 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning
Oct 23, 2025



Robotic manipulation systems benefit from complementary sensing modalities, where each provides unique environmental information. Point clouds capture detailed geometric structure, while RGB images provide rich semantic context. Current point cloud methods struggle to capture fine-grained detail, especially for complex tasks, which RGB methods lack geometric awareness, which hinders their precision and generalization. We introduce PointMapPolicy, a novel approach that conditions diffusion policies on structured grids of points without downsampling. The resulting data type makes it easier to extract shape and spatial relationships from observations, and can be transformed between reference frames. Yet due to their structure in a regular grid, we enable the use of established computer vision techniques directly to 3D data. Using xLSTM as a backbone, our model efficiently fuses the point maps with RGB data for enhanced multi-modal perception. Through extensive experiments on the RoboCasa and CALVIN benchmarks and real robot evaluations, we demonstrate that our method achieves state-of-the-art performance across diverse manipulation tasks. The overview and demos are available on our project page: https://point-map.github.io/Point-Map/
BEAST: Efficient Tokenization of B-Splines Encoded Action Sequences for Imitation Learning
Jun 06, 2025We present the B-spline Encoded Action Sequence Tokenizer (BEAST), a novel action tokenizer that encodes action sequences into compact discrete or continuous tokens using B-splines. In contrast to existing action tokenizers based on vector quantization or byte pair encoding, BEAST requires no separate tokenizer training and consistently produces tokens of uniform length, enabling fast action sequence generation via parallel decoding. Leveraging our B-spline formulation, BEAST inherently ensures generating smooth trajectories without discontinuities between adjacent segments. We extensively evaluate BEAST by integrating it with three distinct model architectures: a Variational Autoencoder (VAE) with continuous tokens, a decoder-only Transformer with discrete tokens, and Florence-2, a pretrained Vision-Language Model with an encoder-decoder architecture, demonstrating BEAST's compatibility and scalability with large pretrained models. We evaluate BEAST across three established benchmarks consisting of 166 simulated tasks and on three distinct robot settings with a total of 8 real-world tasks. Experimental results demonstrate that BEAST (i) significantly reduces both training and inference computational costs, and (ii) consistently generates smooth, high-frequency control signals suitable for continuous control tasks while (iii) reliably achieves competitive task success rates compared to state-of-the-art methods.
