 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmile, be Happy :) Emoji Embedding for Visual Sentiment Analysis
Jul 14, 2019
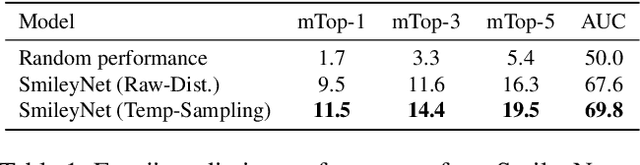
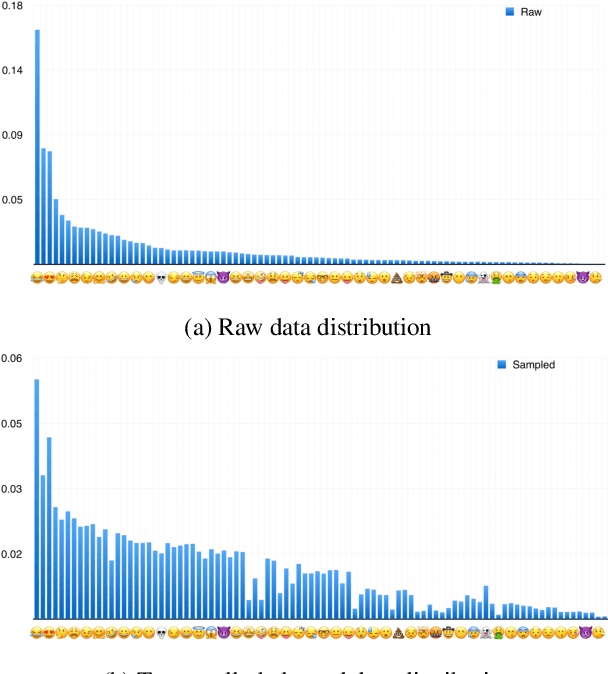
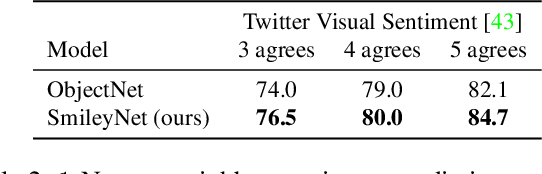
Due to the lack of large-scale datasets, the prevailing approach in visual sentiment analysis is to leverage models trained for object classification in large datasets like ImageNet. However, objects are sentiment neutral which hinders the expected gain of transfer learning for such tasks. In this work, we propose to overcome this problem by learning a novel sentiment-aligned image embedding that is better suited for subsequent visual sentiment analysis. Our embedding leverages the intricate relation between emojis and images in large-scale and readily available data from social media. Emojis are language-agnostic, consistent, and carry a clear sentiment signal which make them an excellent proxy to learn a sentiment aligned embedding. Hence, we construct a novel dataset of $4$ million images collected from Twitter with their associated emojis. We train a deep neural model for image embedding using emoji prediction task as a proxy. Our evaluation demonstrates that the proposed embedding outperforms the popular object-based counterpart consistently across several sentiment analysis benchmarks. Furthermore, without bell and whistles, our compact, effective and simple embedding outperforms the more elaborate and customized state-of-the-art deep models on these public benchmarks. Additionally, we introduce a novel emoji representation based on their visual emotional response which support a deeper understanding of the emoji modality and their usage on social media.
Frame Interpolation with Multi-Scale Deep Loss Functions and Generative Adversarial Networks
Nov 16, 2017

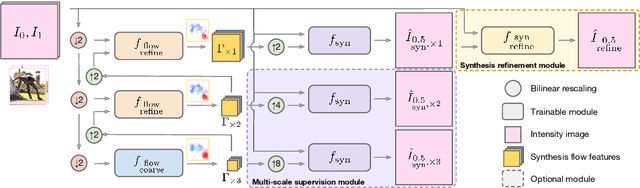
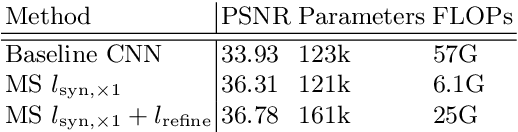
Frame interpolation attempts to synthesise intermediate frames given one or more consecutive video frames. In recent years, deep learning approaches, and in particular convolutional neural networks, have succeeded at tackling low- and high-level computer vision problems including frame interpolation. There are two main pursuits in this line of research, namely algorithm efficiency and reconstruction quality. In this paper, we present a multi-scale generative adversarial network for frame interpolation (FIGAN). To maximise the efficiency of our network, we propose a novel multi-scale residual estimation module where the predicted flow and synthesised frame are constructed in a coarse-to-fine fashion. To improve the quality of synthesised intermediate video frames, our network is jointly supervised at different levels with a perceptual loss function that consists of an adversarial and two content losses. We evaluate the proposed approach using a collection of 60fps videos from YouTube-8m. Our results improve the state-of-the-art accuracy and efficiency, and a subjective visual quality comparable to the best performing interpolation method.
