 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Pick-up in Dynamic Action Space Reinforcement Learning
Apr 03, 2023



Most reinforcement learning algorithms are based on a key assumption that Markov decision processes (MDPs) are stationary. However, non-stationary MDPs with dynamic action space are omnipresent in real-world scenarios. Yet problems of dynamic action space reinforcement learning have been studied by many previous works, how to choose valuable actions from new and unseen actions to improve learning efficiency remains unaddressed. To tackle this problem, we propose an intelligent Action Pick-up (AP) algorithm to autonomously choose valuable actions that are most likely to boost performance from a set of new actions. In this paper, we first theoretically analyze and find that a prior optimal policy plays an important role in action pick-up by providing useful knowledge and experience. Then, we design two different AP methods: frequency-based global method and state clustering-based local method, based on the prior optimal policy. Finally, we evaluate the AP on two simulated but challenging environments where action spaces vary over time. Experimental results demonstrate that our proposed AP has advantages over baselines in learning efficiency.
Knowledge Graph Quality Evaluation under Incomplete Information
Dec 02, 2022



Utilities of knowledge graphs (KGs) depend on their qualities. A KG that is of poor quality not only has little applicability but also leads to some unexpected errors. Therefore, quality evaluation for KGs is crucial and indispensable. Existing methods design many quality dimensions and calculate metrics in the corresponding dimensions based on details (i.e., raw data and graph structures) of KGs for evaluation. However, there are two major issues. On one hand, they consider the details as public information, which exposes the raw data and graph structures. These details are strictly confidential because they involve commercial privacy or others in practice. On the other hand, the existing methods focus on how much knowledge KGs have rather than KGs' practicability. To address the above problems, we propose a knowledge graph quality evaluation framework under incomplete information (QEII). The quality evaluation problem is transformed into an adversarial game, and the relative quality is evaluated according to the winner and loser. Participants of the game are KGs, and the adversarial gameplay is to question and answer (Q&A). In the QEII, we generate and train a question model and an answer model for each KG. The question model of a KG first asks a certain number of questions to the other KG. Then it evaluates the answers returned by the answer model of the other KG and outputs a percentage score. The relative quality is evaluated by the scores, which measures the ability to apply knowledge. Q&A messages are the only information that KGs exchange, without exposing any raw data and graph structure. Experimental results on two pairs of KGs demonstrate that, comparing with baselines, the QEII realizes a reasonable quality evaluation from the perspective of third-party evaluators under incomplete information.
TaylorBeamixer: Learning Taylor-Inspired All-Neural Multi-Channel Speech Enhancement from Beam-Space Dictionary Perspective
Nov 30, 2022Despite the promising performance of existing frame-wise all-neural beamformers in the speech enhancement field, it remains unclear what the underlying mechanism exists. In this paper, we revisit the beamforming behavior from the beam-space dictionary perspective and formulate it into the learning and mixing of different beam-space components. Based on that, we propose an all-neural beamformer called TaylorBM to simulate Taylor's series expansion operation in which the 0th-order term serves as a spatial filter to conduct the beam mixing, and several high-order terms are tasked with residual noise cancellation for post-processing. The whole system is devised to work in an end-to-end manner. Experiments are conducted on the spatialized LibriSpeech corpus and results show that the proposed approach outperforms existing advanced baselines in terms of evaluation metrics.
A General Deep Learning Speech Enhancement Framework Motivated by Taylor's Theorem
Nov 30, 2022



While deep neural networks greatly facilitate the proliferation of the speech enhancement field, most of the existing methods are developed following either heuristic or blind optimization criteria, which severely hampers interpretability and transparency. Inspired by Taylor's theorem, we propose a general unfolding framework for both single- and multi-channel speech enhancement tasks. Concretely, we formulate the complex spectrum recovery into the spectral magnitude mapping in the neighboring space of the noisy mixture, in which the sparse prior is introduced for phase modification in advance. Based on that, the mapping function is decomposed into the superimposition of the 0th-order and high-order polynomials in Taylor's series, where the former coarsely removes the interference in the magnitude domain and the latter progressively complements the remaining spectral detail in the complex spectrum domain. In addition, we study the relation between adjacent order term and reveal that each high-order term can be recursively estimated with its lower-order term, and each high-order term is then proposed to evaluate using a surrogate function with trainable weights, so that the whole system can be trained in an end-to-end manner. Extensive experiments are conducted on WSJ0-SI84, DNS-Challenge, Voicebank+Demand, and spatialized Librispeech datasets. Quantitative results show that the proposed approach not only yields competitive performance over existing top-performed approaches, but also enjoys decent internal transparency and flexibility.
