 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing on Persons: Colorizing Old Images Learning from Modern Historical Movies
Aug 14, 2021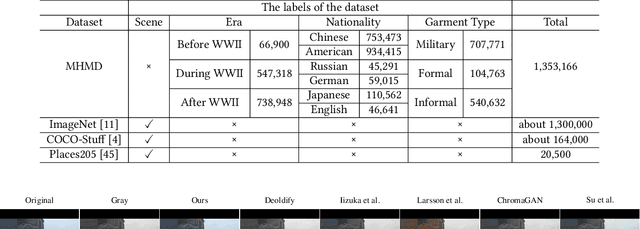
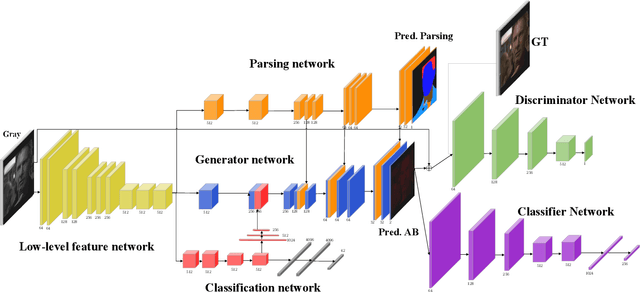
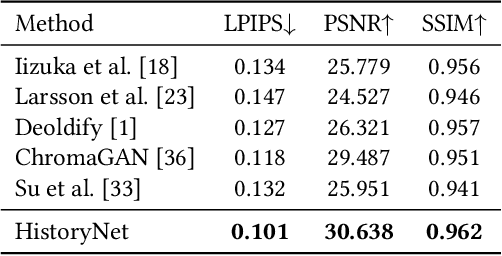
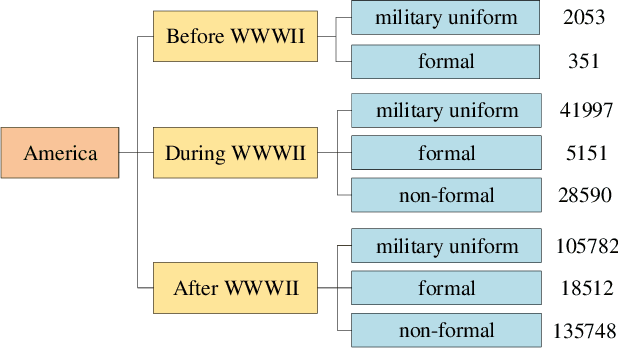
In industry, there exist plenty of scenarios where old gray photos need to be automatically colored, such as video sites and archives. In this paper, we present the HistoryNet focusing on historical person's diverse high fidelity clothing colorization based on fine grained semantic understanding and prior. Colorization of historical persons is realistic and practical, however, existing methods do not perform well in the regards. In this paper, a HistoryNet including three parts, namely, classification, fine grained semantic parsing and colorization, is proposed. Classification sub-module supplies classifying of images according to the eras, nationalities and garment types; Parsing sub-network supplies the semantic for person contours, clothing and background in the image to achieve more accurate colorization of clothes and persons and prevent color overflow. In the training process, we integrate classification and semantic parsing features into the coloring generation network to improve colorization. Through the design of classification and parsing subnetwork, the accuracy of image colorization can be improved and the boundary of each part of image can be more clearly. Moreover, we also propose a novel Modern Historical Movies Dataset (MHMD) containing 1,353,166 images and 42 labels of eras, nationalities, and garment types for automatic colorization from 147 historical movies or TV series made in modern time. Various quantitative and qualitative comparisons demonstrate that our method outperforms the state-of-the-art colorization methods, especially on military uniforms, which has correct colors according to the historical literatures.
