 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive pooling for Group Activity Recognition
Aug 31, 2022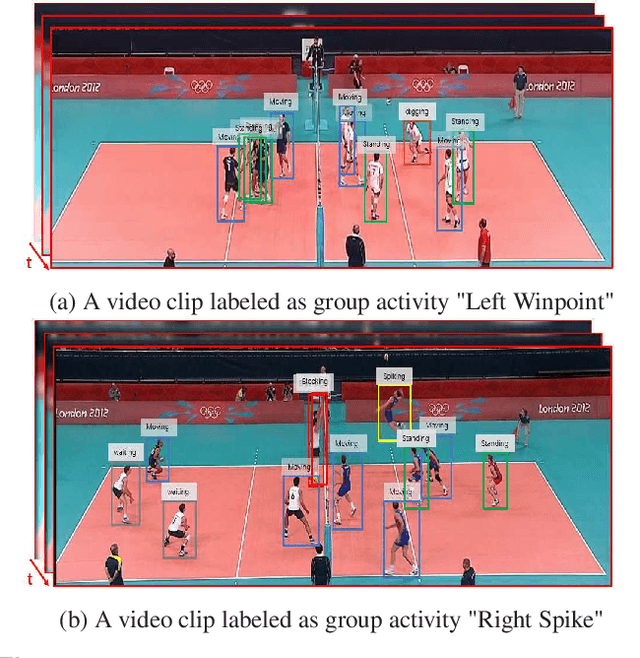

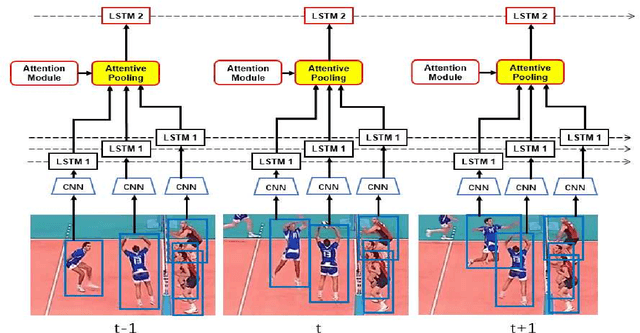
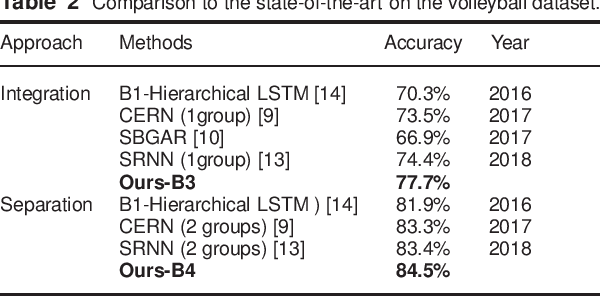
In group activity recognition, hierarchical framework is widely adopted to represent the relationships between individuals and their corresponding group, and has achieved promising performance. However, the existing methods simply employed max/average pooling in this framework, which ignored the distinct contributions of different individuals to the group activity recognition. In this paper, we propose a new contextual pooling scheme, named attentive pooling, which enables the weighted information transition from individual actions to group activity. By utilizing the attention mechanism, the attentive pooling is intrinsically interpretable and able to embed member context into the existing hierarchical model. In order to verify the effectiveness of the proposed scheme, two specific attentive pooling methods, i.e., global attentive pooling (GAP) and hierarchical attentive pooling (HAP) are designed. GAP rewards the individuals that are significant to group activity, while HAP further considers the hierarchical division by introducing subgroup structure. The experimental results on the benchmark dataset demonstrate that our proposal is significantly superior beyond the baseline and is comparable to the state-of-the-art methods.