Fast Face-swap Using Convolutional Neural Networks
Jul 27, 2017
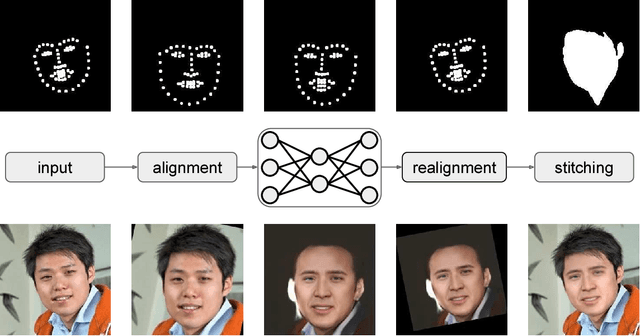
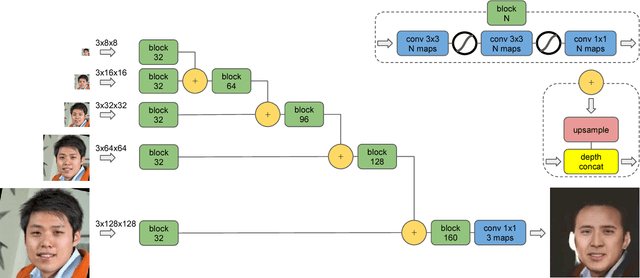
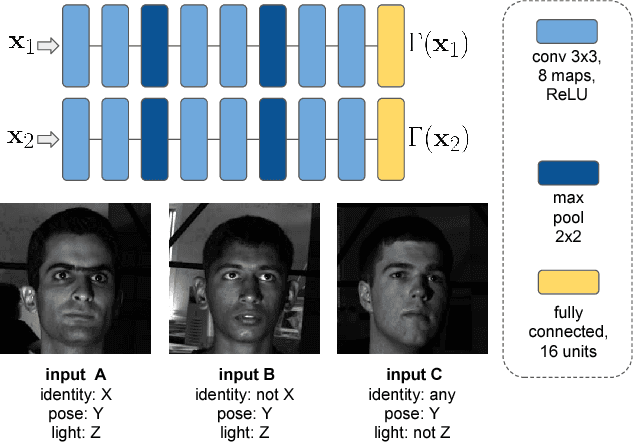
We consider the problem of face swapping in images, where an input identity is transformed into a target identity while preserving pose, facial expression, and lighting. To perform this mapping, we use convolutional neural networks trained to capture the appearance of the target identity from an unstructured collection of his/her photographs.This approach is enabled by framing the face swapping problem in terms of style transfer, where the goal is to render an image in the style of another one. Building on recent advances in this area, we devise a new loss function that enables the network to produce highly photorealistic results. By combining neural networks with simple pre- and post-processing steps, we aim at making face swap work in real-time with no input from the user.
Checkerboard artifact free sub-pixel convolution: A note on sub-pixel convolution, resize convolution and convolution resize
Jul 10, 2017
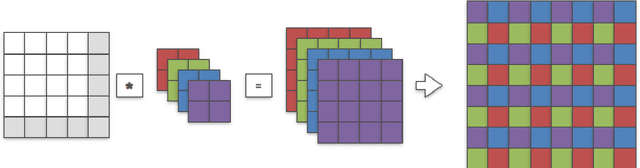
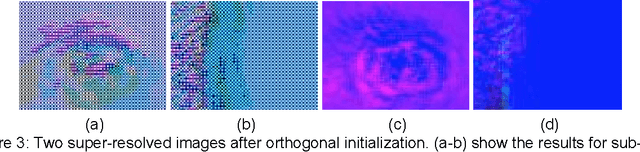
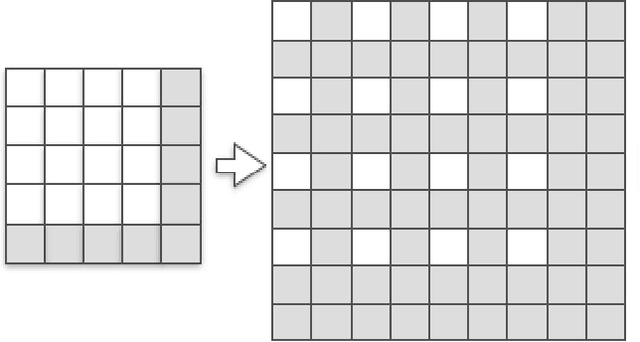
The most prominent problem associated with the deconvolution layer is the presence of checkerboard artifacts in output images and dense labels. To combat this problem, smoothness constraints, post processing and different architecture designs have been proposed. Odena et al. highlight three sources of checkerboard artifacts: deconvolution overlap, random initialization and loss functions. In this note, we proposed an initialization method for sub-pixel convolution known as convolution NN resize. Compared to sub-pixel convolution initialized with schemes designed for standard convolution kernels, it is free from checkerboard artifacts immediately after initialization. Compared to resize convolution, at the same computational complexity, it has more modelling power and converges to solutions with smaller test errors.