Generating Large-scale Dynamic Optimization Problem Instances Using the Generalized Moving Peaks Benchmark
Jul 23, 2021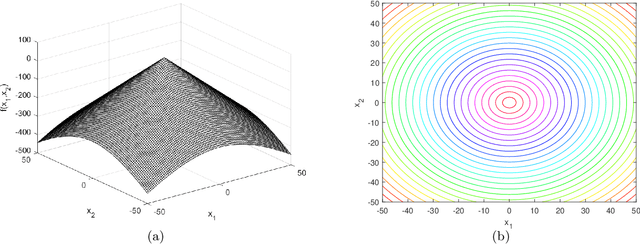

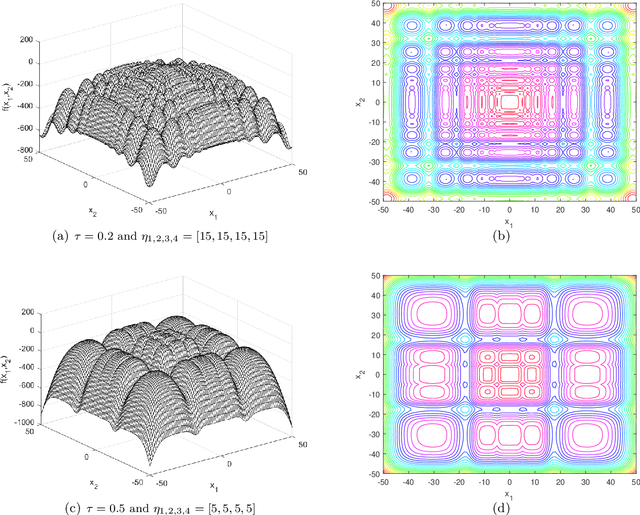

This document describes the generalized moving peaks benchmark (GMPB) and how it can be used to generate problem instances for continuous large-scale dynamic optimization problems. It presents a set of 15 benchmark problems, the relevant source code, and a performance indicator, designed for comparative studies and competitions in large-scale dynamic optimization. Although its primary purpose is to provide a coherent basis for running competitions, its generality allows the interested reader to use this document as a guide to design customized problem instances to investigate issues beyond the scope of the presented benchmark suite. To this end, we explain the modular structure of the GMPB and how its constituents can be assembled to form problem instances with a variety of controllable characteristics ranging from unimodal to highly multimodal, symmetric to highly asymmetric, smooth to highly irregular, and various degrees of variable interaction and ill-conditioning.
Linear Polytree Structural Equation Models: Structural Learning and Inverse Correlation Estimation
Jul 22, 2021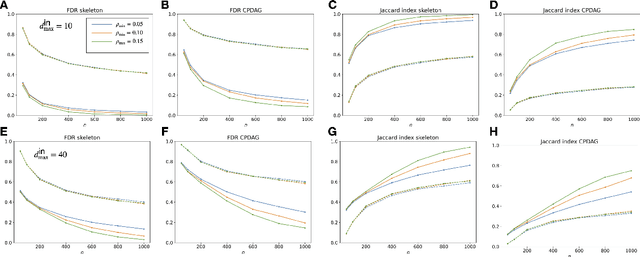
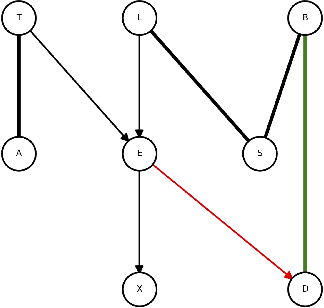
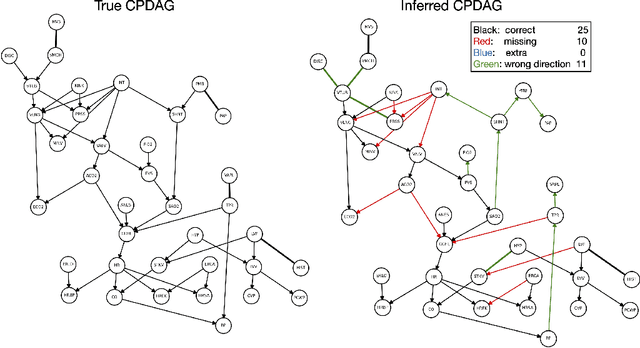
We are interested in the problem of learning the directed acyclic graph (DAG) when data are generated from a linear structural equation model (SEM) and the causal structure can be characterized by a polytree. Specially, under both Gaussian and sub-Gaussian models, we study the sample size conditions for the well-known Chow-Liu algorithm to exactly recover the equivalence class of the polytree, which is uniquely represented by a CPDAG. We also study the error rate for the estimation of the inverse correlation matrix under such models. Our theoretical findings are illustrated by comprehensive numerical simulations, and experiments on benchmark data also demonstrate the robustness of the method when the ground truth graphical structure can only be approximated by a polytree.