Variational Distillation for Multi-View Learning
Jun 20, 2022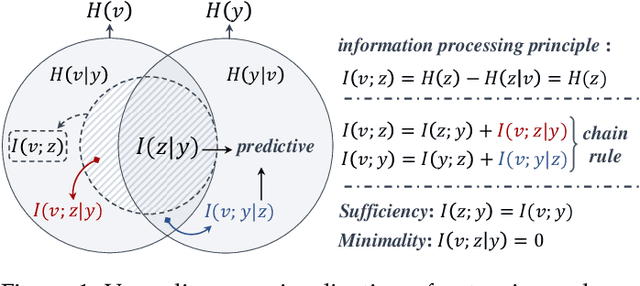
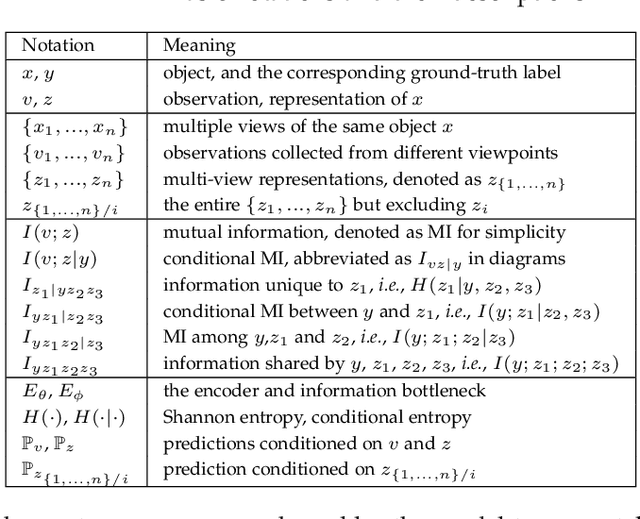
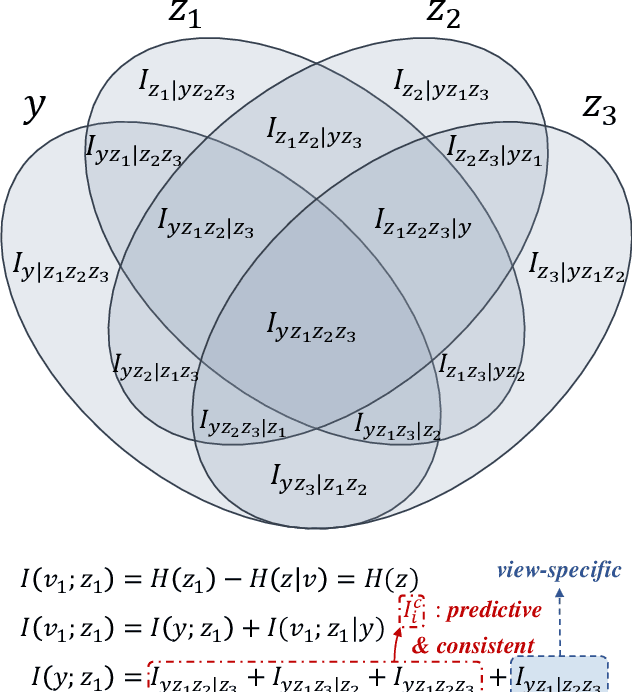
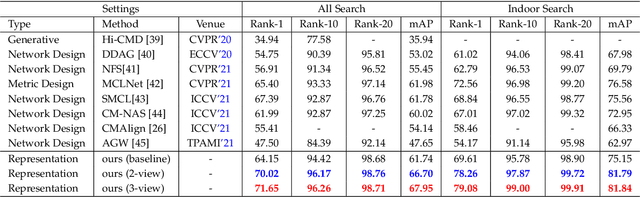
Information Bottleneck (IB) based multi-view learning provides an information theoretic principle for seeking shared information contained in heterogeneous data descriptions. However, its great success is generally attributed to estimate the multivariate mutual information which is intractable when the network becomes complicated. Moreover, the representation learning tradeoff, {\it i.e.}, prediction-compression and sufficiency-consistency tradeoff, makes the IB hard to satisfy both requirements simultaneously. In this paper, we design several variational information bottlenecks to exploit two key characteristics ({\it i.e.}, sufficiency and consistency) for multi-view representation learning. Specifically, we propose a Multi-View Variational Distillation (MV$^2$D) strategy to provide a scalable, flexible and analytical solution to fitting MI by giving arbitrary input of viewpoints but without explicitly estimating it. Under rigorously theoretical guarantee, our approach enables IB to grasp the intrinsic correlation between observations and semantic labels, producing predictive and compact representations naturally. Also, our information-theoretic constraint can effectively neutralize the sensitivity to heterogeneous data by eliminating both task-irrelevant and view-specific information, preventing both tradeoffs in multiple view cases. To verify our theoretically grounded strategies, we apply our approaches to various benchmarks under three different applications. Extensive experiments to quantitatively and qualitatively demonstrate the effectiveness of our approach against state-of-the-art methods.
Deep Multi-view Semi-supervised Clustering with Sample Pairwise Constraints
Jun 10, 2022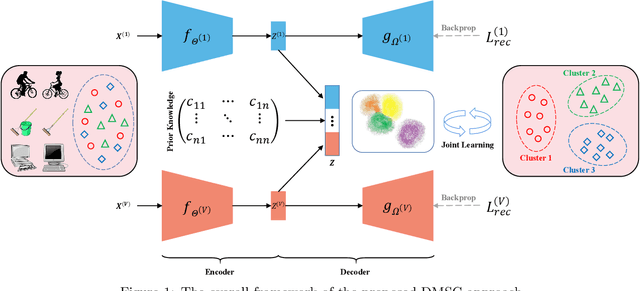


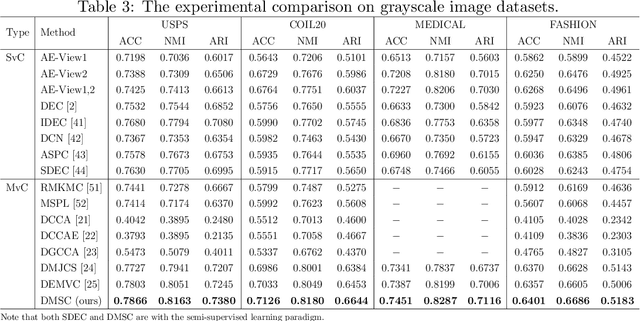
Multi-view clustering has attracted much attention thanks to the capacity of multi-source information integration. Although numerous advanced methods have been proposed in past decades, most of them generally overlook the significance of weakly-supervised information and fail to preserve the feature properties of multiple views, thus resulting in unsatisfactory clustering performance. To address these issues, in this paper, we propose a novel Deep Multi-view Semi-supervised Clustering (DMSC) method, which jointly optimizes three kinds of losses during networks finetuning, including multi-view clustering loss, semi-supervised pairwise constraint loss and multiple autoencoders reconstruction loss. Specifically, a KL divergence based multi-view clustering loss is imposed on the common representation of multi-view data to perform heterogeneous feature optimization, multi-view weighting and clustering prediction simultaneously. Then, we innovatively propose to integrate pairwise constraints into the process of multi-view clustering by enforcing the learned multi-view representation of must-link samples (cannot-link samples) to be similar (dissimilar), such that the formed clustering architecture can be more credible. Moreover, unlike existing rivals that only preserve the encoders for each heterogeneous branch during networks finetuning, we further propose to tune the intact autoencoders frame that contains both encoders and decoders. In this way, the issue of serious corruption of view-specific and view-shared feature space could be alleviated, making the whole training procedure more stable. Through comprehensive experiments on eight popular image datasets, we demonstrate that our proposed approach performs better than the state-of-the-art multi-view and single-view competitors.
