 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Many Human Judgments Are Enough? Feasibility Limits of Human Preference Evaluation
Jan 15, 2026Human preference evaluations are widely used to compare generative models, yet it remains unclear how many judgments are required to reliably detect small improvements. We show that when preference signal is diffuse across prompts (i.e., all prompt types are similarly informative), proportional allocation is minimax-optimal: no allocation strategy substantially improves detectability. Empirical analysis of large-scale human preference datasets shows that most comparisons fall into this diffuse regime, exhibiting small preference margins that require far more judgments than typically collected, even in well-sampled comparisons. These limits persist across evaluation protocols and modalities, including chat, image generation, and code generation with execution feedback. In contrast, curated benchmarks that reduce prompt induced variability systematically induce larger margins and improve detectability through a $1.5\times$ reduction in prompt-level variance. Our results show that inconclusive or negative human evaluation outcomes frequently reflect underpowered evaluation rather than model equivalence, underscoring the need to account explicitly for effect size, budget, and protocol design.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024



Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Evolving Label Usage within Generation Z when Self-Describing Sexual Orientation
Aug 29, 2022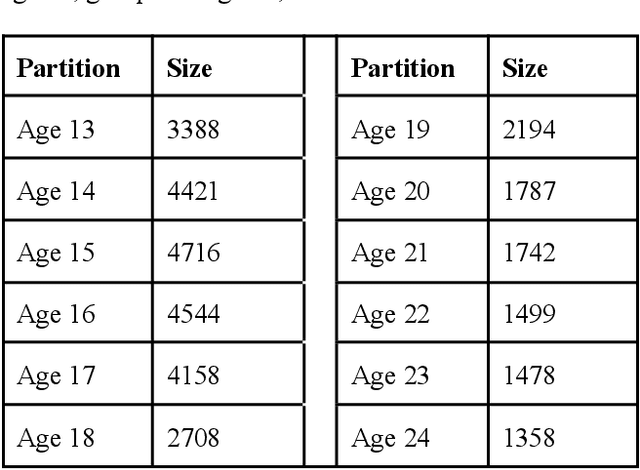
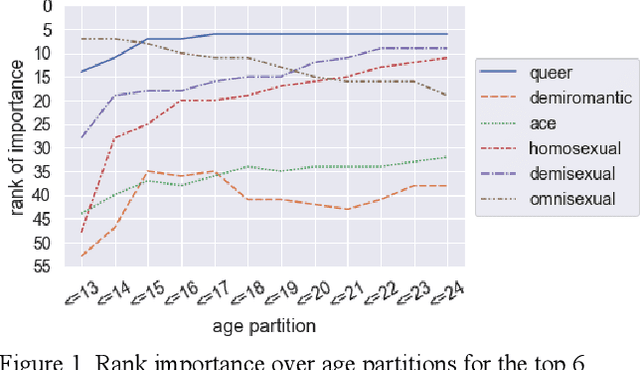
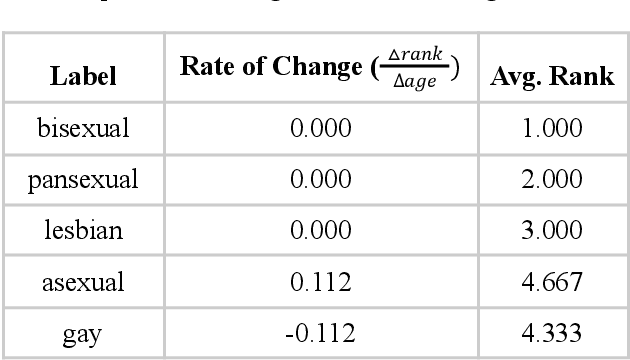
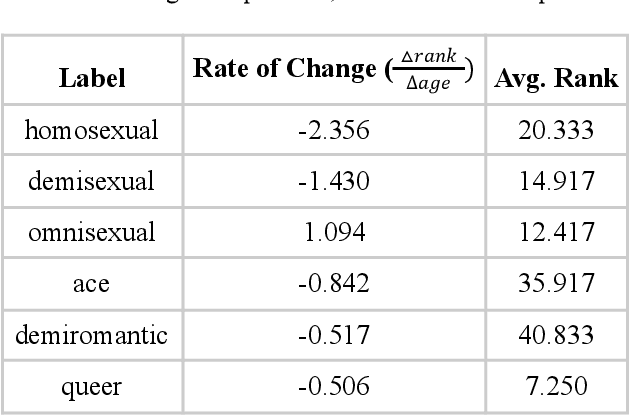
Evaluating change in ranked term importance in a growing corpus is a powerful tool for understanding changes in vocabulary usage. In this paper, we analyze a corpus of free-response answers where 33,993 LGBTQ Generation Z respondents from age 13 to 24 in the United States are asked to self-describe their sexual orientation. We observe that certain labels, such as bisexual, pansexual, and lesbian, remain equally important across age groups. The importance of other labels, such as homosexual, demisexual, and omnisexual, evolve across age groups. Although Generation Z is often stereotyped as homogenous, we observe noticeably different label usage when self-describing sexual orientation within it. We urge that interested parties must routinely survey the most important sexual orientation labels to their target audience and refresh their materials (such as demographic surveys) to reflect the constantly evolving LGBTQ community and create an inclusive environment.
Between words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP
Dec 20, 2021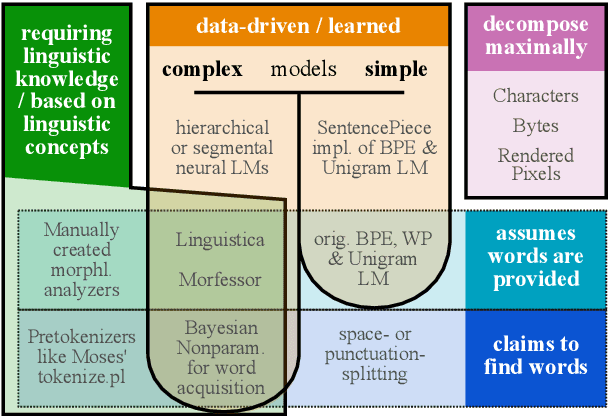
What are the units of text that we want to model? From bytes to multi-word expressions, text can be analyzed and generated at many granularities. Until recently, most natural language processing (NLP) models operated over words, treating those as discrete and atomic tokens, but starting with byte-pair encoding (BPE), subword-based approaches have become dominant in many areas, enabling small vocabularies while still allowing for fast inference. Is the end of the road character-level model or byte-level processing? In this survey, we connect several lines of work from the pre-neural and neural era, by showing how hybrid approaches of words and characters as well as subword-based approaches based on learned segmentation have been proposed and evaluated. We conclude that there is and likely will never be a silver bullet singular solution for all applications and that thinking seriously about tokenization remains important for many applications.