Enhancing Constraint Programming via Supervised Learning for Job Shop Scheduling
Nov 26, 2022



Constraint programming (CP) is an effective technique for solving constraint satisfaction and optimization problems. CP solvers typically use a variable ordering strategy to select which variable to explore first in the solving process, which has a large impact on the efficacy of the solvers. In this paper, we propose a novel variable ordering strategy based on supervised learning to solve job shop scheduling problems. We develop a classification model and a regression model to predict the optimal solution of a problem instance, and use the predicted solution to order variables for CP solvers. We show that training machine learning models is very efficient and can achieve a high accuracy. Our extensive experiments demonstrate that the learned variable ordering methods perform competitively compared to four existing methods. Finally, we show that hybridising the machine learning-based variable ordering methods with traditional domain-based methods is beneficial.
Adaptive Population-based Simulated Annealing for Uncertain Resource Constrained Job Scheduling
Oct 31, 2022



Transporting ore from mines to ports is of significant interest in mining supply chains. These operations are commonly associated with growing costs and a lack of resources. Large mining companies are interested in optimally allocating their resources to reduce operational costs. This problem has been previously investigated in the literature as resource constrained job scheduling (RCJS). While a number of optimisation methods have been proposed to tackle the deterministic problem, the uncertainty associated with resource availability, an inevitable challenge in mining operations, has received less attention. RCJS with uncertainty is a hard combinatorial optimisation problem that cannot be solved efficiently with existing optimisation methods. This study proposes an adaptive population-based simulated annealing algorithm that can overcome the limitations of existing methods for RCJS with uncertainty including the premature convergence, the excessive number of hyper-parameters, and the inefficiency in coping with different uncertainty levels. This new algorithm is designed to effectively balance exploration and exploitation, by using a population, modifying