Improving Fraud Detection via Hierarchical Attention-based Graph Neural Network
Feb 21, 2022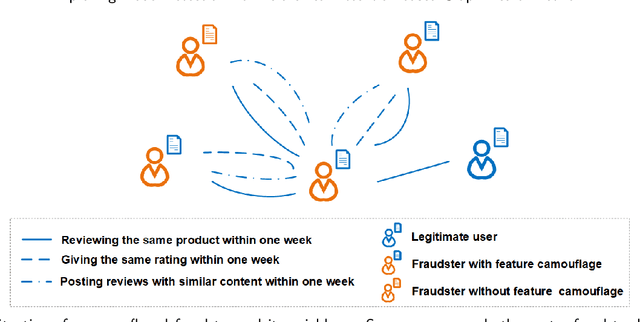
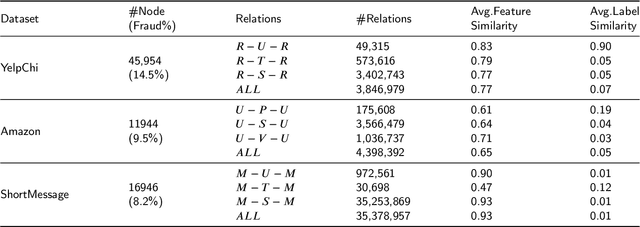
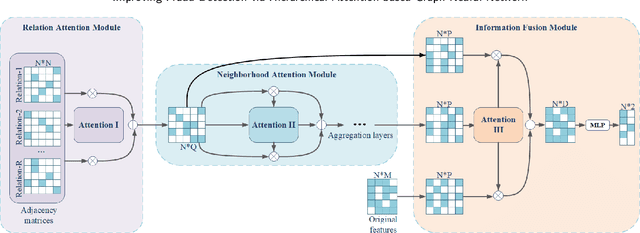
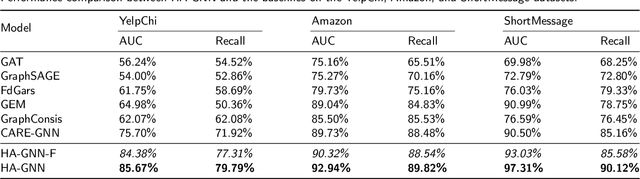
Graph neural networks (GNN) have emerged as a powerful tool for fraud detection tasks, where fraudulent nodes are identified by aggregating neighbor information via different relations. To get around such detection, crafty fraudsters resort to camouflage via connecting to legitimate users (i.e., relation camouflage) or providing seemingly legitimate feedbacks (i.e., feature camouflage). A wide-spread solution reinforces the GNN aggregation process with neighbor selectors according to original node features. This method may carry limitations when identifying fraudsters not only with the relation camouflage, but with the feature camouflage making them hard to distinguish from their legitimate neighbors. In this paper, we propose a Hierarchical Attention-based Graph Neural Network (HA-GNN) for fraud detection, which incorporates weighted adjacency matrices across different relations against camouflage. This is motivated in the Relational Density Theory and is exploited for forming a hierarchical attention-based graph neural network. Specifically, we design a relation attention module to reflect the tie strength between two nodes, while a neighborhood attention module to capture the long-range structural affinity associated with the graph. We generate node embeddings by aggregating information from local/long-range structures and original node features. Experiments on three real-world datasets demonstrate the effectiveness of our model over the state-of-the-arts.