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
May 25, 2017
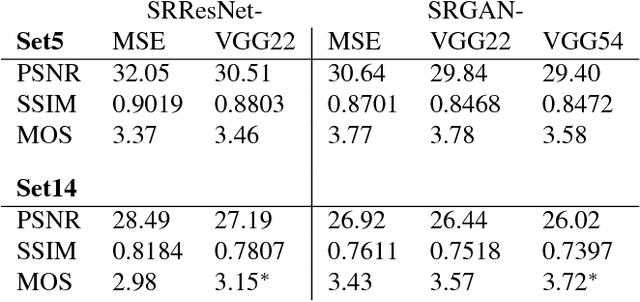

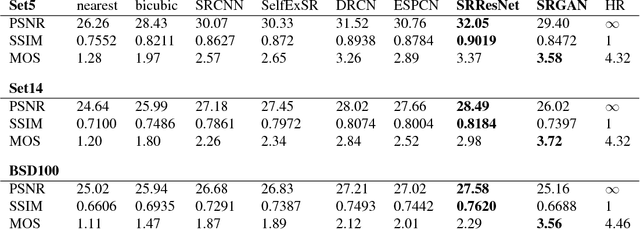
Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4x upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method.
Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation
Apr 10, 2017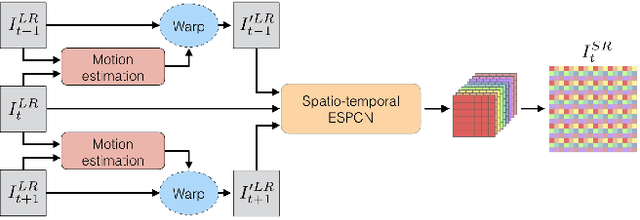

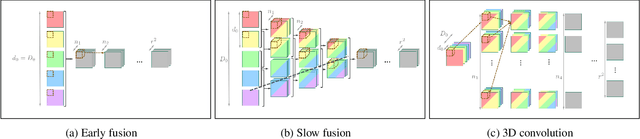
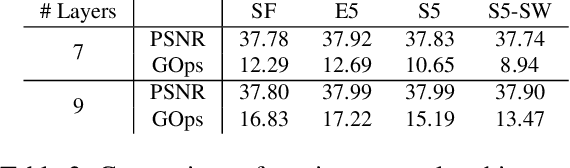
Convolutional neural networks have enabled accurate image super-resolution in real-time. However, recent attempts to benefit from temporal correlations in video super-resolution have been limited to naive or inefficient architectures. In this paper, we introduce spatio-temporal sub-pixel convolution networks that effectively exploit temporal redundancies and improve reconstruction accuracy while maintaining real-time speed. Specifically, we discuss the use of early fusion, slow fusion and 3D convolutions for the joint processing of multiple consecutive video frames. We also propose a novel joint motion compensation and video super-resolution algorithm that is orders of magnitude more efficient than competing methods, relying on a fast multi-resolution spatial transformer module that is end-to-end trainable. These contributions provide both higher accuracy and temporally more consistent videos, which we confirm qualitatively and quantitatively. Relative to single-frame models, spatio-temporal networks can either reduce the computational cost by 30% whilst maintaining the same quality or provide a 0.2dB gain for a similar computational cost. Results on publicly available datasets demonstrate that the proposed algorithms surpass current state-of-the-art performance in both accuracy and efficiency.
