 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Decoding of $\ell_\infty$-coded Light Field Images
Jan 24, 2022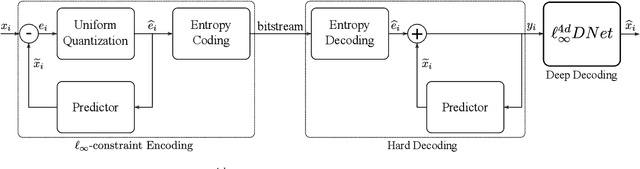
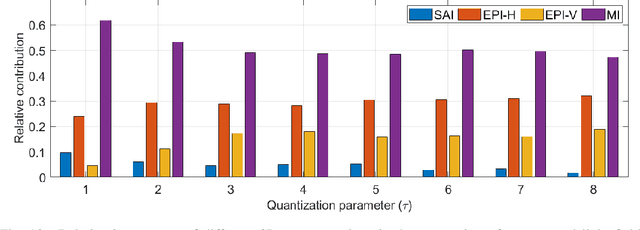
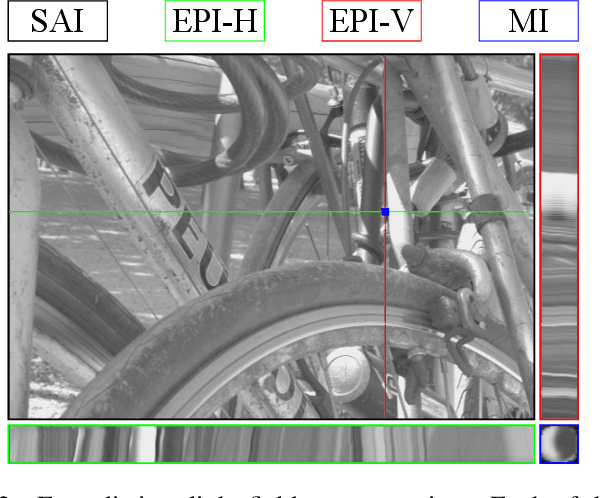
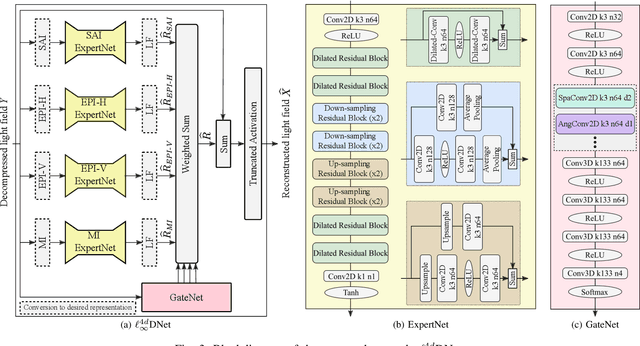
To enrich the functionalities of traditional cameras, light field cameras record both the intensity and direction of light rays, so that images can be rendered with user-defined camera parameters via computations. The added capability and flexibility are gained at the cost of gathering typically more than $100\times$ greater amount of information than conventional images. To cope with this issue, several light field compression schemes have been introduced. However, their ways of exploiting correlations of multidimensional light field data are complex and are hence not suited for inexpensive light field cameras. In this work, we propose a novel $\ell_\infty$-constrained light-field image compression system that has a very low-complexity DPCM encoder and a CNN-based deep decoder. Targeting high-fidelity reconstruction, the CNN decoder capitalizes on the $\ell_\infty$-constraint and light field properties to remove the compression artifacts and achieves significantly better performance than existing state-of-the-art $\ell_2$-based light field compression methods.