Differentiable N-gram Objective on Abstractive Summarization
Feb 10, 2022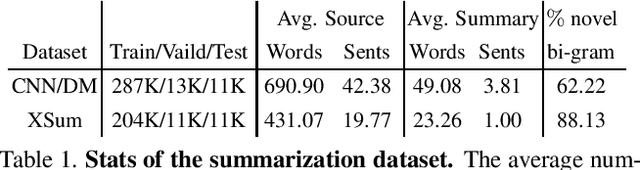
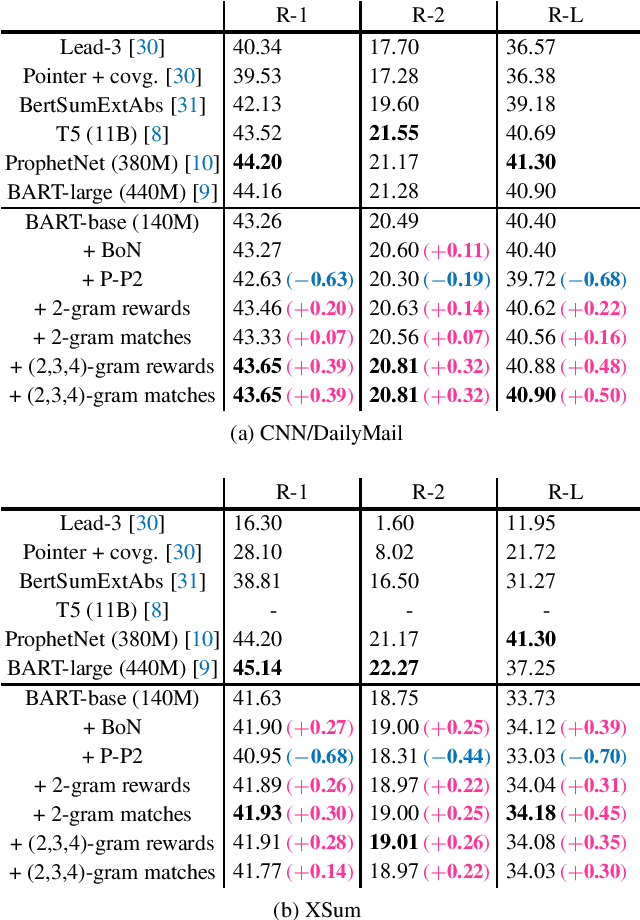
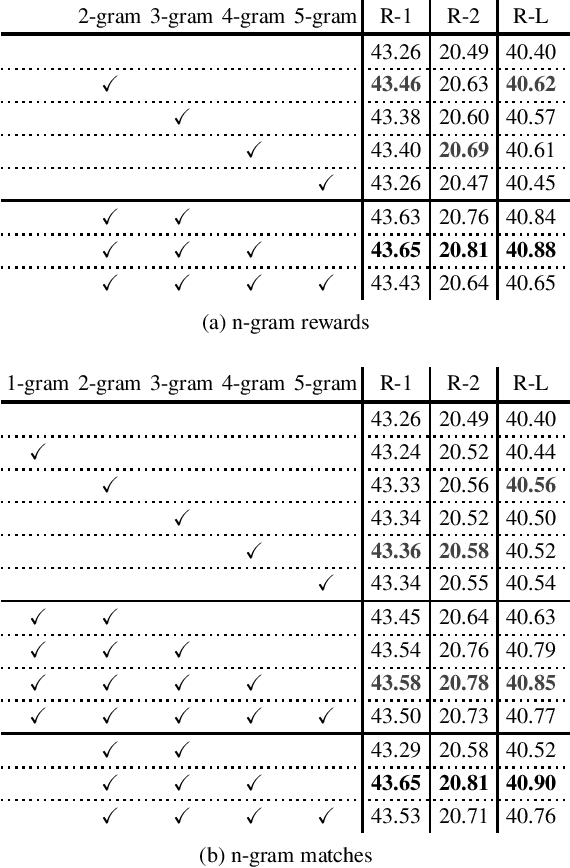
ROUGE is a standard automatic evaluation metric based on n-grams for sequence-to-sequence tasks, while cross-entropy loss is an essential objective of neural network language model that optimizes at a unigram level. We present differentiable n-gram objectives, attempting to alleviate the discrepancy between training criterion and evaluating criterion. The objective maximizes the probabilistic weight of matched sub-sequences, and the novelty of our work is the objective weights the matched sub-sequences equally and does not ceil the number of matched sub-sequences by the ground truth count of n-grams in reference sequence. We jointly optimize cross-entropy loss and the proposed objective, providing decent ROUGE score enhancement over abstractive summarization dataset CNN/DM and XSum, outperforming alternative n-gram objectives.
