 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Privacy Preserving System for Movie Recommendations using Federated Learning
Mar 07, 2023Recommender systems have become ubiquitous in the past years. They solve the tyranny of choice problem faced by many users, and are employed by many online businesses to drive engagement and sales. Besides other criticisms, like creating filter bubbles within social networks, recommender systems are often reproved for collecting considerable amounts of personal data. However, to personalize recommendations, personal information is fundamentally required. A recent distributed learning scheme called federated learning has made it possible to learn from personal user data without its central collection. Accordingly, we present a complete recommender system for movie recommendations, which provides privacy and thus trustworthiness on two levels: First, it is trained using federated learning and thus is, by its very nature, privacy-preserving, while still enabling individual users to benefit from global insights. And second, a novel federated learning scheme, FedQ, is employed, which not only addresses the problem of non-i.i.d. and small local datasets, but also prevents input data reconstruction attacks by aggregating client models early. To reduce the communication overhead, compression is applied, which significantly reduces the exchanged neural network updates to a fraction of their original data. We conjecture that it may also improve data privacy through its lossy quantization stage.
The Meta-Evaluation Problem in Explainable AI: Identifying Reliable Estimators with MetaQuantus
Feb 14, 2023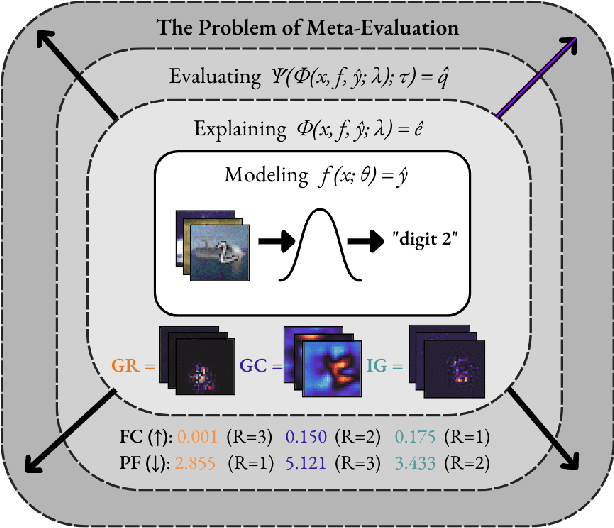



Explainable AI (XAI) is a rapidly evolving field that aims to improve transparency and trustworthiness of AI systems to humans. One of the unsolved challenges in XAI is estimating the performance of these explanation methods for neural networks, which has resulted in numerous competing metrics with little to no indication of which one is to be preferred. In this paper, to identify the most reliable evaluation method in a given explainability context, we propose MetaQuantus -- a simple yet powerful framework that meta-evaluates two complementary performance characteristics of an evaluation method: its resilience to noise and reactivity to randomness. We demonstrate the effectiveness of our framework through a series of experiments, targeting various open questions in XAI, such as the selection of explanation methods and optimisation of hyperparameters of a given metric. We release our work under an open-source license to serve as a development tool for XAI researchers and Machine Learning (ML) practitioners to verify and benchmark newly constructed metrics (i.e., ``estimators'' of explanation quality). With this work, we provide clear and theoretically-grounded guidance for building reliable evaluation methods, thus facilitating standardisation and reproducibility in the field of XAI.
Optimizing Explanations by Network Canonization and Hyperparameter Search
Nov 30, 2022Explainable AI (XAI) is slowly becoming a key component for many AI applications. Rule-based and modified backpropagation XAI approaches however often face challenges when being applied to modern model architectures including innovative layer building blocks, which is caused by two reasons. Firstly, the high flexibility of rule-based XAI methods leads to numerous potential parameterizations. Secondly, many XAI methods break the implementation-invariance axiom because they struggle with certain model components, e.g., BatchNorm layers. The latter can be addressed with model canonization, which is the process of re-structuring the model to disregard problematic components without changing the underlying function. While model canonization is straightforward for simple architectures (e.g., VGG, ResNet), it can be challenging for more complex and highly interconnected models (e.g., DenseNet). Moreover, there is only little quantifiable evidence that model canonization is beneficial for XAI. In this work, we propose canonizations for currently relevant model blocks applicable to popular deep neural network architectures,including VGG, ResNet, EfficientNet, DenseNets, as well as Relation Networks. We further suggest a XAI evaluation framework with which we quantify and compare the effect sof model canonization for various XAI methods in image classification tasks on the Pascal-VOC and ILSVRC2017 datasets, as well as for Visual Question Answering using CLEVR-XAI. Moreover, addressing the former issue outlined above, we demonstrate how our evaluation framework can be applied to perform hyperparameter search for XAI methods to optimize the quality of explanations.
