 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Learning for Video-based Person Re-identification
Dec 14, 2018
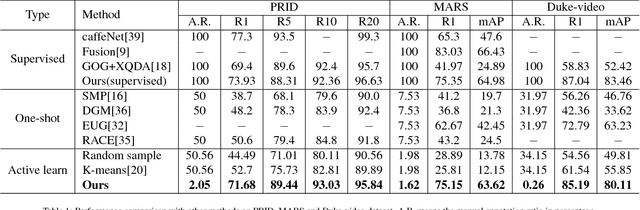
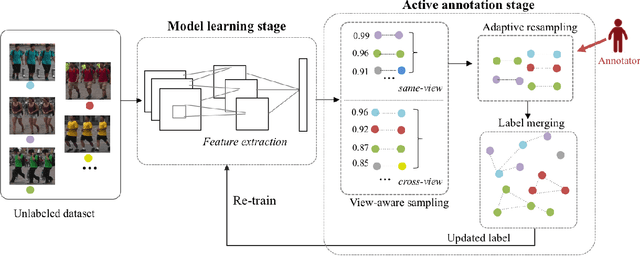

It is prohibitively expensive to annotate a large-scale video-based person re-identification (re-ID) dataset, which makes fully supervised methods inapplicable to real-world deployment. How to maximally reduce the annotation cost while retaining the re-ID performance becomes an interesting problem. In this paper, we address this problem by integrating an active learning scheme into a deep learning framework. Noticing that the truly matched tracklet-pairs, also denoted as true positives (TP), are the most informative samples for our re-ID model, we propose a sampling criterion to choose the most TP-likely tracklet-pairs for annotation. A view-aware sampling strategy considering view-specific biases is designed to facilitate candidate selection, followed by an adaptive resampling step to leave out the selected candidates that are unnecessary to annotate. Our method learns the re-ID model and updates the annotation set iteratively. The re-ID model is supervised by the tracklets' pesudo labels that are initialized by treating each tracklet as a distinct class. With the gained annotations of the actively selected candidates, the tracklets' pesudo labels are updated by label merging and further used to re-train our re-ID model. While being simple, the proposed method demonstrates its effectiveness on three video-based person re-ID datasets. Experimental results show that less than 3\% pairwise annotations are needed for our method to reach comparable performance with the fully-supervised setting.
Dynamic Spatio-temporal Graph-based CNNs for Traffic Prediction
Dec 06, 2018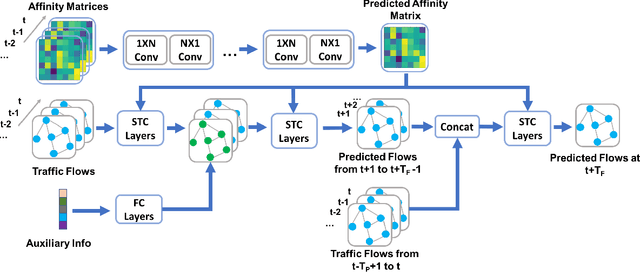
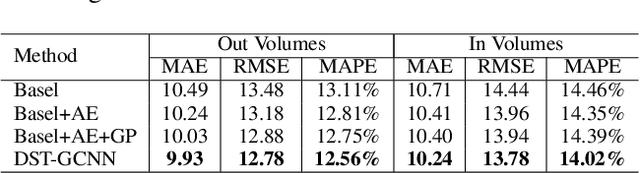
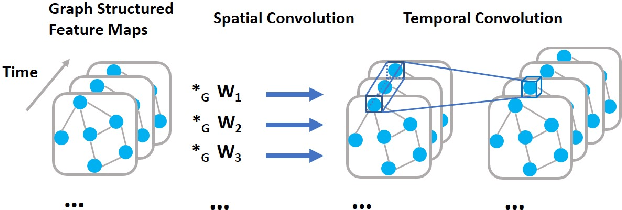
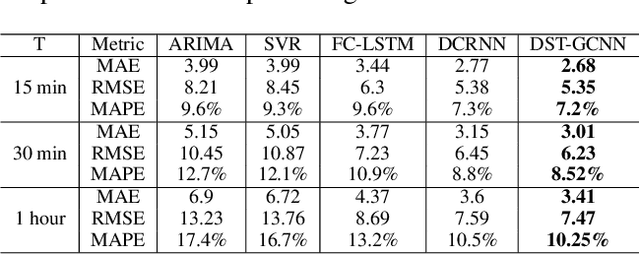
