 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYMOG: learning symmetric mixture of Gaussian modes for improved fixed-point quantization
Feb 19, 2020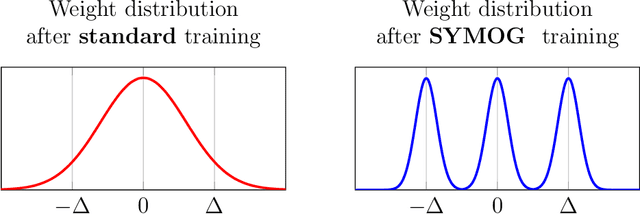
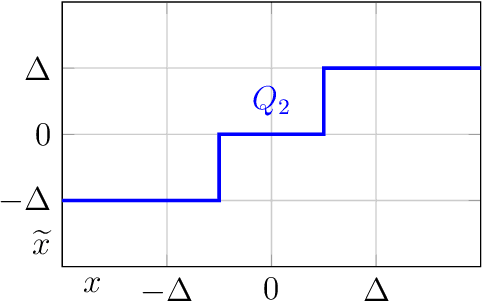
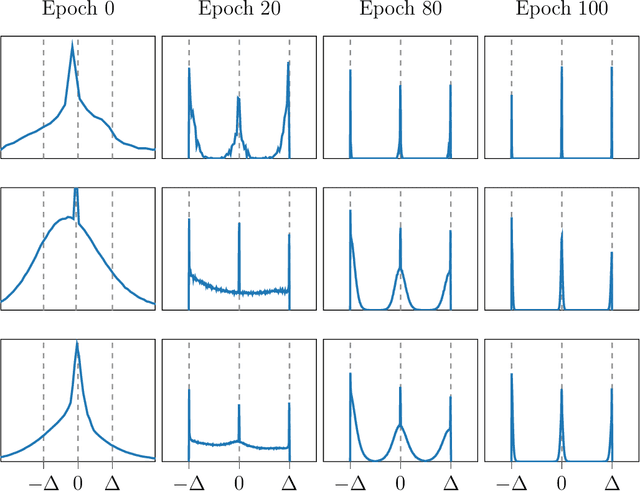
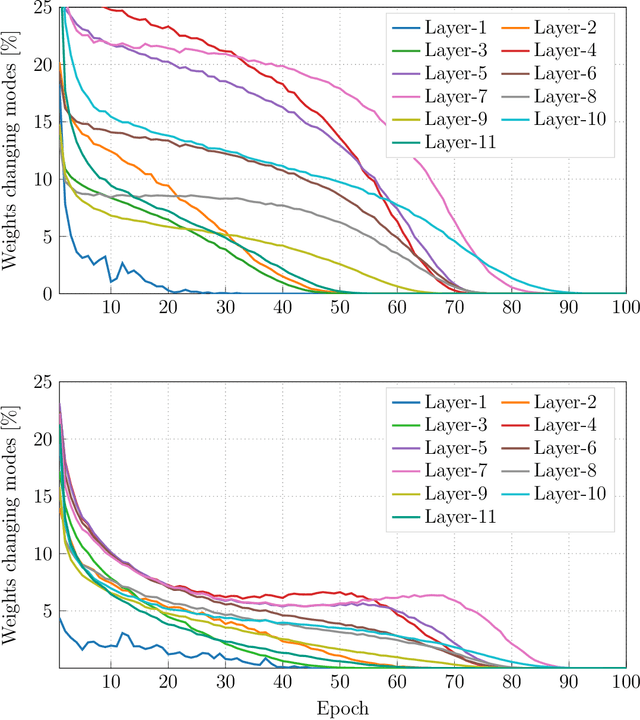
Deep neural networks (DNNs) have been proven to outperform classical methods on several machine learning benchmarks. However, they have high computational complexity and require powerful processing units. Especially when deployed on embedded systems, model size and inference time must be significantly reduced. We propose SYMOG (symmetric mixture of Gaussian modes), which significantly decreases the complexity of DNNs through low-bit fixed-point quantization. SYMOG is a novel soft quantization method such that the learning task and the quantization are solved simultaneously. During training the weight distribution changes from an unimodal Gaussian distribution to a symmetric mixture of Gaussians, where each mean value belongs to a particular fixed-point mode. We evaluate our approach with different architectures (LeNet5, VGG7, VGG11, DenseNet) on common benchmark data sets (MNIST, CIFAR-10, CIFAR-100) and we compare with state-of-the-art quantization approaches. We achieve excellent results and outperform 2-bit state-of-the-art performance with an error rate of only 5.71% on CIFAR-10 and 27.65% on CIFAR-100.
