 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-directional Cognitive Thinking Network for Machine Reading Comprehension
Oct 20, 2020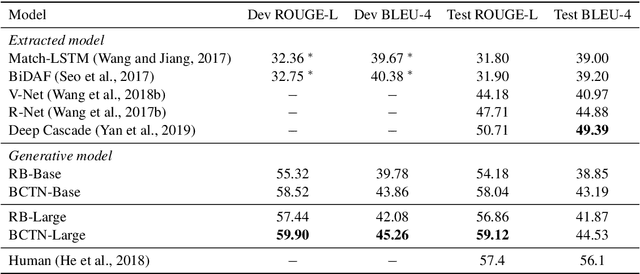
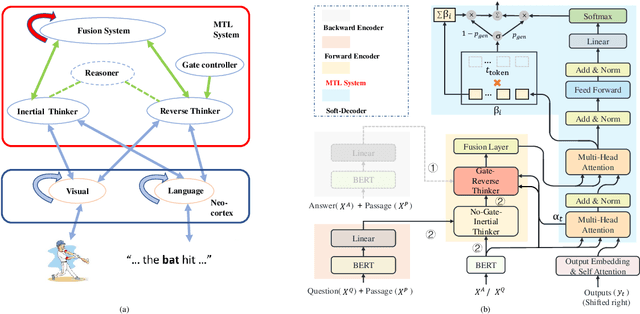

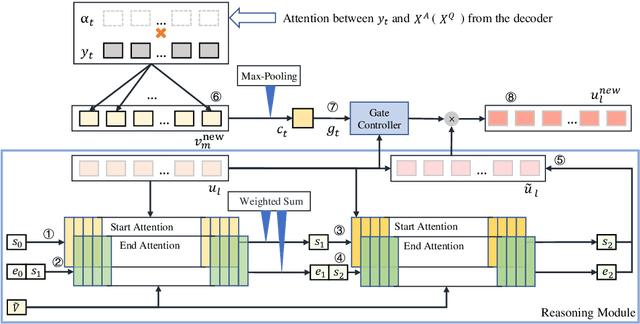
We propose a novel Bi-directional Cognitive Knowledge Framework (BCKF) for reading comprehension from the perspective of complementary learning systems theory. It aims to simulate two ways of thinking in the brain to answer questions, including reverse thinking and inertial thinking. To validate the effectiveness of our framework, we design a corresponding Bi-directional Cognitive Thinking Network (BCTN) to encode the passage and generate a question (answer) given an answer (question) and decouple the bi-directional knowledge. The model has the ability to reverse reasoning questions which can assist inertial thinking to generate more accurate answers. Competitive improvement is observed in DuReader dataset, confirming our hypothesis that bi-directional knowledge helps the QA task. The novel framework shows an interesting perspective on machine reading comprehension and cognitive science.
Uncertainty-Aware Semantic Augmentation for Neural Machine Translation
Oct 09, 2020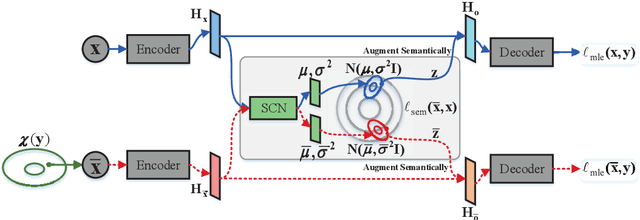
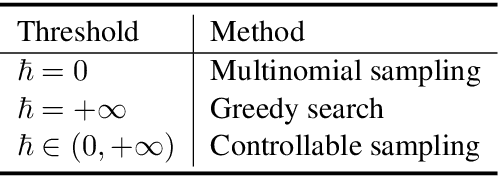
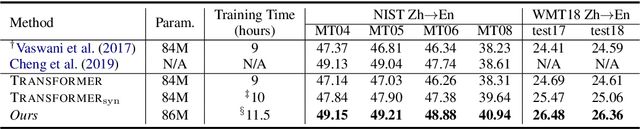
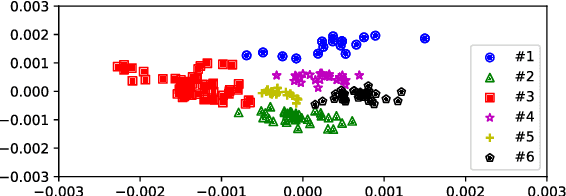
As a sequence-to-sequence generation task, neural machine translation (NMT) naturally contains intrinsic uncertainty, where a single sentence in one language has multiple valid counterparts in the other. However, the dominant methods for NMT only observe one of them from the parallel corpora for the model training but have to deal with adequate variations under the same meaning at inference. This leads to a discrepancy of the data distribution between the training and the inference phases. To address this problem, we propose uncertainty-aware semantic augmentation, which explicitly captures the universal semantic information among multiple semantically-equivalent source sentences and enhances the hidden representations with this information for better translations. Extensive experiments on various translation tasks reveal that our approach significantly outperforms the strong baselines and the existing methods.
On Learning Universal Representations Across Languages
Aug 09, 2020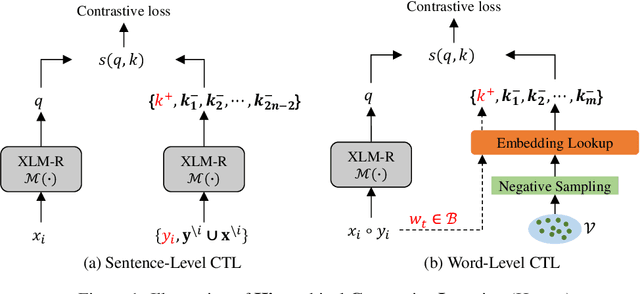

