 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Norm-Agnostic Robustness of Adversarial Training
May 15, 2019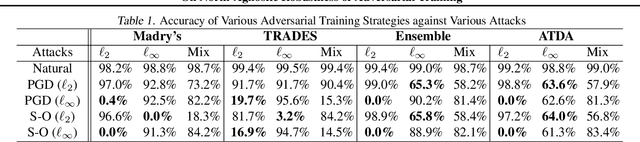
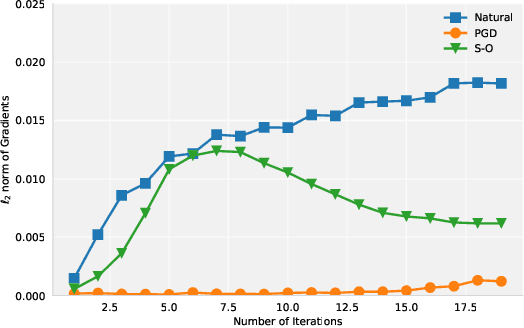
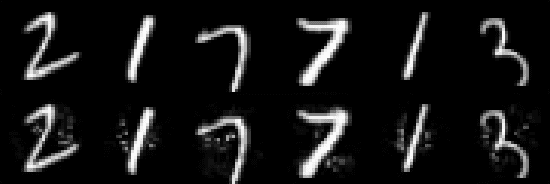
Adversarial examples are carefully perturbed in-puts for fooling machine learning models. A well-acknowledged defense method against such examples is adversarial training, where adversarial examples are injected into training data to increase robustness. In this paper, we propose a new attack to unveil an undesired property of the state-of-the-art adversarial training, that is it fails to obtain robustness against perturbations in $\ell_2$ and $\ell_\infty$ norms simultaneously. We discuss a possible solution to this issue and its limitations as well.
Topic-Guided Variational Autoencoders for Text Generation
Mar 17, 2019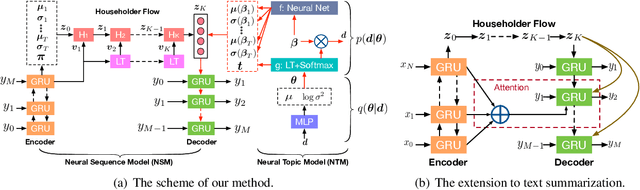

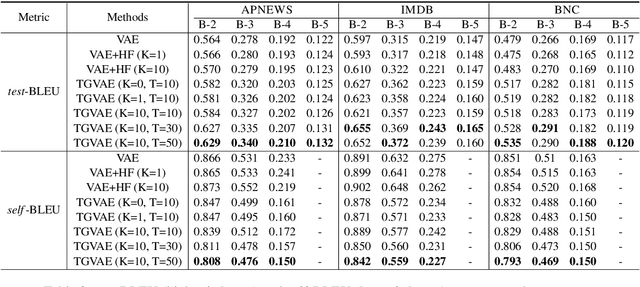
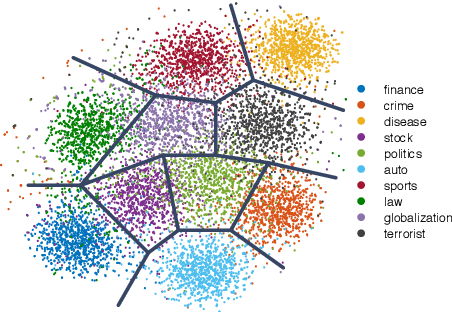
We propose a topic-guided variational autoencoder (TGVAE) model for text generation. Distinct from existing variational autoencoder (VAE) based approaches, which assume a simple Gaussian prior for the latent code, our model specifies the prior as a Gaussian mixture model (GMM) parametrized by a neural topic module. Each mixture component corresponds to a latent topic, which provides guidance to generate sentences under the topic. The neural topic module and the VAE-based neural sequence module in our model are learned jointly. In particular, a sequence of invertible Householder transformations is applied to endow the approximate posterior of the latent code with high flexibility during model inference. Experimental results show that our TGVAE outperforms alternative approaches on both unconditional and conditional text generation, which can generate semantically-meaningful sentences with various topics.
