 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Descent with Large Step Size Restores Symmetry in Deep Linear Networks with Multi-Pathway
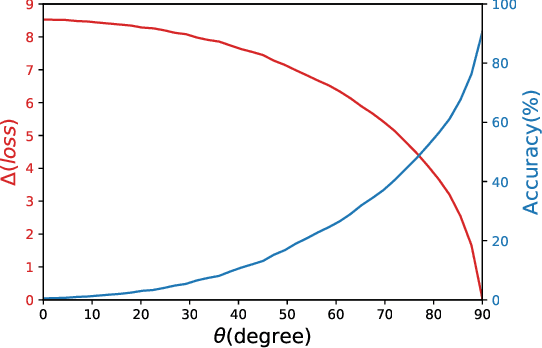
May 29, 2026Recent analyses of multi-pathway Deep Linear Networks use Gradient Flow to predict a "winner-takes-all" specialization in which path symmetry breaks and each feature concentrates in a single pathway. In this work, we show that discrete Gradient Descent (GD) with a large step size tells a different story. We prove that single-path solutions are sharp minima, whereas distributing signals across pathways reduces sharpness by a factor that decreases with both the number of pathways and depth. Consequently, while early training reproduces the depth-driven symmetry breaking predicted by GF, oscillations at the Edge of Stability subsequently override this tendency and drive the network into a re-balancing phase, where signals redistribute across pathways. Together, these results clarify how depth shapes pathway competition and explain why large-step GD favors shared representations rather than persistent single-pathway dominance.
Parallel Tempering Initial Sampling in Inference-Time Reward Alignment
May 29, 2026Inference-time reward alignment steers pretrained diffusion and flow-based generative models to satisfy user-specified rewards without retraining. Recently, Sequential Monte Carlo (SMC) has emerged as a powerful framework for this task by iteratively filtering and propagating multiple particles. However, we show that standard SMC-based methods often suffer from poor performance because they initialize particles from a standard prior, whereas high-reward regions in complex reward landscapes are extremely rare. Further, we show that even recent reward-aware initial sampling approaches remain vulnerable to getting trapped in local modes, as complex reward landscapes are often multi-modal. To overcome these limitations, we propose PATHS (PArallel Tempering for High-complexity reward Sampling), a novel initialization method that couples multiple sampling chains through parallel tempering. PATHS maintains a ladder of reward-tempered chains and periodically performs Metropolis swaps, enabling efficient exploration across flattened reward landscapes, thereby mitigating the mode-trapping issues. Our analysis reveals that this mechanism substantially enhances the finite-budget exploration of rare, high-reward regions that are typically challenging to sample. Experiments on layout-to-image and quantity-aware generation show that PATHS achieves consistent gains in alignment quality, particularly on complex prompts.
Inconsistency-Aware Minimization: Improving Generalization with Unlabeled Data
May 29, 2026Estimating the generalization gap and developing optimization methods that improve generalization are crucial for deep learning models, for both theoretical understanding and practical applications. Leveraging unlabeled data for these purposes offers significant advantages in real-world scenarios. This paper introduces a novel generalization measure, local inconsistency, derived from an information-geometric perspective on the parameter space of neural networks. A key feature of local inconsistency is that it can be computed without explicit labels. We establish theoretical underpinnings by connecting local inconsistency to the Fisher information matrix and the loss Hessian. Empirically, we demonstrate that local inconsistency correlates with the generalization gap. Based on these findings, we propose Inconsistency-Aware Minimization (IAM), which incorporates local inconsistency into the training objective. We demonstrate that in standard supervised learning settings, IAM enhances generalization, achieving performance comparable to that of existing methods such as Sharpness-Aware Minimization. Furthermore, IAM exhibits efficacy in semi- and self-supervised learning scenarios, where the local inconsistency is computed from unlabeled data.