Towards Fusing Point Cloud and Visual Representations for Imitation Learning
Feb 19, 2025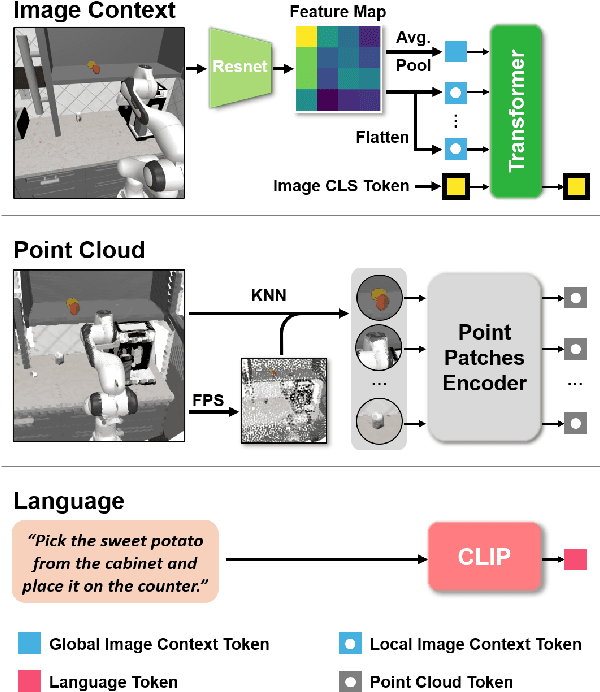
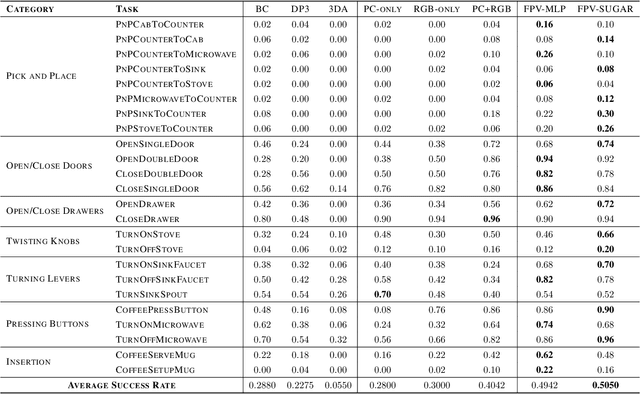
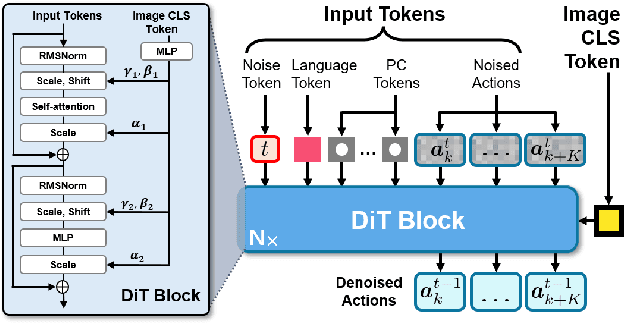
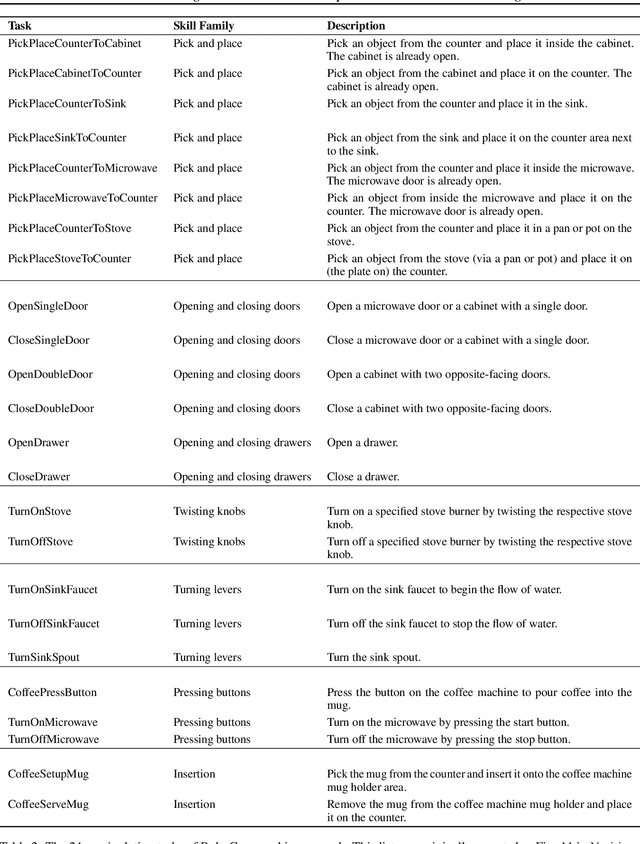
Learning for manipulation requires using policies that have access to rich sensory information such as point clouds or RGB images. Point clouds efficiently capture geometric structures, making them essential for manipulation tasks in imitation learning. In contrast, RGB images provide rich texture and semantic information that can be crucial for certain tasks. Existing approaches for fusing both modalities assign 2D image features to point clouds. However, such approaches often lose global contextual information from the original images. In this work, we propose FPV-Net, a novel imitation learning method that effectively combines the strengths of both point cloud and RGB modalities. Our method conditions the point-cloud encoder on global and local image tokens using adaptive layer norm conditioning, leveraging the beneficial properties of both modalities. Through extensive experiments on the challenging RoboCasa benchmark, we demonstrate the limitations of relying on either modality alone and show that our method achieves state-of-the-art performance across all tasks.
X-IL: Exploring the Design Space of Imitation Learning Policies
Feb 19, 2025Designing modern imitation learning (IL) policies requires making numerous decisions, including the selection of feature encoding, architecture, policy representation, and more. As the field rapidly advances, the range of available options continues to grow, creating a vast and largely unexplored design space for IL policies. In this work, we present X-IL, an accessible open-source framework designed to systematically explore this design space. The framework's modular design enables seamless swapping of policy components, such as backbones (e.g., Transformer, Mamba, xLSTM) and policy optimization techniques (e.g., Score-matching, Flow-matching). This flexibility facilitates comprehensive experimentation and has led to the discovery of novel policy configurations that outperform existing methods on recent robot learning benchmarks. Our experiments demonstrate not only significant performance gains but also provide valuable insights into the strengths and weaknesses of various design choices. This study serves as both a practical reference for practitioners and a foundation for guiding future research in imitation learning.
