 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering of Driving Encounter Scenarios Using Connected Vehicle Trajectories
Mar 16, 2019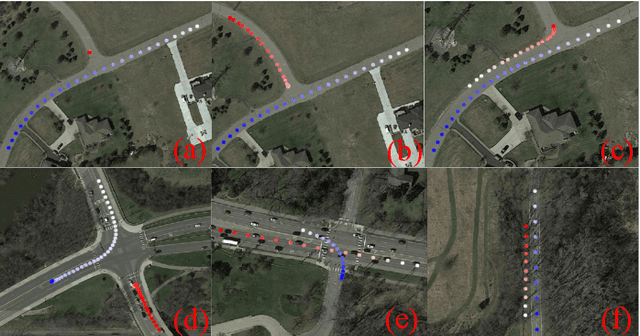
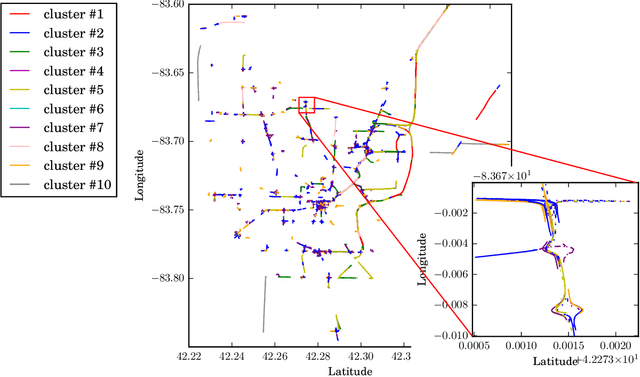
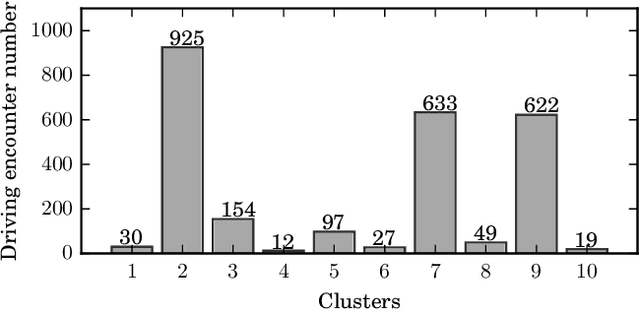
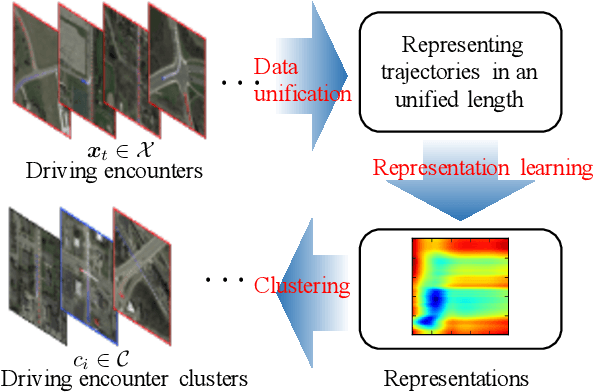
Multi-vehicle interaction behavior classification and analysis offer in-depth knowledge to make an efficient decision for autonomous vehicles. This paper aims to cluster a wide range of driving encounter scenarios based only on multi-vehicle GPS trajectories. Towards this end, we propose a generic unsupervised learning framework comprising two layers: feature representation layer and clustering layer. In the layer of feature representation, we combine the deep autoencoders with a distance-based measure to map the sequential observations of driving encounters into a computationally tractable space that allows quantifying the spatiotemporal interaction characteristics of two vehicles. The clustering algorithm is then applied to the extracted representations to gather homogeneous driving encounters into groups. Our proposed generic framework is then evaluated using 2,568 naturalistic driving encounters. Experimental results demonstrate that our proposed generic framework incorporated with unsupervised learning can cluster multi-trajectory data into distinct groups. These clustering results could benefit decision-making policy analysis and design for autonomous vehicles.