Accurate traffic forecast is a challenging problem due to the large-scale problem size, as well as the complex and dynamic nature of spatio-temporal dependency of traffic flow. Most existing graph-based CNNs attempt to capture the static relations while largely neglecting the dynamics underlying sequential data. In this paper, we present dynamic spatio-temporal graph-based CNNs (DST-GCNNs) by learning expressive features to represent spatio-temporal structures and predict future traffic from historical traffic flow. In particular, DST-GCNN is a two stream network. In the flow prediction stream, we present a novel graph-based spatio-temporal convolutional layer to extract features from a graph representation of traffic flow. Then several such layers are stacked together to predict future traffic over time. Meanwhile, the proximity relations between nodes in the graph are often time variant as the traffic condition changes over time. To capture the graph dynamics, we use the graph prediction stream to predict the dynamic graph structures, and the predicted structures are fed into the flow prediction stream. Experiments on real traffic datasets demonstrate that the proposed model achieves competitive performances compared with the other state-of-the-art methods.
Homocentric Hypersphere Feature Embedding for Person Re-identification
May 01, 2018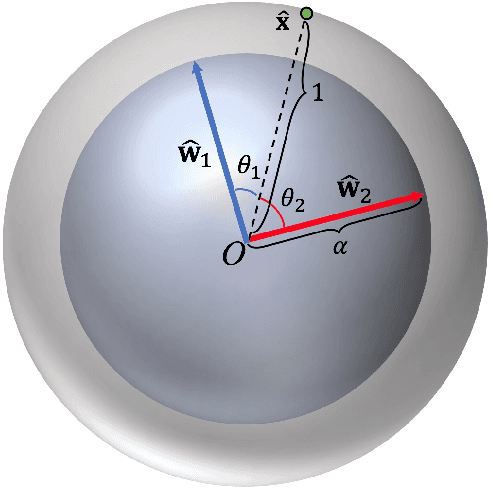
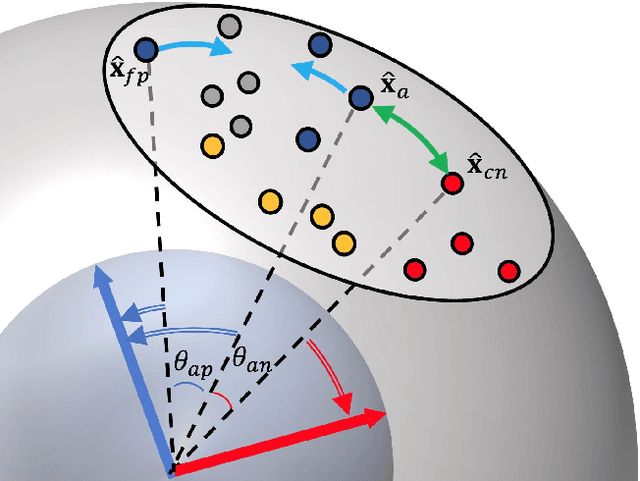
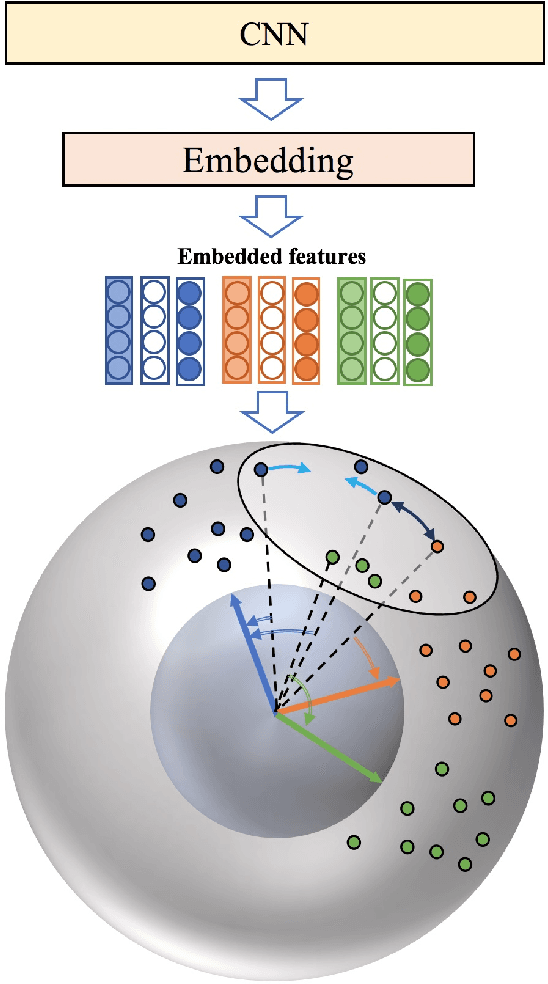

Person re-identification (Person ReID) is a challenging task due to the large variations in camera viewpoint, lighting, resolution, and human pose. Recently, with the advancement of deep learning technologies, the performance of Person ReID has been improved swiftly. Feature extraction and feature matching are two crucial components in the training and deployment stages of Person ReID. However, many existing Person ReID methods have measure inconsistency between the training stage and the deployment stage, and they couple magnitude and orientation information of feature vectors in feature representation. Meanwhile, traditional triplet loss methods focus on samples within a mini-batch and lack knowledge of global feature distribution. To address these issues, we propose a novel homocentric hypersphere