 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN-Ensemble: Towards Random Decision Graph Neural Networks
Mar 20, 2023



Graph Neural Networks (GNNs) have enjoyed wide spread applications in graph-structured data. However, existing graph based applications commonly lack annotated data. GNNs are required to learn latent patterns from a limited amount of training data to perform inferences on a vast amount of test data. The increased complexity of GNNs, as well as a single point of model parameter initialization, usually lead to overfitting and sub-optimal performance. In addition, it is known that GNNs are vulnerable to adversarial attacks. In this paper, we push one step forward on the ensemble learning of GNNs with improved accuracy, generalization, and adversarial robustness. Following the principles of stochastic modeling, we propose a new method called GNN-Ensemble to construct an ensemble of random decision graph neural networks whose capacity can be arbitrarily expanded for improvement in performance. The essence of the method is to build multiple GNNs in randomly selected substructures in the topological space and subfeatures in the feature space, and then combine them for final decision making. These GNNs in different substructure and subfeature spaces generalize their classification in complementary ways. Consequently, their combined classification performance can be improved and overfitting on the training data can be effectively reduced. In the meantime, we show that GNN-Ensemble can significantly improve the adversarial robustness against attacks on GNNs.
Machine Learning for Synthetic Data Generation: a Review
Feb 08, 2023



Data plays a crucial role in machine learning. However, in real-world applications, there are several problems with data, e.g., data are of low quality; a limited number of data points lead to under-fitting of the machine learning model; it is hard to access the data due to privacy, safety and regulatory concerns. \textit{Synthetic data generation} offers a promising new avenue, as it can be shared and used in ways that real-world data cannot. This paper systematically reviews the existing works that leverage machine learning models for synthetic data generation. Specifically, we discuss the synthetic data generation works from several perspectives: (i) applications, including computer vision, speech, natural language, healthcare, and business; (ii) machine learning methods, particularly neural network architectures and deep generative models; (iii) privacy and fairness issue. In addition, we identify the challenges and opportunities in this emerging field and suggest future research directions.
EENet: Learning to Early Exit for Adaptive Inference
Jan 15, 2023Budgeted adaptive inference with early exits is an emerging technique to improve the computational efficiency of deep neural networks (DNNs) for edge AI applications with limited resources at test time. This method leverages the fact that different test data samples may not require the same amount of computation for a correct prediction. By allowing early exiting from full layers of DNN inference for some test examples, we can reduce latency and improve throughput of edge inference while preserving performance. Although there have been numerous studies on designing specialized DNN architectures for training early-exit enabled DNN models, most of the existing work employ hand-tuned or manual rule-based early exit policies. In this study, we introduce a novel multi-exit DNN inference framework, coined as EENet, which leverages multi-objective learning to optimize the early exit policy for a trained multi-exit DNN under a given inference budget. This paper makes two novel contributions. First, we introduce the concept of early exit utility scores by combining diverse confidence measures with class-wise prediction scores to better estimate the correctness of test-time predictions at a given exit. Second, we train a lightweight, budget-driven, multi-objective neural network over validation predictions to learn the exit assignment scheduling for query examples at test time. The EENet early exit scheduler optimizes both the distribution of test samples to different exits and the selection of the exit utility thresholds such that the given inference budget is satisfied while the performance metric is maximized. Extensive experiments are conducted on five benchmarks, including three image datasets (CIFAR-10, CIFAR-100, ImageNet) and two NLP datasets (SST-2, AgNews). The results demonstrate the performance improvements of EENet compared to existing representative early exit techniques.