A New Multi-vehicle Trajectory Generator to Simulate Vehicle-to-Vehicle Encounters
Feb 24, 2019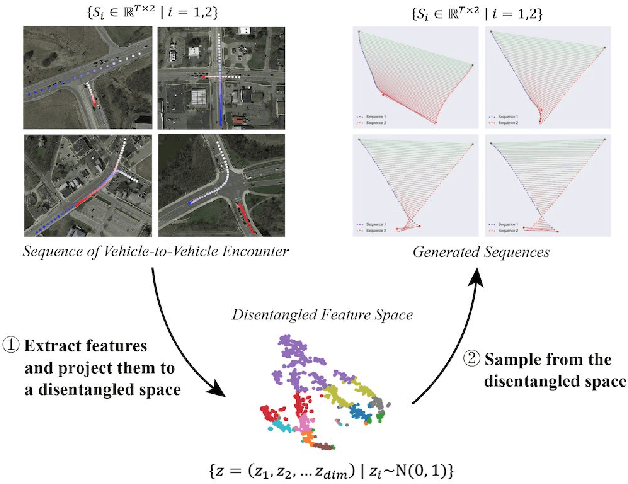
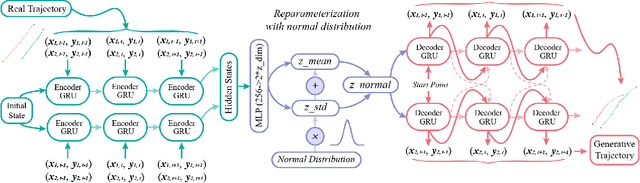
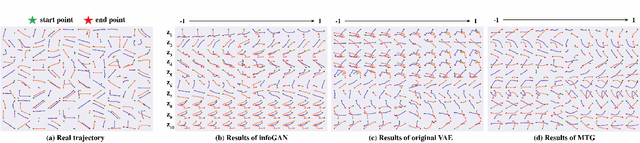
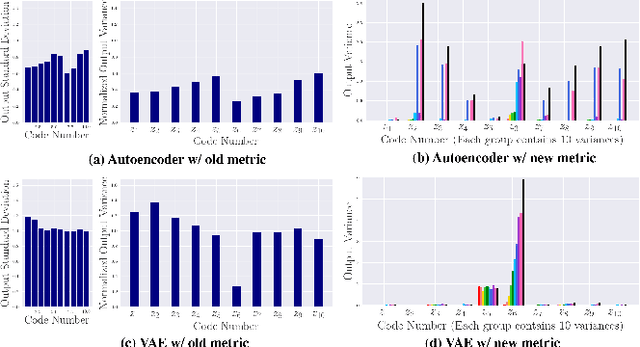
Generating multi-vehicle trajectories from existing limited data can provide rich resources for autonomous vehicle development and testing. This paper introduces a multi-vehicle trajectory generator (MTG) that can encode multi-vehicle interaction scenarios (called driving encounters) into an interpretable representation from which new driving encounter scenarios are generated by sampling. The MTG consists of a bi-directional encoder and a multi-branch decoder. A new disentanglement metric is then developed for model analyses and comparisons in terms of model robustness and the independence of the latent codes. Comparison of our proposed MTG with $\beta$-VAE and InfoGAN demonstrates that the MTG has stronger capability to purposely generate rational vehicle-to-vehicle encounters through operating the disentangled latent codes. Thus the MTG could provide more data for engineers and researchers to develop testing and evaluation scenarios for autonomous vehicles.
Understanding V2V Driving Scenarios through Traffic Primitives
Jul 27, 2018



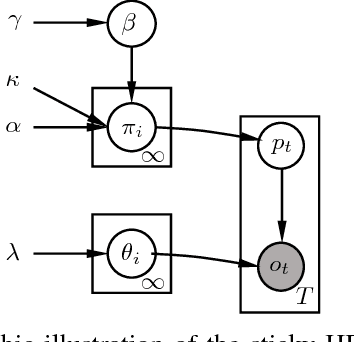
Semantically understanding complex drivers' encountering behavior, wherein two or multiple vehicles are spatially close to each other, does potentially benefit autonomous car's decision-making design. This paper presents a framework of analyzing various encountering behaviors through decomposing driving encounter data into small building blocks, called driving primitives, using nonparametric Bayesian learning (NPBL) approaches, which offers a flexible way to gain an insight into the complex driving encounters without any prerequisite knowledge. The effectiveness of our proposed primitive-based framework is validated based on 976 naturalistic driving encounters, from which more than 4000 driving primitives are learned using NPBL - a sticky HDP-HMM, combined a hidden Markov model (HMM) with a hierarchical Dirichlet process (HDP). After that, a dynamic time warping method integrated with k-means clustering is then developed to cluster all these extracted driving primitives into groups. Experimental results find that there exist 20 kinds of driving primitives capable of representing the basic components of driving encounters in our database. This primitive-based analysis methodology potentially reveals underlying information of vehicle-vehicle encounters for self-driving applications.