embedding scheme to decouple magnitude and orientation information for both feature and weight vectors, and reformulate classification loss and triplet loss to their angular versions and combine them into an angular discriminative loss. We evaluate our proposed method extensively on the widely used Person ReID benchmarks, including Market1501, CUHK03 and DukeMTMC-ReID. Our method demonstrates leading performance on all datasets.
Exploiting Web Images for Dataset Construction: A Domain Robust Approach
Mar 28, 2017
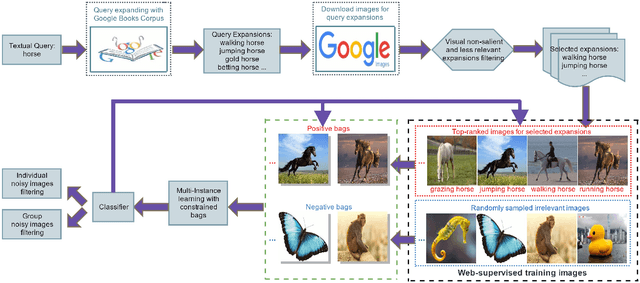
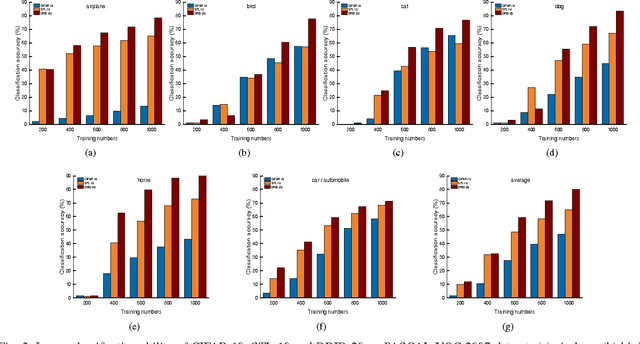
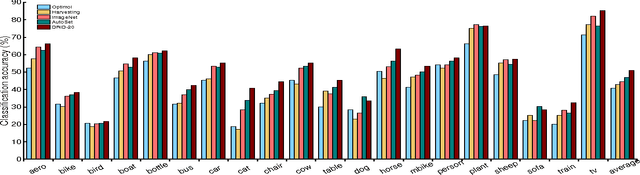
Labelled image datasets have played a critical role in high-level image understanding. However, the process of manual labelling is both time-consuming and labor intensive. To reduce the cost of manual labelling, there has been increased research interest in automatically constructing image datasets by exploiting web images. Datasets constructed by existing methods tend to have a weak domain adaptation ability, which is known as the "dataset bias problem". To address this issue, we present a novel image dataset construction framework that can be generalized well to unseen target domains. Specifically, the given queries are first expanded by searching the Google Books Ngrams Corpus to obtain a rich semantic description, from which the visually non-salient and less relevant expansions are filtered out. By treating each selected expansion as a "bag" and the retrieved images as "instances", image selection can be formulated as a multi-instance learning problem with constrained positive bags. We propose to solve the employed problems by the cutting-plane and concave-convex procedure (CCCP) algorithm. By using this approach, images from different distributions can be kept while noisy images are filtered out. To verify the effectiveness of our proposed approach, we build an image dataset with 20 categories. Extensive experiments on image classification, cross-dataset generalization, diversity comparison and object detection demonstrate the domain robustness of our dataset.