Lossy Image Compression with Compressive Autoencoders
Mar 01, 2017
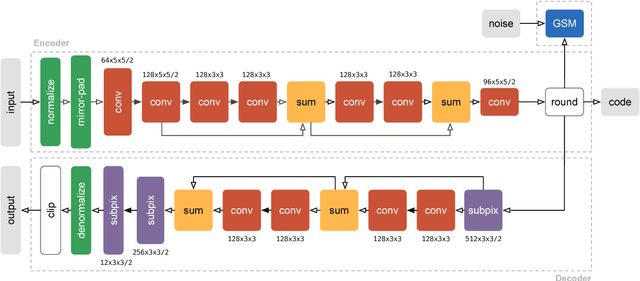
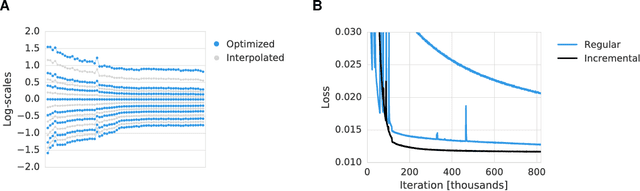
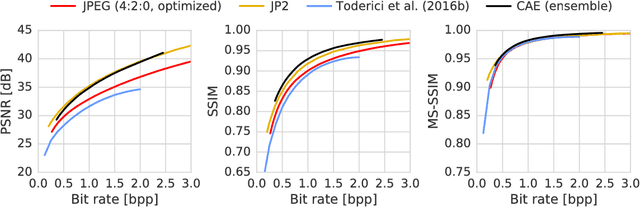
We propose a new approach to the problem of optimizing autoencoders for lossy image compression. New media formats, changing hardware technology, as well as diverse requirements and content types create a need for compression algorithms which are more flexible than existing codecs. Autoencoders have the potential to address this need, but are difficult to optimize directly due to the inherent non-differentiabilty of the compression loss. We here show that minimal changes to the loss are sufficient to train deep autoencoders competitive with JPEG 2000 and outperforming recently proposed approaches based on RNNs. Our network is furthermore computationally efficient thanks to a sub-pixel architecture, which makes it suitable for high-resolution images. This is in contrast to previous work on autoencoders for compression using coarser approximations, shallower architectures, computationally expensive methods, or focusing on small images.
Amortised MAP Inference for Image Super-resolution
Feb 21, 2017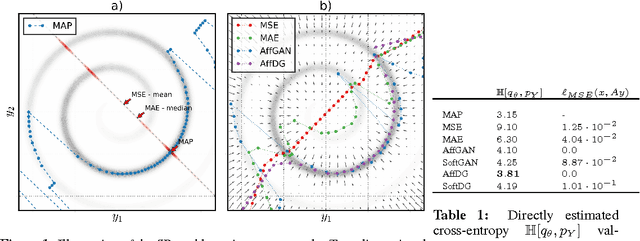
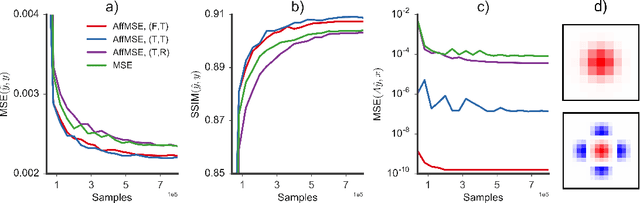


Image super-resolution (SR) is an underdetermined inverse problem, where a large number of plausible high-resolution images can explain the same downsampled image. Most current single image SR methods use empirical risk minimisation, often with a pixel-wise mean squared error (MSE) loss. However, the outputs from such methods tend to be blurry, over-smoothed and generally appear implausible. A more desirable approach would employ Maximum a Posteriori (MAP) inference, preferring solutions that always have a high probability under the image prior, and thus appear more plausible. Direct MAP estimation for SR is non-trivial, as it requires us to build a model for the image prior from samples. Furthermore, MAP inference is often performed via optimisation-based iterative algorithms which don't compare well with the efficiency of neural-network-based alternatives. Here we introduce new methods for amortised MAP inference whereby we calculate the MAP estimate directly using a convolutional neural network. We first introduce a novel neural network architecture that performs a projection to the affine subspace of valid SR solutions ensuring that the high resolution output of the network is always consistent with the low resolution input. We show that, using this architecture, the amortised MAP inference problem reduces to minimising the cross-entropy between two distributions, similar to training generative models. We propose three methods to solve this optimisation problem: (1) Generative Adversarial Networks (GAN) (2) denoiser-guided SR which backpropagates gradient-estimates from denoising to train the network, and (3) a baseline method using a maximum-likelihood-trained image prior. Our experiments show that the GAN based approach performs best on real image data. Lastly, we establish a connection between GANs and amortised variational inference as in e.g. variational autoencoders.