Self-Supervised Visual Terrain Classification from Unsupervised Acoustic Feature Learning
Dec 06, 2019
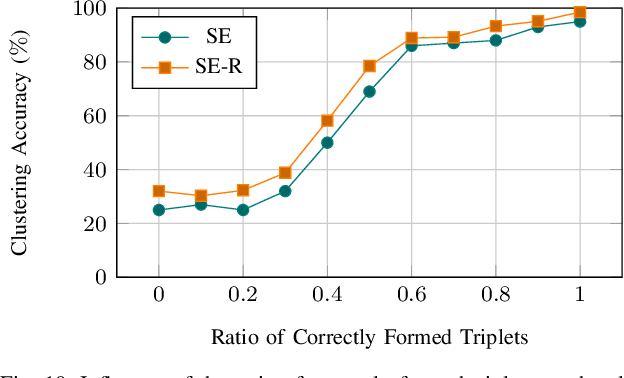

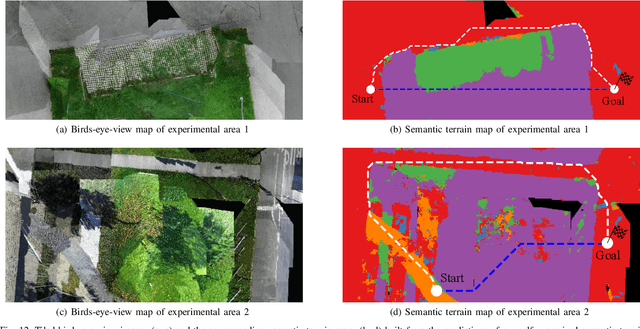
Mobile robots operating in unknown urban environments encounter a wide range of complex terrains to which they must adapt their planned trajectory for safe and efficient navigation. Most existing approaches utilize supervised learning to classify terrains from either an exteroceptive or a proprioceptive sensor modality. However, this requires a tremendous amount of manual labeling effort for each newly encountered terrain as well as for variations of terrains caused by changing environmental conditions. In this work, we propose a novel terrain classification framework leveraging an unsupervised proprioceptive classifier that learns from vehicle-terrain interaction sounds to self-supervise an exteroceptive classifier for pixel-wise semantic segmentation of images. To this end, we first learn a discriminative embedding space for vehicle-terrain interaction sounds from triplets of audio clips formed using visual features of the corresponding terrain patches and cluster the resulting embeddings. We subsequently use these clusters to label the visual terrain patches by projecting the traversed tracks of the robot into the camera images. Finally, we use the sparsely labeled images to train our semantic segmentation network in a weakly supervised manner. We present extensive quantitative and qualitative results that demonstrate that our proprioceptive terrain classifier exceeds the state-of-the-art among unsupervised methods and our self-supervised exteroceptive semantic segmentation model achieves a comparable performance to supervised learning with manually labeled data.
Building an Aerial-Ground Robotics System for Precision Farming
Nov 08, 2019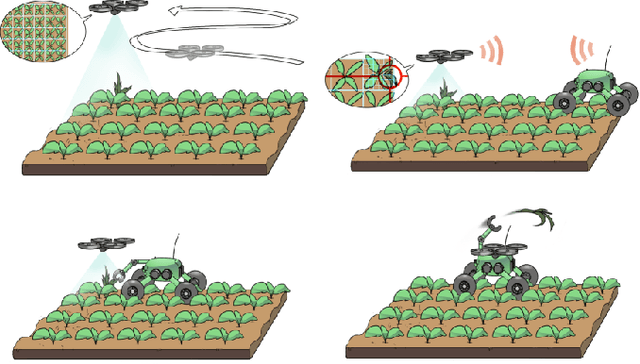

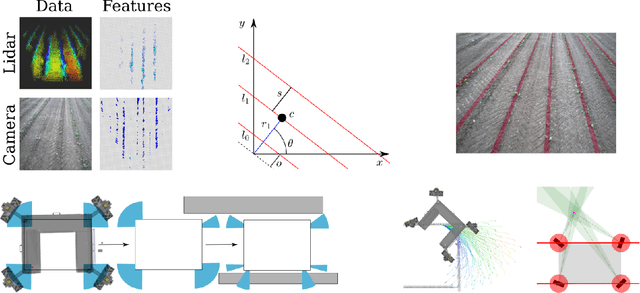
The application of autonomous robots in agriculture is gaining more and more popularity thanks to the high impact it may have on food security, sustainability, resource use efficiency, reduction of chemical treatments, minimization of the human effort and maximization of yield. The Flourish research project faced this challenge by developing an adaptable robotic solution for precision farming that combines the aerial survey capabilities of small autonomous unmanned aerial vehicles (UAVs) with flexible targeted intervention performed by multi-purpose agricultural unmanned ground vehicles (UGVs). This paper presents an exhaustive overview of the scientific and technological advances and outcomes obtained in the Flourish project. We introduce multi-spectral perception algorithms and aerial and ground based systems developed to monitor crop density, weed pressure, crop nitrogen nutrition status, and to accurately classify and locate weeds. We then introduce the navigation and mapping systems to deal with the specificity of the employed robots and of the agricultural environment, highlighting the collaborative modules that enable the UAVs and UGVs to collect and share information in a unified environment model. We finally present the ground intervention hardware, software solutions, and interfaces we implemented and tested in different field conditions and with different crops. We describe here a real use case in which a UAV collaborates with a UGV to monitor the field and to perform selective spraying treatments in a totally autonomous way.