Learning Primal Heuristics for Mixed Integer Programs
Jul 02, 2021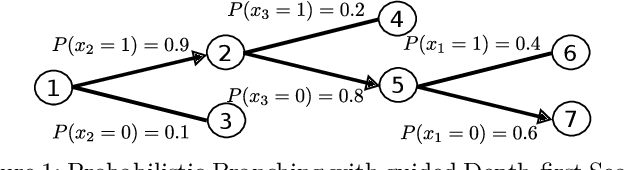
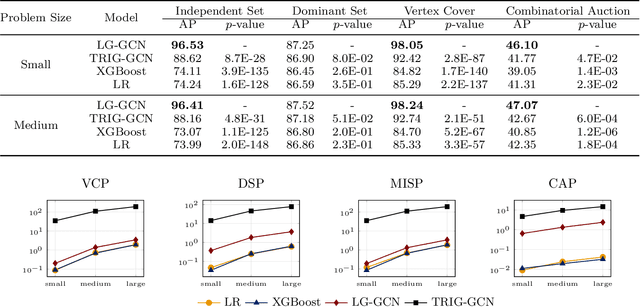
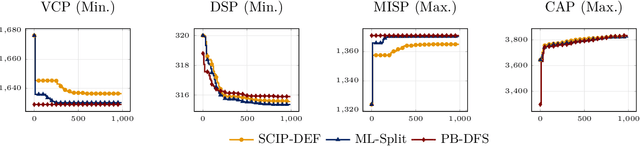
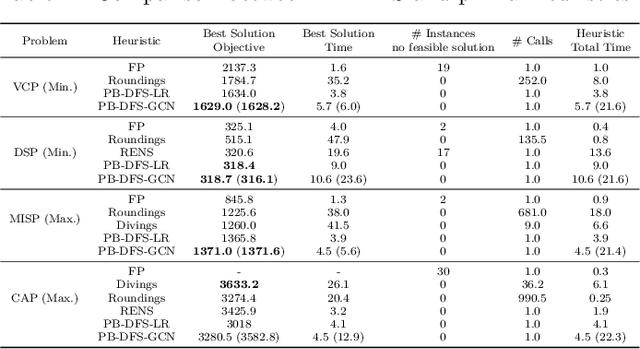
This paper proposes a novel primal heuristic for Mixed Integer Programs, by employing machine learning techniques. Mixed Integer Programming is a general technique for formulating combinatorial optimization problems. Inside a solver, primal heuristics play a critical role in finding good feasible solutions that enable one to tighten the duality gap from the outset of the Branch-and-Bound algorithm (B&B), greatly improving its performance by pruning the B&B tree aggressively. In this paper, we investigate whether effective primal heuristics can be automatically learned via machine learning. We propose a new method to represent an optimization problem as a graph, and train a Graph Convolutional Network on solved problem instances with known optimal solutions. This in turn can predict the values of decision variables in the optimal solution for an unseen problem instance of a similar type. The prediction of variable solutions is then leveraged by a novel configuration of the B&B method, Probabilistic Branching with guided Depth-first Search (PB-DFS) approach, aiming to find (near-)optimal solutions quickly. The experimental results show that this new heuristic can find better primal solutions at a much earlier stage of the solving process, compared to other state-of-the-art primal heuristics.