Shortcomings of Top-Down Randomization-Based Sanity Checks for Evaluations of Deep Neural Network Explanations
Nov 22, 2022



While the evaluation of explanations is an important step towards trustworthy models, it needs to be done carefully, and the employed metrics need to be well-understood. Specifically model randomization testing is often overestimated and regarded as a sole criterion for selecting or discarding certain explanation methods. To address shortcomings of this test, we start by observing an experimental gap in the ranking of explanation methods between randomization-based sanity checks [1] and model output faithfulness measures (e.g. [25]). We identify limitations of model-randomization-based sanity checks for the purpose of evaluating explanations. Firstly, we show that uninformative attribution maps created with zero pixel-wise covariance easily achieve high scores in this type of checks. Secondly, we show that top-down model randomization preserves scales of forward pass activations with high probability. That is, channels with large activations have a high probility to contribute strongly to the output, even after randomization of the network on top of them. Hence, explanations after randomization can only be expected to differ to a certain extent. This explains the observed experimental gap. In summary, these results demonstrate the inadequacy of model-randomization-based sanity checks as a criterion to rank attribution methods.
Revealing Hidden Context Bias in Segmentation and Object Detection through Concept-specific Explanations
Nov 21, 2022



Applying traditional post-hoc attribution methods to segmentation or object detection predictors offers only limited insights, as the obtained feature attribution maps at input level typically resemble the models' predicted segmentation mask or bounding box. In this work, we address the need for more informative explanations for these predictors by proposing the post-hoc eXplainable Artificial Intelligence method L-CRP to generate explanations that automatically identify and visualize relevant concepts learned, recognized and used by the model during inference as well as precisely locate them in input space. Our method therefore goes beyond singular input-level attribution maps and, as an approach based on the recently published Concept Relevance Propagation technique, is efficiently applicable to state-of-the-art black-box architectures in segmentation and object detection, such as DeepLabV3+ and YOLOv6, among others. We verify the faithfulness of our proposed technique by quantitatively comparing different concept attribution methods, and discuss the effect on explanation complexity on popular datasets such as CityScapes, Pascal VOC and MS COCO 2017. The ability to precisely locate and communicate concepts is used to reveal and verify the use of background features, thereby highlighting possible biases of the model.
Data Models for Dataset Drift Controls in Machine Learning With Images
Nov 04, 2022



Camera images are ubiquitous in machine learning research. They also play a central role in the delivery of important services spanning medicine and environmental surveying. However, the application of machine learning models in these domains has been limited because of robustness concerns. A primary failure mode are performance drops due to differences between the training and deployment data. While there are methods to prospectively validate the robustness of machine learning models to such dataset drifts, existing approaches do not account for explicit models of the primary object of interest: the data. This makes it difficult to create physically faithful drift test cases or to provide specifications of data models that should be avoided when deploying a machine learning model. In this study, we demonstrate how these shortcomings can be overcome by pairing machine learning robustness validation with physical optics. We examine the role raw sensor data and differentiable data models can play in controlling performance risks related to image dataset drift. The findings are distilled into three applications. First, drift synthesis enables the controlled generation of physically faithful drift test cases. The experiments presented here show that the average decrease in model performance is ten to four times less severe than under post-hoc augmentation testing. Second, the gradient connection between task and data models allows for drift forensics that can be used to specify performance-sensitive data models which should be avoided during deployment of a machine learning model. Third, drift adjustment opens up the possibility for processing adjustments in the face of drift. This can lead to speed up and stabilization of classifier training at a margin of up to 20% in validation accuracy. A guide to access the open code and datasets is available at https://github.com/aiaudit-org/raw2logit.