Functional Neural Networks for Parametric Image Restoration Problems
Oct 30, 2021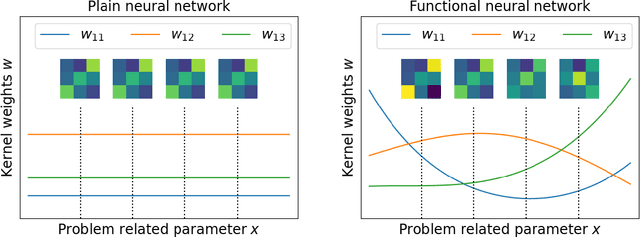
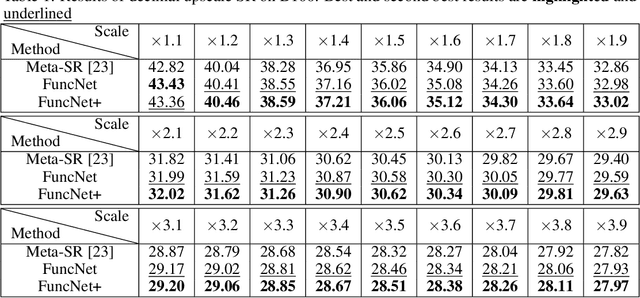

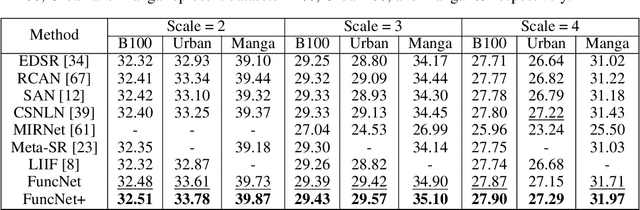
Almost every single image restoration problem has a closely related parameter, such as the scale factor in super-resolution, the noise level in image denoising, and the quality factor in JPEG deblocking. Although recent studies on image restoration problems have achieved great success due to the development of deep neural networks, they handle the parameter involved in an unsophisticated way. Most previous researchers either treat problems with different parameter levels as independent tasks, and train a specific model for each parameter level; or simply ignore the parameter, and train a single model for all parameter levels. The two popular approaches have their own shortcomings. The former is inefficient in computing and the latter is ineffective in performance. In this work, we propose a novel system called functional neural network (FuncNet) to solve a parametric image restoration problem with a single model. Unlike a plain neural network, the smallest conceptual element of our FuncNet is no longer a floating-point variable, but a function of the parameter of the problem. This feature makes it both efficient and effective for a parametric problem. We apply FuncNet to super-resolution, image denoising, and JPEG deblocking. The experimental results show the superiority of our FuncNet on all three parametric image restoration tasks over the state of the arts.
An Efficient Dual-reference Training Data Acquisition Method for CNN-Based Image Super-Resolution
Sep 02, 2021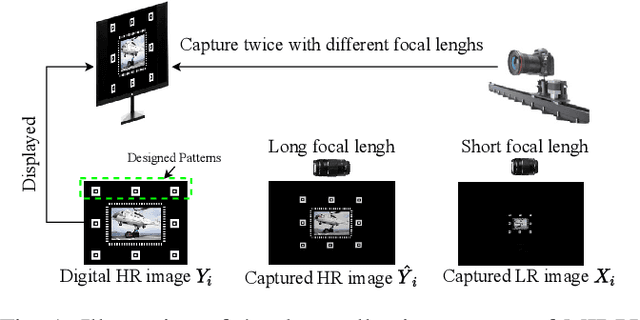



For deep learning methods of image super-resolution, the most critical issue is whether the paired low and high resolution images for training accurately reflect the sampling process of real cameras. Low and high resolution (LR$\sim$HR) image pairs synthesized by existing degradation models (e.g. bicubic downsampling) deviate from those in reality; thus the super-resolution CNN trained by these synthesized LR$\sim$HR image pairs does not perform well when being applied to real images. In this paper, we propose a novel method to capture a large set of realistic LR$\sim$HR image pairs using real cameras. The data acquisition is carried out under controllable lab conditions with minimum human intervention and at high throughput (about 500 image pairs per hour). The high level of automation makes it easy to produce a set of real LR$\sim$HR training image pairs for each camera.Our innovation is to shoot images displayed on an ultra-high quality screen at different resolutions. There are three distinctive advantages of our method for image super-resolution. First, as the LR and HR images are taken of a 3D planar surface (the screen) the registration problem fits exactly to a homography model and we can display specially designed markers on the image to improve the registration precision. Second, the displayed digital image file can be exploited as a reference to optimize the high frequency content of the restored image. Third, this high-efficiency data collection method makes it possible to collect a customized dataset for each camera sensor, for which one can train a specific model for the intended camera sensor. Experimental results show that training a super-resolution CNN by our LR$\sim$HR dataset has superior restoration performance than training it by existing datasets on real world images at the inference stage.
