 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeo-Neus: Geometry-Consistent Neural Implicit Surfaces Learning for Multi-view Reconstruction
May 31, 2022
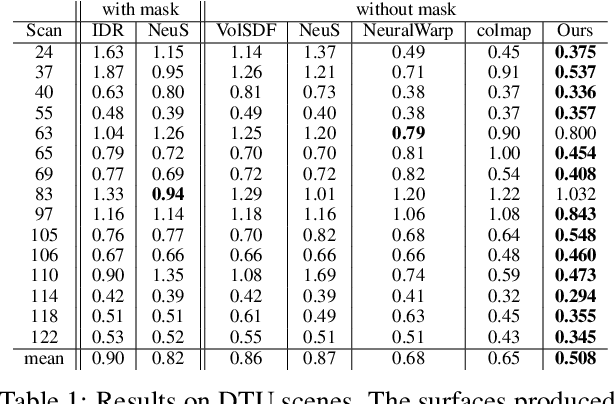
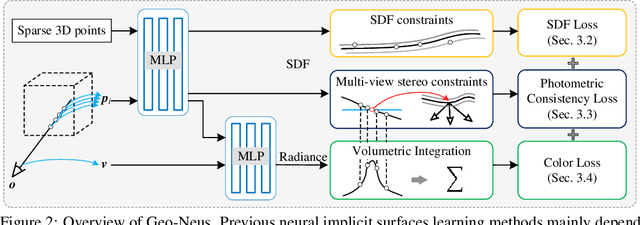

Recently, neural implicit surfaces learning by volume rendering has become popular for multi-view reconstruction. However, one key challenge remains: existing approaches lack explicit multi-view geometry constraints, hence usually fail to generate geometry consistent surface reconstruction. To address this challenge, we propose geometry-consistent neural implicit surfaces learning for multi-view reconstruction. We theoretically analyze that there exists a gap between the volume rendering integral and point-based signed distance function (SDF) modeling. To bridge this gap, we directly locate the zero-level set of SDF networks and explicitly perform multi-view geometry optimization by leveraging the sparse geometry from structure from motion (SFM) and photometric consistency in multi-view stereo. This makes our SDF optimization unbiased and allows the multi-view geometry constraints to focus on the true surface optimization. Extensive experiments show that our proposed method achieves high-quality surface reconstruction in both complex thin structures and large smooth regions, thus outperforming the state-of-the-arts by a large margin.
SC^2-PCR: A Second Order Spatial Compatibility for Efficient and Robust Point Cloud Registration
Mar 28, 2022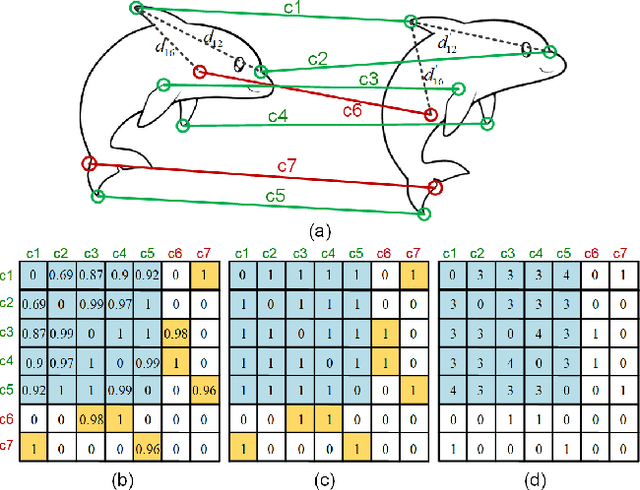
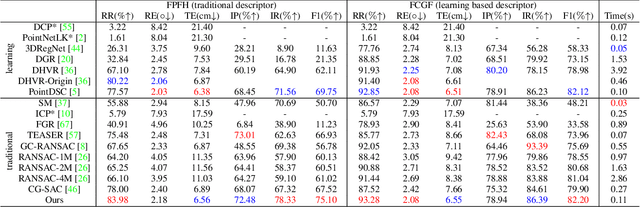

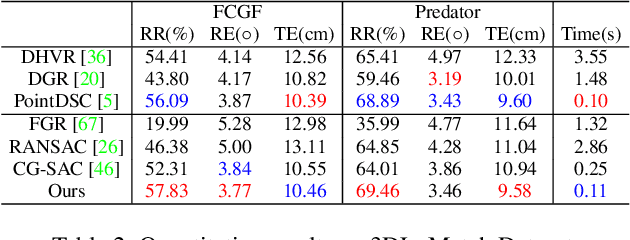
In this paper, we present a second order spatial compatibility (SC^2) measure based method for efficient and robust point cloud registration (PCR), called SC^2-PCR. Firstly, we propose a second order spatial compatibility (SC^2) measure to compute the similarity between correspondences. It considers the global compatibility instead of local consistency, allowing for more distinctive clustering between inliers and outliers at early stage. Based on this measure, our registration pipeline employs a global spectral technique to find some reliable seeds