 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDoG: Adversarial Edge Detection For Graph Neural Networks
Dec 27, 2022Graph Neural Networks (GNNs) have been widely applied to different tasks such as bioinformatics, drug design, and social networks. However, recent studies have shown that GNNs are vulnerable to adversarial attacks which aim to mislead the node or subgraph classification prediction by adding subtle perturbations. Detecting these attacks is challenging due to the small magnitude of perturbation and the discrete nature of graph data. In this paper, we propose a general adversarial edge detection pipeline EDoG without requiring knowledge of the attack strategies based on graph generation. Specifically, we propose a novel graph generation approach combined with link prediction to detect suspicious adversarial edges. To effectively train the graph generative model, we sample several sub-graphs from the given graph data. We show that since the number of adversarial edges is usually low in practice, with low probability the sampled sub-graphs will contain adversarial edges based on the union bound. In addition, considering the strong attacks which perturb a large number of edges, we propose a set of novel features to perform outlier detection as the preprocessing for our detection. Extensive experimental results on three real-world graph datasets including a private transaction rule dataset from a major company and two types of synthetic graphs with controlled properties show that EDoG can achieve above 0.8 AUC against four state-of-the-art unseen attack strategies without requiring any knowledge about the attack type; and around 0.85 with knowledge of the attack type. EDoG significantly outperforms traditional malicious edge detection baselines. We also show that an adaptive attack with full knowledge of our detection pipeline is difficult to bypass it.
UniFed: A Benchmark for Federated Learning Frameworks
Jul 21, 2022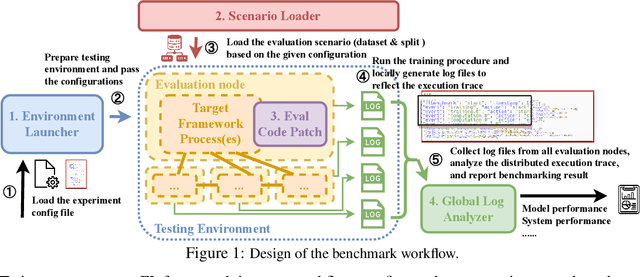
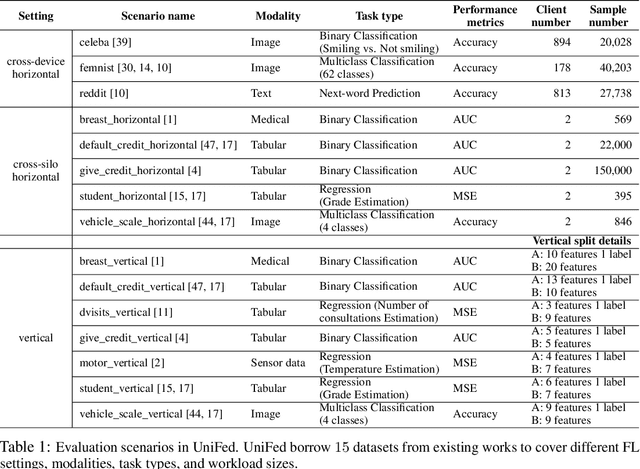
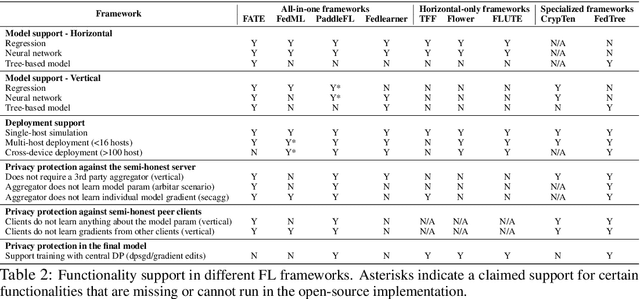
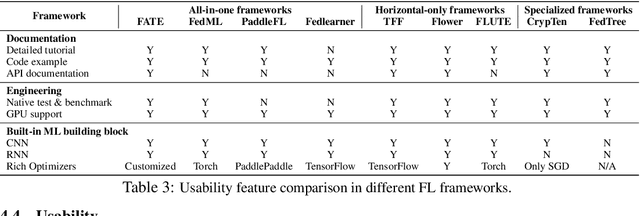
Federated Learning (FL) has become a practical and popular paradigm in machine learning. However, currently, there is no systematic solution that covers diverse use cases. Practitioners often face the challenge of how to select a matching FL framework for their use case. In this work, we present UniFed, the first unified benchmark for standardized evaluation of the existing open-source FL frameworks. With 15 evaluation scenarios, we present both qualitative and quantitative evaluation results of nine existing popular open-sourced FL frameworks, from the perspectives of functionality, usability, and system performance. We also provide suggestions on framework selection based on the benchmark conclusions and point out future improvement directions.