Multi-modality Deep Restoration of Extremely Compressed Face Videos
Jul 05, 2021
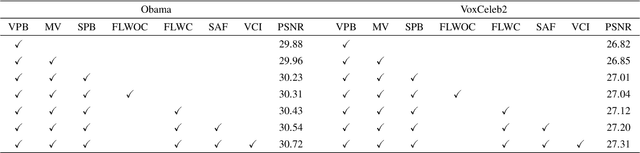
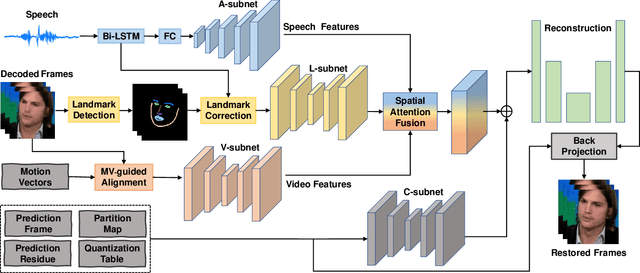

Arguably the most common and salient object in daily video communications is the talking head, as encountered in social media, virtual classrooms, teleconferences, news broadcasting, talk shows, etc. When communication bandwidth is limited by network congestions or cost effectiveness, compression artifacts in talking head videos are inevitable. The resulting video quality degradation is highly visible and objectionable due to high acuity of human visual system to faces. To solve this problem, we develop a multi-modality deep convolutional neural network method for restoring face videos that are aggressively compressed. The main innovation is a new DCNN architecture that incorporates known priors of multiple modalities: the video-synchronized speech signal and semantic elements of the compression code stream, including motion vectors, code partition map and quantization parameters. These priors strongly correlate with the latent video and hence they are able to enhance the capability of deep learning to remove compression artifacts. Ample empirical evidences are presented to validate the superior performance of the proposed DCNN method on face videos over the existing state-of-the-art methods.
Light Pollution Reduction in Nighttime Photography
Jun 18, 2021
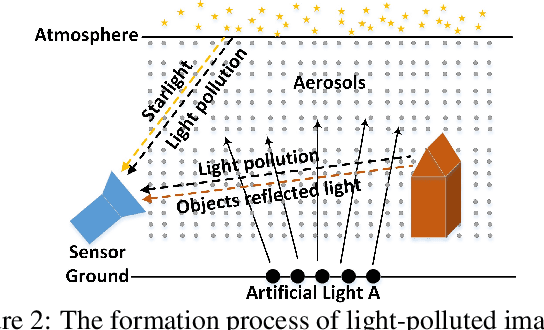
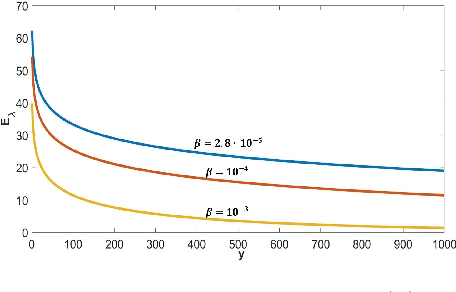
Nighttime photographers are often troubled by light pollution of unwanted artificial lights. Artificial lights, after scattered by aerosols in the atmosphere, can inundate the starlight and degrade the quality of nighttime images, by reducing contrast and dynamic range and causing hazes. In this paper we develop a physically-based light pollution reduction (LPR) algorithm that can substantially alleviate the aforementioned degradations of perceptual quality and restore the pristine state of night sky. The key to the success of the proposed LPR algorithm is an inverse method to estimate the spatial radiance distribution and spectral signature of ground artificial lights. Extensive experiments are carried out to evaluate the efficacy and limitations of the LPR algorithm.
