 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-occurring associated retained concepts in Diffusion Unlearning
Jun 23, 2026Unlearning has emerged as a key technique to mitigate harmful content generation in diffusion models. However, existing methods often remove not only the target concept, but also benign co-occurring concepts. As illustrated in Fig.1, unlearning nudity can unintentionally suppress the concept of person, preventing a model from generating images with person. We define these undesirably suppressed co-occurring concepts that must be preserved CARE (Co-occurring Associated REtained concepts). Then, we introduce the CARE score, a general metric that directly quantifies their preservation across unlearning tasks. With this foundation, we propose ReCARE (Robust erasure for CARE), a framework that explicitly safeguards CARE while erasing only the target concept. ReCARE automatically constructs the CARE-set, a curated vocabulary of benign co-occurring tokens extracted from target images, and leverages this vocabulary during training for stable unlearning. Extensive experiments across various target concepts (Nudity, Van Gogh style, and Tench object) demonstrate that ReCARE achieves overall state-of-the-art performance in balancing robust concept erasure, overall utility, and CARE preservation.
SlotGCG: Exploiting the Positional Vulnerability in LLMs for Jailbreak Attacks
Jun 04, 2026As large language models (LLMs) are widely deployed, identifying their vulnerability through jailbreak attacks becomes increasingly critical. Optimization-based attacks like Greedy Coordinate Gradient (GCG) have focused on inserting adversarial tokens to the end of prompts. However, GCG restricts adversarial tokens to a fixed insertion point (typically the prompt suffix), leaving the effect of inserting tokens at other positions unexplored. In this paper, we empirically investigate \emph{slots}, i.e., candidate positions within a prompt where tokens can be inserted. We find that vulnerability to jailbreaking is highly related to the selection of the \emph{slots}. Based on these findings, we introduce the \textit{Vulnerable Slot Score} (VSS) to quantify the positional vulnerability to jailbreaking. We then propose SlotGCG, which evaluates all slots with VSS, selects the most vulnerable slots for insertion, and runs a targeted optimization attack at those slots. Our approach provides a position-search mechanism that is attack-agnostic and can be plugged into any optimization-based attack, adding only 200ms of preprocessing time. Experiments across multiple models demonstrate that SlotGCG significantly outperforms existing methods. Specifically, it achieves 14\% higher Attack Success Rates (ASR) over GCG-based attacks, converges faster, and shows superior robustness against defense methods with 42\% higher ASR than baseline approaches. Our implementation is available at \href{https://github.com/youai058/SlotGCG}{https://github.com/youai058/SlotGCG}
Machine Unlearning for Masked Diffusion Language Models
May 18, 2026Recent masked diffusion language models (MDLMs), such as LLaDA and Dream, have achieved performance comparable to autoregressive large language models. Unlike autoregressive models, which generate text sequentially, MDLMs generate text by iteratively denoising masked positions in parallel. During fine-tuning, MDLMs learn to recover responses from masked response states conditioned on a prompt, thereby shifting their predictions from a prompt-masked unconditional distribution toward a prompt-conditional distribution. Despite this distinct generative and fine-tuning mechanism, machine unlearning for MDLMs remains largely unexplored. In this paper, we propose Masked Diffusion Unlearning (MDU), the first unlearning framework for MDLMs, by revisiting the process of learning specific knowledge in terms of diffusion. Specifically, MDU minimizes a forward KL divergence from the prompt-conditional prediction to a prompt-masked unconditional anchor at every masked response position, with a temperature scaling parameter to control the privacy-utility trade-off. Our empirical results on standard benchmarks and MDLM backbones show that MDU achieves high unlearning performance compared to existing LLM unlearning methods. Code is available at https://github.com/leegeoru/MDU.
SolidCoder: Bridging the Mental-Reality Gap in LLM Code Generation through Concrete Execution
Apr 20, 2026State-of-the-art code generation frameworks rely on mental simulation, where LLMs internally trace execution to verify correctness. We expose a fundamental limitation: the Mental-Reality Gap -- where models hallucinate execution traces and confidently validate buggy code. This gap manifests along two orthogonal dimensions: the Specification Gap (overlooking edge cases during planning) and the Verification Gap (hallucinating correct behavior for flawed code). We propose SolidCoder with a simple principle: don't imagine -- execute. The S.O.L.I.D. architecture addresses both dimensions by forcing edge-case awareness before algorithm design and replacing imagined traces with sandboxed execution using property-based oracles. With GPT-4o, SolidCoder achieves state-of-the-art pass@1 performance: 95.7% on HumanEval (+0.6%p), 77.0% on CodeContests (+4.3%p), and 26.7% on APPS (+3.4%p). Ablation reveals that edge-case awareness provides the largest individual gain, while execution grounding catches categorically different errors that specification improvements cannot address. These gains generalize to RL post-trained models, validating that bridging both gap dimensions is essential for robust code synthesis. We release our code and framework to facilitate future research.