From "Where" to "What": Towards Human-Understandable Explanations through Concept Relevance Propagation
Jun 07, 2022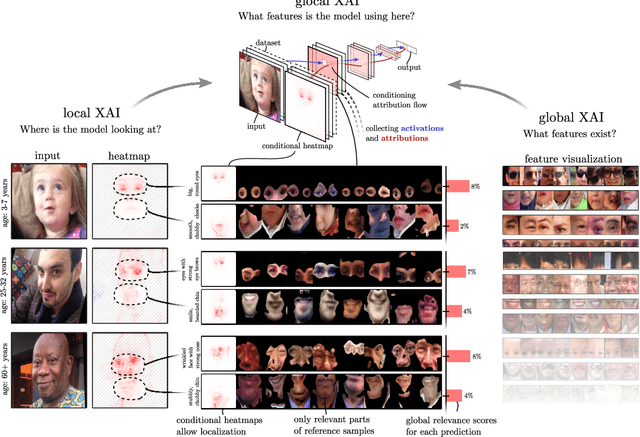
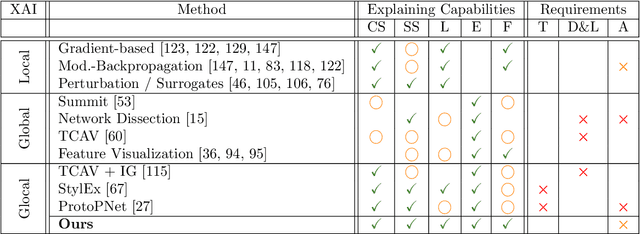
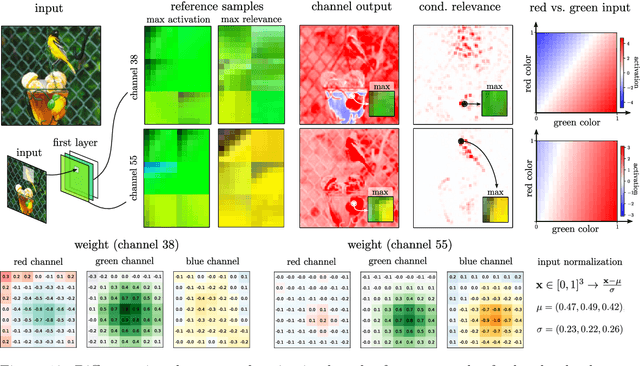

The emerging field of eXplainable Artificial Intelligence (XAI) aims to bring transparency to today's powerful but opaque deep learning models. While local XAI methods explain individual predictions in form of attribution maps, thereby identifying where important features occur (but not providing information about what they represent), global explanation techniques visualize what concepts a model has generally learned to encode. Both types of methods thus only provide partial insights and leave the burden of interpreting the model's reasoning to the user. Only few contemporary techniques aim at combining the principles behind both local and global XAI for obtaining more informative explanations. Those methods, however, are often limited to specific model architectures or impose additional requirements on training regimes or data and label availability, which renders the post-hoc application to arbitrarily pre-trained models practically impossible. In this work we introduce the Concept Relevance Propagation (CRP) approach, which combines the local and global perspectives of XAI and thus allows answering both the "where" and "what" questions for individual predictions, without additional constraints imposed. We further introduce the principle of Relevance Maximization for finding representative examples of encoded concepts based on their usefulness to the model. We thereby lift the dependency on the common practice of Activation Maximization and its limitations. We demonstrate the capabilities of our methods in various settings, showcasing that Concept Relevance Propagation and Relevance Maximization lead to more human interpretable explanations and provide deep insights into the model's representations and reasoning through concept atlases, concept composition analyses, and quantitative investigations of concept subspaces and their role in fine-grained decision making.
