 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-occurring associated retained concepts in Diffusion Unlearning
Jun 23, 2026Unlearning has emerged as a key technique to mitigate harmful content generation in diffusion models. However, existing methods often remove not only the target concept, but also benign co-occurring concepts. As illustrated in Fig.1, unlearning nudity can unintentionally suppress the concept of person, preventing a model from generating images with person. We define these undesirably suppressed co-occurring concepts that must be preserved CARE (Co-occurring Associated REtained concepts). Then, we introduce the CARE score, a general metric that directly quantifies their preservation across unlearning tasks. With this foundation, we propose ReCARE (Robust erasure for CARE), a framework that explicitly safeguards CARE while erasing only the target concept. ReCARE automatically constructs the CARE-set, a curated vocabulary of benign co-occurring tokens extracted from target images, and leverages this vocabulary during training for stable unlearning. Extensive experiments across various target concepts (Nudity, Van Gogh style, and Tench object) demonstrate that ReCARE achieves overall state-of-the-art performance in balancing robust concept erasure, overall utility, and CARE preservation.
Machine Unlearning for Masked Diffusion Language Models
May 18, 2026Recent masked diffusion language models (MDLMs), such as LLaDA and Dream, have achieved performance comparable to autoregressive large language models. Unlike autoregressive models, which generate text sequentially, MDLMs generate text by iteratively denoising masked positions in parallel. During fine-tuning, MDLMs learn to recover responses from masked response states conditioned on a prompt, thereby shifting their predictions from a prompt-masked unconditional distribution toward a prompt-conditional distribution. Despite this distinct generative and fine-tuning mechanism, machine unlearning for MDLMs remains largely unexplored. In this paper, we propose Masked Diffusion Unlearning (MDU), the first unlearning framework for MDLMs, by revisiting the process of learning specific knowledge in terms of diffusion. Specifically, MDU minimizes a forward KL divergence from the prompt-conditional prediction to a prompt-masked unconditional anchor at every masked response position, with a temperature scaling parameter to control the privacy-utility trade-off. Our empirical results on standard benchmarks and MDLM backbones show that MDU achieves high unlearning performance compared to existing LLM unlearning methods. Code is available at https://github.com/leegeoru/MDU.
BayesNAM: Leveraging Inconsistency for Reliable Explanations
Nov 10, 2024Neural additive model (NAM) is a recently proposed explainable artificial intelligence (XAI) method that utilizes neural network-based architectures. Given the advantages of neural networks, NAMs provide intuitive explanations for their predictions with high model performance. In this paper, we analyze a critical yet overlooked phenomenon: NAMs often produce inconsistent explanations, even when using the same architecture and dataset. Traditionally, such inconsistencies have been viewed as issues to be resolved. However, we argue instead that these inconsistencies can provide valuable explanations within the given data model. Through a simple theoretical framework, we demonstrate that these inconsistencies are not mere artifacts but emerge naturally in datasets with multiple important features. To effectively leverage this information, we introduce a novel framework, Bayesian Neural Additive Model (BayesNAM), which integrates Bayesian neural networks and feature dropout, with theoretical proof demonstrating that feature dropout effectively captures model inconsistencies. Our experiments demonstrate that BayesNAM effectively reveals potential problems such as insufficient data or structural limitations of the model, providing more reliable explanations and potential remedies.
Are Self-Attentions Effective for Time Series Forecasting?
May 27, 2024Time series forecasting is crucial for applications across multiple domains and various scenarios. Although Transformer models have dramatically shifted the landscape of forecasting, their effectiveness remains debated. Recent findings have indicated that simpler linear models might outperform complex Transformer-based approaches, highlighting the potential for more streamlined architectures. In this paper, we shift focus from the overall architecture of the Transformer to the effectiveness of self-attentions for time series forecasting. To this end, we introduce a new architecture, Cross-Attention-only Time Series transformer (CATS), that rethinks the traditional Transformer framework by eliminating self-attention and leveraging cross-attention mechanisms instead. By establishing future horizon-dependent parameters as queries and enhanced parameter sharing, our model not only improves long-term forecasting accuracy but also reduces the number of parameters and memory usage. Extensive experiment across various datasets demonstrates that our model achieves superior performance with the lowest mean squared error and uses fewer parameters compared to existing models.
Fair Sampling in Diffusion Models through Switching Mechanism
Jan 09, 2024Diffusion models have shown their effectiveness in generation tasks by well-approximating the underlying probability distribution. However, diffusion models are known to suffer from an amplified inherent bias from the training data in terms of fairness. While the sampling process of diffusion models can be controlled by conditional guidance, previous works have attempted to find empirical guidance to achieve quantitative fairness. To address this limitation, we propose a fairness-aware sampling method called \textit{attribute switching} mechanism for diffusion models. Without additional training, the proposed sampling can obfuscate sensitive attributes in generated data without relying on classifiers. We mathematically prove and experimentally demonstrate the effectiveness of the proposed method on two key aspects: (i) the generation of fair data and (ii) the preservation of the utility of the generated data.