Cluster Naturalistic Driving Encounters Using Deep Unsupervised Learning
Jun 06, 2018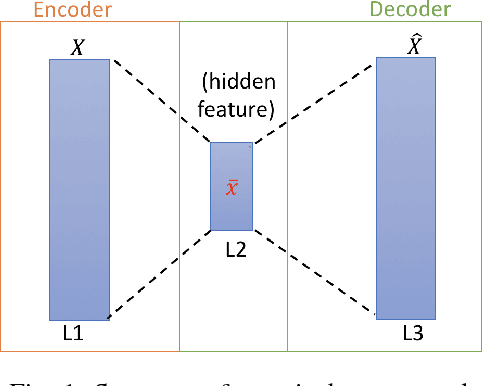
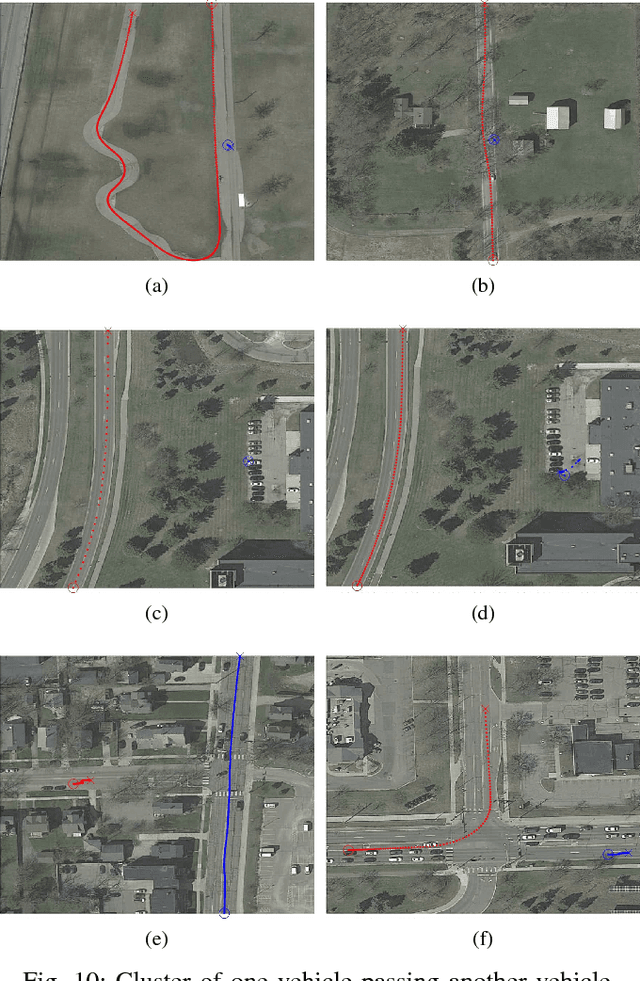
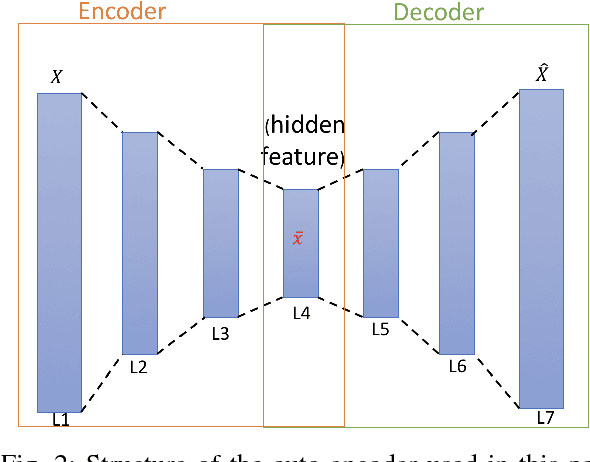
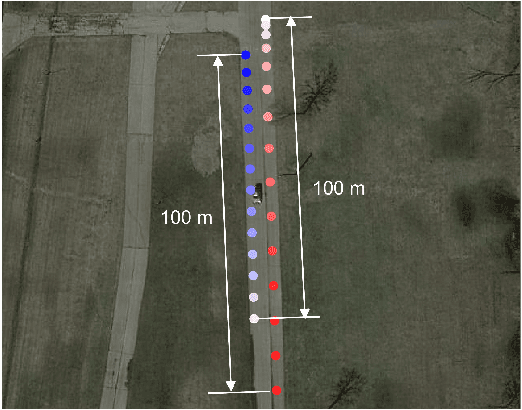
Learning knowledge from driving encounters could help self-driving cars make appropriate decisions when driving in complex settings with nearby vehicles engaged. This paper develops an unsupervised classifier to group naturalistic driving encounters into distinguishable clusters by combining an auto-encoder with k-means clustering (AE-kMC). The effectiveness of AE-kMC was validated using the data of 10,000 naturalistic driving encounters which were collected by the University of Michigan, Ann Arbor in the past five years. We compare our developed method with the $k$-means clustering methods and experimental results demonstrate that the AE-kMC method outperforms the original k-means clustering method.
