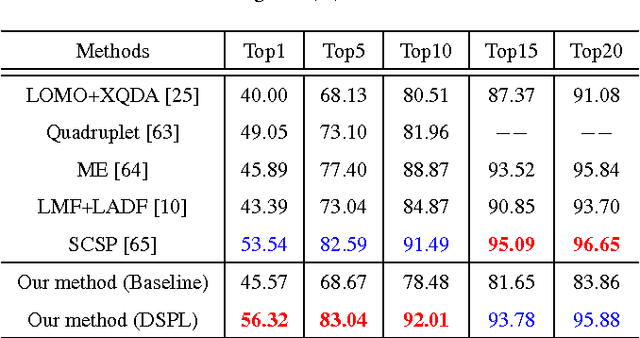
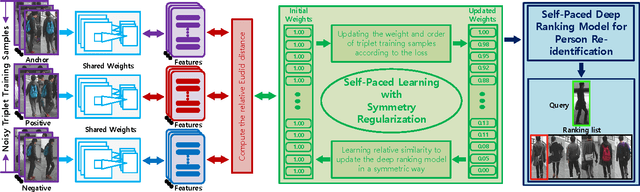
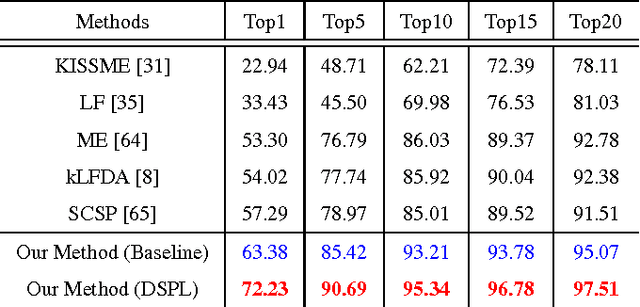
Person re-identification (Re-ID) usually suffers from noisy samples with background clutter and mutual occlusion, which makes it extremely difficult to distinguish different individuals across the disjoint camera views. In this paper, we propose a novel deep self-paced learning (DSPL) algorithm to alleviate this problem, in which we apply a self-paced constraint and symmetric regularization to help the relative distance metric training the deep neural network, so as to learn the stable and discriminative features for person Re-ID. Firstly, we propose a soft polynomial regularizer term which can derive the adaptive weights to samples based on both the training loss and model age. As a result, the high-confidence fidelity samples will be emphasized and the low-confidence noisy samples will be suppressed at early stage of the whole training process. Such a learning regime is naturally implemented under a self-paced learning (SPL) framework, in which samples weights are adaptively updated based on both model age and sample loss using an alternative optimization method. Secondly, we introduce a symmetric regularizer term to revise the asymmetric gradient back-propagation derived by the relative distance metric, so as to simultaneously minimize the intra-class distance and maximize the inter-class distance in each triplet unit. Finally, we build a part-based deep neural network, in which the features of different body parts are first discriminately learned in the lower convolutional layers and then fused in the higher fully connected layers. Experiments on several benchmark datasets have demonstrated the superior performance of our method as compared with the state-of-the-art approaches.