Gradient Leakage Attack Resilient Deep Learning
Dec 25, 2021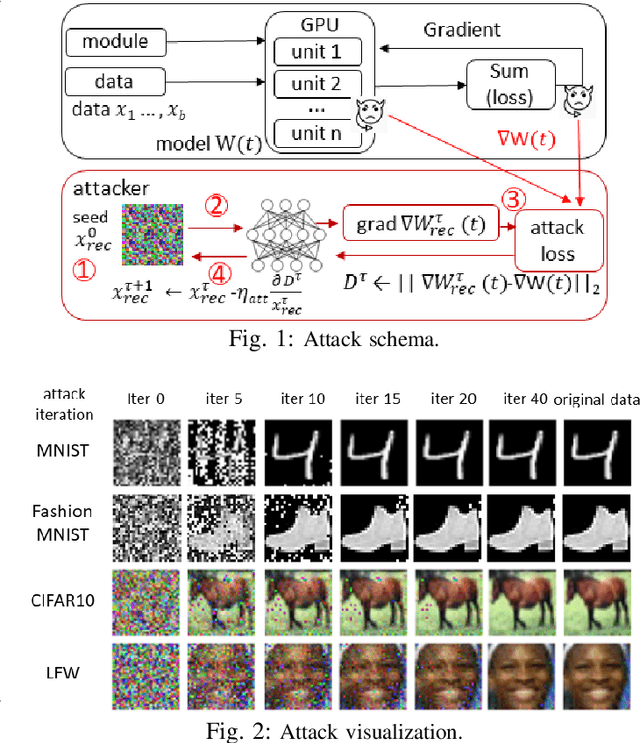

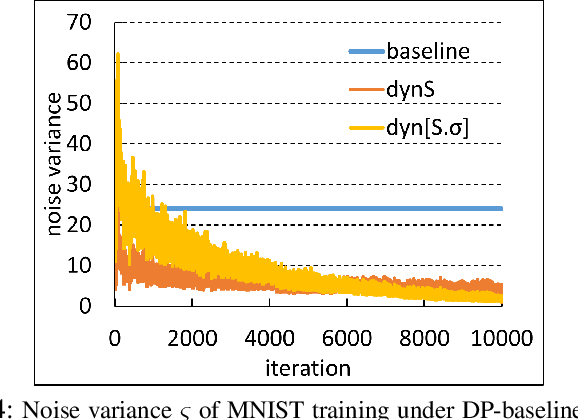

Gradient leakage attacks are considered one of the wickedest privacy threats in deep learning as attackers covertly spy gradient updates during iterative training without compromising model training quality, and yet secretly reconstruct sensitive training data using leaked gradients with high attack success rate. Although deep learning with differential privacy is a defacto standard for publishing deep learning models with differential privacy guarantee, we show that differentially private algorithms with fixed privacy parameters are vulnerable against gradient leakage attacks. This paper investigates alternative approaches to gradient leakage resilient deep learning with differential privacy (DP). First, we analyze existing implementation of deep learning with differential privacy, which use fixed noise variance to injects constant noise to the gradients in all layers using fixed privacy parameters. Despite the DP guarantee provided, the method suffers from low accuracy and is vulnerable to gradient leakage attacks. Second, we present a gradient leakage resilient deep learning approach with differential privacy guarantee by using dynamic privacy parameters. Unlike fixed-parameter strategies that result in constant noise variance, different dynamic parameter strategies present alternative techniques to introduce adaptive noise variance and adaptive noise injection which are closely aligned to the trend of gradient updates during differentially private model training. Finally, we describe four complementary metrics to evaluate and compare alternative approaches.