Attention-guided Image Compression by Deep Reconstruction of Compressive Sensed Saliency Skeleton
Mar 29, 2021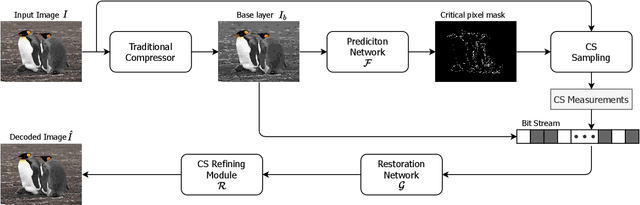
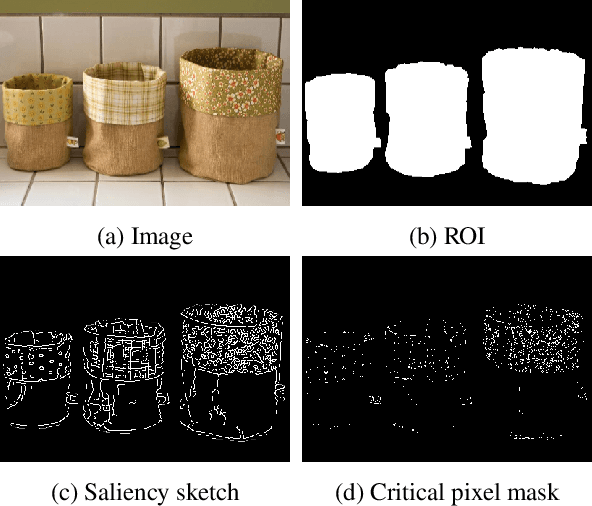
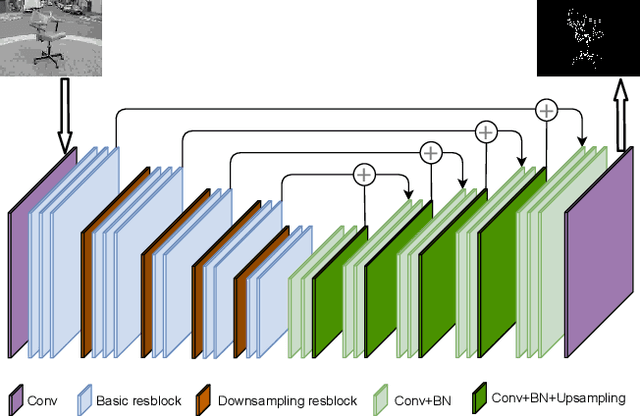
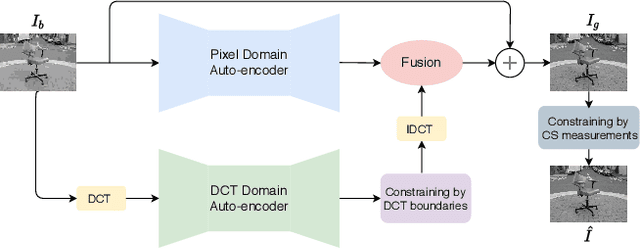
We propose a deep learning system for attention-guided dual-layer image compression (AGDL). In the AGDL compression system, an image is encoded into two layers, a base layer and an attention-guided refinement layer. Unlike the existing ROI image compression methods that spend an extra bit budget equally on all pixels in ROI, AGDL employs a CNN module to predict those pixels on and near a saliency sketch within ROI that are critical to perceptual quality. Only the critical pixels are further sampled by compressive sensing (CS) to form a very compact refinement layer. Another novel CNN method is developed to jointly decode the two compression layers for a much refined reconstruction, while strictly satisfying the transmitted CS constraints on perceptually critical pixels. Extensive experiments demonstrate that the proposed AGDL system advances the state of the art in perception-aware image compression.