ETA-IK: Execution-Time-Aware Inverse Kinematics for Dual-Arm Systems
Nov 21, 2024This paper presents ETA-IK, a novel Execution-Time-Aware Inverse Kinematics method tailored for dual-arm robotic systems. The primary goal is to optimize motion execution time by leveraging the redundancy of both arms, specifically in tasks where only the relative pose of the robots is constrained, such as dual-arm scanning of unknown objects. Unlike traditional inverse kinematics methods that use surrogate metrics such as joint configuration distance, our method incorporates direct motion execution time and implicit collisions into the optimization process, thereby finding target joints that allow subsequent trajectory generation to get more efficient and collision-free motion. A neural network based execution time approximator is employed to predict time-efficient joint configurations while accounting for potential collisions. Through experimental evaluation on a system composed of a UR5 and a KUKA iiwa robot, we demonstrate significant reductions in execution time. The proposed method outperforms conventional approaches, showing improved motion efficiency without sacrificing positioning accuracy. These results highlight the potential of ETA-IK to improve the performance of dual-arm systems in applications, where efficiency and safety are paramount.
Planning with Learned Subgoals Selected by Temporal Information
Oct 26, 2024



Path planning in a changing environment is a challenging task in robotics, as moving objects impose time-dependent constraints. Recent planning methods primarily focus on the spatial aspects, lacking the capability to directly incorporate time constraints. In this paper, we propose a method that leverages a generative model to decompose a complex planning problem into small manageable ones by incrementally generating subgoals given the current planning context. Then, we take into account the temporal information and use learned time estimators based on different statistic distributions to examine and select the generated subgoal candidates. Experiments show that planning from the current robot state to the selected subgoal can satisfy the given time-dependent constraints while being goal-oriented.
HIRO: Heuristics Informed Robot Online Path Planning Using Pre-computed Deterministic Roadmaps
Oct 26, 2024With the goal of efficiently computing collision-free robot motion trajectories in dynamically changing environments, we present results of a novel method for Heuristics Informed Robot Online Path Planning (HIRO). Dividing robot environments into static and dynamic elements, we use the static part for initializing a deterministic roadmap, which provides a lower bound of the final path cost as informed heuristics for fast path-finding. These heuristics guide a search tree to explore the roadmap during runtime. The search tree examines the edges using a fuzzy collision checking concerning the dynamic environment. Finally, the heuristics tree exploits knowledge fed back from the fuzzy collision checking module and updates the lower bound for the path cost. As we demonstrate in real-world experiments, the closed-loop formed by these three components significantly accelerates the planning procedure. An additional backtracking step ensures the feasibility of the resulting paths. Experiments in simulation and the real world show that HIRO can find collision-free paths considerably faster than baseline methods with and without prior knowledge of the environment.
dGrasp: NeRF-Informed Implicit Grasp Policies with Supervised Optimization Slopes
Jun 14, 2024We present dGrasp, an implicit grasp policy with an enhanced optimization landscape. This landscape is defined by a NeRF-informed grasp value function. The neural network representing this function is trained on grasp demonstrations. During training, we use an auxiliary loss to guide not only the weight updates of this network but also the update how the slope of the optimization landscape changes. This loss is computed on the demonstrated grasp trajectory and the gradients of the landscape. With second order optimization, we incorporate valuable information from the trajectory as well as facilitate the optimization process of the implicit policy. Experiments demonstrate that employing this auxiliary loss improves policies' performance in simulation as well as their zero-shot transfer to the real-world.
6-DoF Grasp Pose Evaluation and Optimization via Transfer Learning from NeRFs
Jan 15, 2024



We address the problem of robotic grasping of known and unknown objects using implicit behavior cloning. We train a grasp evaluation model from a small number of demonstrations that outputs higher values for grasp candidates that are more likely to succeed in grasping. This evaluation model serves as an objective function, that we maximize to identify successful grasps. Key to our approach is the utilization of learned implicit representations of visual and geometric features derived from a pre-trained NeRF. Though trained exclusively in a simulated environment with simplified objects and 4-DoF top-down grasps, our evaluation model and optimization procedure demonstrate generalization to 6-DoF grasps and novel objects both in simulation and in real-world settings, without the need for additional data. Supplementary material is available at: https://gergely-soti.github.io/grasp
Train What You Know -- Precise Pick-and-Place with Transporter Networks
Feb 17, 2023



Precise pick-and-place is essential in robotic applications. To this end, we define a novel exact training method and an iterative inference method that improve pick-and-place precision with Transporter Networks. We conduct a large scale experiment on 8 simulated tasks. A systematic analysis shows, that the proposed modifications have a significant positive effect on model performance. Considering picking and placing independently, our methods achieve up to 60% lower rotation and translation errors than baselines. For the whole pick-and-place process we observe 50% lower rotation errors for most tasks with slight improvements in terms of translation errors. Furthermore, we propose architectural changes that retain model performance and reduce computational costs and time. We validate our methods with an interactive teaching procedure on real hardware. Supplementary material will be made available at: https://gergely-soti.github.io/p