Adversarially Robust Models may not Transfer Better: Sufficient Conditions for Domain Transferability from the View of Regularization
Feb 03, 2022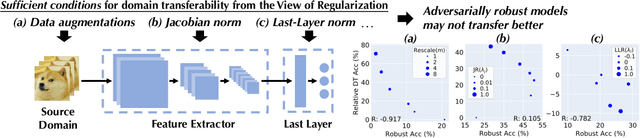
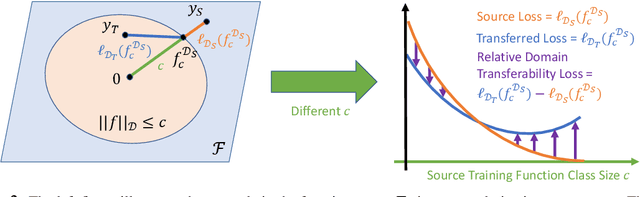
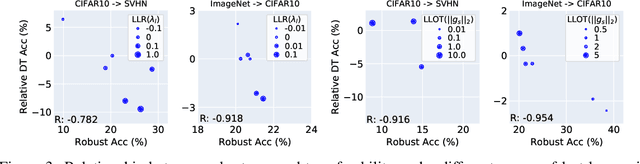
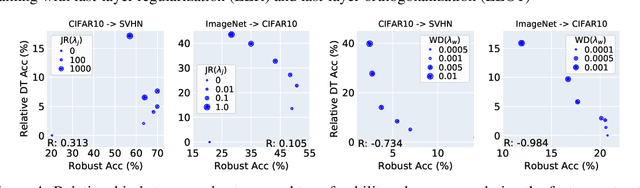
Machine learning (ML) robustness and domain generalization are fundamentally correlated: they essentially concern data distribution shifts under adversarial and natural settings, respectively. On one hand, recent studies show that more robust (adversarially trained) models are more generalizable. On the other hand, there is a lack of theoretical understanding of their fundamental connections. In this paper, we explore the relationship between regularization and domain transferability considering different factors such as norm regularization and data augmentations (DA). We propose a general theoretical framework proving that factors involving the model function class regularization are sufficient conditions for relative domain transferability. Our analysis implies that "robustness" is neither necessary nor sufficient for transferability; rather, robustness induced by adversarial training is a by-product of such function class regularization. We then discuss popular DA protocols and show when they can be viewed as the function class regularization under certain conditions and therefore improve generalization. We conduct extensive experiments to verify our theoretical findings and show several counterexamples where robustness and generalization are negatively correlated on different datasets.
On the Certified Robustness for Ensemble Models and Beyond
Jul 22, 2021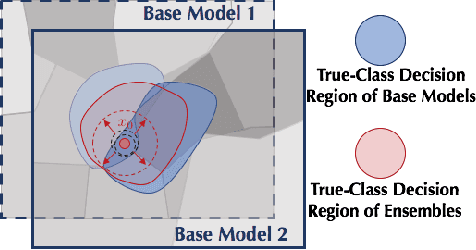
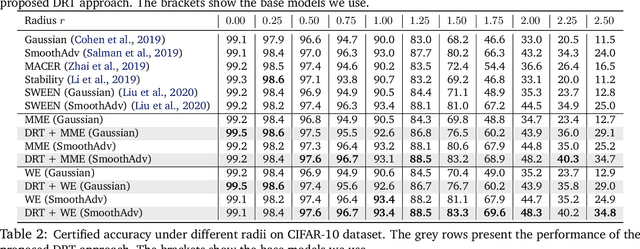
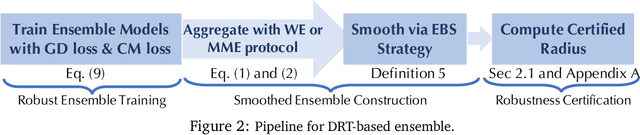
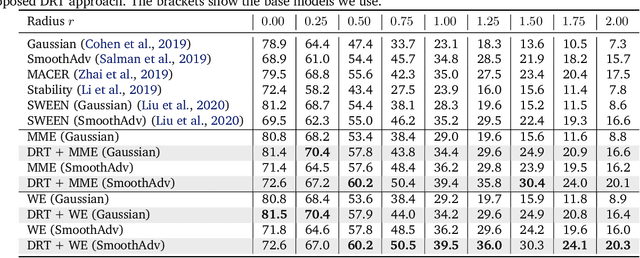
Recent studies show that deep neural networks (DNN) are vulnerable to adversarial examples, which aim to mislead DNNs by adding perturbations with small magnitude. To defend against such attacks, both empirical and theoretical defense approaches have been extensively studied for a single ML model. In this work, we aim to analyze and provide the certified robustness for ensemble ML models, together with the sufficient and necessary conditions of robustness for different ensemble protocols. Although ensemble models are shown more robust than a single model empirically; surprisingly, we find