Refining Image Categorization by Exploiting Web Images and General Corpus
Mar 16, 2017
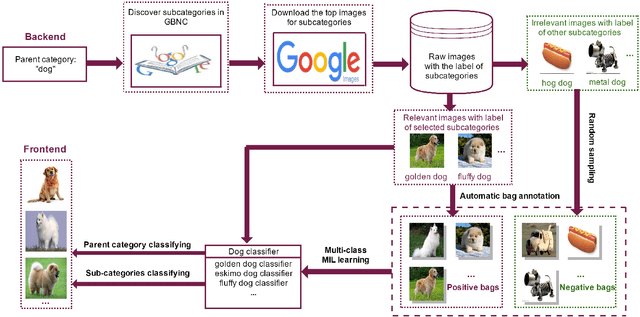
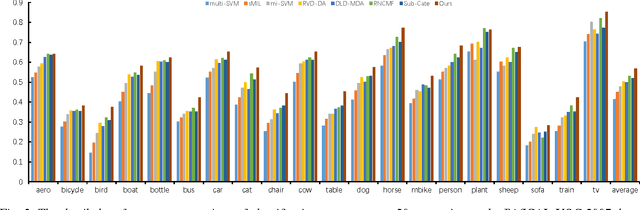
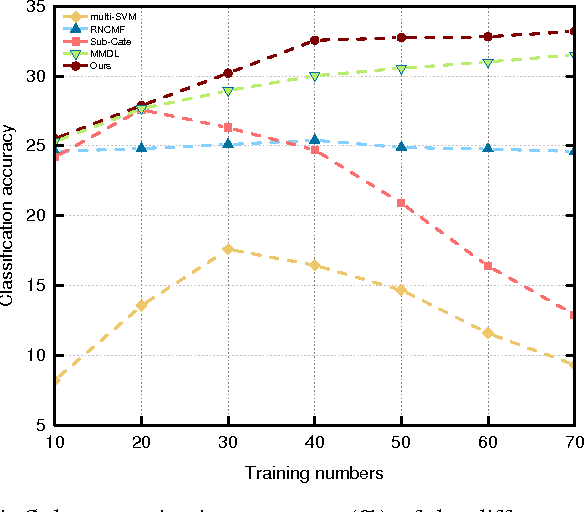
Studies show that refining real-world categories into semantic subcategories contributes to better image modeling and classification. Previous image sub-categorization work relying on labeled images and WordNet's hierarchy is not only labor-intensive, but also restricted to classify images into NOUN subcategories. To tackle these problems, in this work, we exploit general corpus information to automatically select and subsequently classify web images into semantic rich (sub-)categories. The following two major challenges are well studied: 1) noise in the labels of subcategories derived from the general corpus; 2) noise in the labels of images retrieved from the web. Specifically, we first obtain the semantic refinement subcategories from the text perspective and remove the noise by the relevance-based approach. To suppress the search error induced noisy images, we then formulate image selection and classifier learning as a multi-class multi-instance learning problem and propose to solve the employed problem by the cutting-plane algorithm. The experiments show significant performance gains by using the generated data of our way on both image categorization and sub-categorization tasks. The proposed approach also consistently outperforms existing weakly supervised and web-supervised approaches.