the cooling schedule in the Metropolis-Hastings algorithm, and using an adaptive mechanism to select perturbation operators. The results show that the proposed algorithm outperforms existing methods across a wide range of benchmark RCJS instances and uncertainty levels. Moreover, new best known solutions are discovered for all but one problem instance across all uncertainty levels.
Efficient Joint DOA and TOA Estimation for Indoor Positioning with 5G Picocell Base Stations
Jun 20, 2022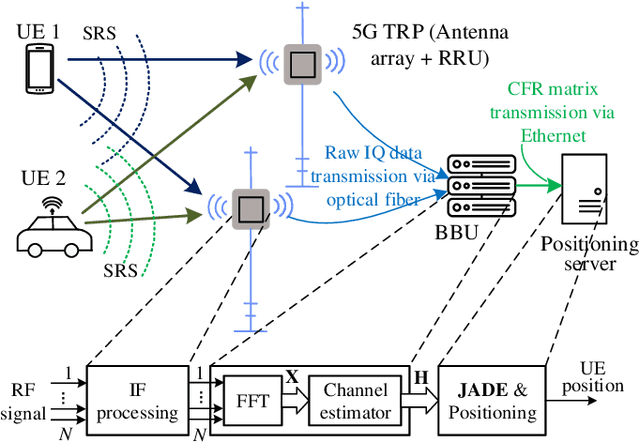
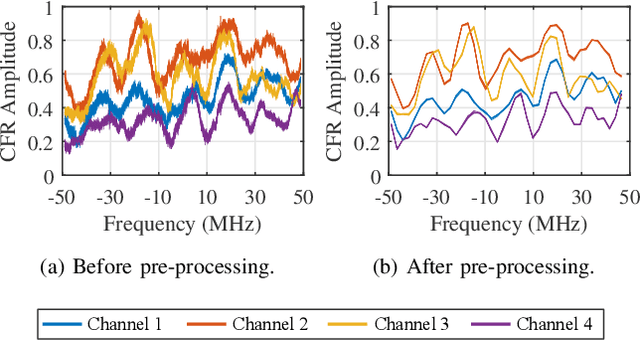
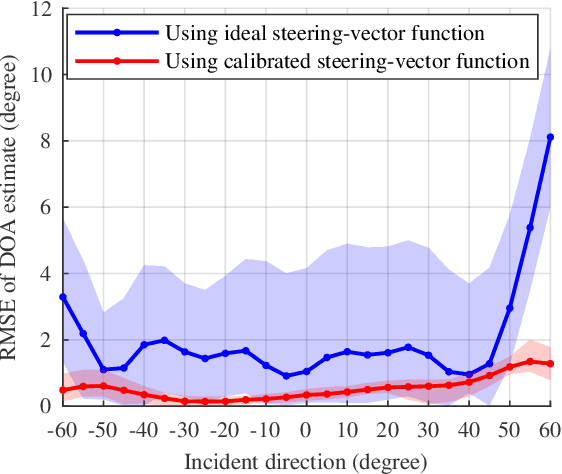
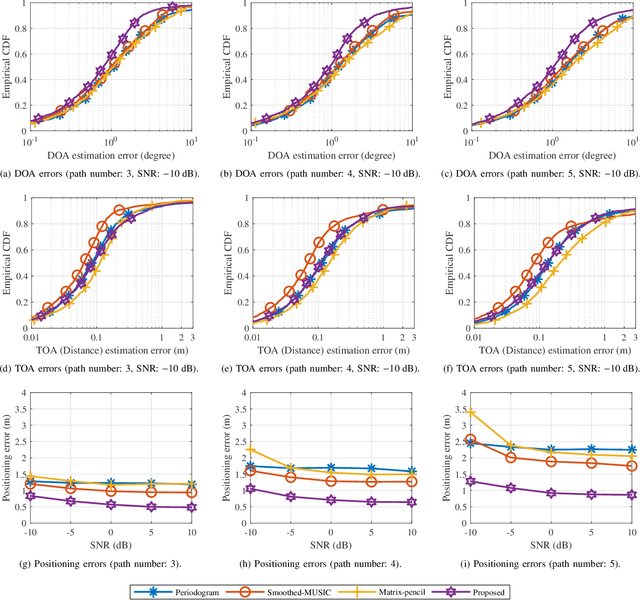
The ubiquity, large bandwidth, and spatial diversity of the fifth generation (5G) cellular signal render it a promising candidate for accurate positioning in indoor environments where the global navigation satellite system (GNSS) signal is absent. In this paper, a joint angle and delay estimation (JADE) scheme is designed for 5G picocell base stations (gNBs) which addresses two crucial issues to make it both effective and efficient in realistic indoor environments. Firstly, the direction-dependence of the array modeling error for picocell gNB as well as its impact on JADE is revealed. This error is mitigated by fitting the array response measurements to a vector-valued function and pre-calibrating the ideal steering-vector with the fitted function. Secondly, based on the deployment reality that 5G picocell gNBs only have a small-scale antenna array but have a large signal bandwidth, the proposed scheme decouples the estimation of time-of-arrival (TOA) and direction-of-arrival (DOA) to reduce the huge complexity induced by two-dimensional joint processing. It employs the iterative-adaptive-approach (IAA) to resolve multipath signals in the TOA domain, followed by a conventional beamformer (CBF) to retrieve the desired line-of-sight DOA. By further exploiting a dimension-reducing pre-processing module and accelerating spectrum computing by fast Fourier transforms, an efficient implementation is achieved for real-time JADE. Numerical simulations demonstrate the superiority of the proposed method in terms of DOA estimation accuracy. Field tests show that a triangulation positioning error of 0.44 m is achieved for 90% cases using only DOAs estimated at two separated receiving points.