that in terms of the certified robustness the standard ensemble models only achieve marginal improvement compared to a single model. Thus, to explore the conditions that guarantee to provide certifiably robust ensemble ML models, we first prove that diversified gradient and large confidence margin are sufficient and necessary conditions for certifiably robust ensemble models under the model-smoothness assumption. We then provide the bounded model-smoothness analysis based on the proposed Ensemble-before-Smoothing strategy. We also prove that an ensemble model can always achieve higher certified robustness than a single base model under mild conditions. Inspired by the theoretical findings, we propose the lightweight Diversity Regularized Training (DRT) to train certifiably robust ensemble ML models. Extensive experiments show that our DRT enhanced ensembles can consistently achieve higher certified robustness than existing single and ensemble ML models, demonstrating the state-of-the-art certified L2-robustness on MNIST, CIFAR-10, and ImageNet datasets.
TRS: Transferability Reduced Ensemble via Encouraging Gradient Diversity and Model Smoothness
Apr 01, 2021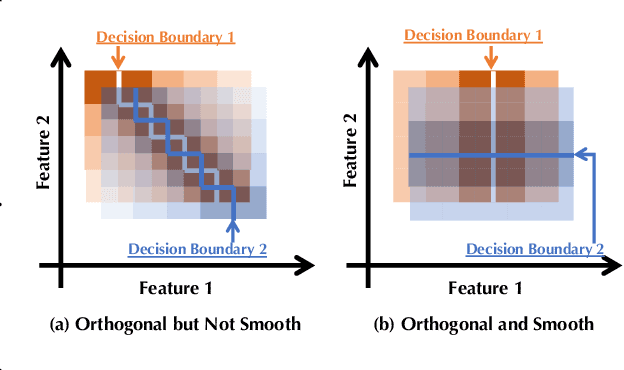
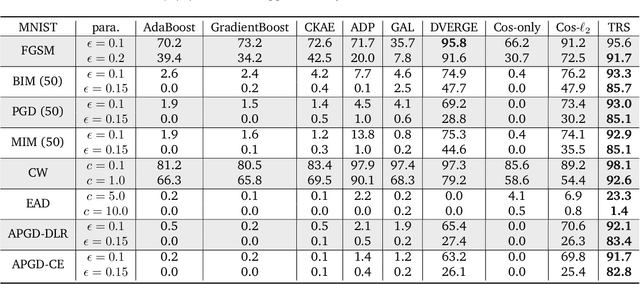
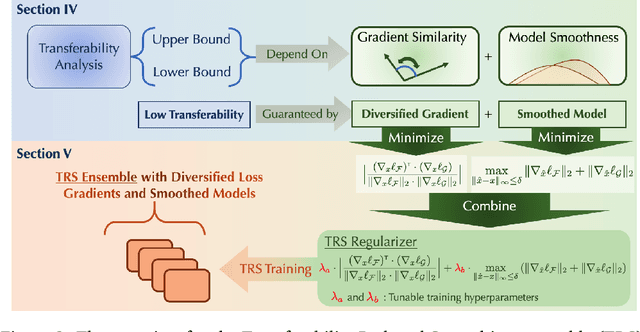
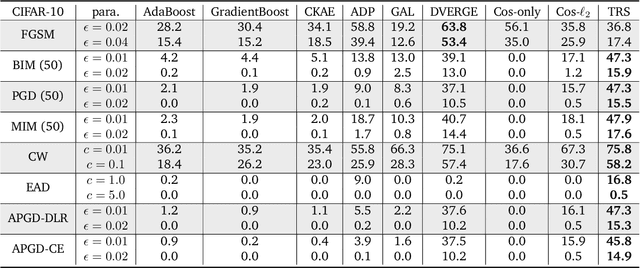
Adversarial Transferability is an intriguing property of adversarial examples -- a perturbation that is crafted against one model is also effective against another model, which may arise from a different model family or training process. To better protect ML systems against adversarial attacks, several questions are raised: what are the sufficient conditions for adversarial transferability? Is it possible to bound such transferability? Is there a way to reduce the transferability in order to improve the robustness of an ensemble ML model? To answer these questions, we first theoretically analyze sufficient conditions for transferability between models and propose a practical algorithm to reduce transferability within an ensemble to improve its robustness. Our theoretical analysis shows only the orthogonality between gradients of different models is not enough to ensure low adversarial transferability: the model smoothness is also an important factor. In particular, we provide a lower/upper bound of adversarial transferability based on model gradient similarity for low risk classifiers based on