A Simultaneous Denoising and Dereverberation Framework with Target Decoupling
Jun 24, 2021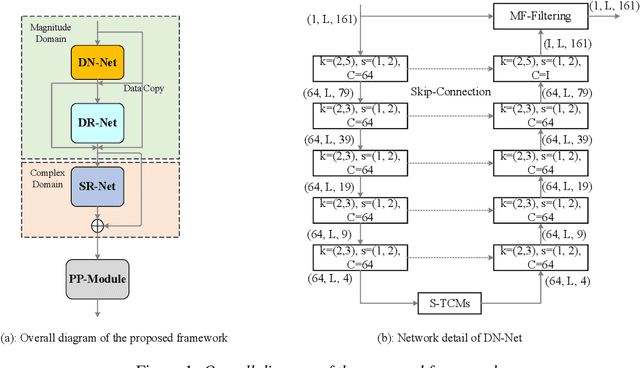
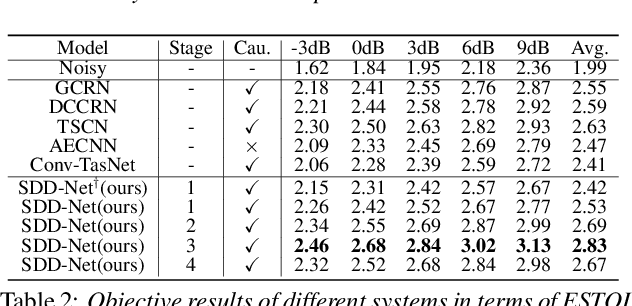
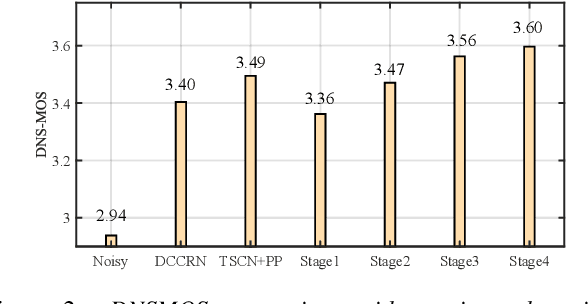
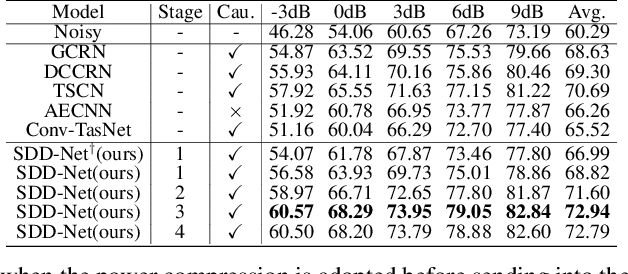
Background noise and room reverberation are regarded as two major factors to degrade the subjective speech quality. In this paper, we propose an integrated framework to address simultaneous denoising and dereverberation under complicated scenario environments. It adopts a chain optimization strategy and designs four sub-stages accordingly. In the first two stages, we decouple the multi-task learning w.r.t. complex spectrum into magnitude and phase, and only implement noise and reverberation removal in the magnitude domain. Based on the estimated priors above, we further polish the spectrum in the third stage, where both magnitude and phase information are explicitly repaired with the residual learning. Due to the data mismatch and nonlinear effect of DNNs, the residual noise often exists in the DNN-processed spectrum. To resolve the problem, we adopt a light-weight algorithm as the post-processing module to capture and suppress the residual noise in the non-active regions. In the Interspeech 2021 Deep Noise Suppression (DNS) Challenge, our submitted system ranked top-1 for the real-time track in terms of Mean Opinion Score (MOS) with ITU-T P.835 framework
Glance and Gaze: A Collaborative Learning Framework for Single-channel Speech Enhancement
Jun 22, 2021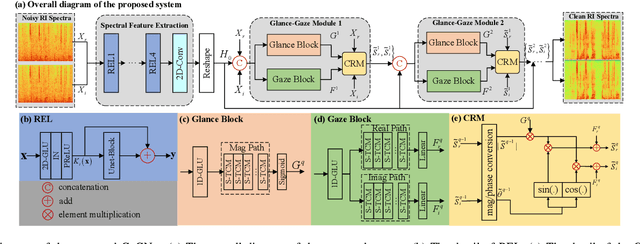
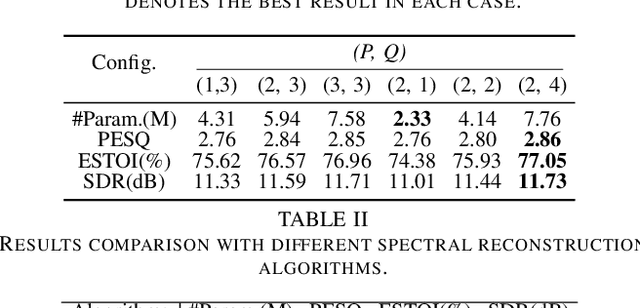
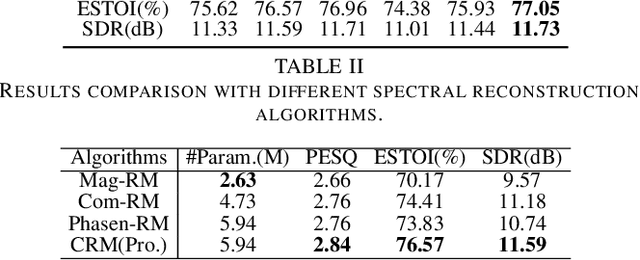