Differentially Private Sharpness-Aware Training
Jun 09, 2023



Training deep learning models with differential privacy (DP) results in a degradation of performance. The training dynamics of models with DP show a significant difference from standard training, whereas understanding the geometric properties of private learning remains largely unexplored. In this paper, we investigate sharpness, a key factor in achieving better generalization, in private learning. We show that flat minima can help reduce the negative effects of per-example gradient clipping and the addition of Gaussian noise. We then verify the effectiveness of Sharpness-Aware Minimization (SAM) for seeking flat minima in private learning. However, we also discover that SAM is detrimental to the privacy budget and computational time due to its two-step optimization. Thus, we propose a new sharpness-aware training method that mitigates the privacy-optimization trade-off. Our experimental results demonstrate that the proposed method improves the performance of deep learning models with DP from both scratch and fine-tuning. Code is available at https://github.com/jinseongP/DPSAT.
Stability Analysis of Sharpness-Aware Minimization
Jan 16, 2023



Sharpness-aware minimization (SAM) is a recently proposed training method that seeks to find flat minima in deep learning, resulting in state-of-the-art performance across various domains. Instead of minimizing the loss of the current weights, SAM minimizes the worst-case loss in its neighborhood in the parameter space. In this paper, we demonstrate that SAM dynamics can have convergence instability that occurs near a saddle point. Utilizing the qualitative theory of dynamical systems, we explain how SAM becomes stuck in the saddle point and then theoretically prove that the saddle point can become an attractor under SAM dynamics. Additionally, we show that this convergence instability can also occur in stochastic dynamical systems by establishing the diffusion of SAM. We prove that SAM diffusion is worse than that of vanilla gradient descent in terms of saddle point escape. Further, we demonstrate that often overlooked training tricks, momentum and batch-size, are important to mitigate the convergence instability and achieve high generalization performance. Our theoretical and empirical results are thoroughly verified through experiments on several well-known optimization problems and benchmark tasks.
Comment on Transferability and Input Transformation with Additive Noise