Sequence Generation with Guider Network
Nov 02, 2018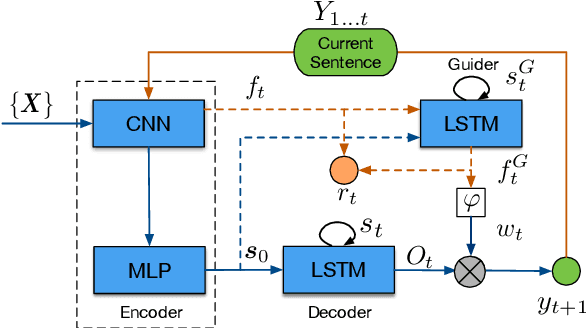
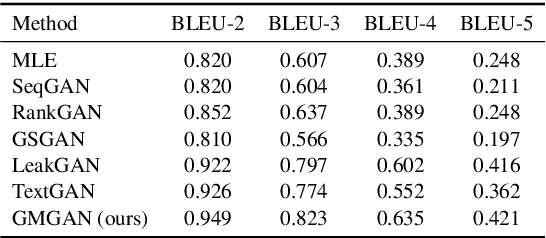
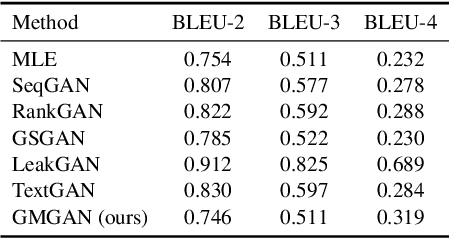
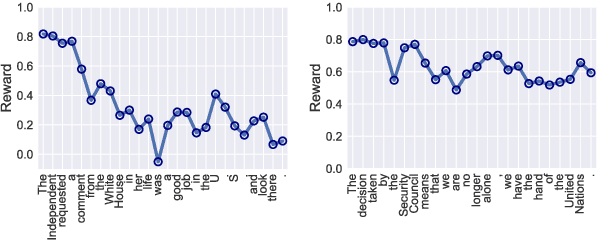
Sequence generation with reinforcement learning (RL) has received significant attention recently. However, a challenge with such methods is the sparse-reward problem in the RL training process, in which a scalar guiding signal is often only available after an entire sequence has been generated. This type of sparse reward tends to ignore the global structural information of a sequence, causing generation of sequences that are semantically inconsistent. In this paper, we present a model-based RL approach to overcome this issue. Specifically, we propose a novel guider network to model the sequence-generation environment, which can assist next-word prediction and provide intermediate rewards for generator optimization. Extensive experiments show that the proposed method leads to improved performance for both unconditional and conditional sequence-generation tasks.
Distilled Wasserstein Learning for Word Embedding and Topic Modeling
Sep 12, 2018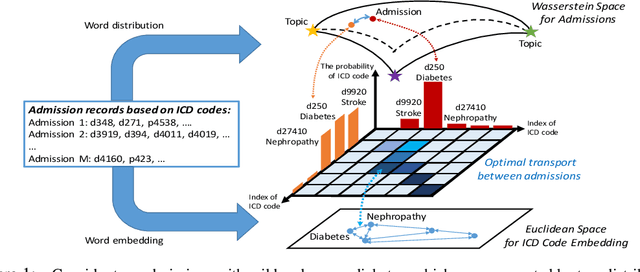
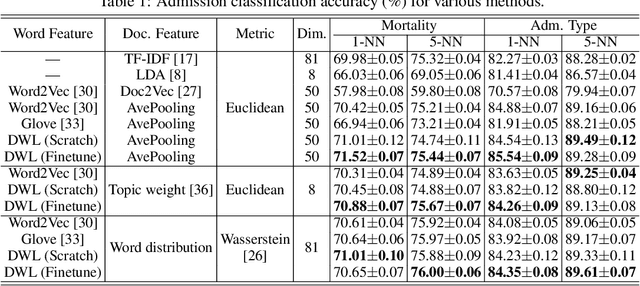
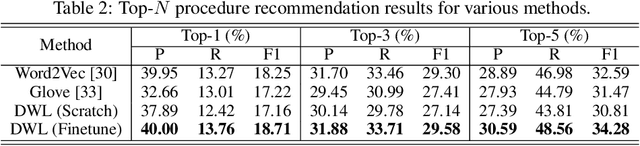
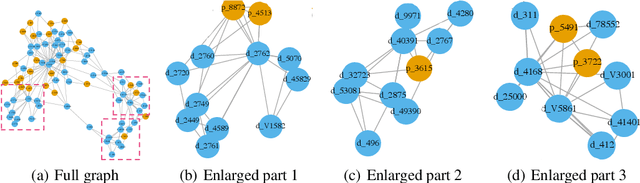
We propose a novel Wasserstein method with a distillation mechanism, yielding joint learning of word embeddings and topics. The proposed method is based on the fact that the Euclidean distance between word embeddings may be employed as the underlying distance in the Wasserstein topic model. The word distributions of topics, their optimal transports to the word distributions of documents, and the embeddings of words are learned in a unified framework. When learning the topic model, we leverage a distilled underlying distance matrix to update the topic distributions and smoothly calculate the corresponding optimal transports. Such a strategy provides the updating of word embeddings with robust guidance, improving the algorithmic convergence. As an application, we focus on patient admission records, in which the proposed method embeds the codes of diseases and procedures and learns the topics of admissions, obtaining superior performance on clinically-meaningful disease network construction, mortality prediction as a function of admission codes, and procedure recommendation.