from the initial correspondences. Then we design a two-stage strategy to expand each seed to a consensus set based on the SC^2 measure matrix. Finally, we feed each consensus set to a weighted SVD algorithm to generate a candidate rigid transformation and select the best model as the final result. Our method can guarantee to find a certain number of outlier-free consensus sets using fewer samplings, making the model estimation more efficient and robust. In addition, the proposed SC^2 measure is general and can be easily plugged into deep learning based frameworks. Extensive experiments are carried out to investigate the performance of our method. Code will be available at \url{https://github.com/ZhiChen902/SC2-PCR}.
DetarNet: Decoupling Translation and Rotation by Siamese Network for Point Cloud Registration
Dec 28, 2021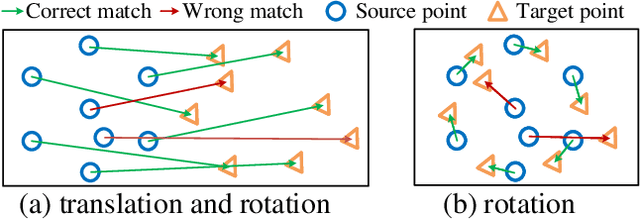
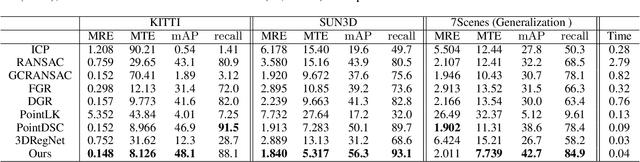
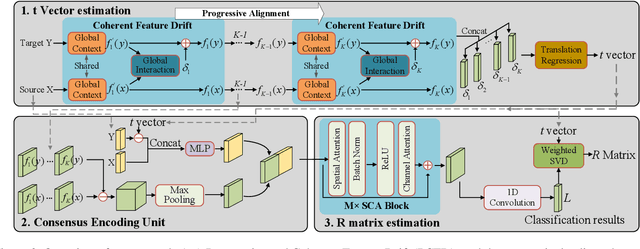
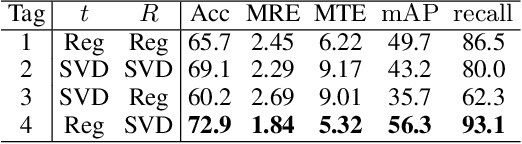
Point cloud registration is a fundamental step for many tasks. In this paper, we propose a neural network named DetarNet to decouple the translation $t$ and rotation $R$, so as to overcome the performance degradation due to their mutual interference in point cloud registration. First, a Siamese Network based Progressive and Coherent Feature Drift (PCFD) module is proposed to align the source and target points in high-dimensional feature space, and accurately recover translation from the alignment process. Then we propose a Consensus Encoding Unit (CEU) to construct more distinguishable features for a set of putative correspondences. After that, a Spatial and Channel Attention (SCA) block is adopted to build a classification network for finding good correspondences. Finally, the rotation is obtained by Singular Value Decomposition (SVD). In this way, the proposed network decouples the estimation of translation and rotation, resulting in better performance for both of them. Experimental results demonstrate that the proposed DetarNet improves registration performance on both indoor and outdoor scenes. Our code will be available in \url{https://github.com/ZhiChen902/DetarNet}.