Extracting Traffic Primitives Directly from Naturalistically Logged Data for Self-Driving Applications
May 26, 2018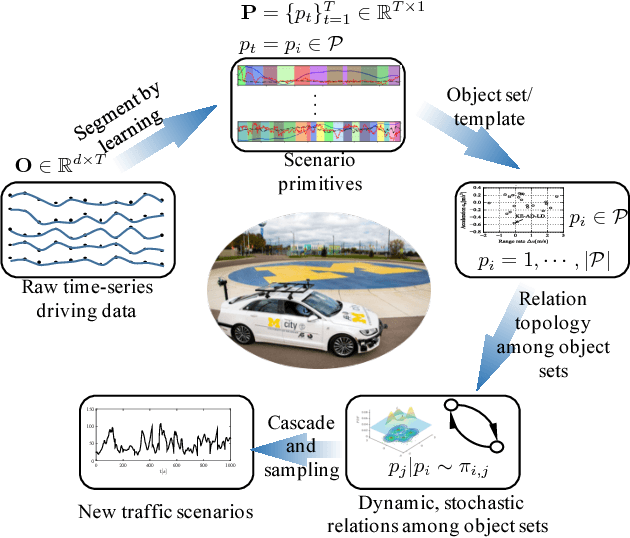
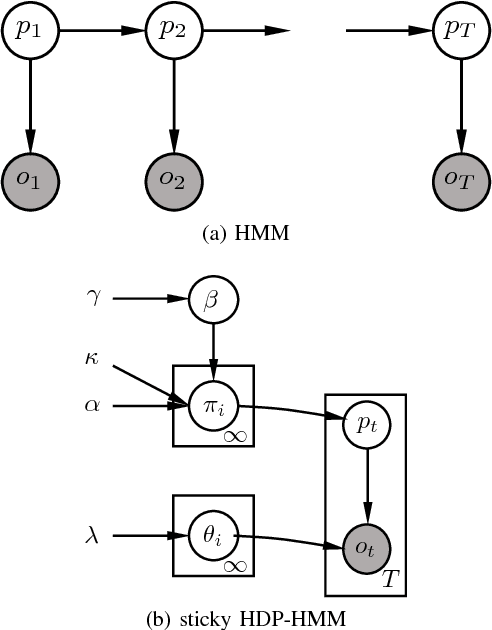

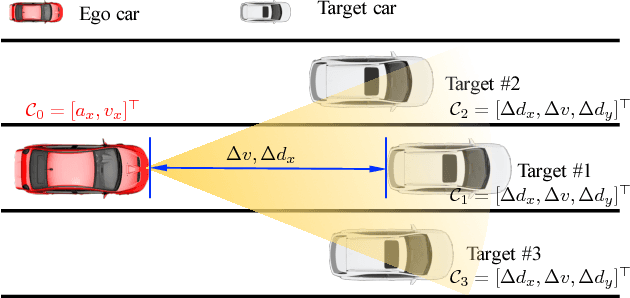
Developing an automated vehicle, that can handle complicated driving scenarios and appropriately interact with other road users, requires the ability to semantically learn and understand driving environment, oftentimes, based on analyzing massive amounts of naturalistic driving data. An important paradigm that allows automated vehicles to both learn from human drivers and gain insights is understanding the principal compositions of the entire traffic, termed as traffic primitives. However, the exploding data growth presents a great challenge in extracting primitives from high-dimensional time-series traffic data with various types of road users engaged. Therefore, automatically extracting primitives is becoming one of the cost-efficient ways to help autonomous vehicles understand and predict the complex traffic scenarios. In addition, the extracted primitives from raw data should 1) be appropriate for automated driving applications and also 2) be easily used to generate new traffic scenarios. However, existing literature does not provide a method to automatically learn these primitives from large-scale traffic data. The contribution of this paper has two manifolds. The first one is that we proposed a new framework to generate new traffic scenarios from a handful of limited traffic data. The second one is that we introduce a nonparametric Bayesian learning method -- a sticky hierarchical Dirichlet process hidden Markov model -- to automatically extract primitives from multidimensional traffic data without prior knowledge of the primitive settings. The developed method is then validated using one day of naturalistic driving data. Experiment results show that the nonparametric Bayesian learning method is able to extract primitives from traffic scenarios where both the binary and continuous events coexist.
An Optimal LiDAR Configuration Approach for Self-Driving Cars
May 20, 2018
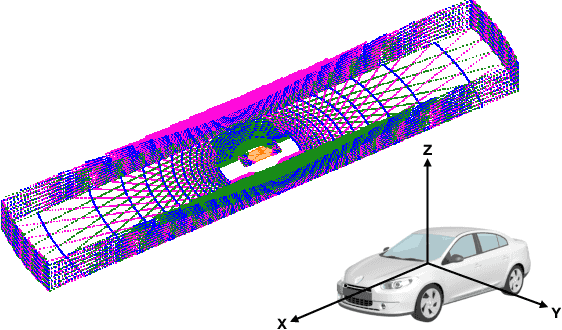
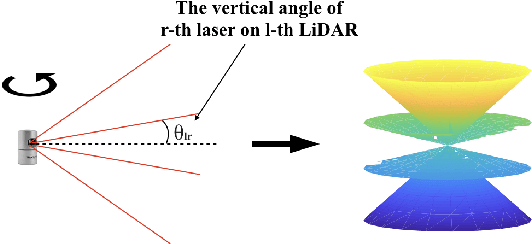
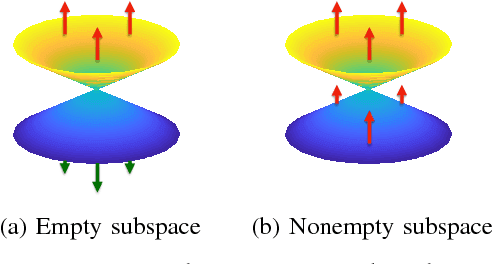
LiDARs plays an important role in self-driving cars and its configuration such as the location placement for each LiDAR can influence object detection performance. This paper aims to investigate an optimal configuration that maximizes the utility of on-hand LiDARs. First, a perception model of LiDAR is built based on its physical attributes. Then a generalized optimization model is developed to find the optimal configuration, including the pitch angle, roll angle, and position of LiDARs. In order to fix the optimization issue with off-the-shelf solvers, we proposed a lattice-based approach by segmenting the LiDAR's range of interest into finite subspaces, thus turning the optimal configuration into a nonlinear optimization problem. A cylinder-based method is also proposed to approximate the objective function, thereby making the nonlinear optimization problem solvable. A series of simulations are conducted to validate our proposed method. This proposed approach to optimal LiDAR configuration can provide a guideline to researchers to maximize the utility of LiDARs.