The capability of the human to pay attention to both coarse and fine-grained regions has been applied to computer vision tasks. Motivated by that, we propose a collaborative learning framework in the complex domain for monaural noise suppression. The proposed system consists of two principal modules, namely spectral feature extraction module (FEM) and stacked glance-gaze modules (GGMs). In FEM, the UNet-block is introduced after each convolution layer, enabling the feature recalibration from multiple scales. In each GGM, we decompose the multi-target optimization in the complex spectrum into two sub-tasks. Specifically, the glance path aims to suppress the noise in the magnitude domain to obtain a coarse estimation, and meanwhile, the gaze path attempts to compensate for the lost spectral detail in the complex domain. The two paths work collaboratively and facilitate spectral estimation from complementary perspectives. Besides, by repeatedly unfolding the GGMs, the intermediate result can be iteratively refined across stages and lead to the ultimate estimation of the spectrum. The experiments are conducted on the WSJ0-SI84, DNS-Challenge dataset, and Voicebank+Demand dataset. Results show that the proposed approach achieves state-of-the-art performance over previous advanced systems on the WSJ0-SI84 and DNS-Challenge dataset, and meanwhile, competitive performance is achieved on the Voicebank+Demand corpus.
Learning to Inference with Early Exit in the Progressive Speech Enhancement
Jun 22, 2021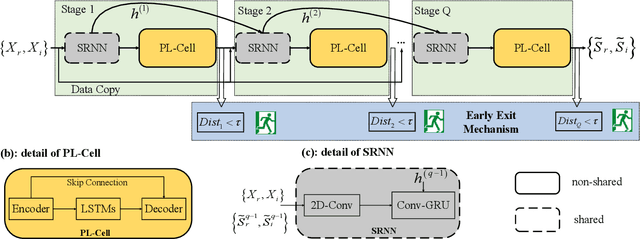
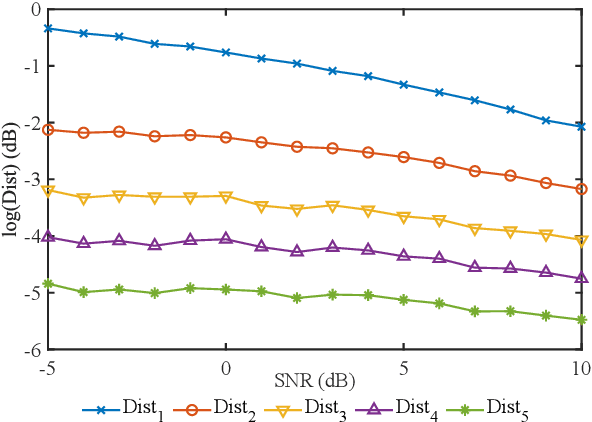
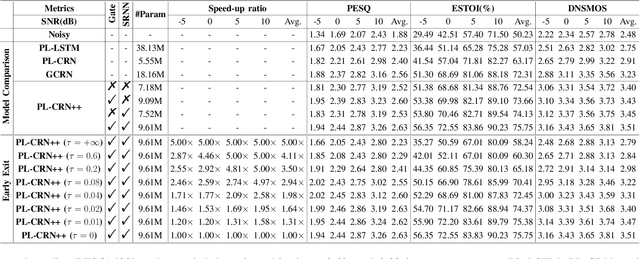
In real scenarios, it is often necessary and significant to control the inference speed of speech enhancement systems under different conditions. To this end, we propose a stage-wise adaptive inference approach with early exit mechanism for progressive speech enhancement. Specifically, in each stage, once the spectral distance between adjacent stages lowers the