Localizing Memorized Regions in Diffusion Models via Coordinate-Wise Curvature Differences
May 28, 2026Diffusion models can unintentionally memorize training samples, raising concerns about privacy and copyright. While recent methods can detect memorization, they often rely on global or model-specific signals and provide limited insight into where memorization appears within a generated image. We provide a geometric characterization of local memorization as a coordinate-wise variance collapse. However, such collapse can also arise from intrinsic data constraints rather than overfitting. To isolate overfitting-driven memorization, we propose curvature-difference methods that subtract the curvature of an underfitted baseline, either the unconditional model or a less-trained version of itself. We further derive a score-difference proxy that provides a geometric explanation for the widely used score-difference-based detection metric. Experiments on Stable Diffusion, evaluated against ground-truth memorization masks, show that our method outperforms the prior attention-based localization method. Code is available at https://github.com/Gwangho99/mem-curv-diff.
The Mean Squared Error of the Ridgeless Least Squares Estimator under General Assumptions on Regression Errors
May 22, 2023In recent years, there has been a significant growth in research focusing on minimum $\ell_2$ norm (ridgeless) interpolation least squares estimators. However, the majority of these analyses have been limited to a simple regression error structure, assuming independent and identically distributed errors with zero mean and common variance, independent of the feature vectors. Additionally, the main focus of these theoretical analyses has been on the out-of-sample prediction risk. This paper breaks away from the existing literature by examining the mean squared error of the ridgeless interpolation least squares estimator, allowing for more general assumptions about the regression errors. Specifically, we investigate the potential benefits of overparameterization by characterizing the mean squared error in a finite sample. Our findings reveal that including a large number of unimportant parameters relative to the sample size can effectively reduce the mean squared error of the estimator. Notably, we establish that the estimation difficulties associated with the variance term can be summarized through the trace of the variance-covariance matrix of the regression errors.