Deep Multi-modality Soft-decoding of Very Low Bit-rate Face Videos
Aug 02, 2020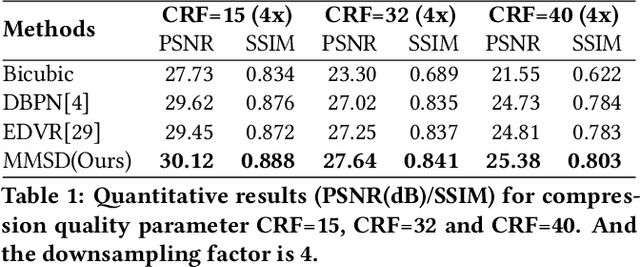
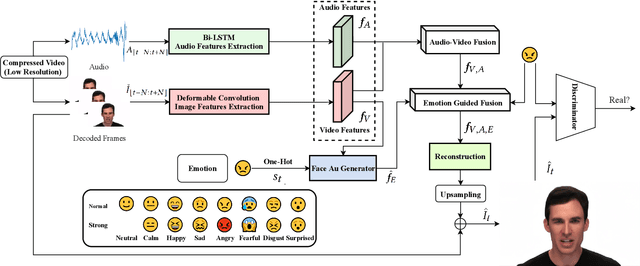
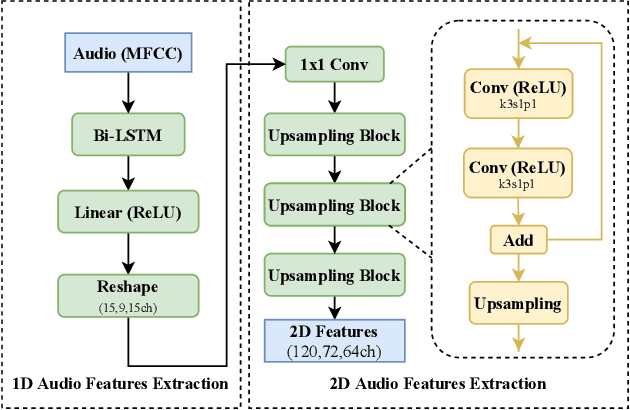
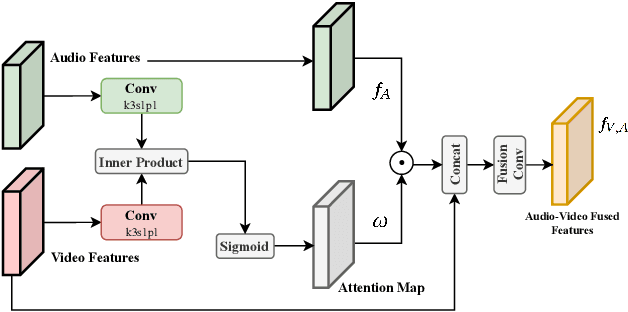
We propose a novel deep multi-modality neural network for restoring very low bit rate videos of talking heads. Such video contents are very common in social media, teleconferencing, distance education, tele-medicine, etc., and often need to be transmitted with limited bandwidth. The proposed CNN method exploits the correlations among three modalities, video, audio and emotion state of the speaker, to remove the video compression artifacts caused by spatial down sampling and quantization. The deep learning approach turns out to be ideally suited for the video restoration task, as the complex non-linear cross-modality correlations are very difficult to model analytically and explicitly. The new method is a video post processor that can significantly boost the perceptual quality of aggressively compressed talking head videos, while being fully compatible with all existing video compression standards.