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
Sep 23, 2016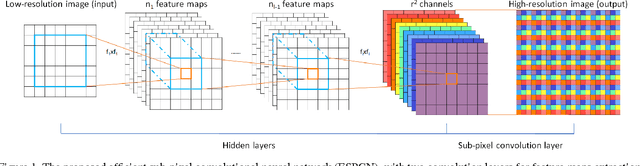

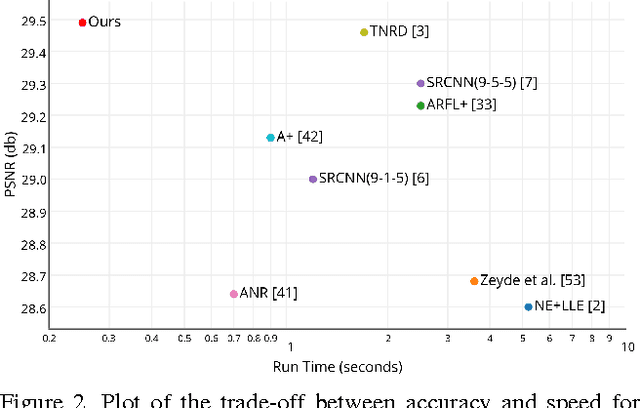
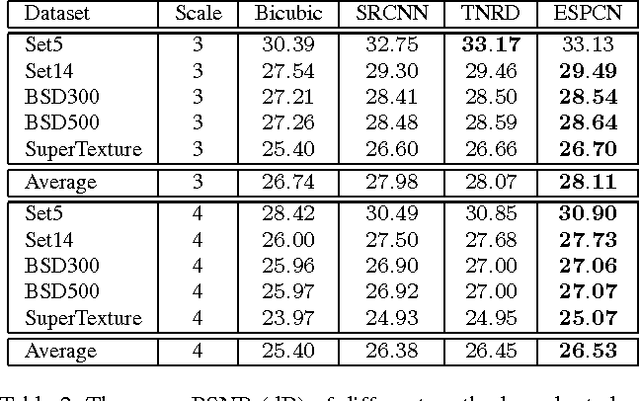
Recently, several models based on deep neural networks have achieved great success in terms of both reconstruction accuracy and computational performance for single image super-resolution. In these methods, the low resolution (LR) input image is upscaled to the high resolution (HR) space using a single filter, commonly bicubic interpolation, before reconstruction. This means that the super-resolution (SR) operation is performed in HR space. We demonstrate that this is sub-optimal and adds computational complexity. In this paper, we present the first convolutional neural network (CNN) capable of real-time SR of 1080p videos on a single K2 GPU. To achieve this, we propose a novel CNN architecture where the feature maps are extracted in the LR space. In addition, we introduce an efficient sub-pixel convolution layer which learns an array of upscaling filters to upscale the final LR feature maps into the HR output. By doing so, we effectively replace the handcrafted bicubic filter in the SR pipeline with more complex upscaling filters specifically trained for each feature map, whilst also reducing the computational complexity of the overall SR operation. We evaluate the proposed approach using images and videos from publicly available datasets and show that it performs significantly better (+0.15dB on Images and +0.39dB on Videos) and is an order of magnitude faster than previous CNN-based methods.
Is the deconvolution layer the same as a convolutional layer?
Sep 22, 2016In this note, we want to focus on aspects related to two questions most people asked us at CVPR about the network we presented. Firstly, What is the relationship between our proposed layer and the deconvolution layer? And secondly, why are convolutions in low-resolution (LR) space a better choice? These are key questions we tried to answer in the paper, but we were not able to go into as much depth and clarity as we would have liked in the space allowance. To better answer these questions in this note, we first discuss the relationships between the deconvolution layer in the forms of the transposed convolution layer, the sub-pixel convolutional layer and our efficient sub-pixel convolutional layer. We will refer to our efficient sub-pixel convolutional layer as a convolutional layer in LR space to distinguish it from the common sub-pixel convolutional layer. We will then show that for a fixed computational budget and complexity, a network with convolutions exclusively in LR space has more representation power at the same speed than a network that first upsamples the input in high resolution space.