FedAUXfdp: Differentially Private One-Shot Federated Distillation
May 30, 2022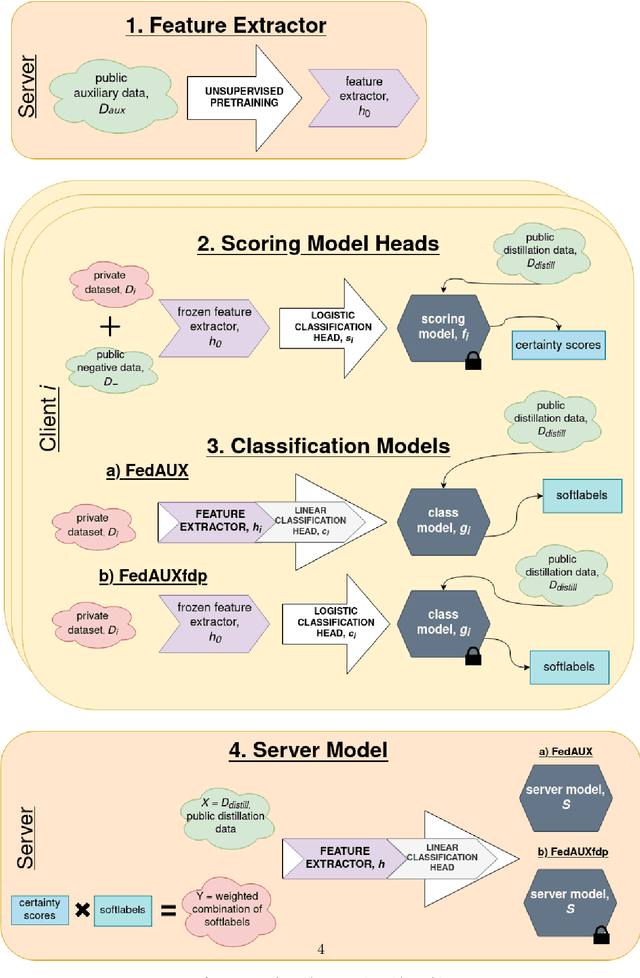



Federated learning suffers in the case of non-iid local datasets, i.e., when the distributions of the clients' data are heterogeneous. One promising approach to this challenge is the recently proposed method FedAUX, an augmentation of federated distillation with robust results on even highly heterogeneous client data. FedAUX is a partially $(\epsilon, \delta)$-differentially private method, insofar as the clients' private data is protected in only part of the training it takes part in. This work contributes a fully differentially private extension, termed FedAUXfdp. In experiments with deep networks on large-scale image datasets, FedAUXfdp with strong differential privacy guarantees performs significantly better than other equally privatized SOTA baselines on non-iid client data in just a single communication round. Full privatization results in a negligible reduction in accuracy at all levels of data heterogeneity.
Decentral and Incentivized Federated Learning Frameworks: A Systematic Literature Review
May 18, 2022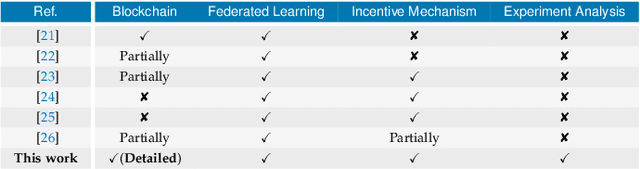
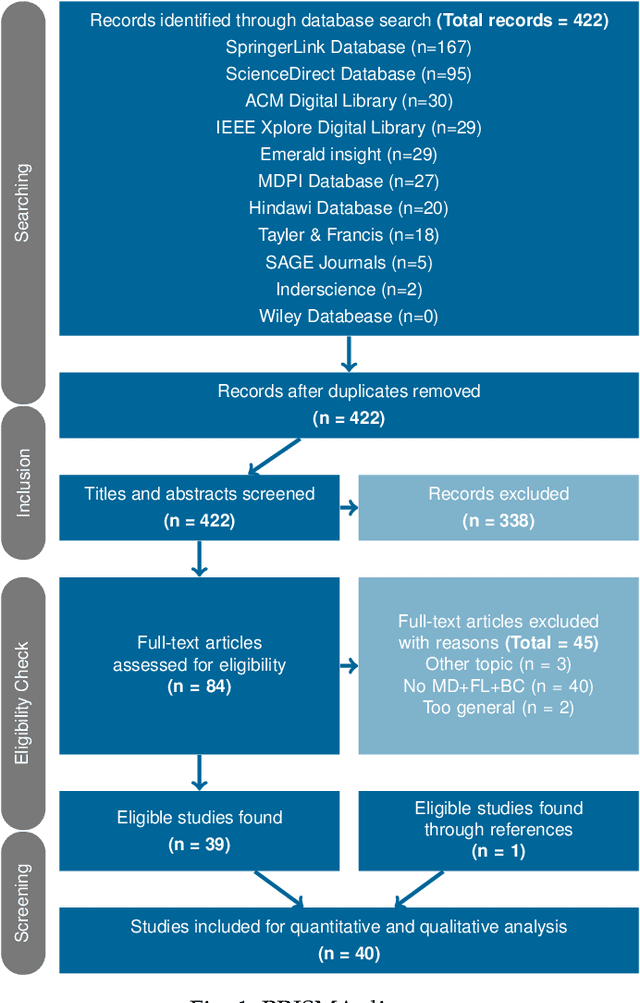
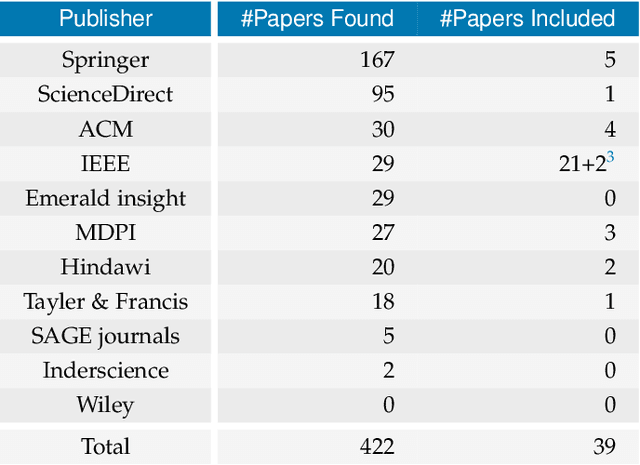
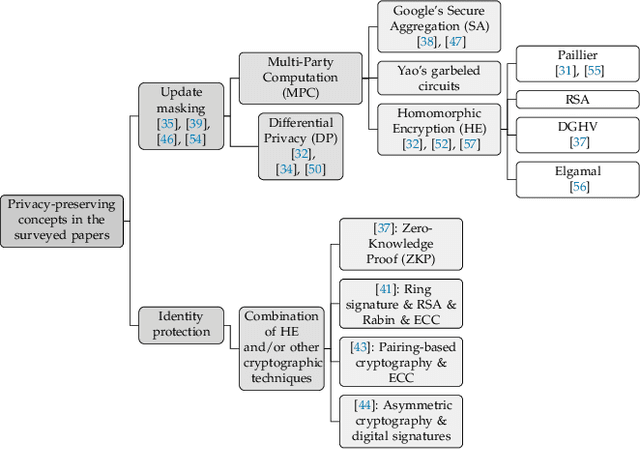
The advent of Federated Learning (FL) has ignited a new paradigm for parallel and confidential decentralized Machine Learning (ML) with the potential of utilizing the computational power of a vast number of IoT, mobile and edge devices without data leaving the respective device, ensuring privacy by design. Yet, in order to scale this new paradigm beyond small groups of already entrusted entities towards mass adoption, the Federated Learning Framework (FLF) has to become (i) truly decentralized and (ii) participants have to be incentivized. This is the first systematic literature review analyzing holistic FLFs in the domain of both, decentralized and incentivized federated learning. 422 publications were retrieved, by querying 12 major scientific databases. Finally, 40 articles remained after a systematic review and filtering process for in-depth examination. Although having massive potential to direct the future of a more distributed and secure AI, none of the analyzed FLF is production-ready. The approaches vary heavily in terms of use-cases, system design, solved issues and thoroughness. We are the first to provide a systematic approach to classify and quantify differences between FLF, exposing limitations of current works and derive future directions for research in this novel domain.