gradient orthogonality and model smoothness. We demonstrate that under the condition of gradient orthogonality, smoother classifiers will guarantee lower adversarial transferability. Furthermore, we propose an effective Transferability Reduced Smooth-ensemble(TRS) training strategy to train a robust ensemble with low transferability by enforcing model smoothness and gradient orthogonality between base models. We conduct extensive experiments on TRS by comparing with other state-of-the-art baselines on different datasets, showing that the proposed TRS outperforms all baselines significantly. We believe our analysis on adversarial transferability will inspire future research towards developing robust ML models taking these adversarial transferability properties into account.
Nonlinear Projection Based Gradient Estimation for Query Efficient Blackbox Attacks
Feb 25, 2021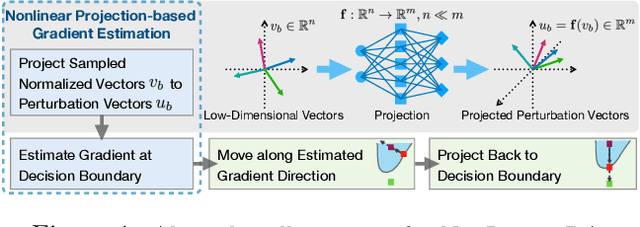

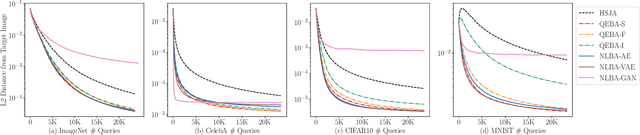
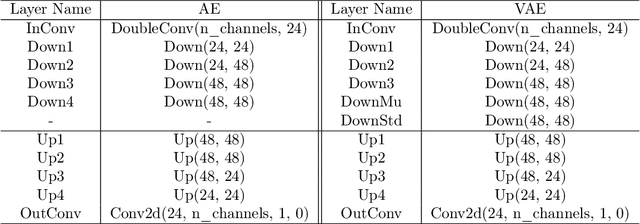
Gradient estimation and vector space projection have been studied as two distinct topics. We aim to bridge the gap between the two by investigating how to efficiently estimate gradient based on a projected low-dimensional space. We first provide lower and upper bounds for gradient estimation under both linear and nonlinear projections, and outline checkable sufficient conditions under which one is better than the other. Moreover, we analyze the query complexity for the projection-based gradient estimation and present a sufficient condition for query-efficient estimators. Built upon our theoretic analysis, we propose a novel query-efficient Nonlinear Gradient Projection-based Boundary Blackbox Attack (NonLinear-BA). We conduct extensive experiments on four image datasets: ImageNet, CelebA, CIFAR-10, and MNIST, and show the superiority of the proposed methods compared with the state-of-the-art baselines. In particular, we show that the projection-based boundary blackbox attacks are able to achieve much smaller magnitude of perturbations with 100% attack success rate based on efficient queries. Both linear and nonlinear projections demonstrate their advantages under different conditions. We also evaluate NonLinear-BA against the commercial online API MEGVII Face++, and demonstrate the high blackbox attack performance both quantitatively and qualitatively. The code is publicly available at https://github.com/AI-secure/NonLinear-BA.
