 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Sep 04, 2023Experimentation on real robots is demanding in terms of time and costs. For this reason, a large part of the reinforcement learning (RL) community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interactions with the environment. The Real Robot Challenge 2022 therefore served as a bridge between the RL and robotics communities by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last years, offline reinforcement learning has matured into a promising paradigm for learning from pre-collected datasets, alleviating the reliance on expensive online interactions. We therefore asked the participants to learn two dexterous manipulation tasks involving pushing, grasping, and in-hand orientation from provided real-robot datasets. An extensive software documentation and an initial stage based on a simulation of the real set-up made the competition particularly accessible. By giving each team plenty of access budget to evaluate their offline-learned policies on a cluster of seven identical real TriFinger platforms, we organized an exciting competition for machine learners and roboticists alike. In this work we state the rules of the competition, present the methods used by the winning teams and compare their results with a benchmark of state-of-the-art offline RL algorithms on the challenge datasets.
Selective Distillation of Weakly Annotated GTD for Vision-based Slab Identification System
Oct 09, 2018
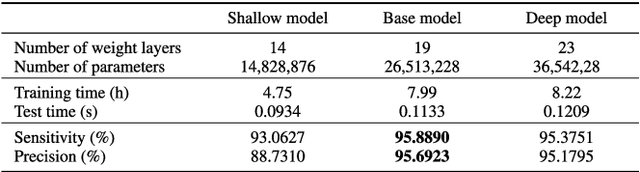
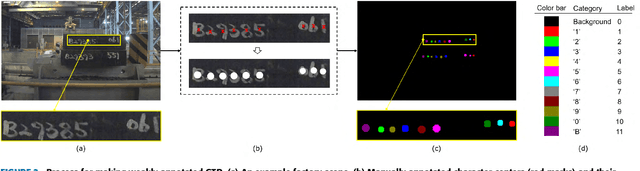

This paper proposes an algorithm for recognizing slab identification numbers in factory scenes. In the development a deep-learning based system, manual labeling for preparing ground truth data (GTD) is an important but expensive task. Furthermore, the quality of GTD is closely related to the performance of a supervised learning algorithm. To reduce manual work in labeling process, we generated weakly annotated GTD by marking only character centroids. Whereas conventional GTD for scene text recognition, bounding-boxes, require at least a drag-and-drop operation or two clicks to annotate a character location, the weakly annotated GTD requires a single click to record a character location. The main contribution of this paper is on selective distillation to improve the quality of the weakly annotated GTD. Because manual GTD are usually generated by many people, it may contain personal bias or human error. To address this problem, the information in manual GTD is integrated and refined by selective distillation. In the process of selective distillation, a fully convolutional network (FCN) is trained using the weakly annotated GTD, and its prediction maps are selectively used to revise locations and boundaries of semantic regions of characters in the initial GTD. The modified GTD are used in main training stage, and a post-processing is conducted to retrieve text information. Experiments were thoroughly conducted on actual industry data collected at a steelworks to demonstrate the effectiveness of the proposed method.