Adaptive Curriculum Generation from Demonstrations for Sim-to-Real Visuomotor Control
Oct 31, 2019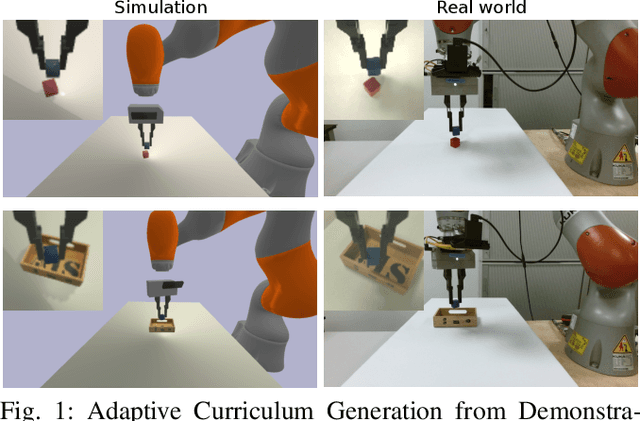
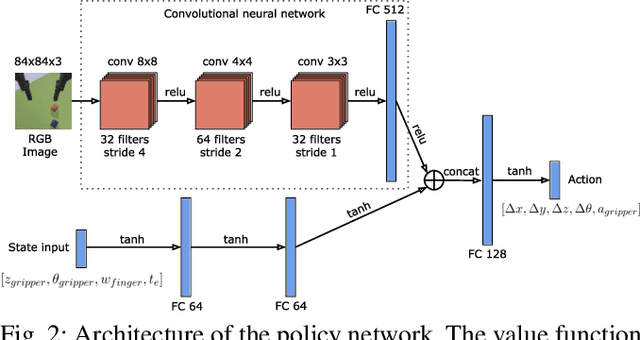
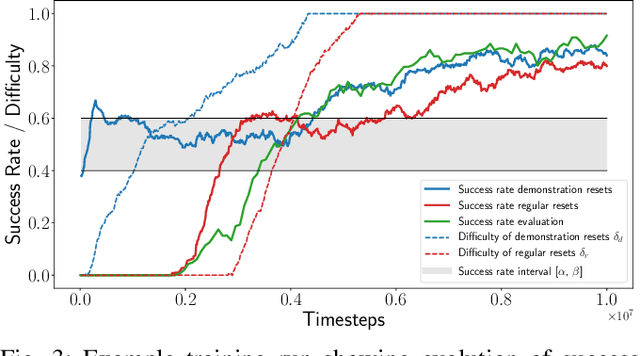
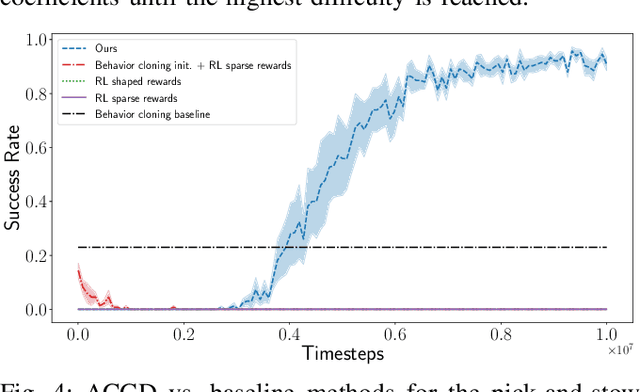
We propose Adaptive Curriculum Generation from Demonstrations (ACGD) for reinforcement learning in the presence of sparse rewards. Rather than designing shaped reward functions, ACGD adaptively sets the appropriate task difficulty for the learner by controlling where to sample from the demonstration trajectories and which set of simulation parameters to use. We show that training vision-based control policies in simulation while gradually increasing the difficulty of the task via ACGD improves the policy transfer to the real world. The degree of domain randomization is also gradually increased through the task difficulty. We demonstrate zero-shot transfer for two real-world manipulation tasks: pick-and-stow and block stacking. A video showing the results can be found at https://lmb.informatik.uni-freiburg.de/projects/curriculum/
Long-Term Urban Vehicle Localization Using Pole Landmarks Extracted from 3-D Lidar Scans