A Tempt to Unify Heterogeneous Driving Databases using Traffic Primitives
May 13, 2018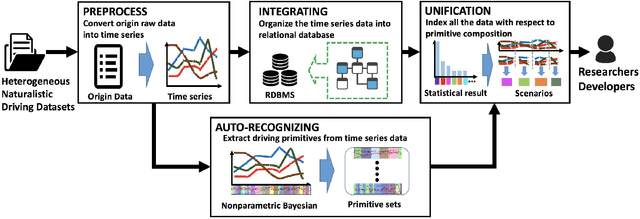
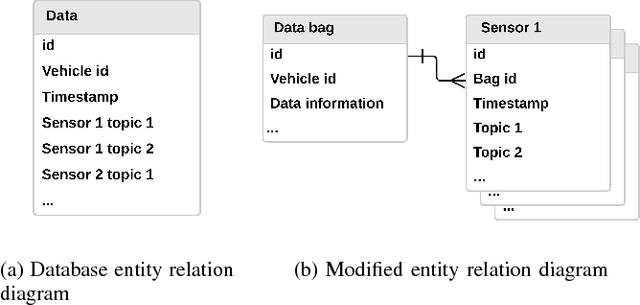
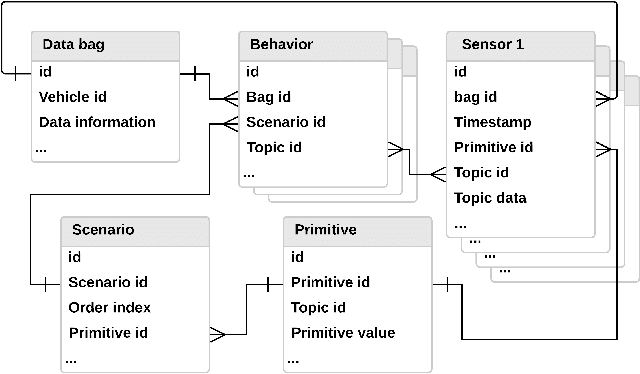
A multitude of publicly-available driving datasets and data platforms have been raised for autonomous vehicles (AV). However, the heterogeneities of databases in size, structure and driving context make existing datasets practically ineffective due to a lack of uniform frameworks and searchable indexes. In order to overcome these limitations on existing public datasets, this paper proposes a data unification framework based on traffic primitives with ability to automatically unify and label heterogeneous traffic data. This is achieved by two steps: 1) Carefully arrange raw multidimensional time series driving data into a relational database and then 2) automatically extract labeled and indexed traffic primitives from traffic data through a Bayesian nonparametric learning method. Finally, we evaluate the effectiveness of our developed framework using the collected real vehicle data.
Learning and Inferring a Driver's Braking Action in Car-Following Scenarios
Jan 11, 2018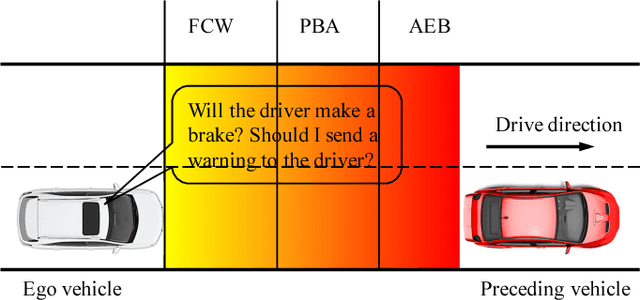
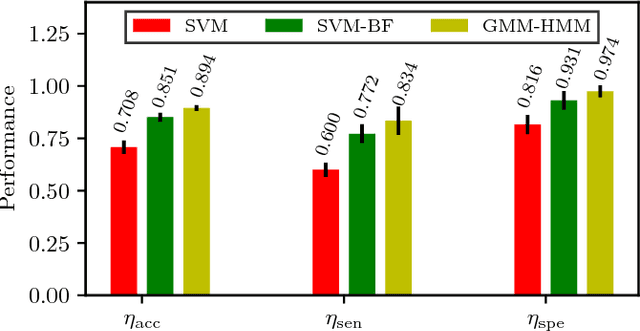
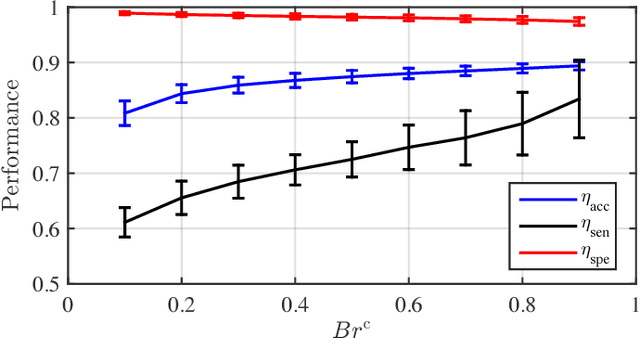
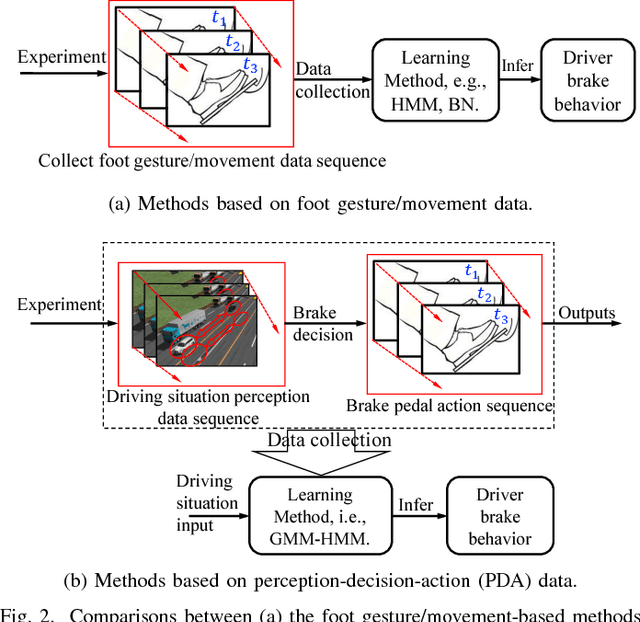