Learnable Faster Kernel-PCA for Nonlinear Fault Detection: Deep Autoencoder-Based Realization
Dec 08, 2021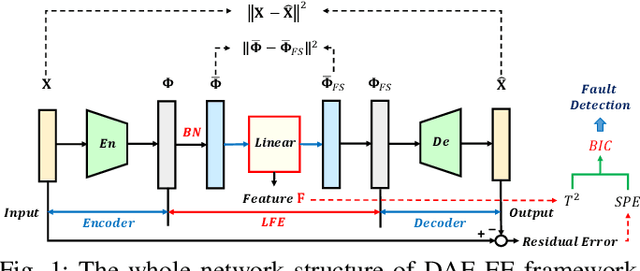
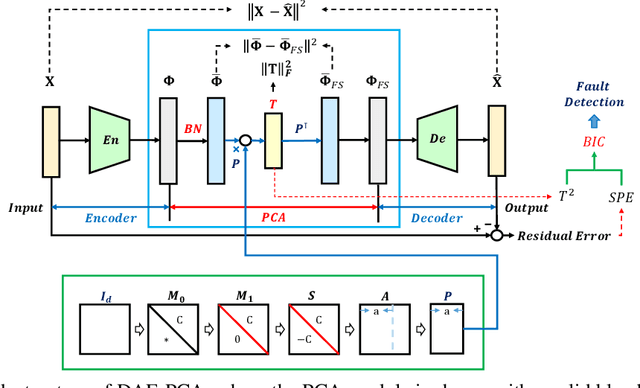
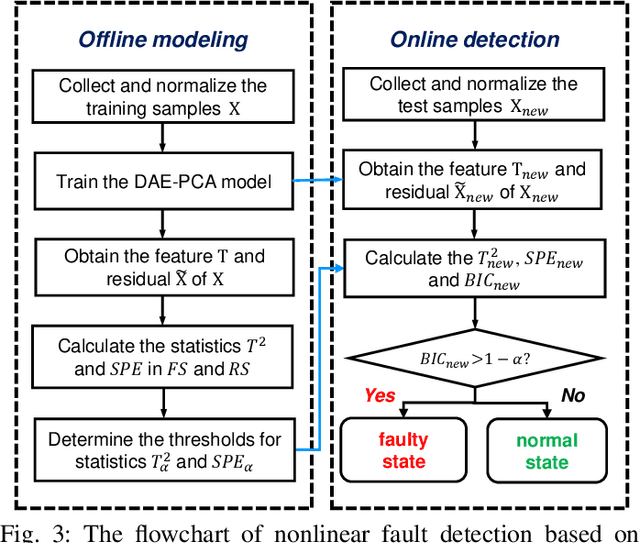
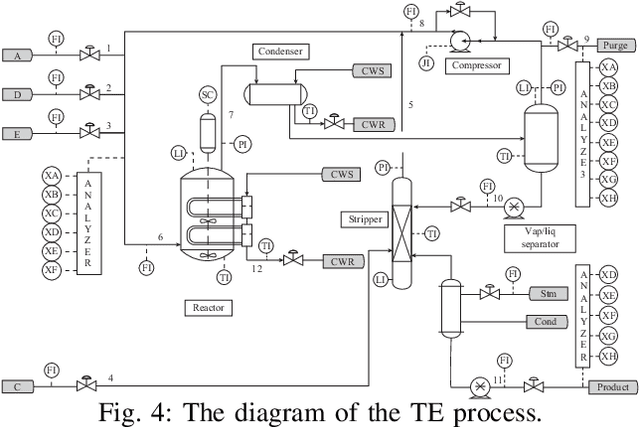
Kernel principal component analysis (KPCA) is a well-recognized nonlinear dimensionality reduction method that has been widely used in nonlinear fault detection tasks. As a kernel trick-based method, KPCA inherits two major problems. First, the form and the parameters of the kernel function are usually selected blindly, depending seriously on trial-and-error. As a result, there may be serious performance degradation in case of inappropriate selections. Second, at the online monitoring stage, KPCA has much computational burden and poor real-time performance, because the kernel method requires to leverage all the offline training data. In this work, to deal with the two drawbacks, a learnable faster realization of the conventional KPCA is proposed. The core idea is to parameterize all feasible kernel functions using the novel nonlinear DAE-FE (deep autoencoder based feature extraction) framework and propose DAE-PCA (deep autoencoder based principal component analysis) approach in detail. The proposed DAE-PCA method is proved to be equivalent to KPCA but has more advantage in terms of automatic searching of the most suitable nonlinear high-dimensional space according to the inputs. Furthermore, the online computational efficiency improves by approximately 100 times compared with the conventional KPCA. With the Tennessee Eastman (TE) process benchmark, the effectiveness and superiority of the proposed method is illustrated.