* Accepted by Proceedings of the 28th ACM International Conference on Multimedia(ACM MM),2020
Rapid Whole Slide Imaging via Learning-based Two-shot Virtual Autofocusing
Mar 14, 2020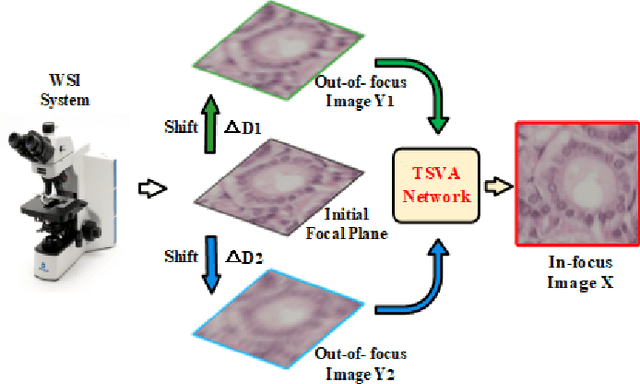
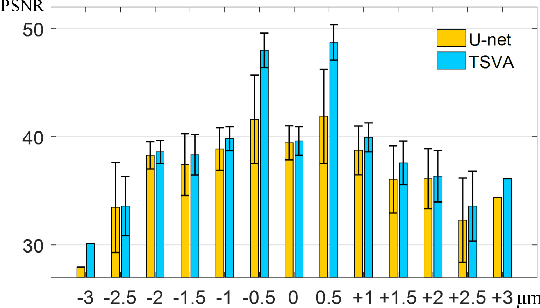
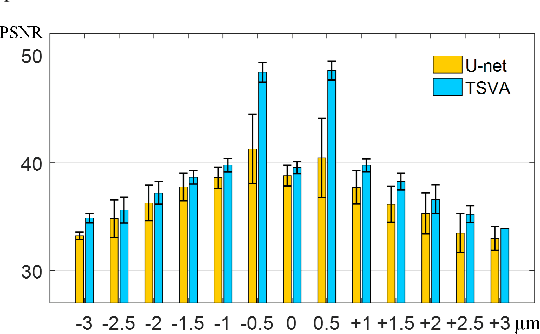
Whole slide imaging (WSI) is an emerging technology for digital pathology. The process of autofocusing is the main influence of the performance of WSI. Traditional autofocusing methods either are time-consuming due to repetitive mechanical motions, or require additional hardware and thus are not compatible to current WSI systems. In this paper, we propose the concept of \textit{virtual autofocusing}, which does not rely on mechanical adjustment to conduct refocusing but instead recovers in-focus images in an offline learning-based manner. With the initial focal position, we only perform two-shot imaging, in contrast traditional methods commonly need to conduct as many as 21 times image shooting in each tile scanning. Considering that the two captured out-of-focus images retain pieces of partial information about the underlying in-focus image, we propose a U-Net-inspired deep neural network based approach for fusing them into a recovered in-focus image. The proposed scheme is fast in tissue slides scanning, enabling a high-throughput generation of digital pathology images. Experimental results demonstrate that our scheme achieves satisfactory refocusing performance.