ABBSPO: Adaptive Bounding Box Scaling and Symmetric Prior based Orientation Prediction for Detecting Aerial Image Objects
Dec 10, 2025



Weakly supervised oriented object detection (WS-OOD) has gained attention as a cost-effective alternative to fully supervised methods, providing both efficiency and high accuracy. Among weakly supervised approaches, horizontal bounding box (HBox)-supervised OOD stands out for its ability to directly leverage existing HBox annotations while achieving the highest accuracy under weak supervision settings. This paper introduces adaptive bounding box scaling and symmetry-prior-based orientation prediction, called ABBSPO, a framework for WS-OOD. Our ABBSPO addresses limitations of previous HBox-supervised OOD methods, which compare ground truth (GT) HBoxes directly with the minimum circumscribed rectangles of predicted RBoxes, often leading to inaccurate scale estimation. To overcome this, we propose: (i) Adaptive Bounding Box Scaling (ABBS), which appropriately scales GT HBoxes to optimize for the size of each predicted RBox, ensuring more accurate scale prediction; and (ii) a Symmetric Prior Angle (SPA) loss that exploits inherent symmetry of aerial objects for self-supervised learning, resolving issues in previous methods where learning collapses when predictions for all three augmented views (original, rotated, and flipped) are consistently incorrect. Extensive experimental results demonstrate that ABBSPO achieves state-of-the-art performance, outperforming existing methods.
Repulsive Trajectory Modification and Conflict Resolution for Efficient Multi-Manipulator Motion Planning
Sep 17, 2025We propose an efficient motion planning method designed to efficiently find collision-free trajectories for multiple manipulators. While multi-manipulator systems offer significant advantages, coordinating their motions is computationally challenging owing to the high dimensionality of their composite configuration space. Conflict-Based Search (CBS) addresses this by decoupling motion planning, but suffers from subsequent conflicts incurred by resolving existing conflicts, leading to an exponentially growing constraint tree of CBS. Our proposed method is based on repulsive trajectory modification within the two-level structure of CBS. Unlike conventional CBS variants, the low-level planner applies a gradient descent approach using an Artificial Potential Field. This field generates repulsive forces that guide the trajectory of the conflicting manipulator away from those of other robots. As a result, subsequent conflicts are less likely to occur. Additionally, we develop a strategy that, under a specific condition, directly attempts to find a conflict-free solution in a single step without growing the constraint tree. Through extensive tests including physical robot experiments, we demonstrate that our method consistently reduces the number of expanded nodes in the constraint tree, achieves a higher success rate, and finds a solution faster compared to Enhanced CBS and other state-of-the-art algorithms.
Reactive Composition of UAV Delivery Services in Urban Environments
Apr 29, 2024We propose a novel failure-aware reactive UAV delivery service composition framework. A skyway network infrastructure is presented for the effective provisioning of services in urban areas. We present a formal drone delivery service model and a system architecture for reactive drone delivery services. We develop radius-based, cell density-based, and two-phased algorithms to reduce the search space and perform reactive service compositions when a service failure occurs. We conduct a set of experiments with a real drone dataset to demonstrate the effectiveness of our proposed approach.