Multi-scale 2D Representation Learning for weakly-supervised moment retrieval
Nov 04, 2021
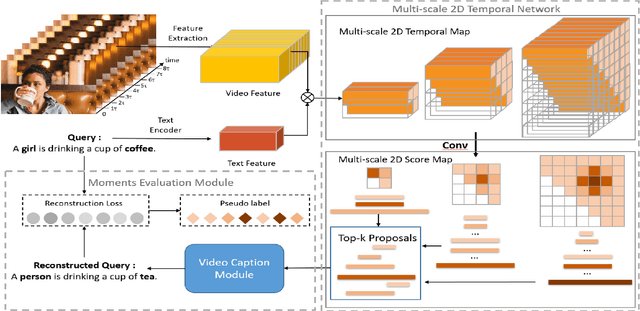
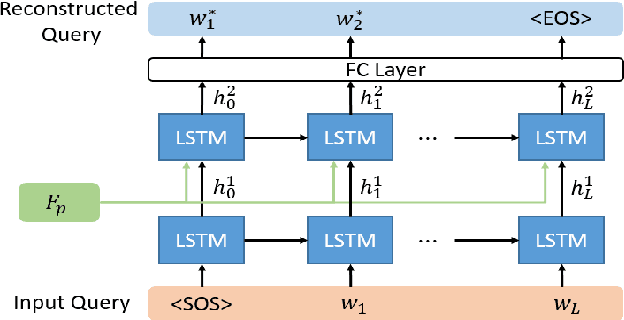

Video moment retrieval aims to search the moment most relevant to a given language query. However, most existing methods in this community often require temporal boundary annotations which are expensive and time-consuming to label. Hence weakly supervised methods have been put forward recently by only using coarse video-level label. Despite effectiveness, these methods usually process moment candidates independently, while ignoring a critical issue that the natural temporal dependencies between candidates in different temporal scales. To cope with this issue, we propose a Multi-scale 2D Representation Learning method for weakly supervised video moment retrieval. Specifically, we first construct a two-dimensional map for each temporal scale to capture the temporal dependencies between candidates. Two dimensions in this map indicate the start and end time points of these candidates. Then, we select top-K candidates from each scale-varied map with a learnable convolutional neural network. With a newly designed Moments Evaluation Module, we obtain the alignment scores of the selected candidates. At last, the similarity between captions and language query is served as supervision for further training the candidates' selector. Experiments on two benchmark datasets Charades-STA and ActivityNet Captions demonstrate that our approach achieves superior performance to state-of-the-art results.
Towards Book Cover Design via Layout Graphs
May 24, 2021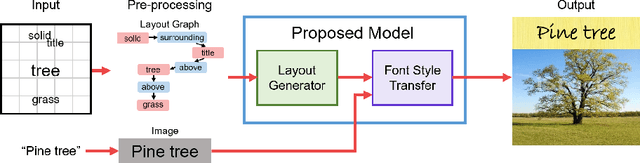
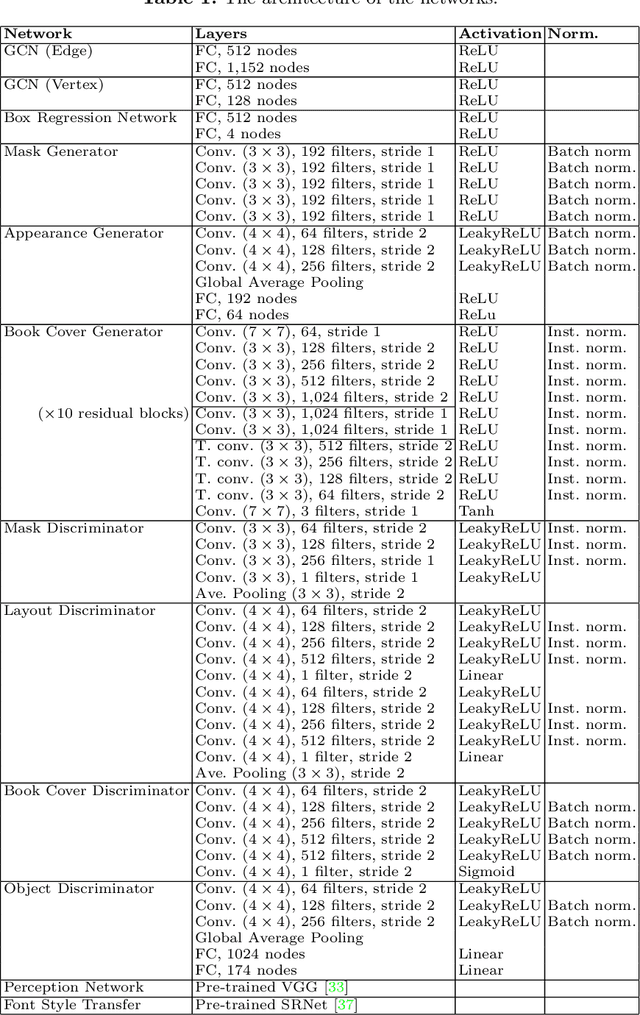
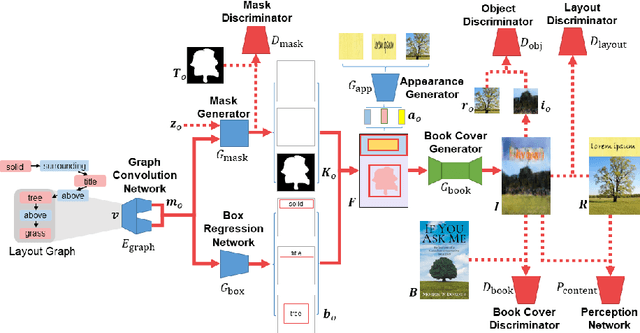
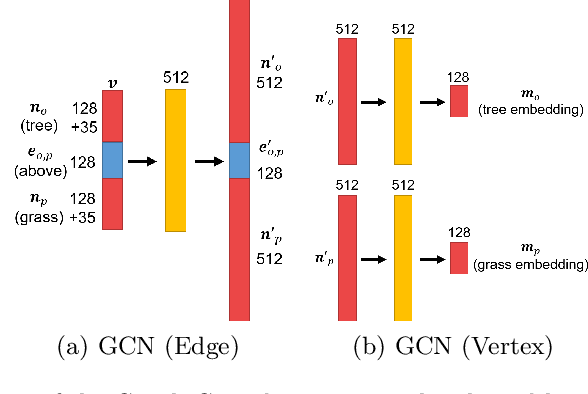
Book covers are intentionally designed and provide an introduction to a book. However, they typically require professional skills to design and produce the cover images. Thus, we propose a generative neural network that can produce book covers based on an easy-to-use layout graph. The layout graph contains objects such as text, natural scene objects, and solid color spaces. This layout graph is embedded using a graph convolutional neural network and then used with a mask proposal generator and a bounding-box generator and filled using an object proposal generator. Next, the objects are compiled into a single image and the entire network is trained using a combination of adversarial training, perceptual training, and reconstruction. Finally, a Style Retention Network (SRNet) is used to transfer the learned font style onto the desired text. Using the proposed method allows for easily controlled and unique book covers.
