 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy Aware Cascade Network: Bridging Epistemic Uncertainty and Geometric Manifold for 3D Tooth Segmentation
Jan 12, 2026Accurate three-dimensional (3D) tooth segmentation from Cone-Beam Computed Tomography (CBCT) is a prerequisite for digital dental workflows. However, achieving high-fidelity segmentation remains challenging due to adhesion artifacts in naturally occluded scans, which are caused by low contrast and indistinct inter-arch boundaries. To address these limitations, we propose the Anatomy Aware Cascade Network (AACNet), a coarse-to-fine framework designed to resolve boundary ambiguity while maintaining global structural consistency. Specifically, we introduce two mechanisms: the Ambiguity Gated Boundary Refiner (AGBR) and the Signed Distance Map guided Anatomical Attention (SDMAA). The AGBR employs an entropy based gating mechanism to perform targeted feature rectification in high uncertainty transition zones. Meanwhile, the SDMAA integrates implicit geometric constraints via signed distance map to enforce topological consistency, preventing the loss of spatial details associated with standard pooling. Experimental results on a dataset of 125 CBCT volumes demonstrate that AACNet achieves a Dice Similarity Coefficient of 90.17 \% and a 95\% Hausdorff Distance of 3.63 mm, significantly outperforming state-of-the-art methods. Furthermore, the model exhibits strong generalization on an external dataset with an HD95 of 2.19 mm, validating its reliability for downstream clinical applications such as surgical planning. Code for AACNet is available at https://github.com/shiliu0114/AACNet.
MOSS: Motion-based 3D Clothed Human Synthesis from Monocular Video
May 21, 2024



Single-view clothed human reconstruction holds a central position in virtual reality applications, especially in contexts involving intricate human motions. It presents notable challenges in achieving realistic clothing deformation. Current methodologies often overlook the influence of motion on surface deformation, resulting in surfaces lacking the constraints imposed by global motion. To overcome these limitations, we introduce an innovative framework, Motion-Based 3D Clothed Humans Synthesis (MOSS), which employs kinematic information to achieve motion-aware Gaussian split on the human surface. Our framework consists of two modules: Kinematic Gaussian Locating Splatting (KGAS) and Surface Deformation Detector (UID). KGAS incorporates matrix-Fisher distribution to propagate global motion across the body surface. The density and rotation factors of this distribution explicitly control the Gaussians, thereby enhancing the realism of the reconstructed surface. Additionally, to address local occlusions in single-view, based on KGAS, UID identifies significant surfaces, and geometric reconstruction is performed to compensate for these deformations. Experimental results demonstrate that MOSS achieves state-of-the-art visual quality in 3D clothed human synthesis from monocular videos. Notably, we improve the Human NeRF and the Gaussian Splatting by 33.94% and 16.75% in LPIPS* respectively. Codes are available at https://wanghongsheng01.github.io/MOSS/.
Using Frequency Attention to Make Adversarial Patch Powerful Against Person Detector
May 11, 2022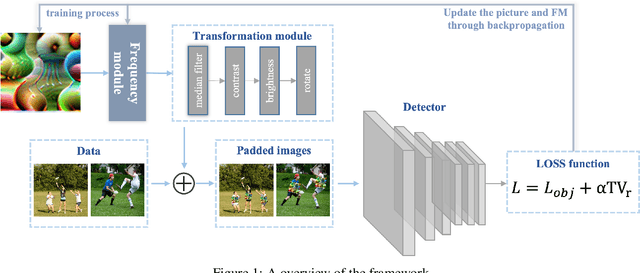

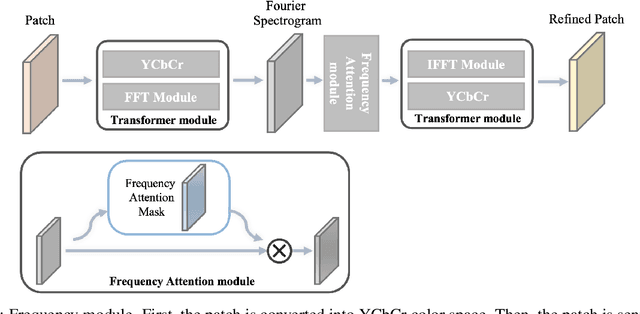
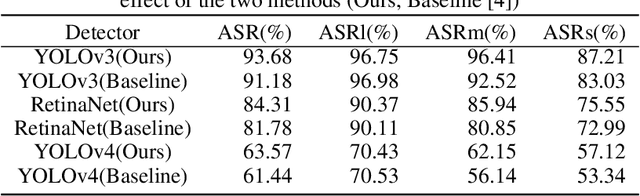
Deep neural networks (DNNs) are vulnerable to adversarial attacks. In particular, object detectors may be attacked by applying a particular adversarial patch to the image. However, because the patch shrinks during preprocessing, most existing approaches that employ adversarial patches to attack object detectors would diminish the attack success rate on small and medium targets. This paper proposes a Frequency Module(FRAN), a frequency-domain attention module for guiding patch generation. This is the first study to introduce frequency domain attention to optimize the attack capabilities of adversarial patches. Our method increases the attack success rates of small and medium targets by 4.18% and 3.89%, respectively, over the state-of-the-art attack method for fooling the human detector while assaulting YOLOv3 without reducing the attack success rate of big targets.