Jun 18, 2022Adversarial attacks have verified the existence of the vulnerability of neural networks. By adding small perturbations to a benign example, adversarial attacks successfully generate adversarial examples that lead misclassification of deep learning models. More importantly, an adversarial example generated from a specific model can also deceive other models without modification. We call this phenomenon ``transferability". Here, we analyze the relationship between transferability and input transformation with additive noise by mathematically proving that the modified optimization can produce more transferable adversarial examples.
Bridged Adversarial Training
Aug 25, 2021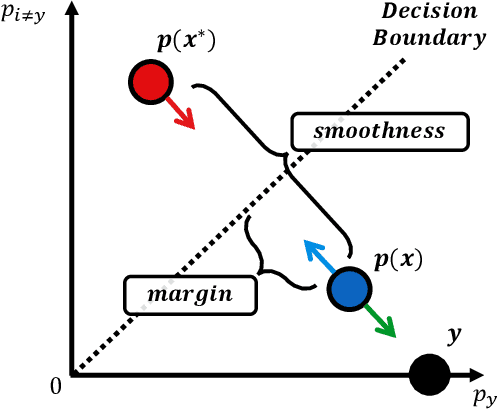
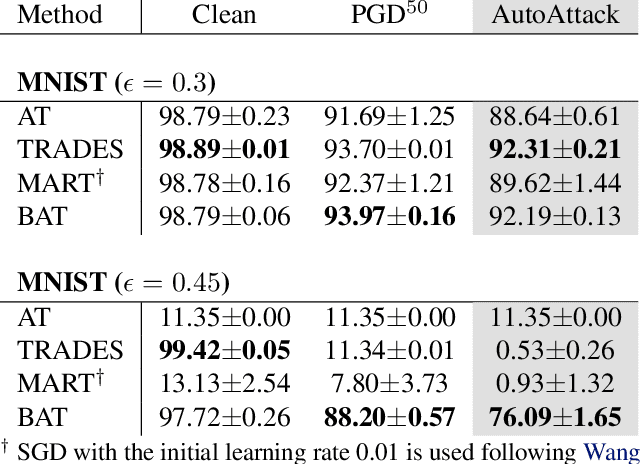
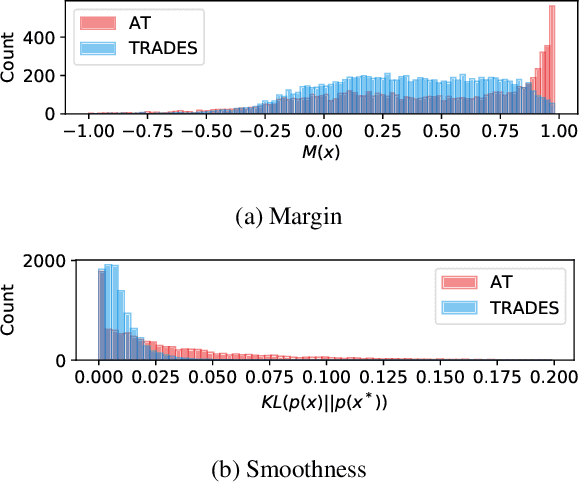
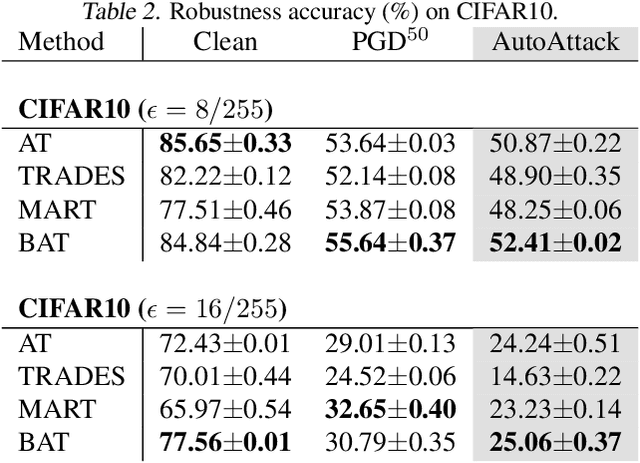
Adversarial robustness is considered as a required property of deep neural networks. In this study, we discover that adversarially trained models might have significantly different characteristics in terms of margin and smoothness, even they show similar robustness. Inspired by the observation, we investigate the effect of different regularizers and discover the negative effect of the smoothness regularizer on maximizing the margin. Based on the analyses, we propose a new method called bridged adversarial training that mitigates the negative effect by bridging the gap between clean and adversarial examples. We provide theoretical and empirical evidence that the proposed method provides stable and better robustness, especially for large perturbations.
GradDiv: Adversarial Robustness of Randomized Neural Networks via Gradient Diversity Regularization
Jul 06, 2021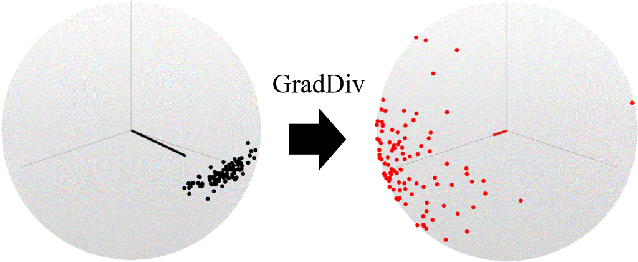
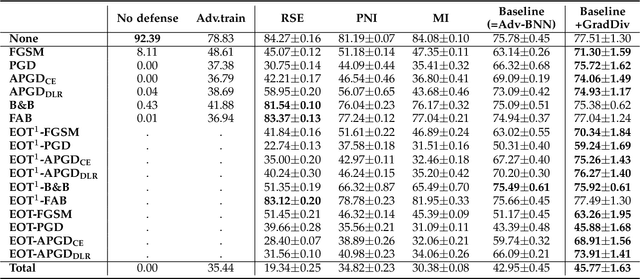
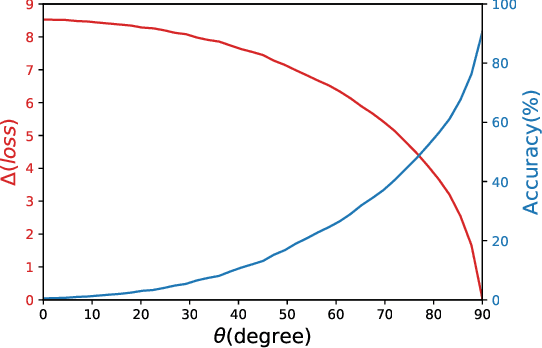

Deep learning is vulnerable to adversarial examples. Many defenses based on randomized neural networks have been proposed to solve the problem, but fail to achieve robustness against attacks using proxy gradients such as the Expectation over Transformation (EOT) attack. We investigate the effect of the adversarial attacks using proxy gradients on randomized neural networks and demonstrate that it highly relies on the directional distribution of the loss gradients of the randomized neural network. We show in particular that proxy gradients are less effective when the gradients are more scattered. To this end, we propose Gradient Diversity (GradDiv) regularizations that minimize the concentration of the gradients to build a robust randomized neural network. Our experiments on MNIST, CIFAR10, and STL10 show that our proposed GradDiv regularizations improve the adversarial robustness of randomized neural networks against a variety of state-of-the-art attack methods. Moreover, our method efficiently reduces the transferability among sample models of randomized neural networks.