 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective and Robust Multimodal Medical Image Analysis
Feb 17, 2026Multimodal Fusion Learning (MFL), leveraging disparate data from various imaging modalities (e.g., MRI, CT, SPECT), has shown great potential for addressing medical problems such as skin cancer and brain tumor prediction. However, existing MFL methods face three key limitations: a) they often specialize in specific modalities, and overlook effective shared complementary information across diverse modalities, hence limiting their generalizability for multi-disease analysis; b) they rely on computationally expensive models, restricting their applicability in resource-limited settings; and c) they lack robustness against adversarial attacks, compromising reliability in medical AI applications. To address these limitations, we propose a novel Multi-Attention Integration Learning (MAIL) network, incorporating two key components: a) an efficient residual learning attention block for capturing refined modality-specific multi-scale patterns and b) an efficient multimodal cross-attention module for learning enriched complementary shared representations across diverse modalities. Furthermore, to ensure adversarial robustness, we extend MAIL network to design Robust-MAIL by incorporating random projection filters and modulated attention noise. Extensive evaluations on 20 public datasets show that both MAIL and Robust-MAIL outperform existing methods, achieving performance gains of up to 9.34% while reducing computational costs by up to 78.3%. These results highlight the superiority of our approaches, ensuring more reliable predictions than top competitors. Code: https://github.com/misti1203/MAIL-Robust-MAIL.
Multimodal Fusion Learning with Dual Attention for Medical Imaging
Dec 02, 2024



Multimodal fusion learning has shown significant promise in classifying various diseases such as skin cancer and brain tumors. However, existing methods face three key limitations. First, they often lack generalizability to other diagnosis tasks due to their focus on a particular disease. Second, they do not fully leverage multiple health records from diverse modalities to learn robust complementary information. And finally, they typically rely on a single attention mechanism, missing the benefits of multiple attention strategies within and across various modalities. To address these issues, this paper proposes a dual robust information fusion attention mechanism (DRIFA) that leverages two attention modules, i.e. multi-branch fusion attention module and the multimodal information fusion attention module. DRIFA can be integrated with any deep neural network, forming a multimodal fusion learning framework denoted as DRIFA-Net. We show that the multi-branch fusion attention of DRIFA learns enhanced representations for each modality, such as dermoscopy, pap smear, MRI, and CT-scan, whereas multimodal information fusion attention module learns more refined multimodal shared representations, improving the network's generalization across multiple tasks and enhancing overall performance. Additionally, to estimate the uncertainty of DRIFA-Net predictions, we have employed an ensemble Monte Carlo dropout strategy. Extensive experiments on five publicly available datasets with diverse modalities demonstrate that our approach consistently outperforms state-of-the-art methods. The code is available at https://github.com/misti1203/DRIFA-Net.
* 10 pages
Fruit Classification System with Deep Learning and Neural Architecture Search
Jun 04, 2024



The fruit identification process involves analyzing and categorizing different types of fruits based on their visual characteristics. This activity can be achieved using a range of methodologies, encompassing manual examination, conventional computer vision methodologies, and more sophisticated methodologies employing machine learning and deep learning. Our study identified a total of 15 distinct categories of fruit, consisting of class Avocado, Banana, Cherry, Apple Braeburn, Apple golden 1, Apricot, Grape, Kiwi, Mango, Orange, Papaya, Peach, Pineapple, Pomegranate and Strawberry. Neural Architecture Search (NAS) is a technological advancement employed within the realm of deep learning and artificial intelligence, to automate conceptualizing and refining neural network topologies. NAS aims to identify neural network structures that are highly suitable for tasks, such as the detection of fruits. Our suggested model with 99.98% mAP increased the detection performance of the preceding research study that used Fruit datasets. In addition, after the completion of the study, a comparative analysis was carried out to assess the findings in conjunction with those of another research that is connected to the topic. When compared to the findings of earlier studies, the detector that was proposed exhibited higher performance in terms of both its accuracy and its precision.
Adaptive Population-based Simulated Annealing for Uncertain Resource Constrained Job Scheduling
Oct 31, 2022



Transporting ore from mines to ports is of significant interest in mining supply chains. These operations are commonly associated with growing costs and a lack of resources. Large mining companies are interested in optimally allocating their resources to reduce operational costs. This problem has been previously investigated in the literature as resource constrained job scheduling (RCJS). While a number of optimisation methods have been proposed to tackle the deterministic problem, the uncertainty associated with resource availability, an inevitable challenge in mining operations, has received less attention. RCJS with uncertainty is a hard combinatorial optimisation problem that cannot be solved efficiently with existing optimisation methods. This study proposes an adaptive population-based simulated annealing algorithm that can overcome the limitations of existing methods for RCJS with uncertainty including the premature convergence, the excessive number of hyper-parameters, and the inefficiency in coping with different uncertainty levels. This new algorithm is designed to effectively balance exploration and exploitation, by using a population, modifying the cooling schedule in the Metropolis-Hastings algorithm, and using an adaptive mechanism to select perturbation operators. The results show that the proposed algorithm outperforms existing methods across a wide range of benchmark RCJS instances and uncertainty levels. Moreover, new best known solutions are discovered for all but one problem instance across all uncertainty levels.