Solving the Travelling Thief Problem based on Item Selection Weight and Reverse Order Allocation
Dec 16, 2020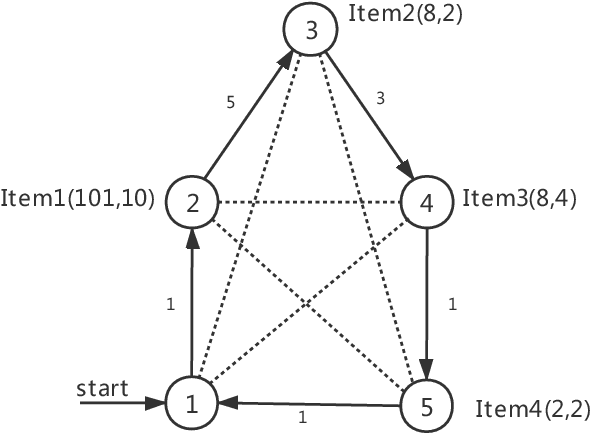
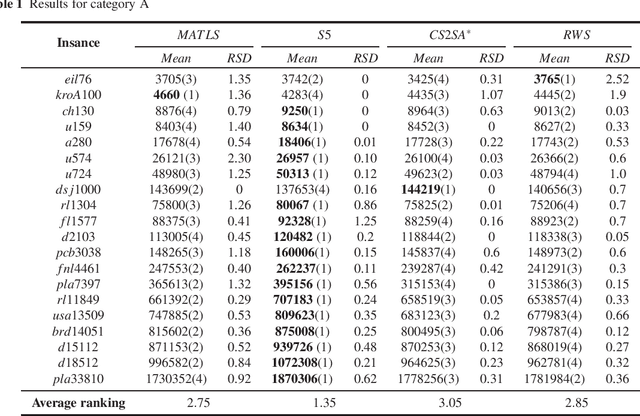
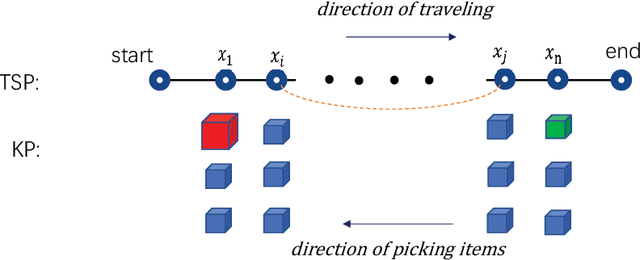
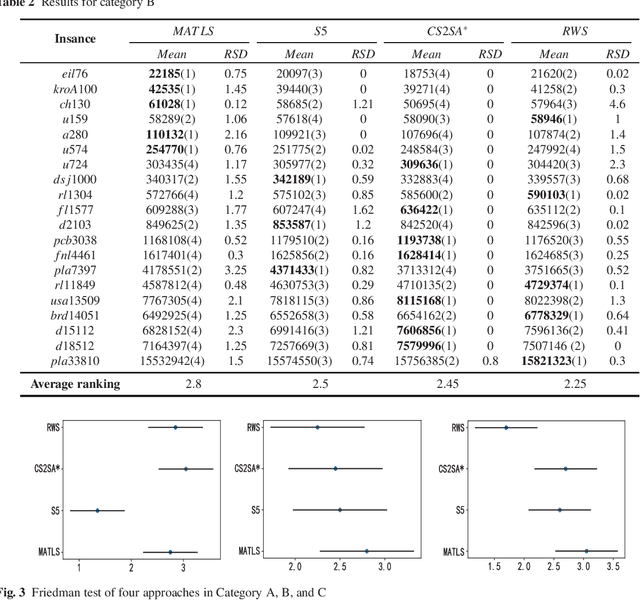
The Travelling Thief Problem (TTP) is a challenging combinatorial optimization problem that attracts many scholars. The TTP interconnects two well-known NP-hard problems: the Travelling Salesman Problem (TSP) and the 0-1 Knapsack Problem (KP). Increasingly algorithms have been proposed for solving this novel problem that combines two interdependent sub-problems. In this paper, TTP is investigated theoretically and empirically. An algorithm based on the score value calculated by our proposed formulation in picking items and sorting items in the reverse order in the light of the scoring value is proposed to solve the problem. Different approaches for solving the TTP are compared and analyzed; the experimental investigations suggest that our proposed approach is very efficient in meeting or beating current state-of-the-art heuristic solutions on a comprehensive set of benchmark TTP instances.