Explain to Not Forget: Defending Against Catastrophic Forgetting with XAI
May 11, 2022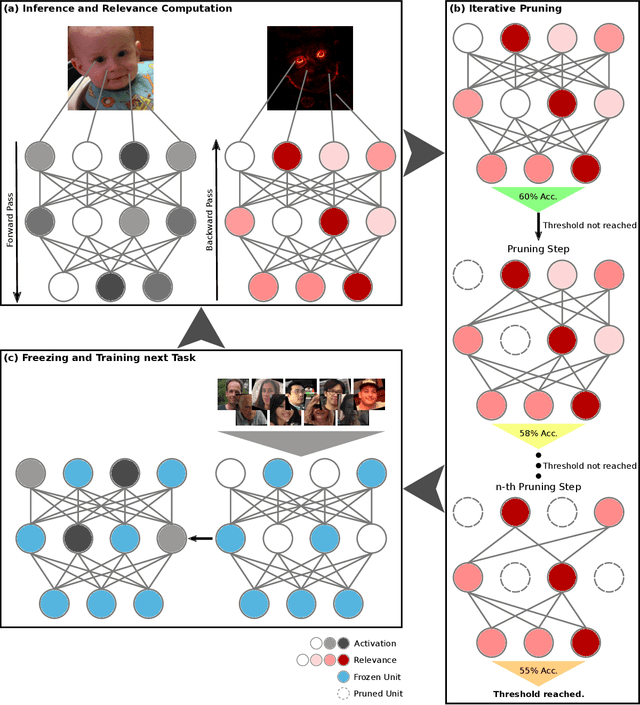
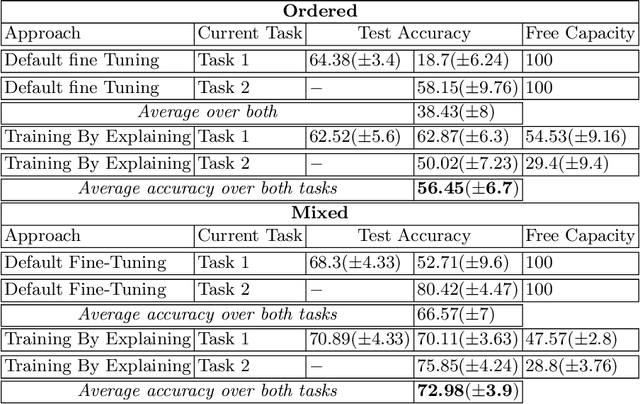
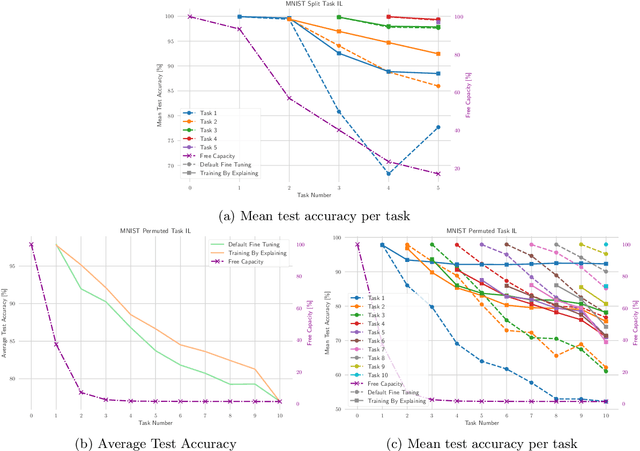
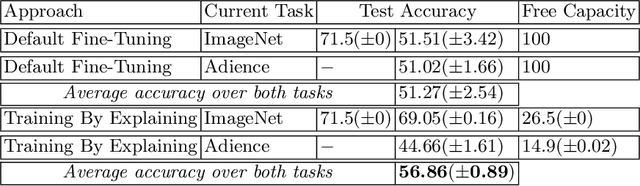
The ability to continuously process and retain new information like we do naturally as humans is a feat that is highly sought after when training neural networks. Unfortunately, the traditional optimization algorithms often require large amounts of data available during training time and updates wrt. new data are difficult after the training process has been completed. In fact, when new data or tasks arise, previous progress may be lost as neural networks are prone to catastrophic forgetting. Catastrophic forgetting describes the phenomenon when a neural network completely forgets previous knowledge when given new information. We propose a novel training algorithm called training by explaining in which we leverage Layer-wise Relevance Propagation in order to retain the information a neural network has already learned in previous tasks when training on new data. The method is evaluated on a range of benchmark datasets as well as more complex data. Our method not only successfully retains the knowledge of old tasks within the neural networks but does so more resource-efficiently than other state-of-the-art solutions.