Taylor, Can You Hear Me Now? A Taylor-Unfolding Framework for Monaural Speech Enhancement
Apr 30, 2022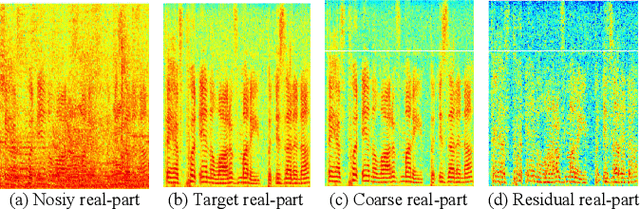
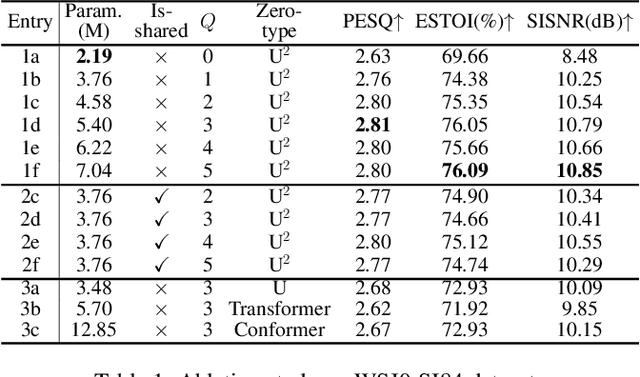
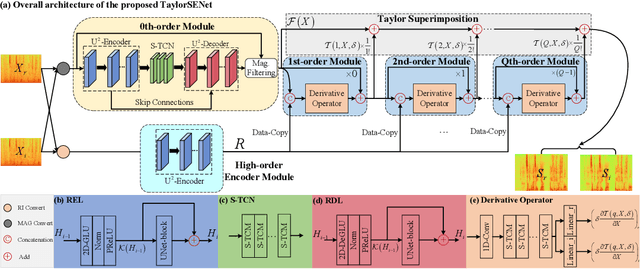
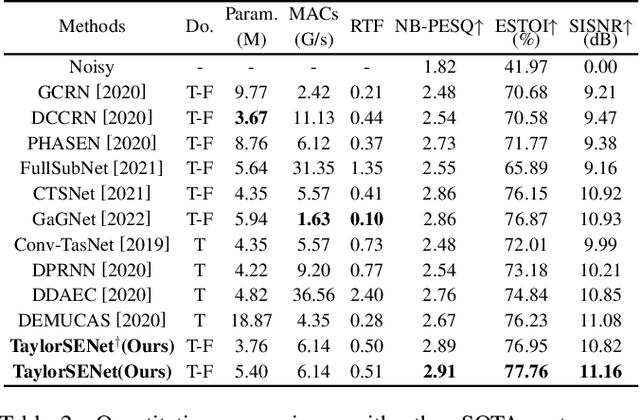
While the deep learning techniques promote the rapid development of the speech enhancement (SE) community, most schemes only pursue the performance in a black-box manner and lack adequate model interpretability. Inspired by Taylor's approximation theory, we propose an interpretable decoupling-style SE framework, which disentangles the complex spectrum recovery into two separate optimization problems \emph{i.e.}, magnitude and complex residual estimation. Specifically, serving as the 0th-order term in Taylor's series, a filter network is delicately devised to suppress the noise component only in the magnitude domain and obtain a coarse spectrum. To refine the phase distribution, we estimate the sparse complex residual, which is defined as the difference between target and coarse spectra, and measures the phase gap. In this study, we formulate the residual component as the combination of various high-order Taylor terms and propose a lightweight trainable module to replace the complicated derivative operator between adjacent terms. Finally, following Taylor's formula, we can reconstruct the target spectrum by the superimposition between 0th-order and high-order terms. Experimental results on two benchmark datasets show that our framework achieves state-of-the-art performance over previous competing baselines in various evaluation metrics. The source code is available at github.com/Andong-Lispeech/TaylorSENet.
TaylorBeamformer: Learning All-Neural Beamformer for Multi-Channel Speech Enhancement from Taylor's Approximation Theory
Mar 16, 2022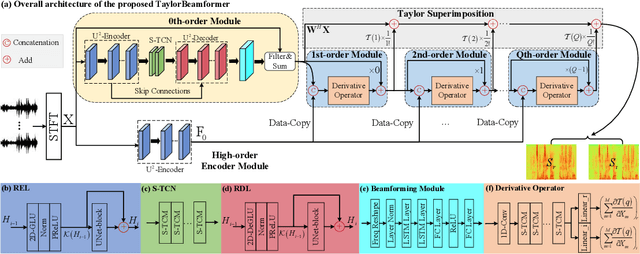
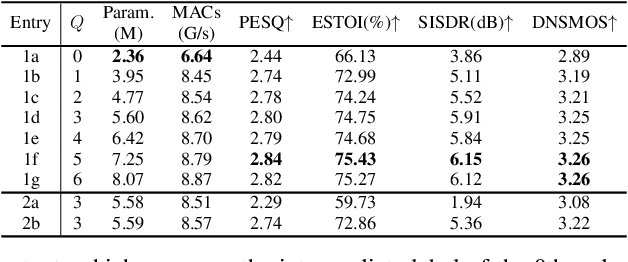
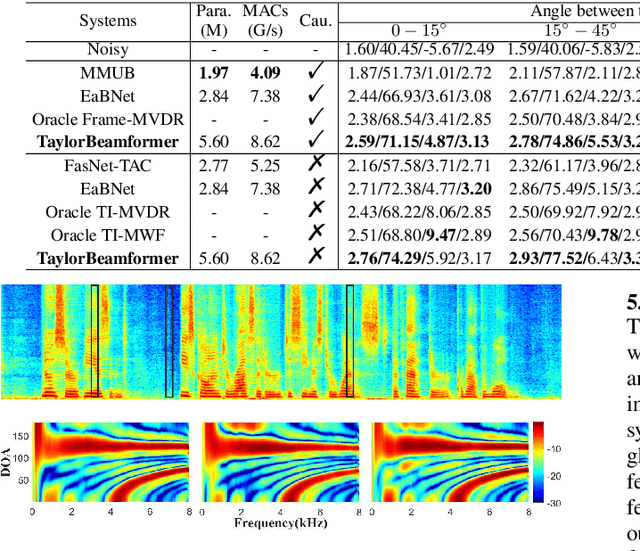
While existing end-to-end beamformers achieve impressive performance in various front-end speech processing tasks, they usually encapsulate the whole process into a black box and thus lack adequate interpretability. As an attempt to fill the blank, we propose a novel neural beamformer inspired by Taylor's approximation theory called TaylorBeamformer