Network Representation Learning: From Preprocessing, Feature Extraction to Node Embedding
Oct 14, 2021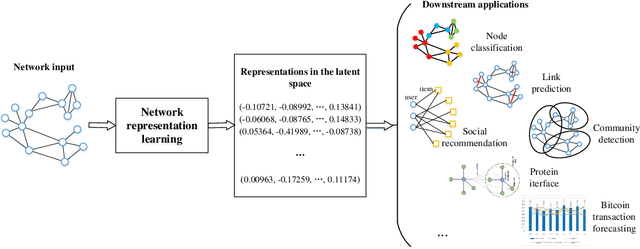

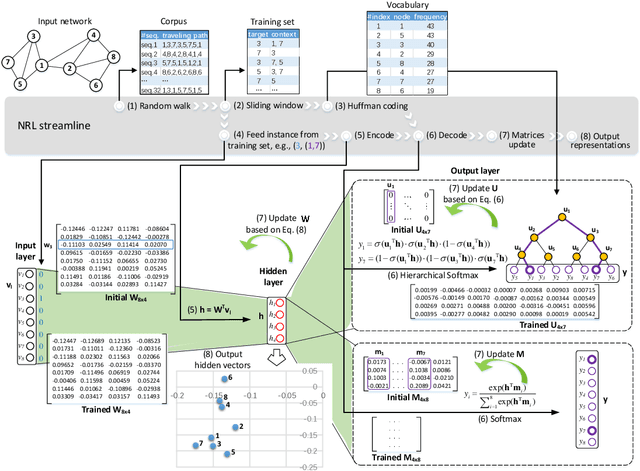
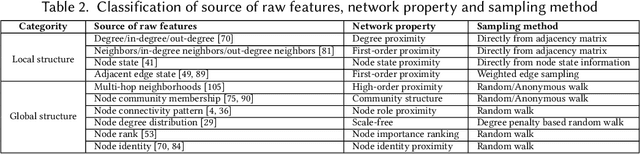
Network representation learning (NRL) advances the conventional graph mining of social networks, knowledge graphs, and complex biomedical and physics information networks. Over dozens of network representation learning algorithms have been reported in the literature. Most of them focus on learning node embeddings for homogeneous networks, but they differ in the specific encoding schemes and specific types of node semantics captured and used for learning node embedding. This survey paper reviews the design principles and the different node embedding techniques for network representation learning over homogeneous networks. To facilitate the comparison of different node embedding algorithms, we introduce a unified reference framework to divide and generalize the node embedding learning process on a given network into preprocessing steps, node feature extraction steps and node embedding model training for a NRL task such as link prediction and node clustering. With this unifying reference framework, we highlight the representative methods, models, and techniques used at different stages of the node embedding model learning process. This survey not only helps researchers and practitioners to gain an in-depth understanding of different network representation learning techniques but also provides practical guidelines for designing and developing the next generation of network representation learning algorithms and systems.