empirically preset threshold, the inference will terminate and output the estimation, which can effectively accelerate the inference speed. To further improve the performance of existing speech enhancement systems, PL-CRN++ is proposed, which is an improved version over our preliminary work PL-CRN and combines stage recurrent mechanism and complex spectral mapping. Extensive experiments are conducted on the TIMIT corpus, the results demonstrate the superiority of our system over state-of-the-art baselines in terms of PESQ, ESTOI and DNSMOS. Moreover, by adjusting the threshold, we can easily control the inference efficiency while sustaining the system performance.
ICASSP 2021 Deep Noise Suppression Challenge: Decoupling Magnitude and Phase Optimization with a Two-Stage Deep Network
Mar 01, 2021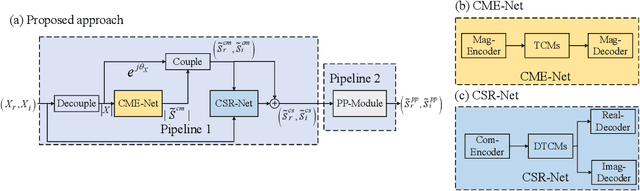
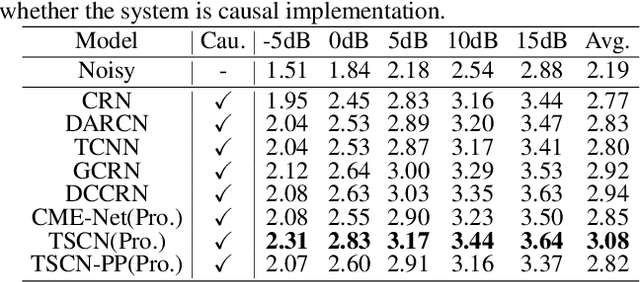
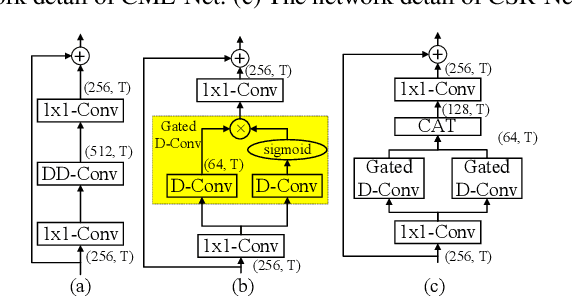
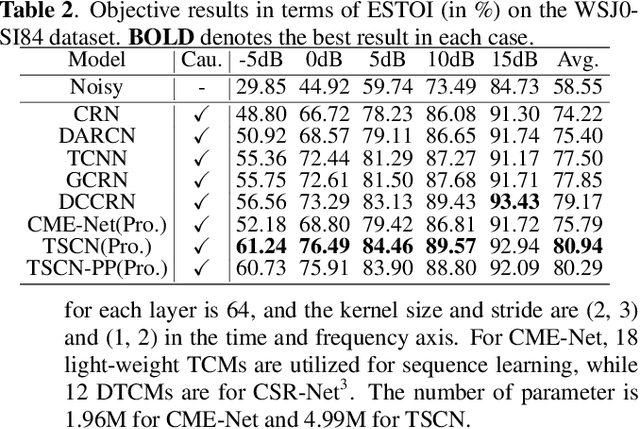
It remains a tough challenge to recover the speech signals contaminated by various noises under real acoustic environments. To this end, we propose a novel system for denoising in the complicated applications, which is mainly comprised of two pipelines, namely a two-stage network and a post-processing module. The first pipeline is proposed to decouple the optimization problem w:r:t: magnitude and phase, i.e., only the magnitude is estimated in the first stage and both of them are further refined in the second stage. The second pipeline aims to further suppress the remaining unnatural distorted noise, which is demonstrated to sufficiently improve the subjective quality. In the ICASSP 2021 Deep Noise Suppression (DNS) Challenge, our submitted system ranked top-1 for the real-time track 1 in terms of Mean Opinion Score (MOS) with ITU-T P.808 framework.