Accurately predicting and inferring a driver's decision to brake is critical for designing warning systems and avoiding collisions. In this paper we focus on predicting a driver's intent to brake in car-following scenarios from a perception-decision-action perspective according to his/her driving history. A learning-based inference method, using onboard data from CAN-Bus, radar and cameras as explanatory variables, is introduced to infer drivers' braking decisions by combining a Gaussian mixture model (GMM) with a hidden Markov model (HMM). The GMM is used to model stochastic relationships among variables, while the HMM is applied to infer drivers' braking actions based on the GMM. Real-case driving data from 49 drivers (more than three years' driving data per driver on average) have been collected from the University of Michigan Safety Pilot Model Deployment database. We compare the GMM-HMM method to a support vector machine (SVM) method and an SVM-Bayesian filtering method. The experimental results are evaluated by employing three performance metrics: accuracy, sensitivity, specificity. The comparison results show that the GMM-HMM obtains the best performance, with an accuracy of 90%, sensitivity of 84%, and specificity of 97%. Thus, we believe that this method has great potential for real-world active safety systems.
Driving Style Analysis Using Primitive Driving Patterns With Bayesian Nonparametric Approaches
Aug 16, 2017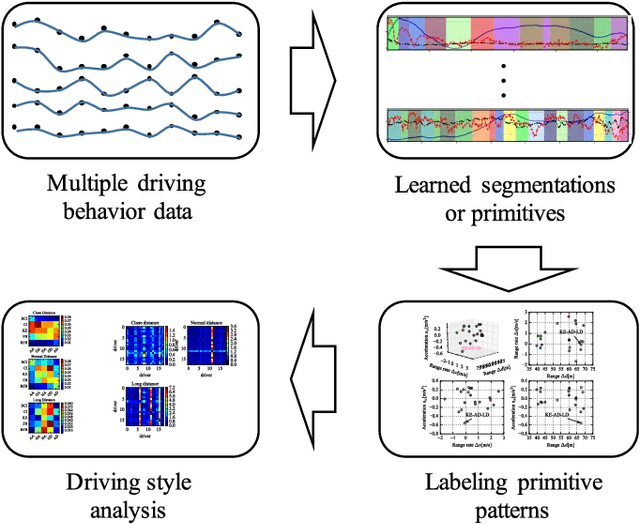
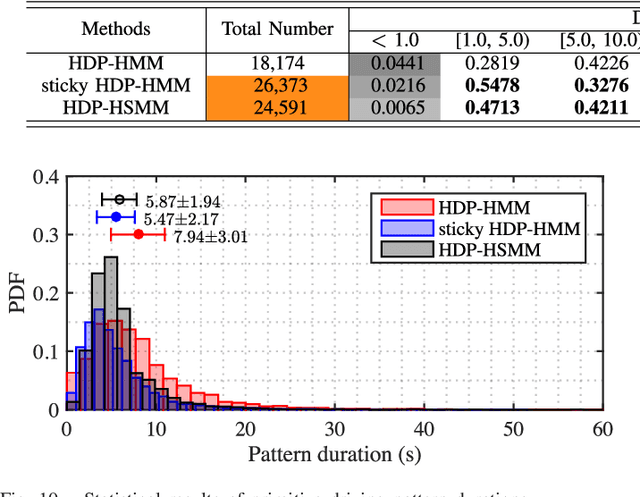
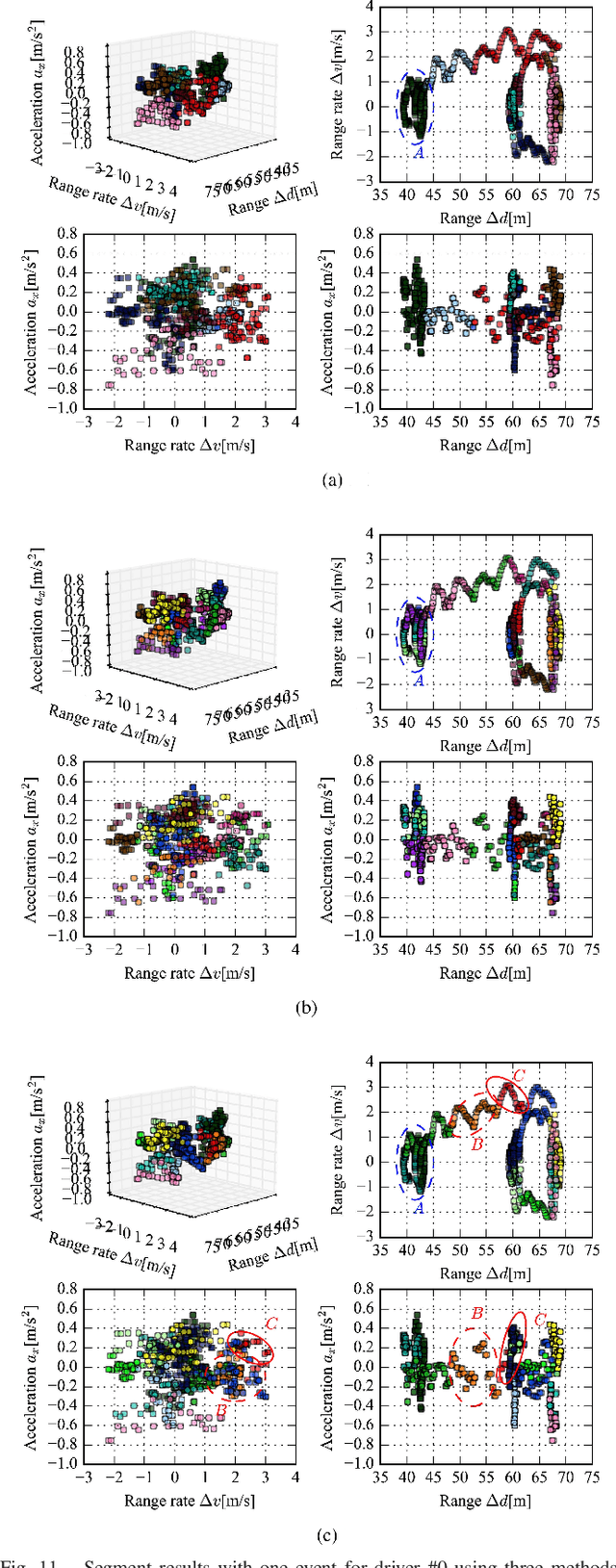
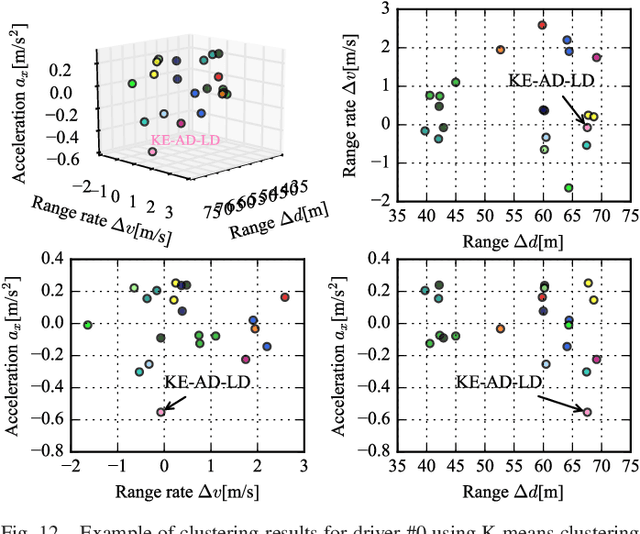