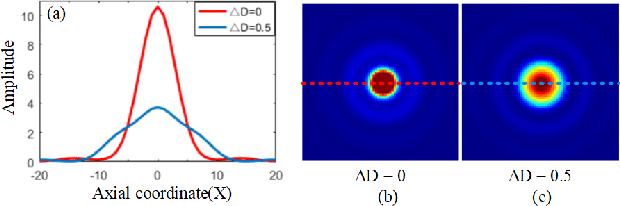
Ultra High Fidelity Image Compression with $\ell_\infty$-constrained Encoding and Deep Decoding
Feb 10, 2020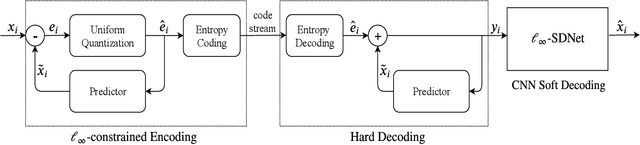



In many professional fields, such as medicine, remote sensing and sciences, users often demand image compression methods to be mathematically lossless. But lossless image coding has a rather low compression ratio (around 2:1 for natural images). The only known technique to achieve significant compression while meeting the stringent fidelity requirements is the methodology of $\ell_\infty$-constrained coding that was developed and standardized in nineties. We make a major progress in $\ell_\infty$-constrained image coding after two decades, by developing a novel CNN-based soft $\ell_\infty$-constrained decoding method. The new method repairs compression defects by using a restoration CNN called the $\ell_\infty\mbox{-SDNet}$ to map a conventionally decoded image to the latent image. A unique strength of the $\ell_\infty\mbox{-SDNet}$ is its ability to enforce a tight error bound on a per pixel basis. As such, no small distinctive structures of the original image can be dropped or distorted, even if they are statistical outliers that are otherwise sacrificed by mainstream CNN restoration methods. More importantly, this research ushers in a new image compression system of $\ell_\infty$-constrained encoding and deep soft decoding ($\ell_\infty\mbox{-ED}^2$). The $\ell_\infty \mbox{-ED}^2$ approach beats the best of existing lossy image compression methods (e.g., BPG, WebP, etc.) not only in $\ell_\infty$ but also in $\ell_2$ error metric and perceptual quality, for bit rates near the threshold of perceptually transparent reconstruction. Operationally, the new compression system is practical, with a low-complexity real-time encoder and a cascade decoder consisting of a fast initial decoder and an optional CNN soft decoder.
Lossless Compression of Mosaic Images with Convolutional Neural Network Prediction
Jan 28, 2020
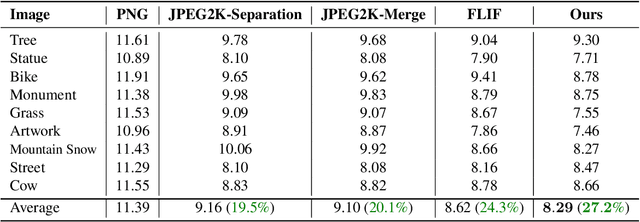
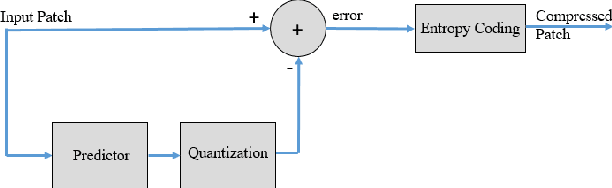
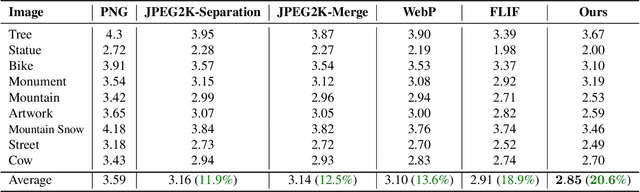
We present a CNN-based predictive lossless compression scheme for raw color mosaic images of digital cameras. This specialized application problem was previously understudied but it is now becoming increasingly important, because modern CNN methods for image restoration tasks (e.g., superresolution, low lighting enhancement, deblurring), must operate on original raw mosaic images to obtain the best possible results. The key innovation of this paper is a high-order nonlinear CNN predictor of spatial-spectral mosaic patterns. The deep learning prediction can model highly complex sample dependencies in spatial-spectral mosaic images more accurately and hence remove statistical redundancies more thoroughly than existing image predictors. Experiments show that the proposed CNN predictor achieves unprecedented lossless compression performance on camera raw images.