Speech2Video: Cross-Modal Distillation for Speech to Video Generation
Jul 10, 2021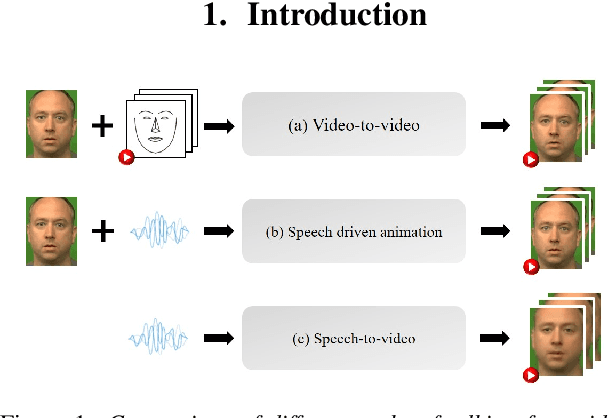
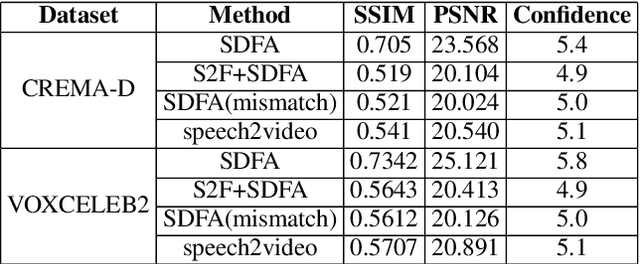
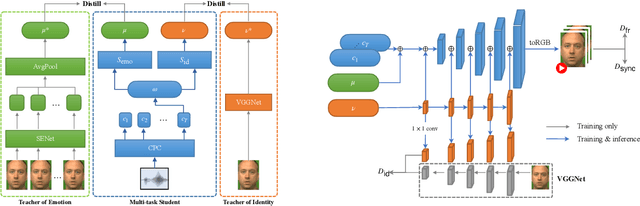
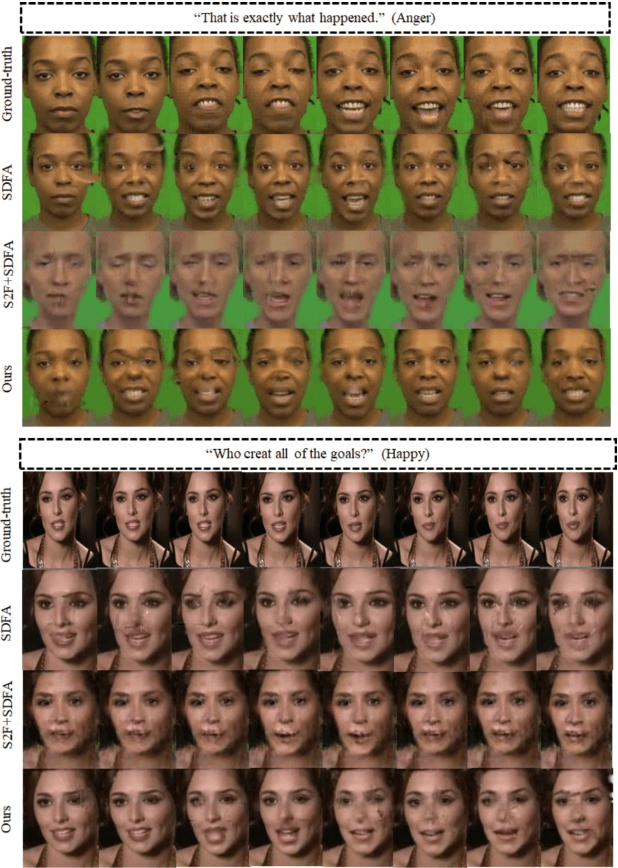
This paper investigates a novel task of talking face video generation solely from speeches. The speech-to-video generation technique can spark interesting applications in entertainment, customer service, and human-computer-interaction industries. Indeed, the timbre, accent and speed in speeches could contain rich information relevant to speakers' appearance. The challenge mainly lies in disentangling the distinct visual attributes from audio signals. In this article, we propose a light-weight, cross-modal distillation method to extract disentangled emotional and identity information from unlabelled video inputs. The extracted features are then integrated by a generative adversarial network into talking face video clips. With carefully crafted discriminators, the proposed framework achieves realistic generation results. Experiments with observed individuals demonstrated that the proposed framework captures the emotional expressions solely from speeches, and produces spontaneous facial motion in the video output. Compared to the baseline method where speeches are combined with a static image of the speaker, the results of the proposed framework is almost indistinguishable. User studies also show that the proposed method outperforms the existing algorithms in terms of emotion expression in the generated videos.