Oct 23, 2019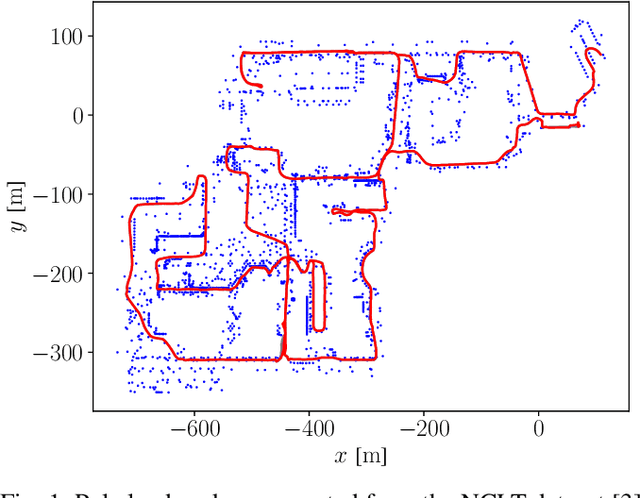
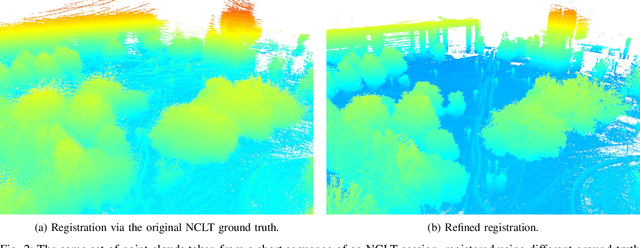
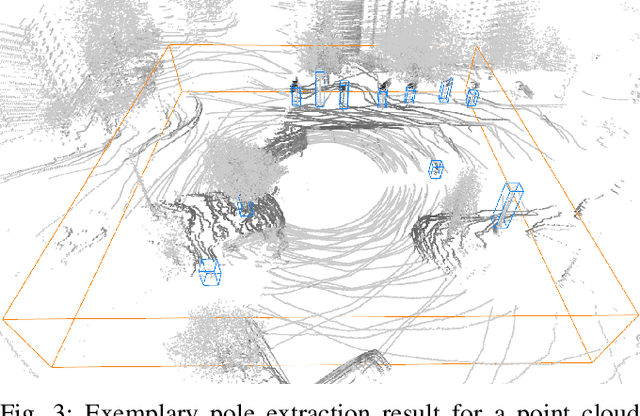
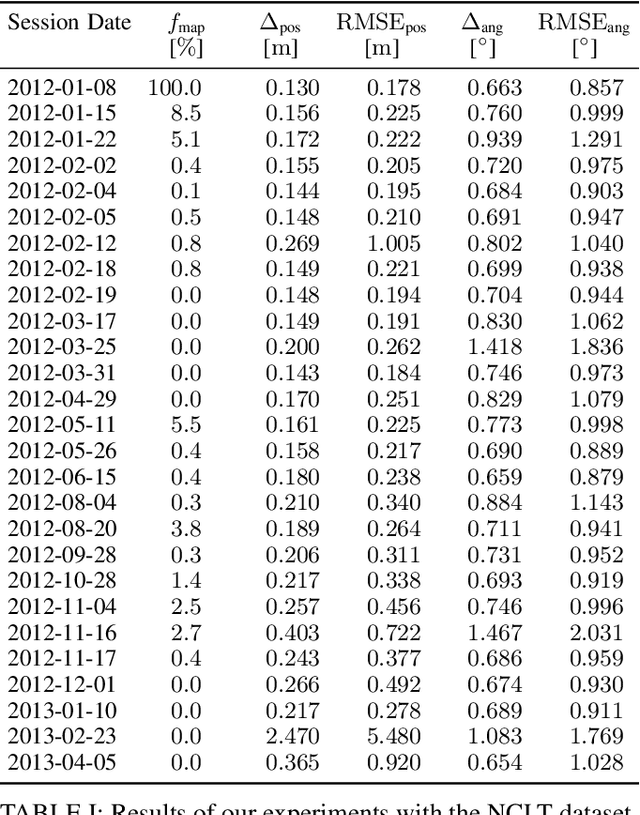
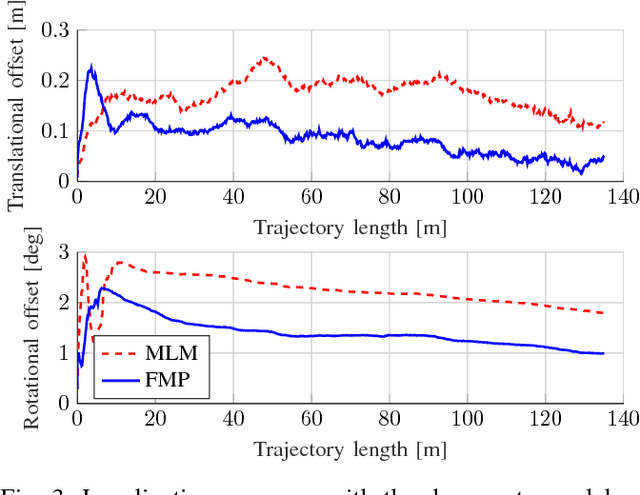
Due to their ubiquity and long-term stability, pole-like objects are well suited to serve as landmarks for vehicle localization in urban environments. In this work, we present a complete mapping and long-term localization system based on pole landmarks extracted from 3-D lidar data. Our approach features a novel pole detector, a mapping module, and an online localization module, each of which are described in detail, and for which we provide an open-source implementation at www.github.com/acschaefer/polex. In extensive experiments, we demonstrate that our method improves on the state of the art with respect to long-term reliability and accuracy: First, we prove reliability by tasking the system with localizing a mobile robot over the course of 15~months in an urban area based on an initial map, confronting it with constantly varying routes, differing weather conditions, seasonal changes, and construction sites. Second, we show that the proposed approach clearly outperforms a recently published method in terms of accuracy.