Bridged Adversarial Training
Aug 25, 2021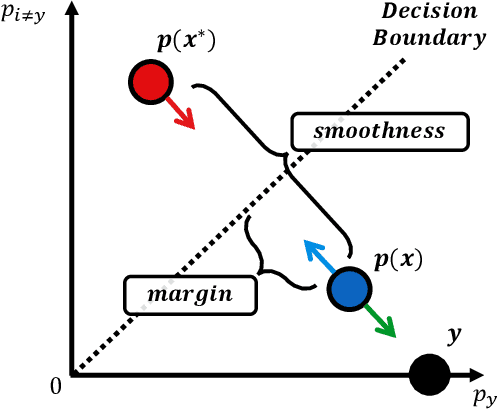
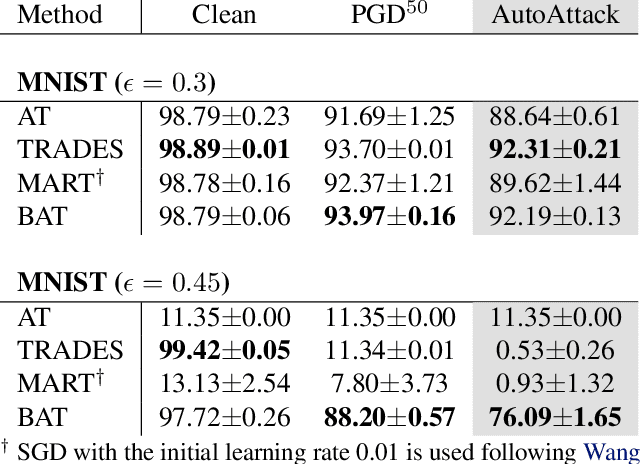
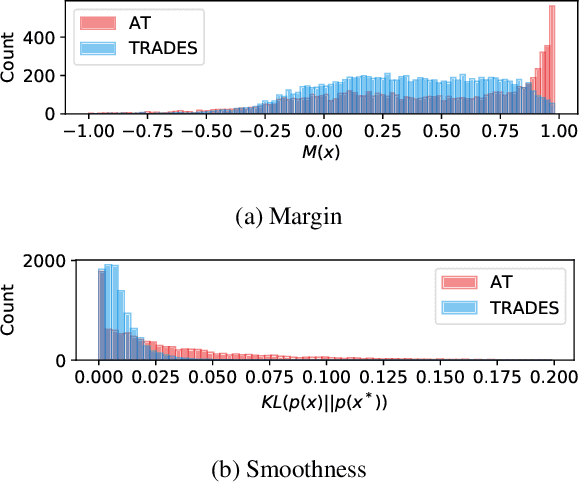
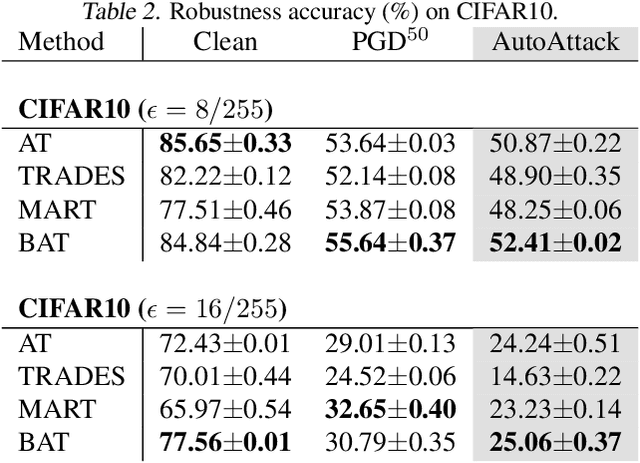
Adversarial robustness is considered as a required property of deep neural networks. In this study, we discover that adversarially trained models might have significantly different characteristics in terms of margin and smoothness, even they show similar robustness. Inspired by the observation, we investigate the effect of different regularizers and discover the negative effect of the smoothness regularizer on maximizing the margin. Based on the analyses, we propose a new method called bridged adversarial training that mitigates the negative effect by bridging the gap between clean and adversarial examples. We provide theoretical and empirical evidence that the proposed method provides stable and better robustness, especially for large perturbations.
GradDiv: Adversarial Robustness of Randomized Neural Networks via Gradient Diversity Regularization
Jul 06, 2021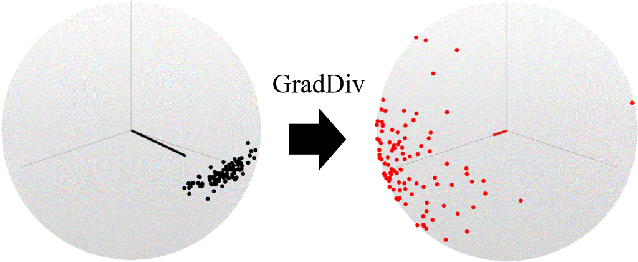
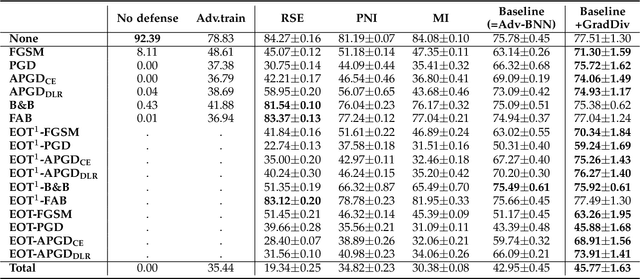

Deep learning is vulnerable to adversarial examples. Many defenses based on randomized neural networks have been proposed to solve the problem, but fail to achieve robustness against attacks using proxy gradients such as the Expectation over Transformation (EOT) attack. We investigate the effect of the adversarial attacks using proxy gradients on randomized neural networks and demonstrate that it highly relies on the directional distribution of the loss gradients of the randomized neural network. We show in particular that proxy gradients are less effective when the gradients are more scattered. To this end, we propose Gradient Diversity (GradDiv) regularizations that minimize the concentration of the gradients to build a robust randomized neural network. Our experiments on MNIST, CIFAR10, and STL10 show that our proposed GradDiv regularizations improve the adversarial robustness of randomized neural networks against a variety of state-of-the-art attack methods. Moreover, our method efficiently reduces the transferability among sample models of randomized neural networks.