Gradient-Leakage Resilient Federated Learning
Jul 02, 2021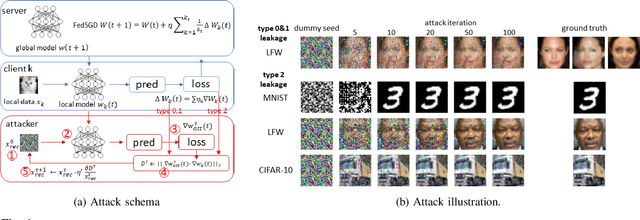
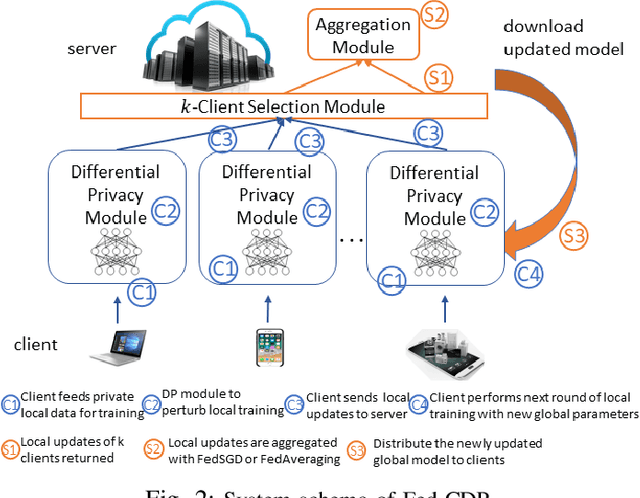
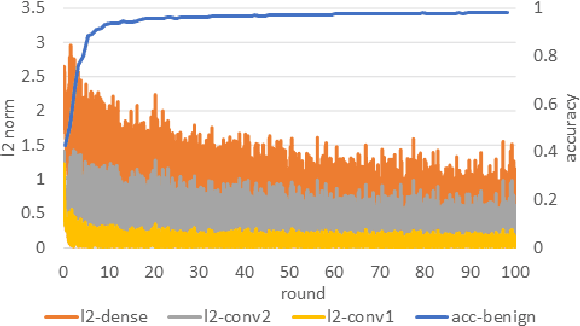
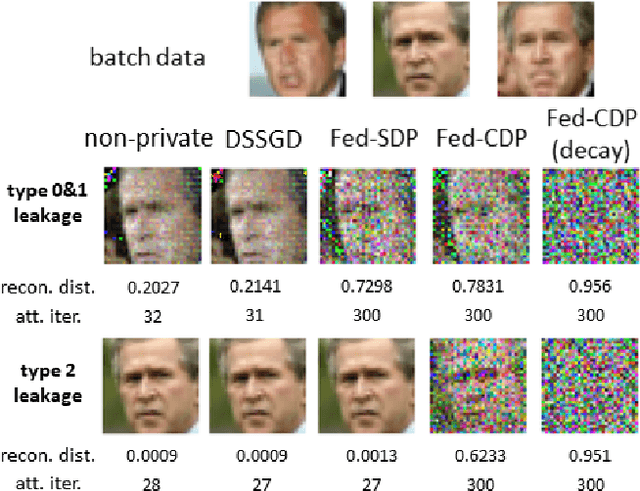
Federated learning(FL) is an emerging distributed learning paradigm with default client privacy because clients can keep sensitive data on their devices and only share local training parameter updates with the federated server. However, recent studies reveal that gradient leakages in FL may compromise the privacy of client training data. This paper presents a gradient leakage resilient approach to privacy-preserving federated learning with per training example-based client differential privacy, coined as Fed-CDP. It makes three original contributions. First, we identify three types of client gradient leakage threats in federated learning even with encrypted client-server communications. We articulate when and why the conventional server coordinated differential privacy approach, coined as Fed-SDP, is insufficient to protect the privacy of the training data. Second, we introduce Fed-CDP, the per example-based client differential privacy algorithm, and provide a formal analysis of Fed-CDP with the $(\epsilon, \delta)$ differential privacy guarantee, and a formal comparison between Fed-CDP and Fed-SDP in terms of privacy accounting. Third, we formally analyze the privacy-utility trade-off for providing differential privacy guarantee by Fed-CDP and present a dynamic decay noise-injection policy to further improve the accuracy and resiliency of Fed-CDP. We evaluate and compare Fed-CDP and Fed-CDP(decay) with Fed-SDP in terms of differential privacy guarantee and gradient leakage resilience over five benchmark datasets. The results show that the Fed-CDP approach outperforms conventional Fed-SDP in terms of resilience to client gradient leakages while offering competitive accuracy performance in federated learning.