A Robust Maximum Likelihood Distortionless Response Beamformer based on a Complex Generalized Gaussian Distribution
Feb 19, 2021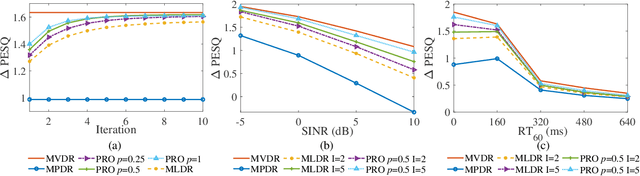
For multichannel speech enhancement, this letter derives a robust maximum likelihood distortionless response beamformer by modeling speech sparse priors with a complex generalized Gaussian distribution, where we refer to as the CGGD-MLDR beamformer. The proposed beamformer can be regarded as a generalization of the minimum power distortionless response beamformer and its improved variations. For narrowband applications, we also reveal that the proposed beamformer reduces to the minimum dispersion distortionless response beamformer, which has been derived with the ${{\ell}_{p}}$-norm minimization. The mechanisms of the proposed beamformer in improving the robustness are clearly pointed out and experimental results show its better performance in PESQ improvement.
Confused Modulo Projection based Somewhat Homomorphic Encryption -- Cryptosystem, Library and Applications on Secure Smart Cities
Dec 19, 2020
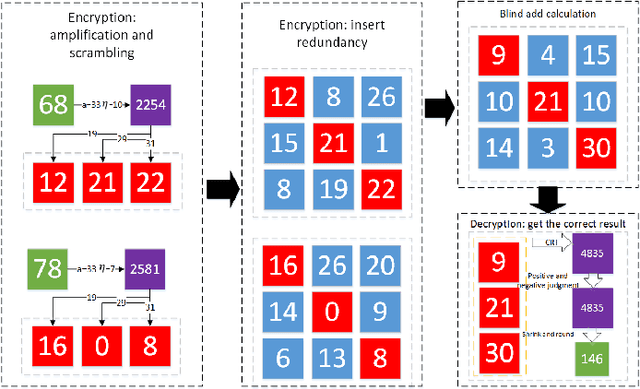


With the development of cloud computing, the storage and processing of massive visual media data has gradually transferred to the cloud server. For example, if the intelligent video monitoring system cannot process a large amount of data locally, the data will be uploaded to the cloud. Therefore, how to process data in the cloud without exposing the original data has become an important research topic. We propose a single-server version of somewhat homomorphic encryption cryptosystem based on confused modulo projection theorem named CMP-SWHE, which allows the server to complete blind data processing without \emph{seeing} the effective information of user data. On the client side, the original data is encrypted by amplification, randomization, and setting confusing redundancy. Operating on the encrypted data on the server side is equivalent to operating on the original data. As an extension, we designed and implemented a blind computing scheme of accelerated version based on batch processing technology to improve efficiency. To make this algorithm easy to use, we also designed and implemented an efficient general blind computing library based on CMP-SWHE. We have applied this library to foreground extraction, optical flow tracking and object detection with satisfactory results, which are helpful for building smart cities. We also discuss how to extend the algorithm to deep learning applications. Compared with other homomorphic encryption cryptosystems and libraries, the results show that our method has obvious advantages in computing efficiency. Although our algorithm has some tiny errors ($10^{-6}$) when the data is too large, it is very efficient and practical, especially suitable for blind image and video processing.