Robust Collaborative Learning of Patch-level and Image-level Annotations for Diabetic Retinopathy Grading from Fundus Image
Aug 03, 2020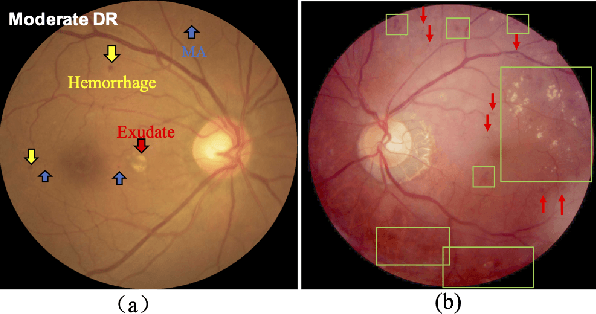
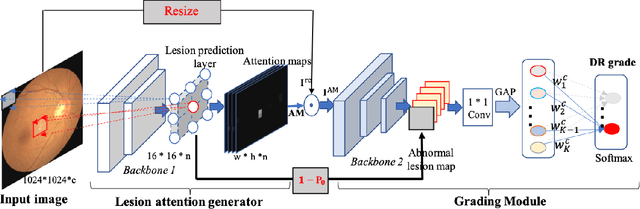
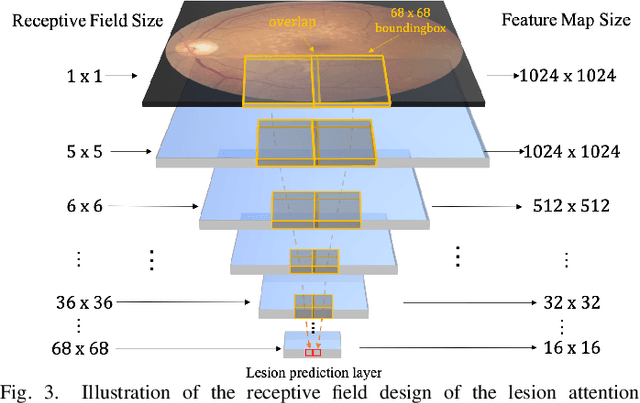
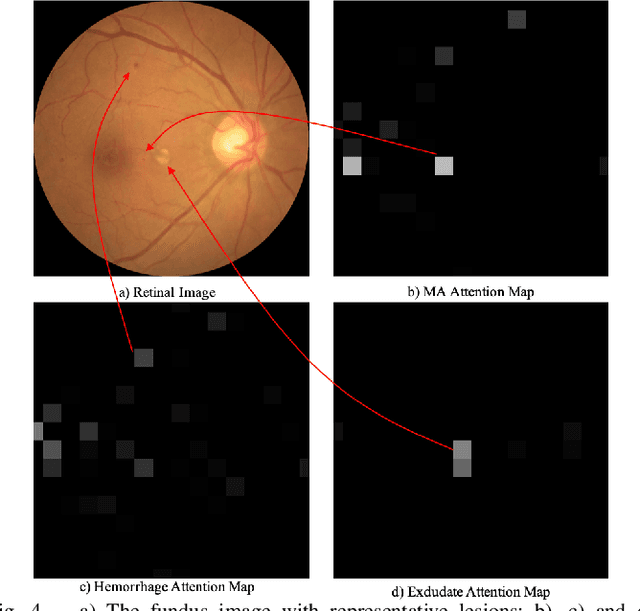
Currently, diabetic retinopathy (DR) grading from fundus images has attracted incremental interests in both academic and industrial communities. Most convolutional neural networks (CNNs) based algorithms treat DR grading as a classification task via image-level annotations. However, they have not fully explored the valuable information from the DR-related lesions. In this paper, we present a robust framework, which can collaboratively utilize both patch-level lesion and image-level grade annotations, for DR severity grading. By end-to-end optimizing the entire framework, the fine-grained lesion and image-level grade information can be bidirectionally exchanged to exploit more discriminative features for DR grading. Compared with the recent state-of-the-art algorithms and three over 9-years clinical experienced ophthalmologists, the proposed algorithm shows favorable performance. Testing on the datasets from totally different scenarios and distributions (such as label and camera), our algorithm is proved robust in facing image quality and distribution problems that commonly exist in real-world practice. Extensive ablation studies dissect the proposed framework and indicate the effectiveness and necessity of each motivation. The code and some valuable annotations are now publicly available.