Promoting High Diversity Ensemble Learning with EnsembleBench
Oct 20, 2020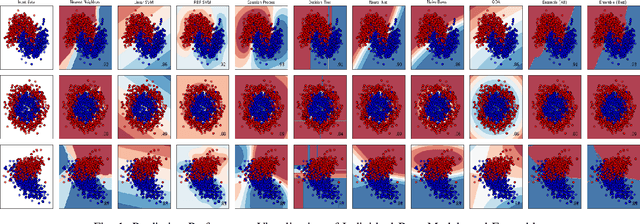



Ensemble learning is gaining renewed interests in recent years. This paper presents EnsembleBench, a holistic framework for evaluating and recommending high diversity and high accuracy ensembles. The design of EnsembleBench offers three novel features: (1) EnsembleBench introduces a set of quantitative metrics for assessing the quality of ensembles and for comparing alternative ensembles constructed for the same learning tasks. (2) EnsembleBench implements a suite of baseline diversity metrics and optimized diversity metrics for identifying and selecting ensembles with high diversity and high quality, making it an effective framework for benchmarking, evaluating and recommending high diversity model ensembles. (3) Four representative ensemble consensus methods are provided in the first release of EnsembleBench, enabling empirical study on the impact of consensus methods on ensemble accuracy. A comprehensive experimental evaluation on popular benchmark datasets demonstrates the utility and effectiveness of EnsembleBench for promoting high diversity ensembles and boosting the overall performance of selected ensembles.
Robust Deep Learning Ensemble against Deception
Sep 14, 2020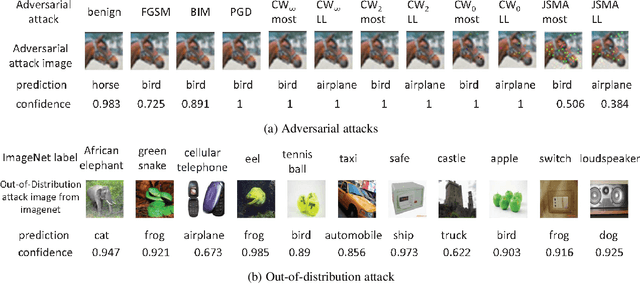
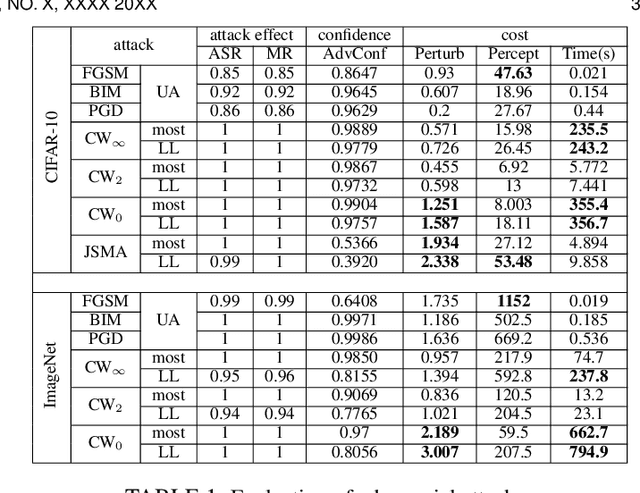
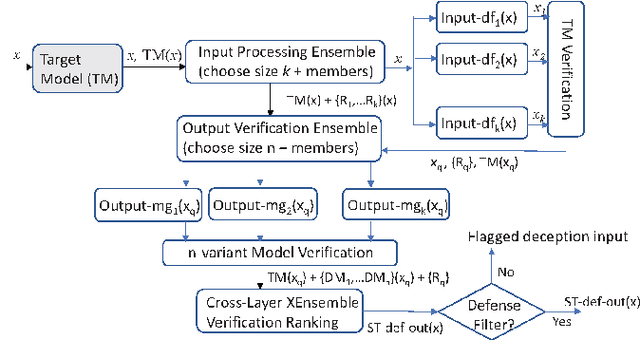
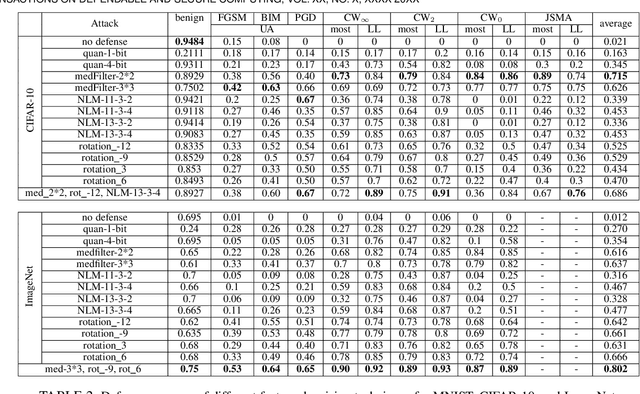
Deep neural network (DNN) models are known to be vulnerable to maliciously crafted adversarial examples and to out-of-distribution inputs drawn sufficiently far away from the training data. How to protect a machine learning model against deception of both types of destructive inputs remains an open challenge. This paper presents XEnsemble, a diversity ensemble verification methodology for enhancing the adversarial robustness of DNN models against deception caused by either adversarial examples or out-of-distribution inputs. XEnsemble by design has three unique capabilities. First, XEnsemble builds diverse input denoising verifiers by leveraging different data cleaning