Second-Order Adversarial Attack and Certifiable Robustness
Sep 10, 2018
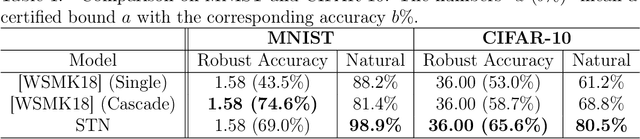


We propose a powerful second-order attack method that outperforms existing attack methods on reducing the accuracy of state-of-the-art defense models based on adversarial training. The effectiveness of our attack method motivates an investigation of provable robustness of a defense model. To this end, we introduce a framework that allows one to obtain a certifiable lower bound on the prediction accuracy against adversarial examples. We conduct experiments to show the effectiveness of our attack method. At the same time, our defense models obtain higher accuracies compared to previous works under our proposed attack.
Continuous-Time Flows for Efficient Inference and Density Estimation
Aug 01, 2018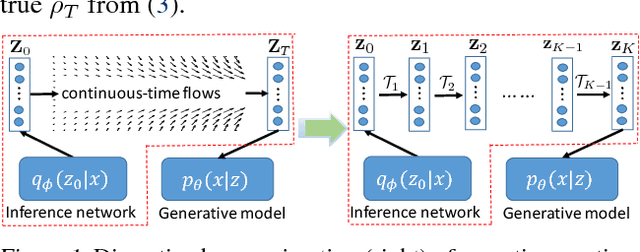

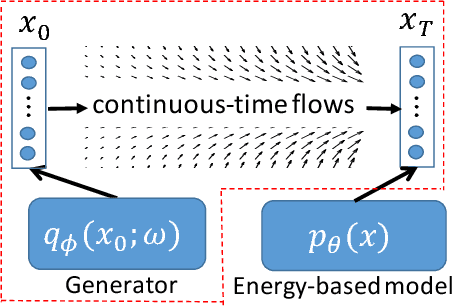
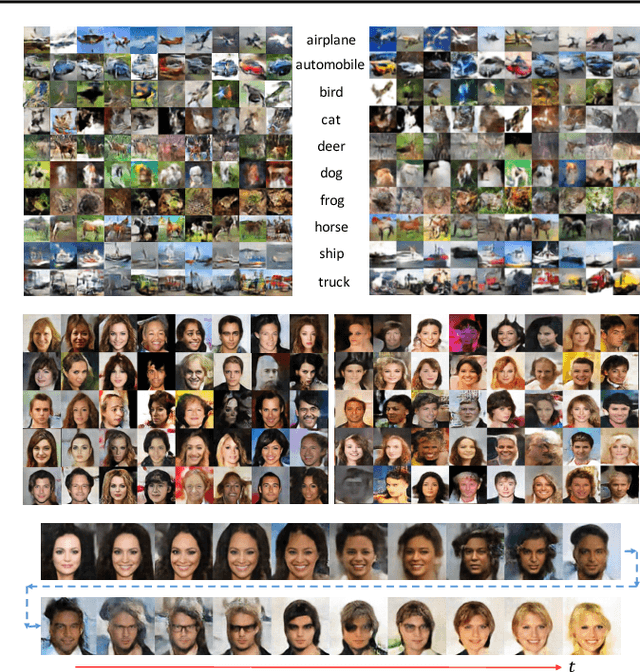
Two fundamental problems in unsupervised learning are efficient inference for latent-variable models and robust density estimation based on large amounts of unlabeled data. Algorithms for the two tasks, such as normalizing flows and generative adversarial networks (GANs), are often developed independently. In this paper, we propose the concept of {\em continuous-time flows} (CTFs), a family of diffusion-based methods that are able to asymptotically approach a target distribution. Distinct from normalizing flows and GANs, CTFs can be adopted to achieve the above two goals in one framework, with theoretical guarantees. Our framework includes distilling knowledge from a CTF for efficient inference, and learning an explicit energy-based distribution with CTFs for density estimation. Both tasks rely on a new technique for distribution matching within amortized learning. Experiments on various tasks demonstrate promising performance of the proposed CTF framework, compared to related techniques.