Bridged Adversarial Training
Aug 25, 2021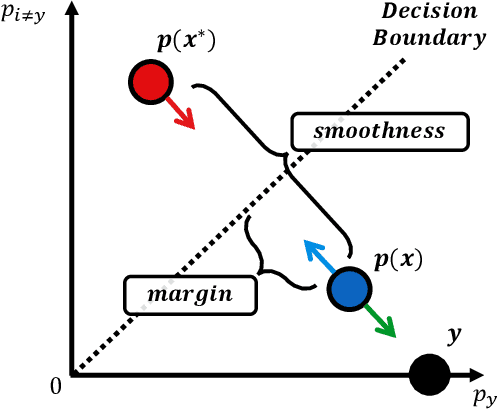
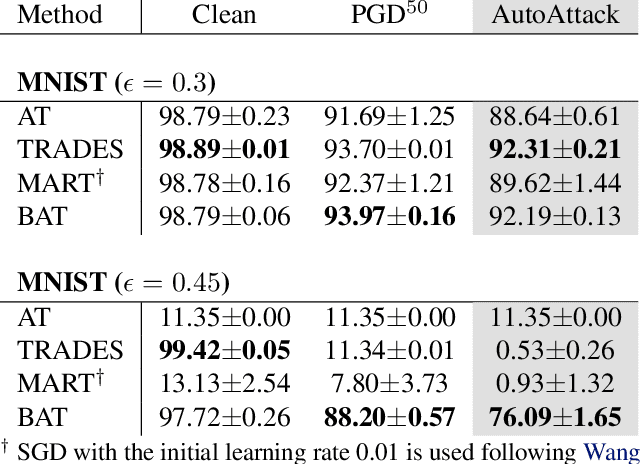
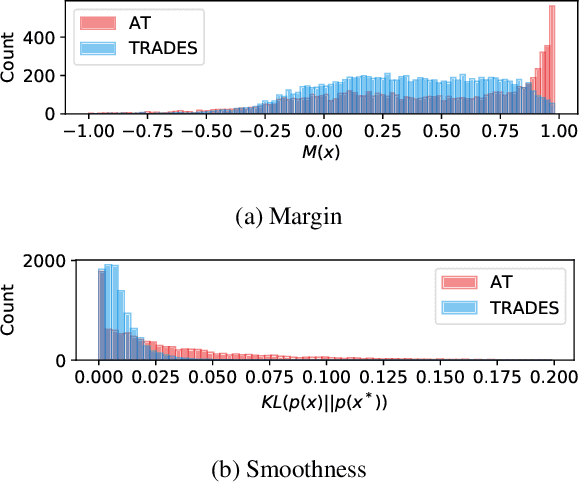
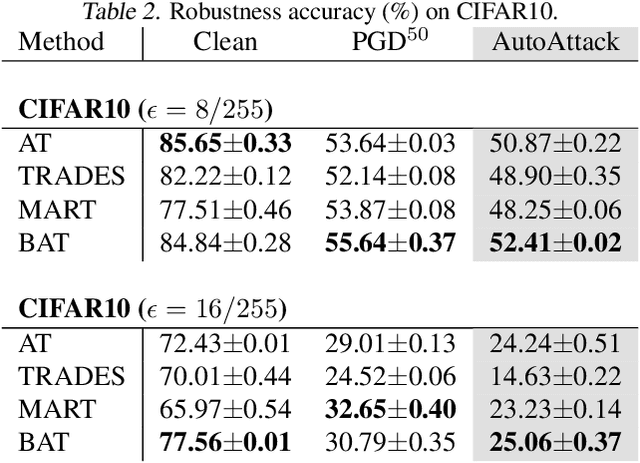
Adversarial robustness is considered as a required property of deep neural networks. In this study, we discover that adversarially trained models might have significantly different characteristics in terms of margin and smoothness, even they show similar robustness. Inspired by the observation, we investigate the effect of different regularizers and discover the negative effect of the smoothness regularizer on maximizing the margin. Based on the analyses, we propose a new method called bridged adversarial training that mitigates the negative effect by bridging the gap between clean and adversarial examples. We provide theoretical and empirical evidence that the proposed method provides stable and better robustness, especially for large perturbations.
Package Delivery Using Autonomous Drones in Skyways
Aug 13, 2021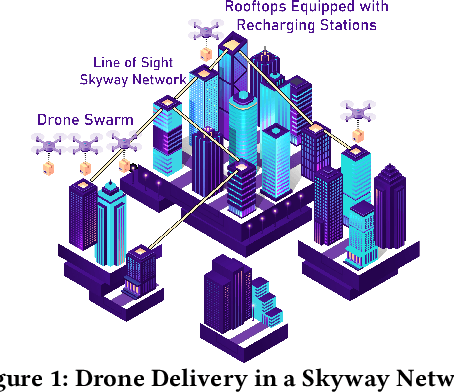

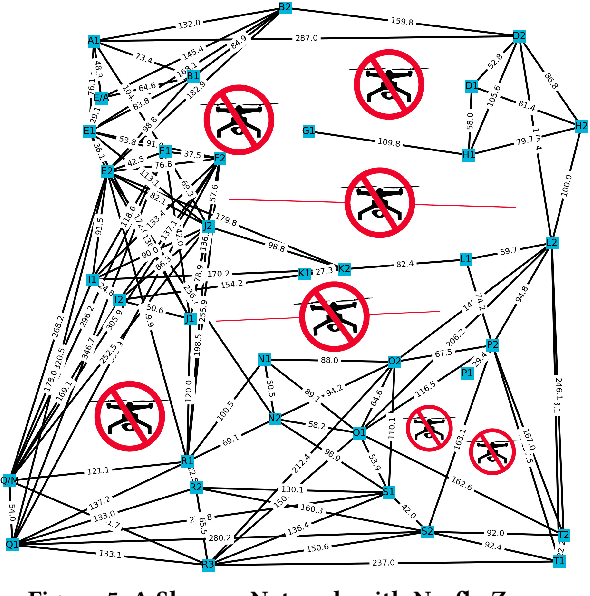
Current drone delivery systems mostly focus on point-to-point package delivery. We present a multi-stop drone service system to deliver packages anywhere anytime within a specified geographic area. We define a skyway network which takes into account flying regulations, including restricted areas and no-fly zones. The skyway nodes typically represent building rooftops which may act as both recharging stations and delivery destinations. A heuristic-based A* algorithm is used to compute an optimal path from source to destination taking into account a number of constraints, including delivery time, availability of recharging stations, etc. We deploy our drone delivery system in an indoor testbed environment using a 3D model of Sydney CBD. We describe a graphical user interface to monitor the real-time package delivery in the skyway network.