techniques. Second, XEnsemble develops a disagreement-diversity ensemble learning methodology for guarding the output of the prediction model against deception. Third, XEnsemble provides a suite of algorithms to combine input verification and output verification to protect the DNN prediction models from both adversarial examples and out of distribution inputs. Evaluated using eleven popular adversarial attacks and two representative out-of-distribution datasets, we show that XEnsemble achieves a high defense success rate against adversarial examples and a high detection success rate against out-of-distribution data inputs, and outperforms existing representative defense methods with respect to robustness and defensibility.
A Real-time Robot-based Auxiliary System for Risk Evaluation of COVID-19 Infection
Aug 18, 2020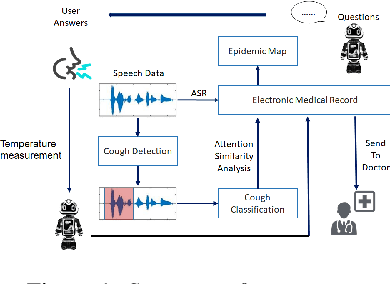

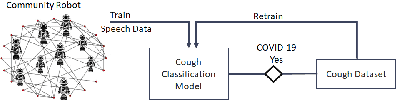
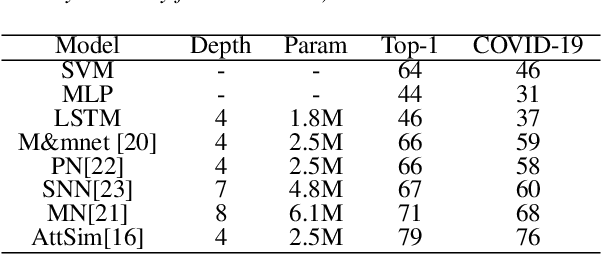
In this paper, we propose a real-time robot-based auxiliary system for risk evaluation of COVID-19 infection. It combines real-time speech recognition, temperature measurement, keyword detection, cough detection and other functions in order to convert live audio into actionable structured data to achieve the COVID-19 infection risk assessment function. In order to better evaluate the COVID-19 infection, we propose an end-to-end method for cough detection and classification for our proposed system. It is based on real conversation data from human-robot, which processes speech signals to detect cough and classifies it if detected. The structure of our model are maintained concise to be implemented for real-time applications. And we further embed this entire auxiliary diagnostic system in the robot and it is placed in the communities, hospitals and supermarkets to support COVID-19 testing. The system can be further leveraged within a business rules engine, thus serving as a foundation for real-time supervision and assistance applications. Our model utilizes a pretrained, robust training environment that allows for efficient creation and customization of customer-specific health states.