 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Face Privacy Protection From a Single Image
May 18, 2026Photos of faces uploaded online are vulnerable to malicious actors who can scrape facial images from online sources and intrude on personal privacy via unauthorized use of facial recognition models. This paper presents FaceCloak, a novel personalized face privacy protection system, which can generate defensive identity-specific universal face privacy masks from a single image of a user, causing facial recognition to fail. FaceCloak introduces a three-stage personalized face perturbation learning methodology: (1) It generates a small set of high-variety synthetic face images of a person based on a single image of the person. (2) It learns face cloaking by adding more protection to key facial-identity leakage regions through iterative perturbation generation over the small set of synthetic images, effectively shifting a user's identity embedding towards a distant anchor identity and away from a similar one. (3) It generates a personalized identity-protective mask in the form of pixel-wise cloaking, which is light-weight and can be efficiently applied to any facial image of a user while maintaining good perceptual quality. Extensive experiments on three popular face datasets across ten recognition models show the effectiveness of FaceCloak compared to 29 other existing representative methods. Code is available at https://github.com/zacharyyahn/FaceCloak
A Framework for Evaluating Gradient Leakage Attacks in Federated Learning
Apr 23, 2020


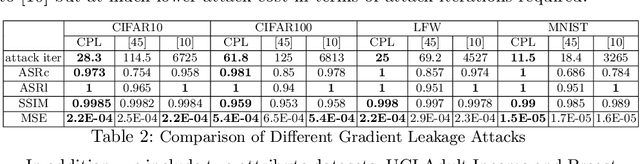
Federated learning (FL) is an emerging distributed machine learning framework for collaborative model training with a network of clients (edge devices). FL offers default client privacy by allowing clients to keep their sensitive data on local devices and to only share local training parameter updates with the federated server. However, recent studies have shown that even sharing local parameter updates from a client to the federated server may be susceptible to gradient leakage attacks and intrude the client privacy regarding its training data. In this paper, we present a principled framework for evaluating and comparing different forms of client privacy leakage attacks. We first provide formal and experimental analysis to show how adversaries can reconstruct the private local training data by simply analyzing the shared parameter update from local training (e.g., local gradient or weight update vector). We then analyze how different hyperparameter configurations in federated learning and different settings of the attack algorithm may impact on both attack effectiveness and attack cost. Our framework also measures, evaluates, and analyzes the effectiveness of client privacy leakage attacks under different gradient compression ratios when using communication efficient FL protocols. Our experiments also include some preliminary mitigation strategies to highlight the importance of providing a systematic attack evaluation framework towards an in-depth understanding of the various forms of client privacy leakage threats in federated learning and developing theoretical foundations for attack mitigation.
Cross-Layer Strategic Ensemble Defense Against Adversarial Examples
Oct 01, 2019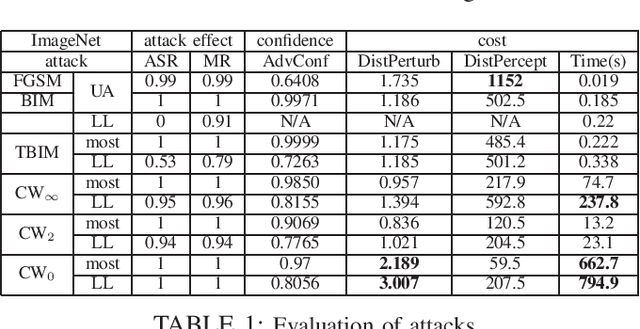

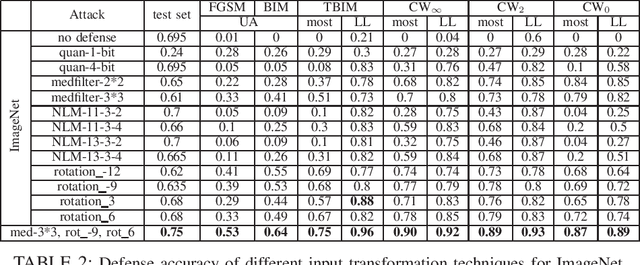

Deep neural network (DNN) has demonstrated its success in multiple domains. However, DNN models are inherently vulnerable to adversarial examples, which are generated by adding adversarial perturbations to benign inputs to fool the DNN model to misclassify. In this paper, we present a cross-layer strategic ensemble framework and a suite of robust defense algorithms, which are attack-independent, and capable of auto-repairing and auto-verifying the target model being attacked. Our strategic ensemble approach makes three original contributions. First, we employ input-transformation diversity to design the input-layer strategic transformation ensemble algorithms. Second, we utilize model-disagreement diversity to develop the output-layer strategic model ensemble algorithms. Finally, we create an input-output cross-layer strategic ensemble defense that strengthens the defensibility by combining diverse input transformation based model ensembles with diverse output verification model ensembles. Evaluated over 10 attacks on ImageNet dataset, we show that our strategic ensemble defense algorithms can achieve high defense success rates and are more robust with high attack prevention success rates and low benign false negative rates, compared to existing representative defense methods.
Deep Neural Network Ensembles against Deception: Ensemble Diversity, Accuracy and Robustness
Aug 29, 2019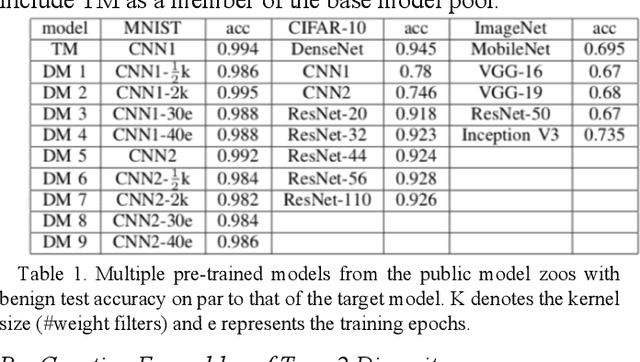

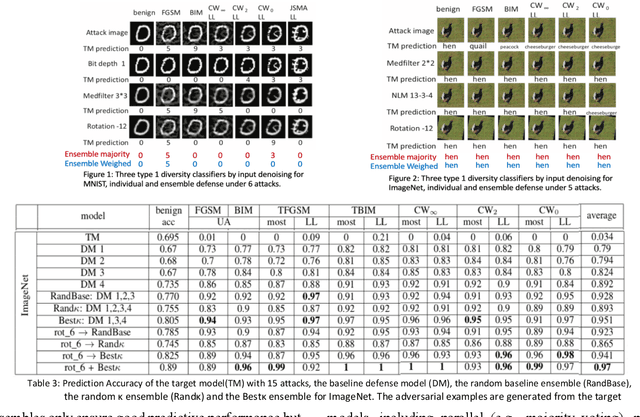
Ensemble learning is a methodology that integrates multiple DNN learners for improving prediction performance of individual learners. Diversity is greater when the errors of the ensemble prediction is more uniformly distributed. Greater diversity is highly correlated with the increase in ensemble accuracy. Another attractive property of diversity optimized ensemble learning is its robustness against deception: an adversarial perturbation attack can mislead one DNN model to misclassify but may not fool other ensemble DNN members consistently. In this paper we first give an overview of the concept of ensemble diversity and examine the three types of ensemble diversity in the context of DNN classifiers. We then describe a set of ensemble diversity measures, a suite of algorithms for creating diversity ensembles and for performing ensemble consensus (voted or learned) for generating high accuracy ensemble output by strategically combining outputs of individual members. This paper concludes with a discussion on a set of open issues in quantifying ensemble diversity for robust deep learning.