* 9 pages
A Maximum Likelihood Approach to Extract Finite Planes from 3-D Laser Scans
Oct 23, 2019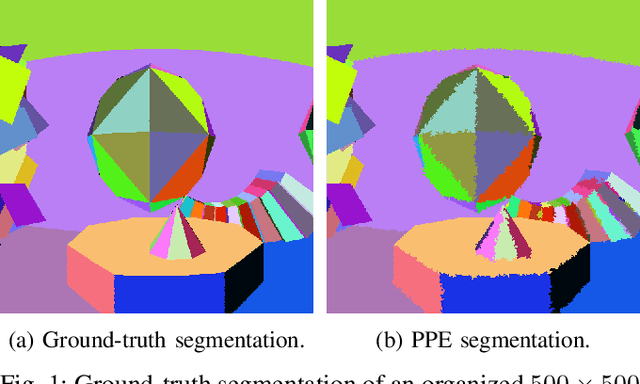

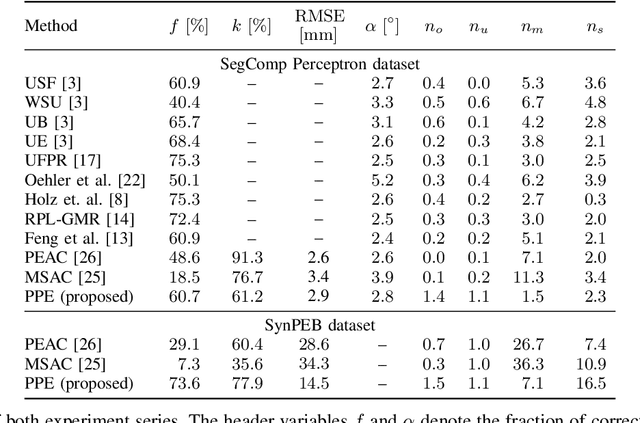
Whether it is object detection, model reconstruction, laser odometry, or point cloud registration: Plane extraction is a vital component of many robotic systems. In this paper, we propose a strictly probabilistic method to detect finite planes in organized 3-D laser range scans. An agglomerative hierarchical clustering technique, our algorithm builds planes from bottom up, always extending a plane by the point that decreases the measurement likelihood of the scan the least. In contrast to most related methods, which rely on heuristics like orthogonal point-to-plane distance, we leverage the ray path information to compute the measurement likelihood. We evaluate our approach not only on the popular SegComp benchmark, but also provide a challenging synthetic dataset that overcomes SegComp's deficiencies. Both our implementation and the suggested dataset are available at www.github.com/acschaefer/ppe.