Understanding Catastrophic Overfitting in Single-step Adversarial Training
Oct 05, 2020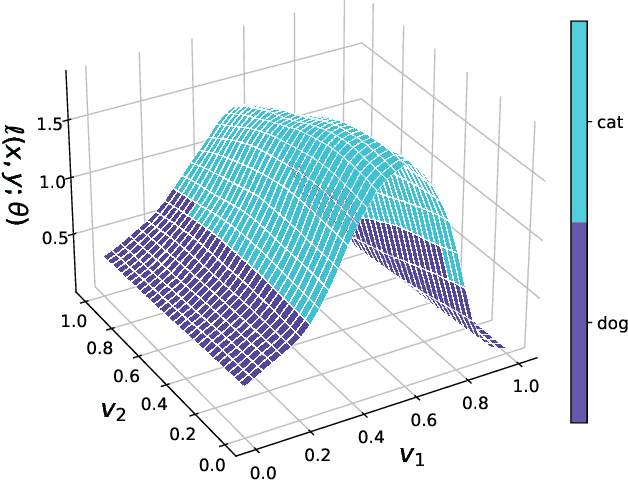
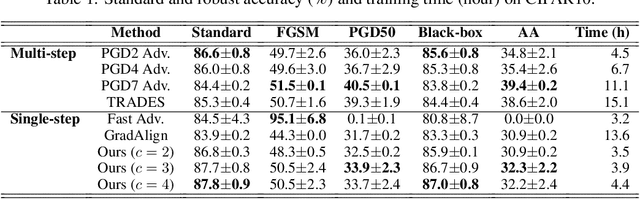
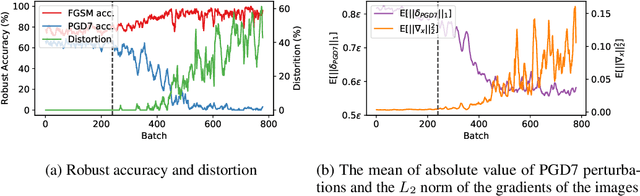
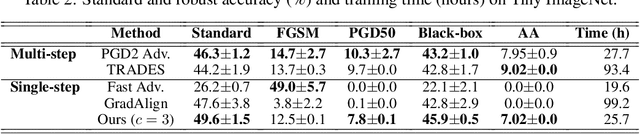
Adversarial examples are perturbed inputs that are designed to deceive machine-learning classifiers by adding adversarial perturbations to the original data. Although fast adversarial training have demonstrated both robustness and efficiency, the problem of "catastrophic overfitting" has been observed. It is a phenomenon that, during single-step adversarial training, the robust accuracy against projected gradient descent (PGD) suddenly decreases to 0% after few epochs, whereas the robustness against fast gradient sign method (FGSM) increases to 100%. In this paper, we address three main topics. (i) We demonstrate that catastrophic overfitting occurs in single-step adversarial training because it trains adversarial images with maximum perturbation only, not all adversarial examples in the adversarial direction, which leads to a distorted decision boundary and a highly curved loss surface. (ii) We experimentally prove this phenomenon by proposing a simple method using checkpoints. This method not only prevents catastrophic overfitting, but also overrides the belief that single-step adversarial training is hard to prevent multi-step attacks. (iii) We compare the performance of the proposed method to that obtained in recent works and demonstrate that it provides sufficient robustness to different attacks even after hundreds of training epochs in less time. All code for reproducing the experiments in this paper are at https://github.com/Harry24k/catastrophic-overfitting.