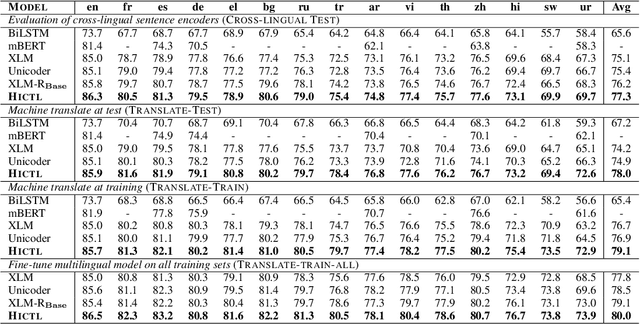
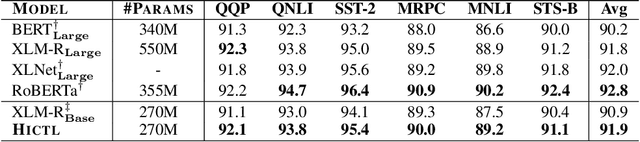
Recent studies have demonstrated the overwhelming advantage of cross-lingual pre-trained models (PTMs), such as multilingual BERT and XLM, on cross-lingual NLP tasks. However, existing approaches essentially capture the co-occurrence among tokens through involving the masked language model (MLM) objective with token-level cross entropy. In this work, we extend these approaches to learn sentence-level representations, and show the effectiveness on cross-lingual understanding and generation. We propose Hierarchical Contrastive Learning (HiCTL) to (1) learn universal representations for parallel sentences distributed in one or multiple languages and (2) distinguish the semantically-related words from a shared cross-lingual vocabulary for each sentence. We conduct evaluations on three benchmarks: language understanding tasks (QQP, QNLI, SST-2, MRPC, STS-B and MNLI) in the GLUE benchmark, cross-lingual natural language inference (XNLI) and machine translation. Experimental results show that the HiCTL obtains an absolute gain of 1.0%/2.2% accuracy on GLUE/XNLI as well as achieves substantial improvements of +1.7-+3.6 BLEU on both the high-resource and low-resource English-to-X translation tasks over strong baselines. We will release the source codes as soon as possible.
Multiscale Collaborative Deep Models for Neural Machine Translation
May 11, 2020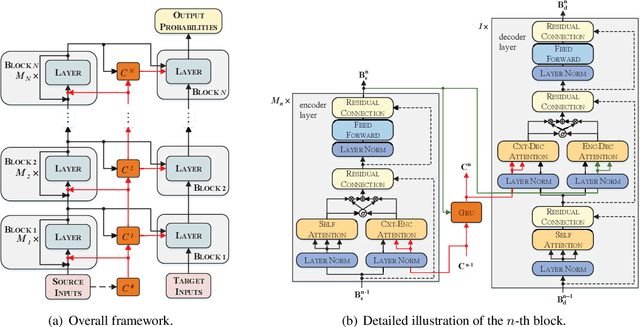

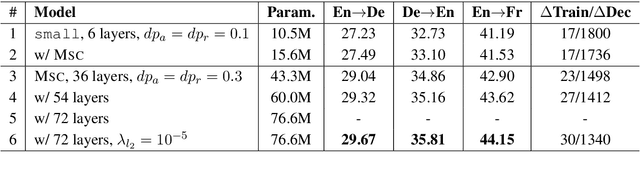
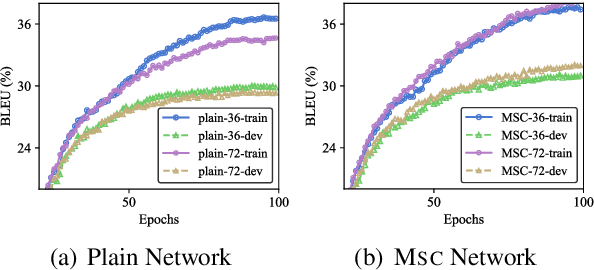
Recent evidence reveals that Neural Machine Translation (NMT) models with deeper neural networks can be more effective but are difficult to train. In this paper, we present a MultiScale Collaborative (MSC) framework to ease the training of NMT models that are substantially deeper than those used previously. We explicitly boost the gradient back-propagation from top to bottom levels by introducing a block-scale collaboration mechanism into deep NMT models. Then, instead of forcing the whole encoder stack directly learns a desired representation, we let each encoder block learns a fine-grained representation and enhance it by encoding spatial dependencies using a context-scale collaboration. We provide empirical evidence showing that the MSC nets are easy to optimize and can obtain improvements of translation quality from considerably increased depth. On IWSLT translation tasks with three translation directions, our extremely deep models (with 72-layer encoders) surpass strong baselines by +2.2~+3.1 BLEU points. In addition, our deep MSC achieves a BLEU score of 30.56 on WMT14 English-German task that significantly outperforms state-of-the-art deep NMT models.