A Maximum Likelihood Approach to Extract Polylines from 2-D Laser Range Scans
Oct 23, 2019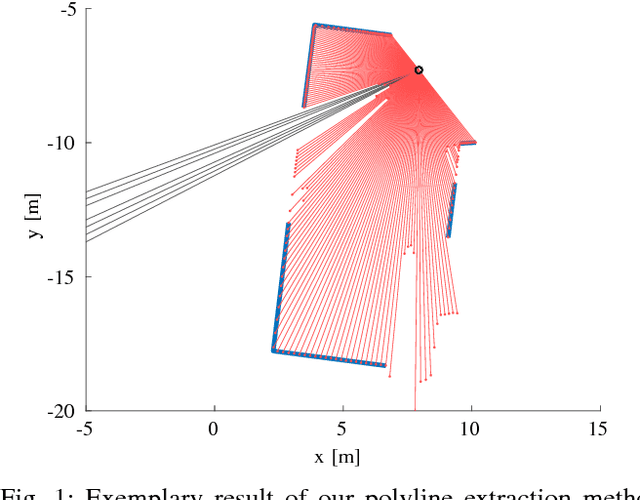
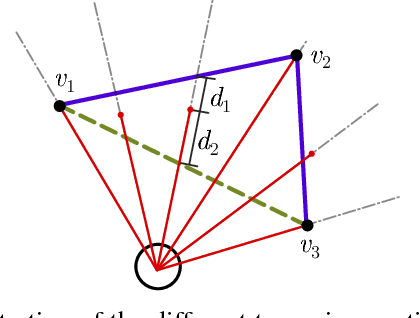
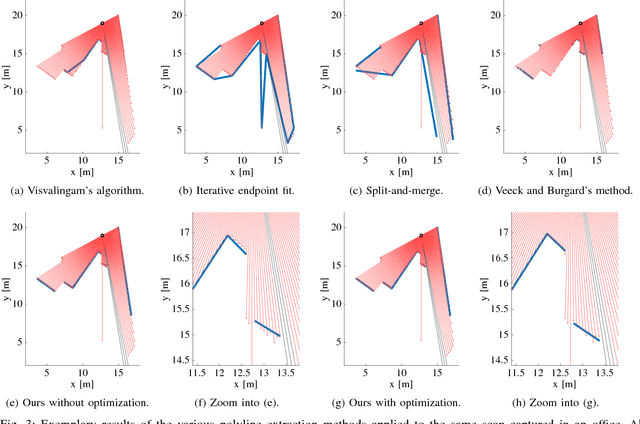
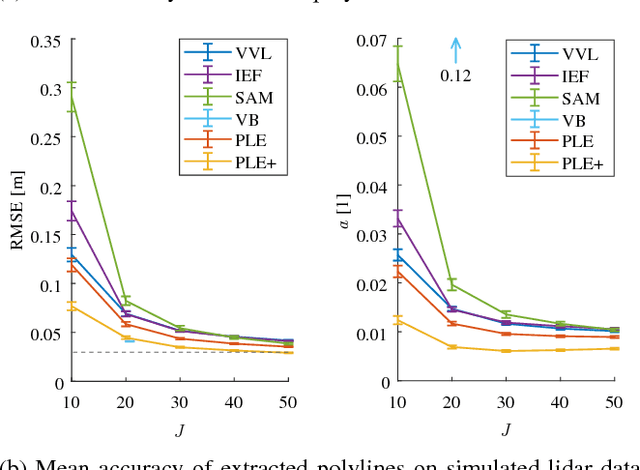
Man-made environments such as households, offices, or factory floors are typically composed of linear structures. Accordingly, polylines are a natural way to accurately represent their geometry. In this paper, we propose a novel probabilistic method to extract polylines from raw 2-D laser range scans. The key idea of our approach is to determine a set of polylines that maximizes the likelihood of a given scan. In extensive experiments carried out on publicly available real-world datasets and on simulated laser scans, we demonstrate that our method substantially outperforms existing state-of-the-art approaches in terms of accuracy, while showing comparable computational requirements. Our implementation is available under https://github.com/acschaefer/ple.