QEBA: Query-Efficient Boundary-Based Blackbox Attack
May 28, 2020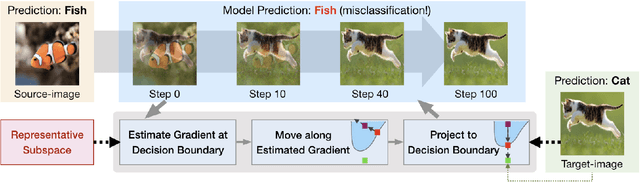
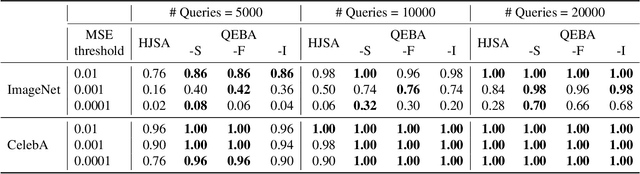
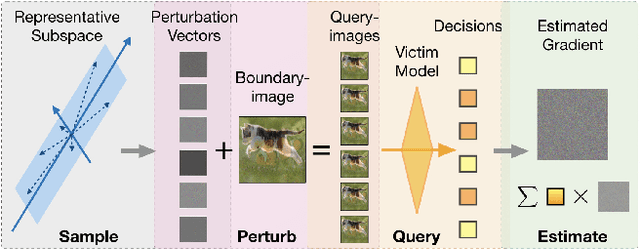
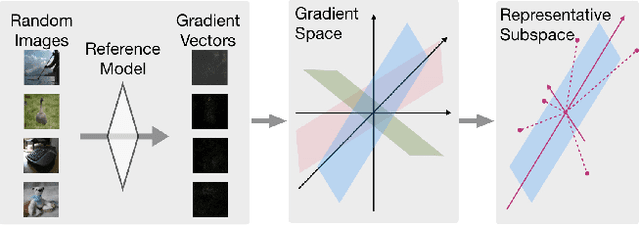
Machine learning (ML), especially deep neural networks (DNNs) have been widely used in various applications, including several safety-critical ones (e.g. autonomous driving). As a result, recent research about adversarial examples has raised great concerns. Such adversarial attacks can be achieved by adding a small magnitude of perturbation to the input to mislead model prediction. While several whitebox attacks have demonstrated their effectiveness, which assume that the attackers have full access to the machine learning models; blackbox attacks are more realistic in practice. In this paper, we propose a Query-Efficient Boundary-based blackbox Attack (QEBA) based only on model's final prediction labels. We theoretically show why previous boundary-based attack with gradient estimation on the whole gradient space is not efficient in terms of query numbers, and provide optimality analysis for our dimension reduction-based gradient estimation. On the other hand, we conducted extensive experiments on ImageNet and CelebA datasets to evaluate QEBA. We show that compared with the state-of-the-art blackbox attacks, QEBA is able to use a smaller number of queries to achieve a lower magnitude of perturbation with 100% attack success rate. We also show case studies of attacks on real-world APIs including MEGVII Face++ and Microsoft Azure.