A Unified Particle-Optimization Framework for Scalable Bayesian Sampling
Jul 10, 2018
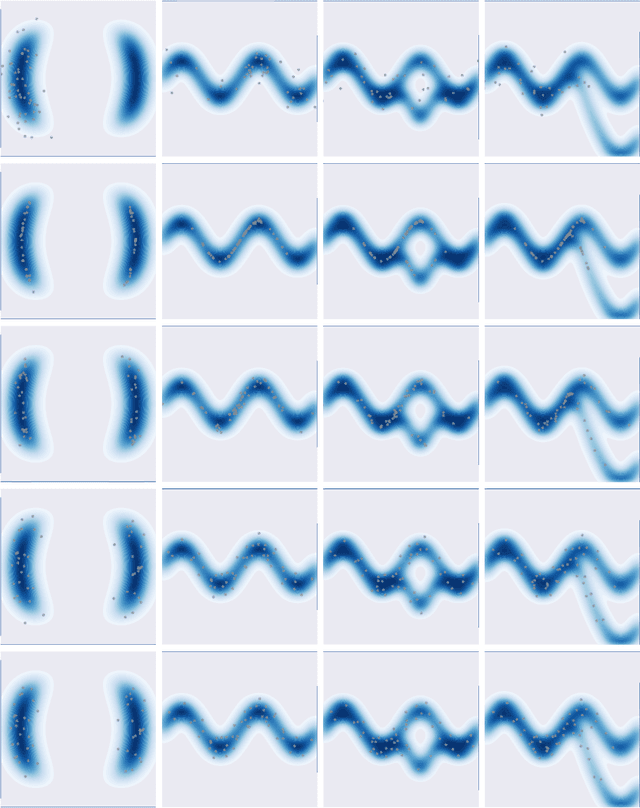
There has been recent interest in developing scalable Bayesian sampling methods such as stochastic gradient MCMC (SG-MCMC) and Stein variational gradient descent (SVGD) for big-data analysis. A standard SG-MCMC algorithm simulates samples from a discrete-time Markov chain to approximate a target distribution, thus samples could be highly correlated, an undesired property for SG-MCMC. In contrary, SVGD directly optimizes a set of particles to approximate a target distribution, and thus is able to obtain good approximations with relatively much fewer samples. In this paper, we propose a principle particle-optimization framework based on Wasserstein gradient flows to unify SG-MCMC and SVGD, and to allow new algorithms to be developed. Our framework interprets SG-MCMC as particle optimization on the space of probability measures, revealing a strong connection between SG-MCMC and SVGD. The key component of our framework is several particle-approximate techniques to efficiently solve the original partial differential equations on the space of probability measures. Extensive experiments on both synthetic data and deep neural networks demonstrate the effectiveness and efficiency of our framework for scalable Bayesian sampling.
Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms
May 24, 2018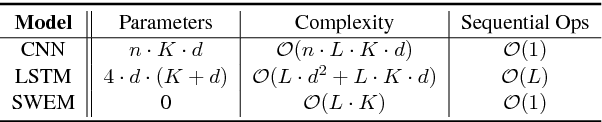
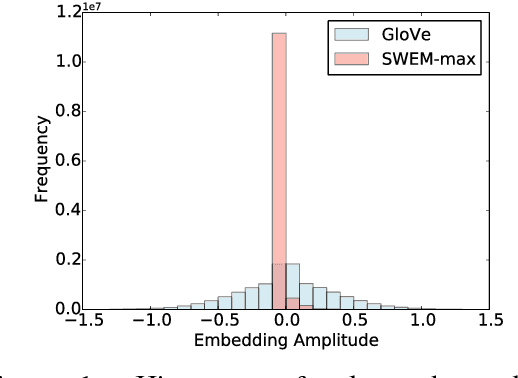

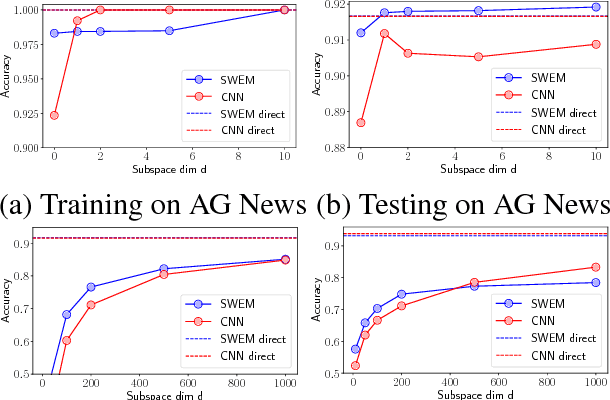
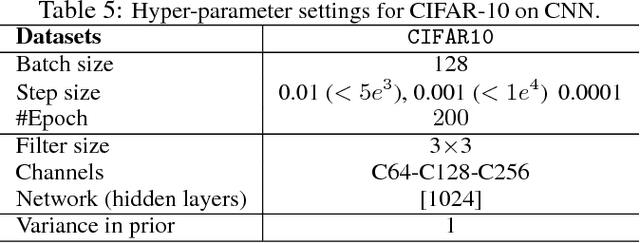
Many deep learning architectures have been proposed to model the compositionality in text sequences, requiring a substantial number of parameters and expensive computations. However, there has not been a rigorous evaluation regarding the added value of sophisticated compositional functions. In this paper, we conduct a point-by-point comparative study between Simple Word-Embedding-based Models (SWEMs), consisting of parameter-free pooling operations, relative to word-embedding-based RNN/CNN models. Surprisingly, SWEMs exhibit comparable or even superior performance in the majority of cases considered. Based upon this understanding, we propose two additional pooling strategies over learned word embeddings: (i) a max-pooling operation for improved interpretability; and (ii) a hierarchical pooling operation, which preserves spatial (n-gram) information within text sequences. We present experiments on 17 datasets encompassing three tasks: (i) (long) document classification; (ii) text sequence matching; and (iii) short text tasks, including classification and tagging. The source code and datasets can be obtained from https:// github.com/dinghanshen/SWEM.
NASH: Toward End-to-End Neural Architecture for Generative Semantic Hashing
May 14, 2018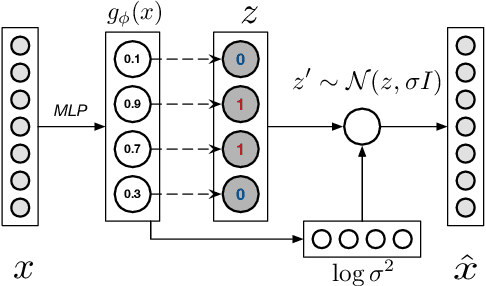
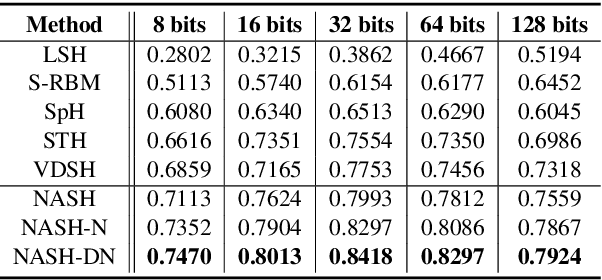
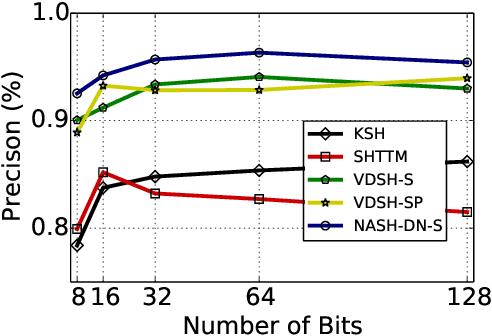
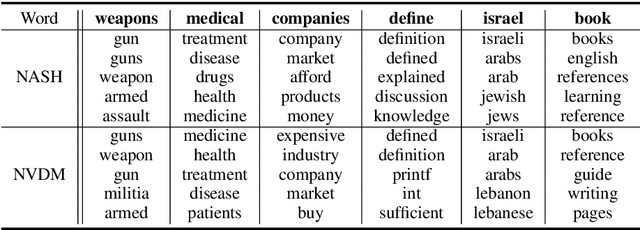