* 9 pages
DCT Maps: Compact Differentiable Lidar Maps Based on the Cosine Transform
Oct 23, 2019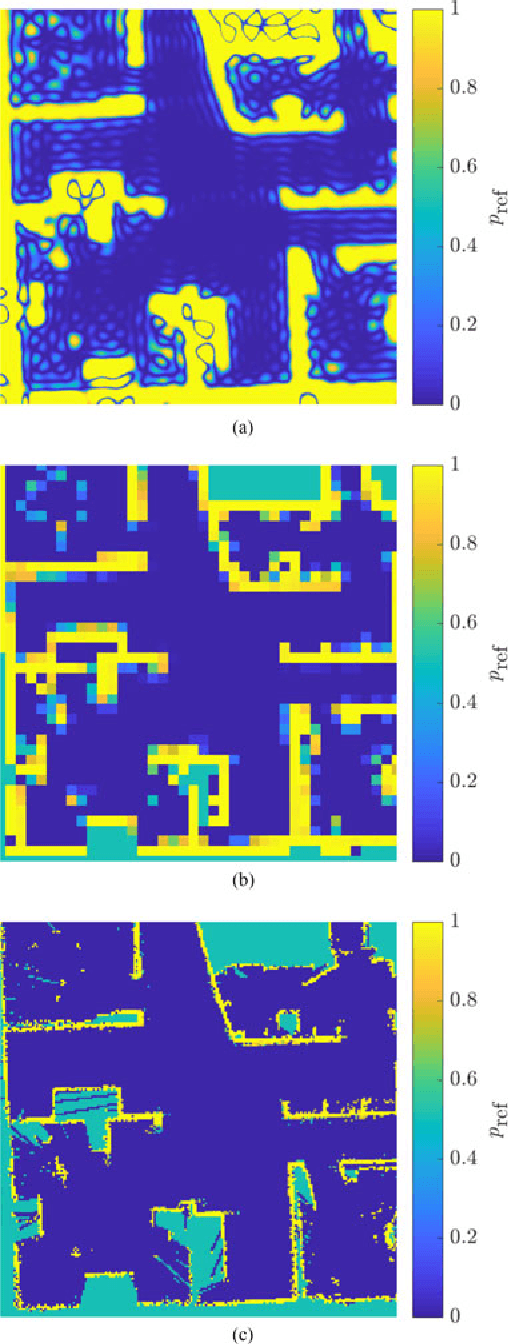
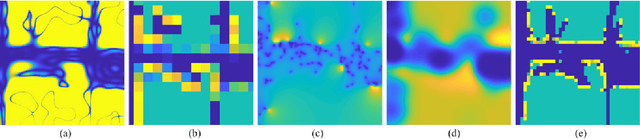

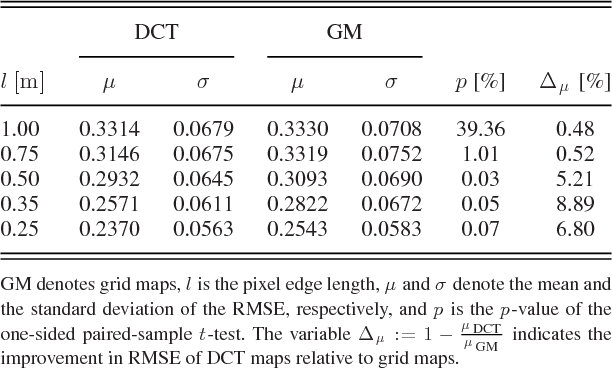
Most robot mapping techniques for lidar sensors tessellate the environment into pixels or voxels and assume uniformity of the environment within them. Although intuitive, this representation entails disadvantages: The resulting grid maps exhibit aliasing effects and are not differentiable. In the present paper, we address these drawbacks by introducing a novel mapping technique that does neither rely on tessellation nor on the assumption of piecewise uniformity of the space, without increasing memory requirements. Instead of representing the map in the position domain, we store the map parameters in the discrete frequency domain and leverage the continuous extension of the inverse discrete cosine transform to convert them to a continuously differentiable scalar field in the position domain, which we call DCT map. A DCT map assigns to each point in space a lidar decay rate, which models the local permeability of the space for laser rays. In this way, the map can describe objects of different laser permeabilities, from completely opaque to completely transparent. DCT maps represent lidar measurements significantly more accurate than grid maps, Gaussian process occupancy maps, and Hilbert maps, all with the same memory requirements, as demonstrated in our real-world experiments.