for multi-channel speech enhancement. The core idea is that the recovery process can be formulated as the spatial filtering in the neighborhood of the input mixture. Based on that, we decompose it into the superimposition of the 0th-order non-derivative and high-order derivative terms, where the former serves as the spatial filter and the latter is viewed as the residual noise canceller to further improve the speech quality. To enable end-to-end training, we replace the derivative operations with trainable networks and thus can learn from training data. Extensive experiments are conducted on the synthesized dataset based on LibriSpeech and results show that the proposed approach performs favorably against the previous advanced baselines.
MDNet: Learning Monaural Speech Enhancement from Deep Prior Gradient
Mar 16, 2022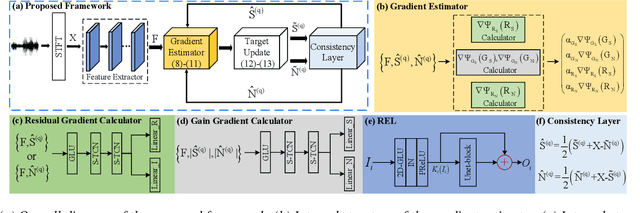
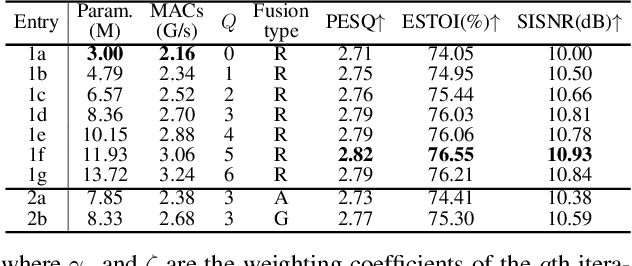
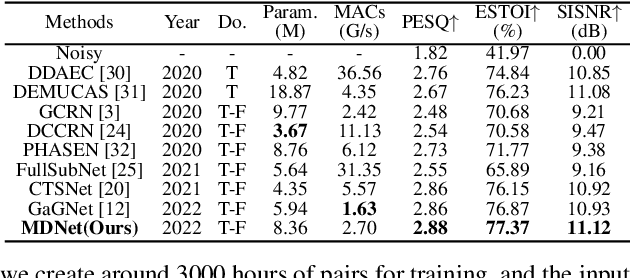
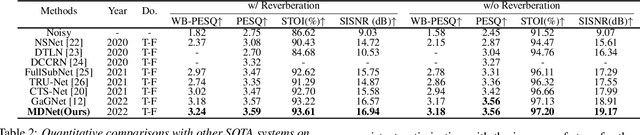
While traditional statistical signal processing model-based methods can derive the optimal estimators relying on specific statistical assumptions, current learning-based methods further promote the performance upper bound via deep neural networks but at the expense of high encapsulation and lack adequate interpretability. Standing upon the intersection between traditional model-based methods and learning-based methods, we propose a model-driven approach based on the maximum a posteriori (MAP) framework, termed as MDNet, for single-channel speech enhancement. Specifically, the original problem is formulated into the joint posterior estimation w.r.t. speech and noise components. Different from the manual assumption toward the prior terms, we propose to model the prior distribution via networks and thus can learn from training data. The framework takes the unfolding structure and in each step, the target parameters can be progressively estimated through explicit gradient descent operations. Besides, another network serves as the fusion module to further refine the previous speech estimation. The experiments are conducted on the WSJ0-SI84 and Interspeech2020 DNS-Challenge datasets, and quantitative results show that the proposed approach outshines previous state-of-the-art baselines.