 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Resolution Medical Image Analysis with Spatial Partitioning
Sep 12, 2019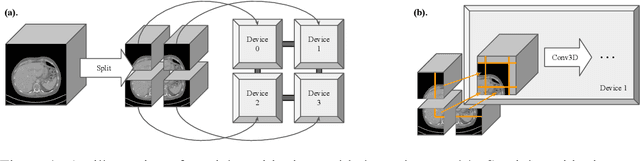
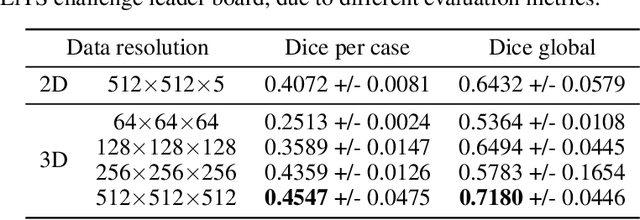

Medical images such as 3D computerized tomography (CT) scans and pathology images, have hundreds of millions or billions of voxels/pixels. It is infeasible to train CNN models directly on such high resolution images, because neural activations of a single image do not fit in the memory of a single GPU/TPU, and naive data and model parallelism approaches do not work. Existing image analysis approaches alleviate this problem by cropping or down-sampling input images, which leads to complicated implementation and sub-optimal performance due to information loss. In this paper, we implement spatial partitioning, which internally distributes the input and output of convolutional layers across GPUs/TPUs. Our implementation is based on the Mesh-TensorFlow framework and the computation distribution is transparent to end users. With this technique, we train a 3D Unet on up to 512 by 512 by 512 resolution data. To the best of our knowledge, this is the first work for handling such high resolution images end-to-end.
Reducing BERT Pre-Training Time from 3 Days to 76 Minutes
Apr 01, 2019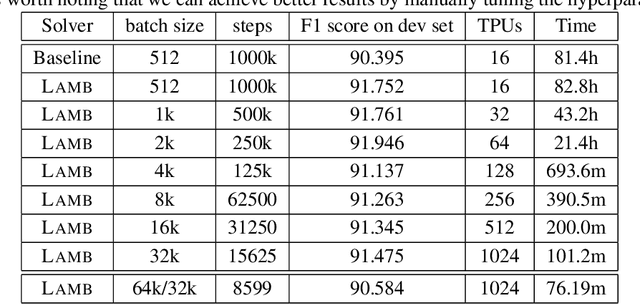
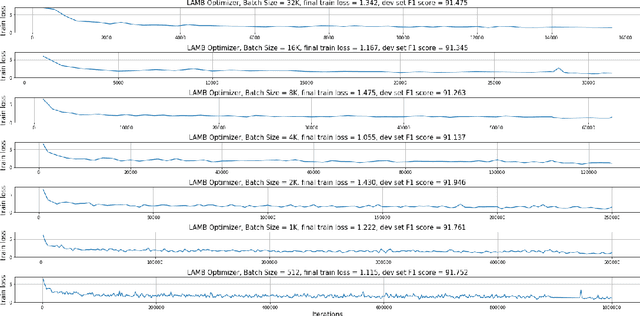
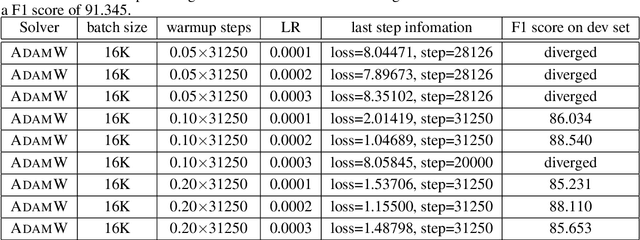
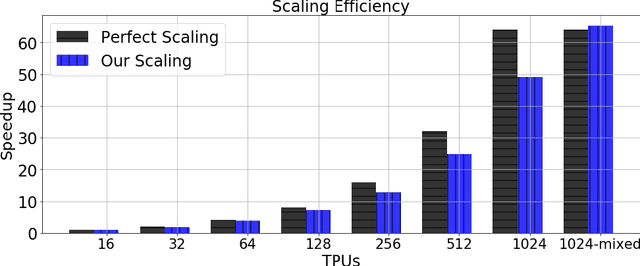
Large-batch training is key to speeding up deep neural network training in large distributed systems. However, large-batch training is difficult because it produces a generalization gap. Straightforward optimization often leads to accuracy loss on the test set. BERT \cite{devlin2018bert} is a state-of-the-art deep learning model that builds on top of deep bidirectional transformers for language understanding. Previous large-batch training techniques do not perform well for BERT when we scale the batch size (e.g. beyond 8192). BERT pre-training also takes a long time to finish (around three days on 16 TPUv3 chips). To solve this problem, we propose the LAMB optimizer, which helps us to scale the batch size to 65536 without losing accuracy. LAMB is a general optimizer that works for both small and large batch sizes and does not need hyper-parameter tuning besides the learning rate. The baseline BERT-Large model needs 1 million iterations to finish pre-training, while LAMB with batch size 65536/32768 only needs 8599 iterations. We push the batch size to the memory limit of a TPUv3 pod and can finish BERT training in 76 minutes.