* 8 pages
Closed-Form Full Map Posteriors for Robot Localization with Lidar Sensors
Oct 23, 2019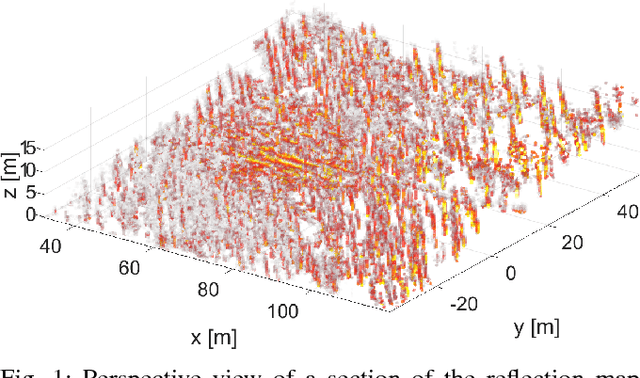
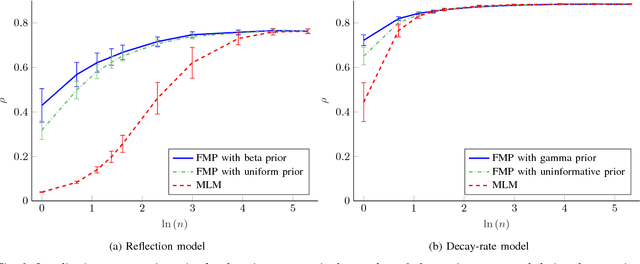

A popular class of lidar-based grid mapping algorithms computes for each map cell the probability that it reflects an incident laser beam. These algorithms typically determine the map as the set of reflection probabilities that maximizes the likelihood of the underlying laser data and do not compute the full posterior distribution over all possible maps. Thereby, they discard crucial information about the confidence of the estimate. The approach presented in this paper preserves this information by determining the full map posterior. In general, this problem is hard because distributions over real-valued quantities can possess infinitely many dimensions. However, for two state-of-the-art beam-based lidar models, our approach yields closed-form map posteriors that possess only two parameters per cell. Even better, these posteriors come for free, in the sense that they use the same parameters as the traditional approaches, without the need for additional computations. An important use case for grid maps is robot localization, which we formulate as Bayesian filtering based on the closed-form map posterior rather than based on a single map. The resulting measurement likelihoods can also be expressed in closed form. In simulations and extensive real-world experiments, we show that leveraging the full map posterior improves the localization accuracy compared to approaches that use the most likely map.
* 7 pages
An Analytical Lidar Sensor Model Based on Ray Path Information
Oct 23, 2019
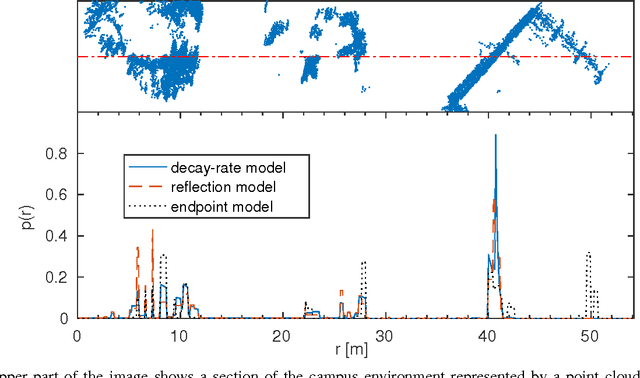


Two core competencies of a mobile robot are to build a map of the environment and to estimate its own pose on the basis of this map and incoming sensor readings. To account for the uncertainties in this process, one typically employs probabilistic state estimation approaches combined with a model of the specific sensor. Over the past years, lidar sensors have become a popular choice for mapping and localization. However, many common lidar models perform poorly in unstructured, unpredictable environments, they lack a consistent physical model for both mapping and localization, and they do not exploit all the information the sensor provides, e.g. out-of-range measurements. In this paper, we introduce a consistent physical model that can be applied to mapping as well as to localization. It naturally deals with unstructured environments and makes use of both out-of-range measurements and information about the ray path. The approach can be seen as a generalization of the well-established reflection model, but in addition to counting ray reflections and traversals in a specific map cell, it considers the distances that all rays travel inside this cell. We prove that the resulting map maximizes the data likelihood and demonstrate that our model outperforms state-of-the-art sensor models in extensive real-world experiments.
* 8 pages