Analysis and recognition of driving styles are profoundly important to intelligent transportation and vehicle calibration. This paper presents a novel driving style analysis framework using the primitive driving patterns learned from naturalistic driving data. In order to achieve this, first, a Bayesian nonparametric learning method based on a hidden semi-Markov model (HSMM) is introduced to extract primitive driving patterns from time series driving data without prior knowledge of the number of these patterns. In the Bayesian nonparametric approach, we utilize a hierarchical Dirichlet process (HDP) instead of learning the unknown number of smooth dynamical modes of HSMM, thus generating the primitive driving patterns. Each primitive pattern is clustered and then labeled using behavioral semantics according to drivers' physical and psychological perception thresholds. For each driver, 75 primitive driving patterns in car-following scenarios are learned and semantically labeled. In order to show the HDP-HSMM's utility to learn primitive driving patterns, other two Bayesian nonparametric approaches, HDP-HMM and sticky HDP-HMM, are compared. The naturalistic driving data of 18 drivers were collected from the University of Michigan Safety Pilot Model Deployment (SPDM) database. The individual driving styles are discussed according to distribution characteristics of the learned primitive driving patterns and also the difference in driving styles among drivers are evaluated using the Kullback-Leibler divergence. The experiment results demonstrate that the proposed primitive pattern-based method can allow one to semantically understand driver behaviors and driving styles.