Non-local Recurrent Regularization Networks for Multi-view Stereo
Oct 13, 2021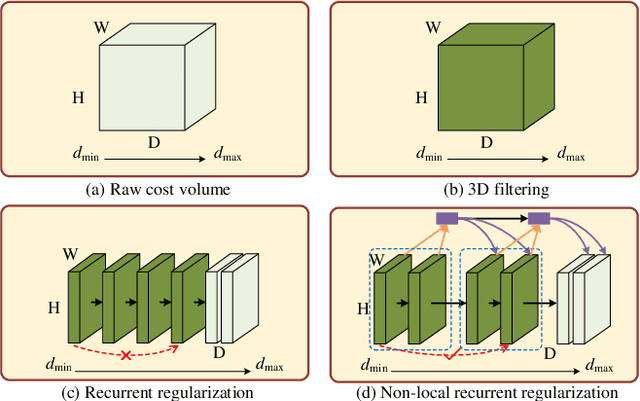
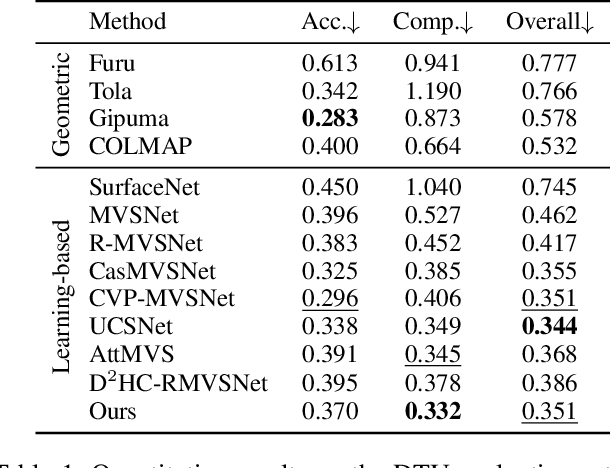
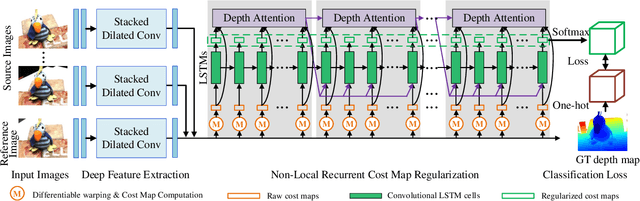
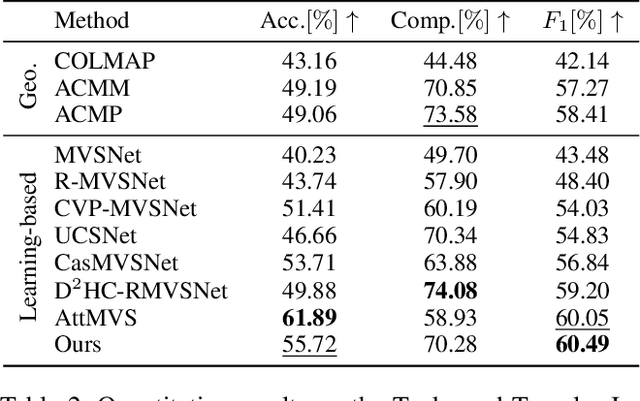
In deep multi-view stereo networks, cost regularization is crucial to achieve accurate depth estimation. Since 3D cost volume filtering is usually memory-consuming, recurrent 2D cost map regularization has recently become popular and has shown great potential in reconstructing 3D models of different scales. However, existing recurrent methods only model the local dependencies in the depth domain, which greatly limits the capability of capturing the global scene context along the depth dimension. To tackle this limitation, we propose a novel non-local recurrent regularization network for multi-view stereo, named NR2-Net. Specifically, we design a depth attention module to capture non-local depth interactions within a sliding depth block. Then, the global scene context between different blocks is modeled in a gated recurrent manner. This way, the long-range dependencies along the depth dimension are captured to facilitate the cost regularization. Moreover, we design a dynamic depth map fusion strategy to improve the algorithm robustness. Our method achieves state-of-the-art reconstruction results on both DTU and Tanks and Temples datasets.