Provable Robust Learning Based on Transformation-Specific Smoothing
Mar 20, 2020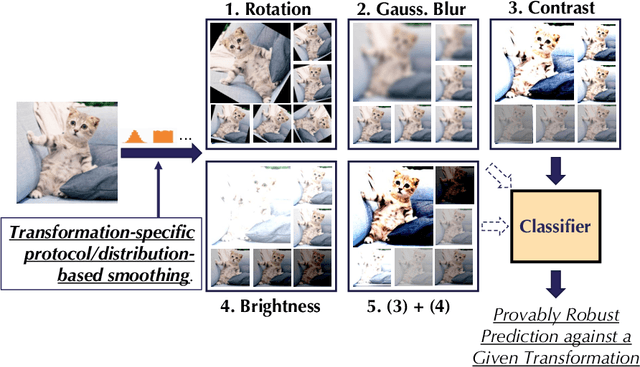

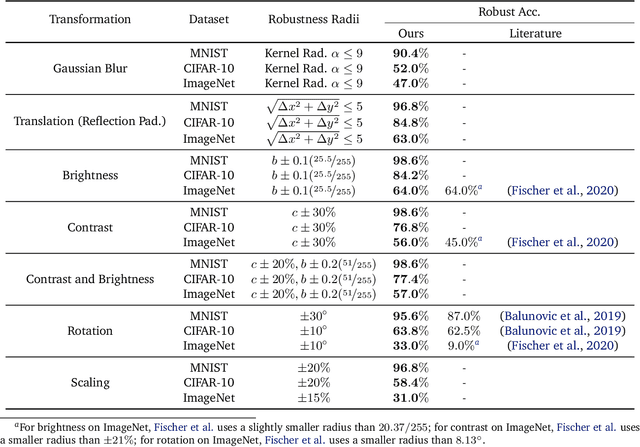
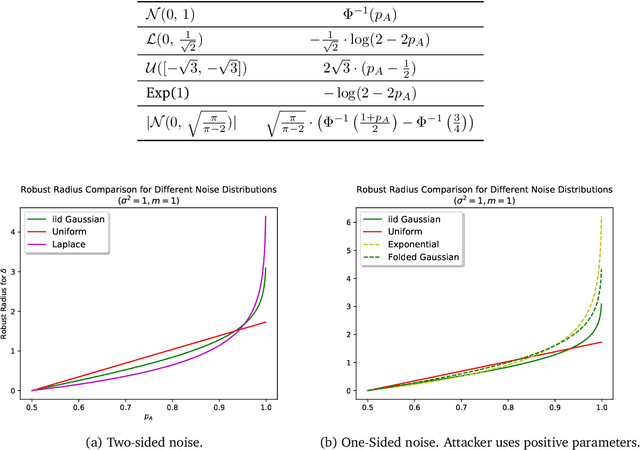
As machine learning systems become pervasive, safeguarding their security is critical. Recent work has demonstrated that motivated adversaries could manipulate the test data to mislead ML systems to make arbitrary mistakes. So far, most research has focused on providing provable robustness guarantees for a specific $\ell_p$ norm bounded adversarial perturbation. However, in practice there are more adversarial transformations that are realistic and of semantic meaning, requiring to be analyzed and ideally certified. In this paper we aim to provide a unified framework for certifying ML model robustness against general adversarial transformations. First, we leverage the function smoothing strategy to certify robustness against a series of adversarial transformations such as rotation, translation, Gaussian blur, etc. We then provide sufficient conditions and strategies for certifying certain transformations. For instance, we propose a novel sampling based interpolation approach with the estimated Lipschitz upper bound to certify the robustness against rotation transformation. In addition, we theoretically optimize the smoothing strategies for certifying the robustness of ML models against different transformations. For instance, we show that smoothing by sampling from exponential distribution provides tighter robustness bound than Gaussian. We also prove two generalization gaps for the proposed framework to understand its theoretic barrier. Extensive experiments show that our proposed unified framework significantly outperforms the state-of-the-art certified robustness approaches on several datasets including ImageNet.
RAB: Provable Robustness Against Backdoor Attacks
Mar 19, 2020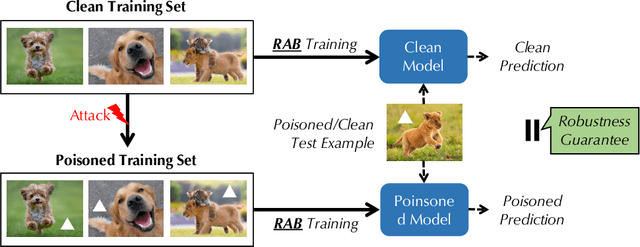
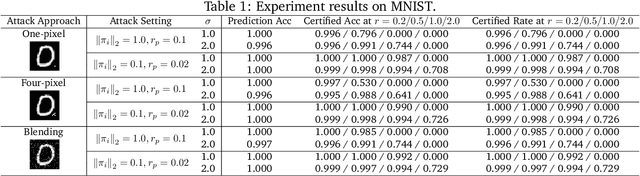
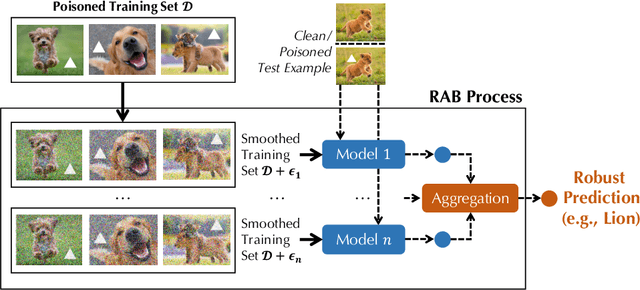
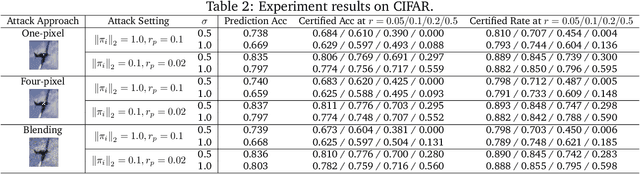
Recent studies have shown that deep neural networks (DNNs) are vulnerable to various attacks, including evasion attacks and poisoning attacks. On the defense side, there have been intensive interests in provable robustness against evasion attacks. In this paper, we focus on improving model robustness against more diverse threat models. Specifically, we provide the first unified framework using smoothing functional to certify the model robustness against general adversarial attacks. In particular, we propose the first robust training process RAB to certify against backdoor attacks. We theoretically prove the robustness bound for machine learning models based on the RAB training process, analyze the tightness of the robustness bound, as well as proposing different smoothing noise distributions such as Gaussian and Uniform distributions. Moreover, we evaluate the certified robustness