Semantic hashing has become a powerful paradigm for fast similarity search in many information retrieval systems. While fairly successful, previous techniques generally require two-stage training, and the binary constraints are handled ad-hoc. In this paper, we present an end-to-end Neural Architecture for Semantic Hashing (NASH), where the binary hashing codes are treated as Bernoulli latent variables. A neural variational inference framework is proposed for training, where gradients are directly back-propagated through the discrete latent variable to optimize the hash function. We also draw connections between proposed method and rate-distortion theory, which provides a theoretical foundation for the effectiveness of the proposed framework. Experimental results on three public datasets demonstrate that our method significantly outperforms several state-of-the-art models on both unsupervised and supervised scenarios.
Joint Embedding of Words and Labels for Text Classification
May 10, 2018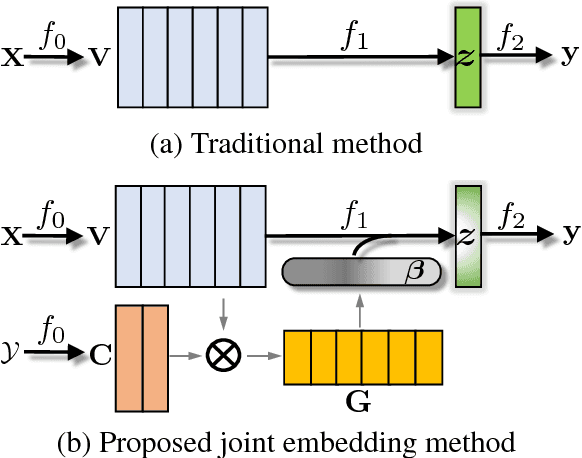
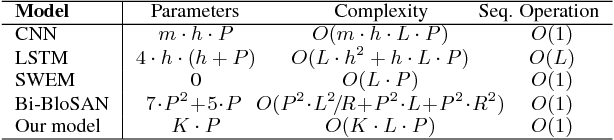
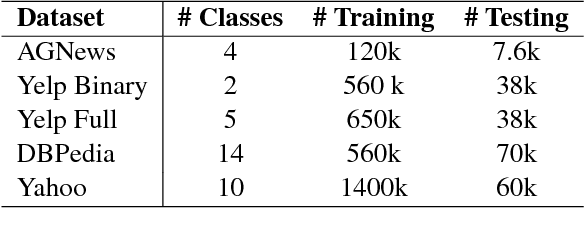
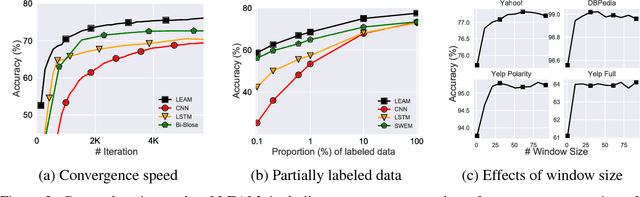
Word embeddings are effective intermediate representations for capturing semantic regularities between words, when learning the representations of text sequences. We propose to view text classification as a label-word joint embedding problem: each label is embedded in the same space with the word vectors. We introduce an attention framework that measures the compatibility of embeddings between text sequences and labels. The attention is learned on a training set of labeled samples to ensure that, given a text sequence, the relevant words are weighted higher than the irrelevant ones. Our method maintains the interpretability of word embeddings, and enjoys a built-in ability to leverage alternative sources of information, in addition to input text sequences. Extensive results on the several large text datasets show that the proposed framework outperforms the state-of-the-art methods by a large margin, in terms of both accuracy and speed.