 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaicIMU: Composing Carrier Experts for Generalizable Neural Inertial Odometry
Jun 08, 2026Robust inertial odometry is essential for various carriers when external sensing is unreliable. Learning-based methods reduce integration drift by capturing local motion priors, but these methods often remain tied to a particular carrier, limiting generalization across heterogeneous platforms. We present MosaicIMU, a carrier-conditioned Mixture-of-Experts (MoE) pretraining-and-adaptation framework for generalizable neural inertial odometry. MosaicIMU uses a prototype-based router to compose carrier-specific expert features, decodes local velocity and uncertainty constraints, and integrates them with a history-aware EKF. For unseen domain adaptation, it freezes the pretrained base model and learns a new lightweight expert residual branch. For edge-deployment, it further reuses the router to select informative online samples for efficient incremental updates. Experiments show that MosaicIMU consistently outperforms learning-based baselines, reducing average ATE and RTE-10s by 40% and 34%, respectively. These results highlight that MosaicIMU provides a scalable pretraining-to-deployment paradigm for generalizable and adaptive neural inertial odometry.
Depth estimation of a monoharmonic source using a vertical linear array at fixed distance
Feb 05, 2026Estimating the depth of a monoharmonic sound source at a fixed range using a vertical linear array (VLA) is challenging in the absence of seabed environmental parameters, and relevant research remains scarce. The orthogonality constrained modal search based depth estimation (OCMS-D) method is proposed in this paper, which enables the estimation of the depth of a monoharmonic source at a fixed range using a VLA under unknown seabed parameters. Using the sparsity of propagating normal modes and the orthogonality of mode depth functions, OCMS-D estimates the normal mode parameters under a fixed source-array distance at first. The estimated normal mode parameters are then used to estimate the source depth. To ensure the precision of the source depth estimation, the method utilizes information on both the amplitude distribution and the sign (positive/negative) patterns of the estimated mode depth functions at the inferred source depth. Numerical simulations evaluate the performance of OCMS-D under different conditions. The effectiveness of OCMS-D is also verified by the Yellow Sea experiment and the SWellEx-96 experiment. In the Yellow Sea experiment, the depth estimation absolute errors by OCMS-D with a 4-second time window are less than 2.4 m. And the depth estimation absolute errors in the SWellEx-96 experiment with a 10-second time window are less than 5.4 m for the shallow source and less than 10.8 m for the deep source.
From Exploration to Exploitation: A Two-Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training
Nov 11, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) for Multimodal Large Language Models (MLLMs) is highly dependent on high-quality labeled data, which is often scarce and prone to substantial annotation noise in real-world scenarios. Existing unsupervised RLVR methods, including pure entropy minimization, can overfit to incorrect labels and limit the crucial reward ranking signal for Group-Relative Policy Optimization (GRPO). To address these challenges and enhance noise tolerance, we propose a novel two-stage, token-level entropy optimization method for RLVR. This approach dynamically guides the model from exploration to exploitation during training. In the initial exploration phase, token-level entropy maximization promotes diverse and stochastic output generation, serving as a strong regularizer that prevents premature convergence to noisy labels and ensures sufficient intra-group variation, which enables more reliable reward gradient estimation in GRPO. As training progresses, the method transitions into the exploitation phase, where token-level entropy minimization encourages the model to produce confident and deterministic outputs, thereby consolidating acquired knowledge and refining prediction accuracy. Empirically, across three MLLM backbones - Qwen2-VL-2B, Qwen2-VL-7B, and Qwen2.5-VL-3B - spanning diverse noise settings and multiple tasks, our phased strategy consistently outperforms prior approaches by unifying and enhancing external, internal, and entropy-based methods, delivering robust and superior performance across the board.
MPGNet: Learning Move-Push-Grasping Synergy for Target-Oriented Grasping in Occluded Scenes
Aug 20, 2024



This paper focuses on target-oriented grasping in occluded scenes, where the target object is specified by a binary mask and the goal is to grasp the target object with as few robotic manipulations as possible. Most existing methods rely on a push-grasping synergy to complete this task. To deliver a more powerful target-oriented grasping pipeline, we present MPGNet, a three-branch network for learning a synergy between moving, pushing, and grasping actions. We also propose a multi-stage training strategy to train the MPGNet which contains three policy networks corresponding to the three actions. The effectiveness of our method is demonstrated via both simulated and real-world experiments.