How Much Data is Enough? A Statistical Approach with Case Study on Longitudinal Driving Behavior
Jun 23, 2017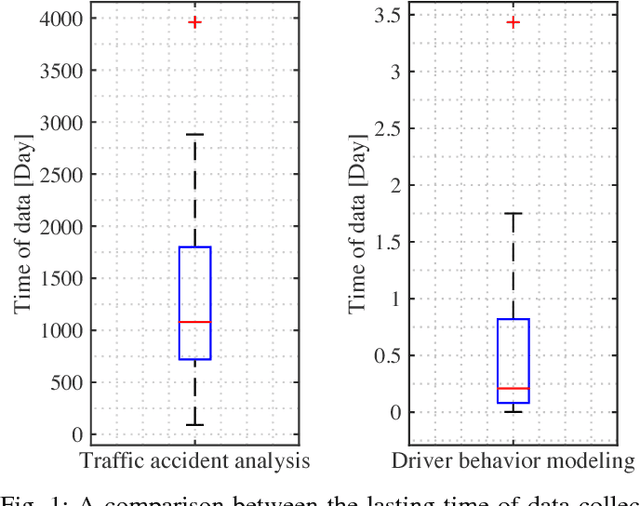
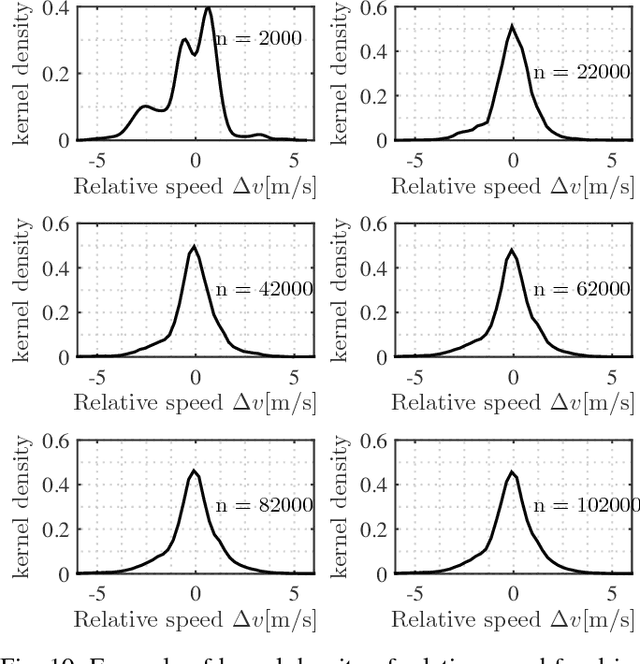
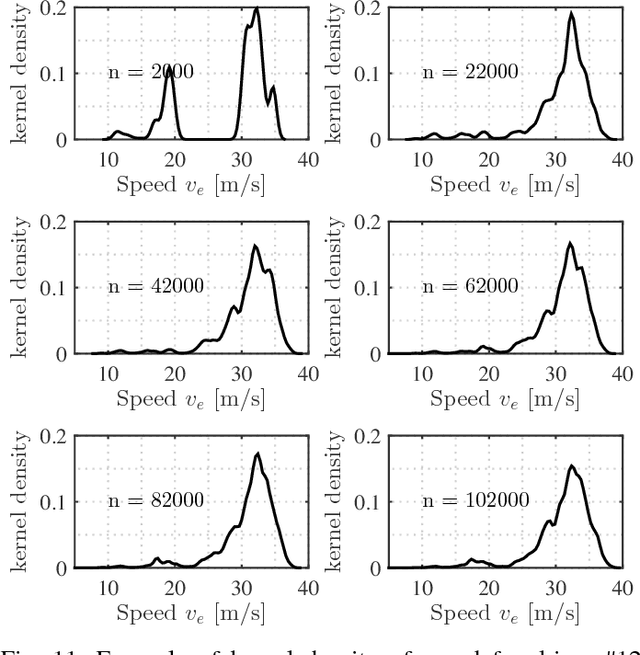

Big data has shown its uniquely powerful ability to reveal, model, and understand driver behaviors. The amount of data affects the experiment cost and conclusions in the analysis. Insufficient data may lead to inaccurate models while excessive data waste resources. For projects that cost millions of dollars, it is critical to determine the right amount of data needed. However, how to decide the appropriate amount has not been fully studied in the realm of driver behaviors. This paper systematically investigates this issue to estimate how much naturalistic driving data (NDD) is needed for understanding driver behaviors from a statistical point of view. A general assessment method is proposed using a Gaussian kernel density estimation to catch the underlying characteristics of driver behaviors. We then apply the Kullback-Liebler divergence method to measure the similarity between density functions with differing amounts of NDD. A max-minimum approach is used to compute the appropriate amount of NDD. To validate our proposed method, we investigated the car-following case using NDD collected from the University of Michigan Safety Pilot Model Deployment (SPMD) program. We demonstrate that from a statistical perspective, the proposed approach can provide an appropriate amount of NDD capable of capturing most features of the normal car-following behavior, which is consistent with the experiment settings in many literatures.