Proximity Forest: An effective and scalable distance-based classifier for time series
Aug 31, 2018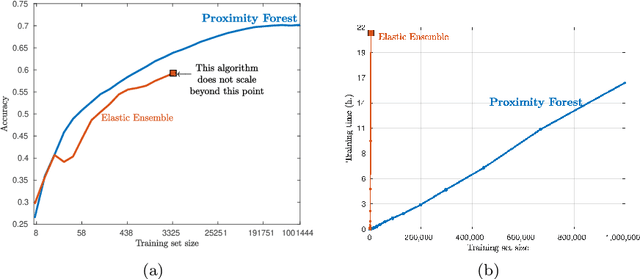
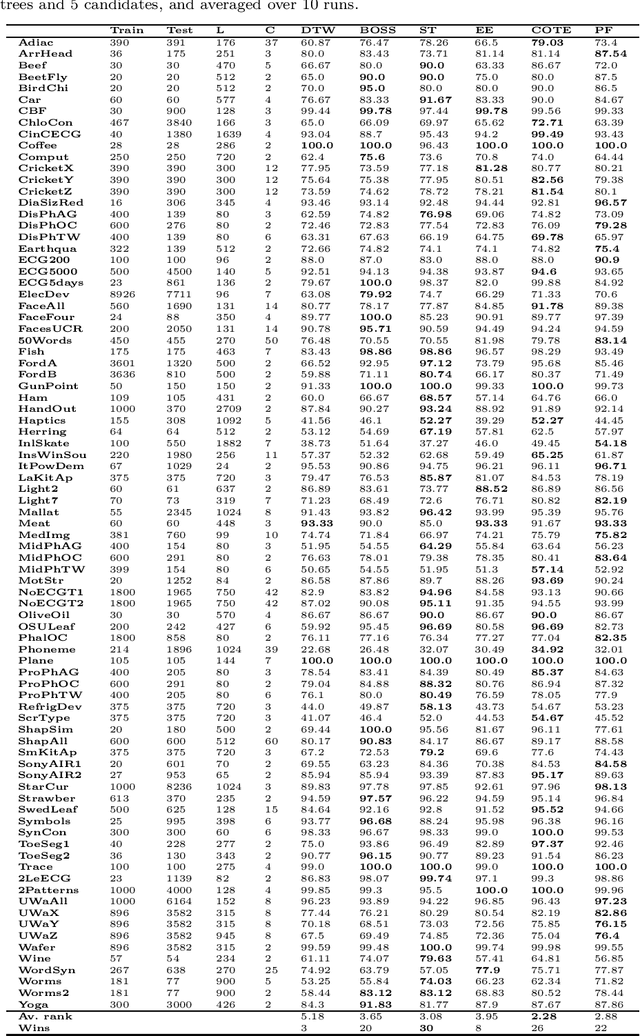
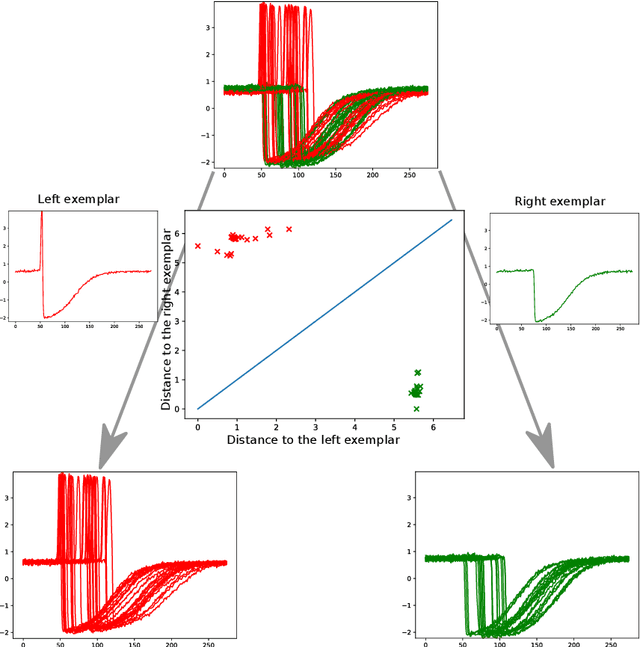
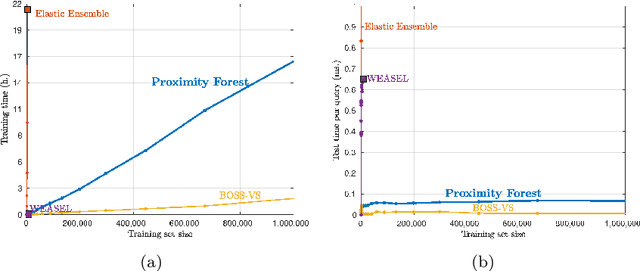
Research into the classification of time series has made enormous progress in the last decade. The UCR time series archive has played a significant role in challenging and guiding the development of new learners for time series classification. The largest dataset in the UCR archive holds 10 thousand time series only; which may explain why the primary research focus has been in creating algorithms that have high accuracy on relatively small datasets. This paper introduces Proximity Forest, an algorithm that learns accurate models from datasets with millions of time series, and classifies a time series in milliseconds. The models are ensembles of highly randomized Proximity Trees. Whereas conventional decision trees branch on attribute values (and usually perform poorly on time series), Proximity Trees branch on the proximity of time series to one exemplar time series or another; allowing us to leverage the decades of work into developing relevant measures for time series. Proximity Forest gains both efficiency and accuracy by stochastic selection of both exemplars and similarity measures. Our work is motivated by recent time series applications that provide orders of magnitude more time series than the UCR benchmarks. Our experiments demonstrate that Proximity Forest is highly competitive on the UCR archive: it ranks among the most accurate classifiers while being significantly faster. We demonstrate on a 1M time series Earth observation dataset that Proximity Forest retains this accuracy on datasets that are many orders of magnitude greater than those in the UCR repository, while learning its models at least 100,000 times faster than current state of the art models Elastic Ensemble and COTE.