3-D Distributed Localization with Mixed Local Relative Measurements
Dec 18, 2023This paper studies 3-D distributed network localization using mixed types of local relative measurements. Each node holds a local coordinate frame without a common orientation and can only measure one type of information (relative position, distance, relative bearing, angle, or ratio-of-distance measurements) about its neighboring nodes in its local coordinate frame. A novel rigidity-theory-based distributed localization is developed to overcome the challenge due to the absence of a global coordinate frame. The main idea is to construct displacement constraints for the positions of the nodes by using mixed local relative measurements. Then, a linear distributed localization algorithm is proposed for each free node to estimate its position by solving the displacement constraints. The algebraic condition and graph condition are obtained to guarantee the global convergence of the proposed distributed localization algorithm.
Training a U-Net based on a random mode-coupling matrix model to recover acoustic interference striations
Mar 24, 2020A U-Net is trained to recover acoustic interference striations (AISs) from distorted ones. A random mode-coupling matrix model is introduced to generate a large number of training data quickly, which are used to train the U-Net. The performance of AIS recovery of the U-Net is tested in range-dependent waveguides with nonlinear internal waves (NLIWs). Although the random mode-coupling matrix model is not an accurate physical model, the test results show that the U-Net successfully recovers AISs under different signal-to-noise ratios (SNRs) and different amplitudes and widths of NLIWs for different shapes.
Sound source ranging using a feed-forward neural network with fitting-based early stopping
Apr 01, 2019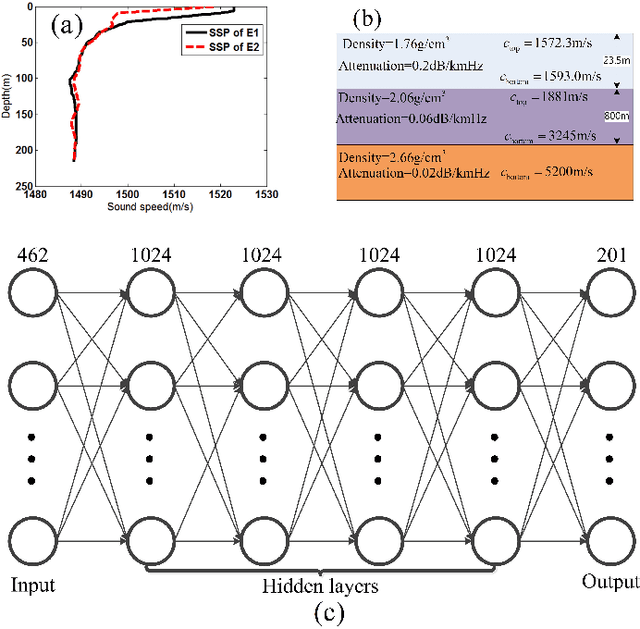
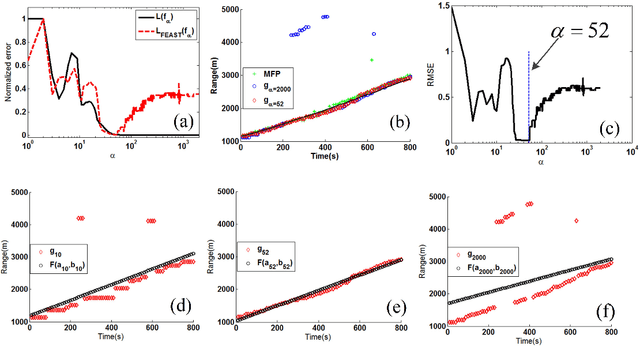
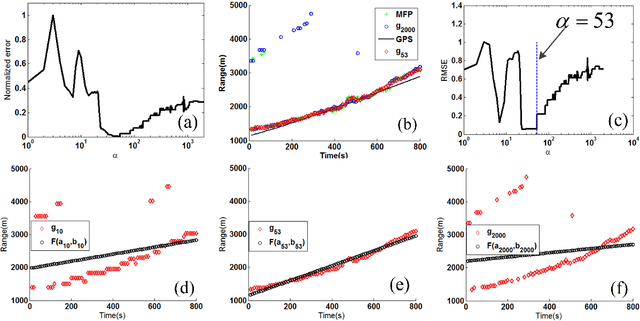
When a feed-forward neural network (FNN) is trained for source ranging in an ocean waveguide, it is difficult evaluating the range accuracy of the FNN on unlabeled test data. A fitting-based early stopping (FEAST) method is introduced to evaluate the range error of the FNN on test data where the distance of source is unknown. Based on FEAST, when the evaluated range error of the FNN reaches the minimum on test data, stopping training, which will help to improve the ranging accuracy of the FNN on the test data. The FEAST is demonstrated on simulated and experimental data.