of a family of "smoothed" DNNs which are trained in a differentially private fashion. In addition, we theoretically show that for simpler models such as K-nearest neighbor models, it is possible to train the robust smoothed models efficiently. For K=1, we propose an exact algorithm to smooth the training process, eliminating the need to sample from a noise distribution.Empirically, we conduct comprehensive experiments for different machine learning models such as DNNs, differentially private DNNs, and KNN models on MNIST, CIFAR-10 and ImageNet datasets to provide the first benchmark for certified robustness against backdoor attacks. In particular, we also evaluate KNN models on a spambase tabular dataset to demonstrate its advantages. Both the theoretic analysis for certified model robustness against arbitrary backdoors, and the comprehensive benchmark on diverse ML models and datasets would shed light on further robust learning strategies against training time or even general adversarial attacks on ML models.
Detecting AI Trojans Using Meta Neural Analysis
Oct 09, 2019
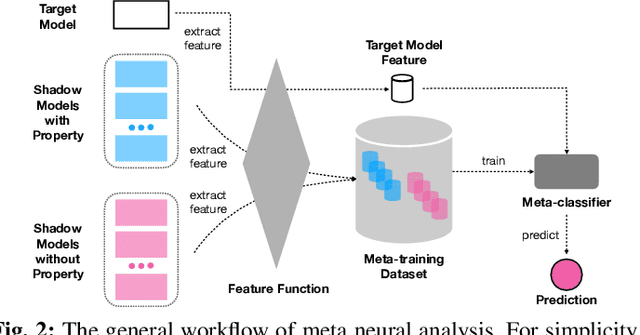


Machine learning models, especially neural networks (NNs), have achieved outstanding performance on diverse and complex applications. However, recent work has found that they are vulnerable to Trojan attacks where an adversary trains a corrupted model with poisoned data or directly manipulates its parameters in a stealthy way. Such Trojaned models can obtain good performance on normal data during test time while predicting incorrectly on the adversarially manipulated data samples. This paper aims to develop ways to detect Trojaned models. We mainly explore the idea of meta neural analysis, a technique involving training a meta NN model that can be used to predict whether or not a target NN model has certain properties. We develop a novel pipeline Meta Neural Trojaned model Detection (MNTD) system to predict if a given NN is Trojaned via meta neural analysis on a set of trained shadow models. We propose two ways to train the meta-classifier without knowing the Trojan attacker's strategies. The first one, one-class learning, will fit a novel detection meta-classifier using only benign neural networks. The second one, called jumbo learning, will approximate a general distribution of Trojaned models and sample a "jumbo" set of Trojaned models to train the meta-classifier and evaluate on the unseen Trojan strategies. Extensive experiments demonstrate the effectiveness of MNTD in detecting different Trojan attacks in diverse areas such as vision, speech, tabular data, and natural language processing. We show that MNTD reaches an average of 97% detection AUC (Area Under the ROC Curve) score and outperforms existing approaches. Furthermore, we design and evaluate MNTD system to defend against strong adaptive attackers who have exactly the knowledge of the detection, which demonstrates the robustness of MNTD.