Accurate parameter estimation for Bayesian Network Classifiers using Hierarchical Dirichlet Processes
May 08, 2018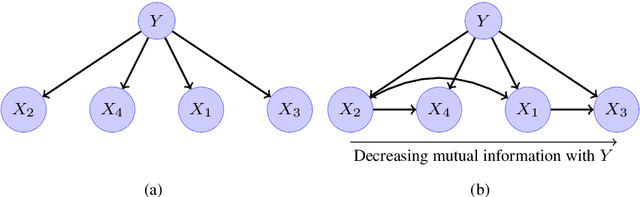

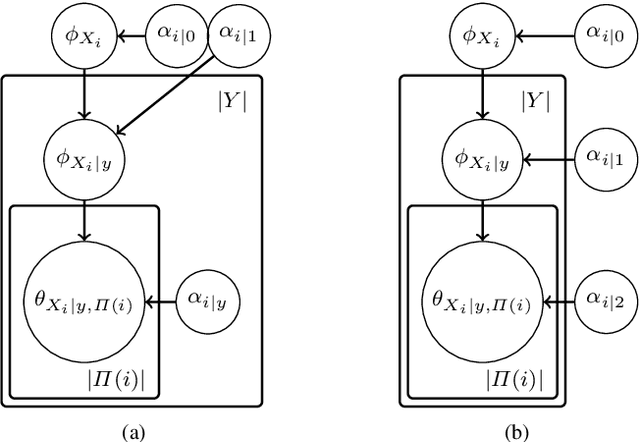
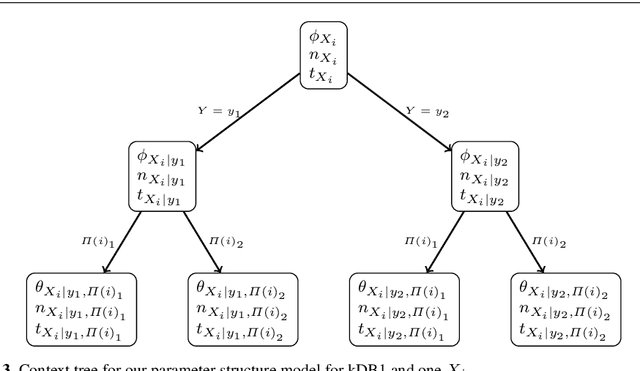
This paper introduces a novel parameter estimation method for the probability tables of Bayesian network classifiers (BNCs), using hierarchical Dirichlet processes (HDPs). The main result of this paper is to show that improved parameter estimation allows BNCs to outperform leading learning methods such as Random Forest for both 0-1 loss and RMSE, albeit just on categorical datasets. As data assets become larger, entering the hyped world of "big", efficient accurate classification requires three main elements: (1) classifiers with low-bias that can capture the fine-detail of large datasets (2) out-of-core learners that can learn from data without having to hold it all in main memory and (3) models that can classify new data very efficiently. The latest Bayesian network classifiers (BNCs) satisfy these requirements. Their bias can be controlled easily by increasing the number of parents of the nodes in the graph. Their structure can be learned out of core with a limited number of passes over the data. However, as the bias is made lower to accurately model classification tasks, so is the accuracy of their parameters' estimates, as each parameter is estimated from ever decreasing quantities of data. In this paper, we introduce the use of Hierarchical Dirichlet Processes for accurate BNC parameter estimation. We conduct an extensive set of experiments on 68 standard datasets and demonstrate that our resulting classifiers perform very competitively with Random Forest in terms of prediction, while keeping the out-of-core capability and superior classification time.