LIF-Seg: LiDAR and Camera Image Fusion for 3D LiDAR Semantic Segmentation
Aug 17, 2021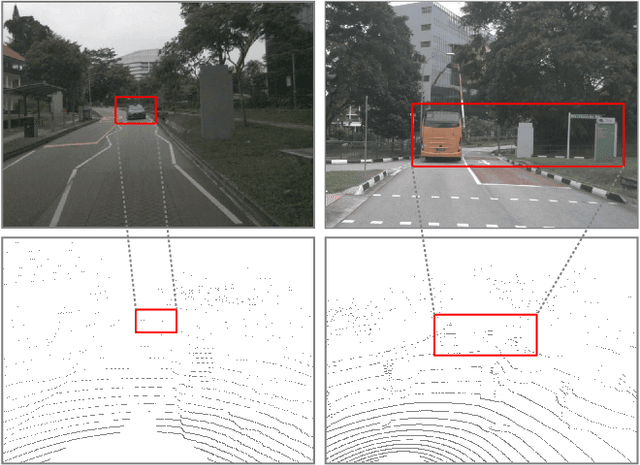

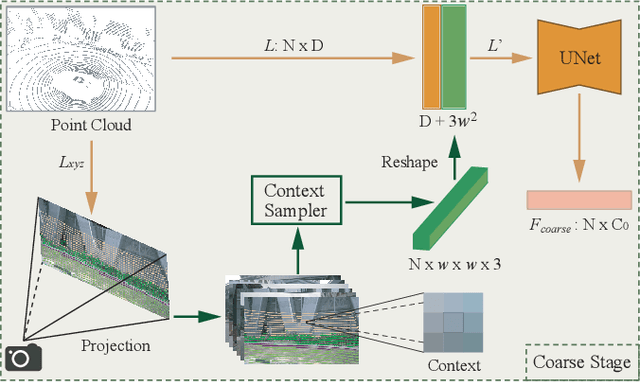
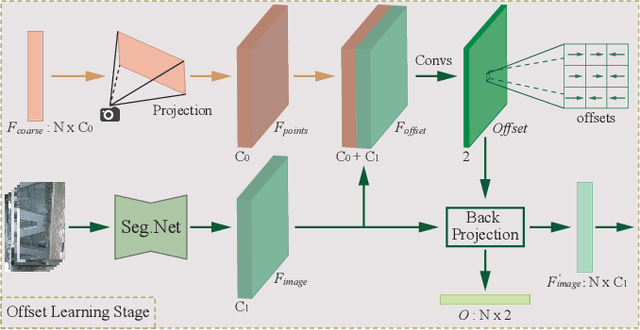
Camera and 3D LiDAR sensors have become indispensable devices in modern autonomous driving vehicles, where the camera provides the fine-grained texture, color information in 2D space and LiDAR captures more precise and farther-away distance measurements of the surrounding environments. The complementary information from these two sensors makes the two-modality fusion be a desired option. However, two major issues of the fusion between camera and LiDAR hinder its performance, \ie, how to effectively fuse these two modalities and how to precisely align them (suffering from the weak spatiotemporal synchronization problem). In this paper, we propose a coarse-to-fine LiDAR and camera fusion-based network (termed as LIF-Seg) for LiDAR segmentation. For the first issue, unlike these previous works fusing the point cloud and image information in a one-to-one manner, the proposed method fully utilizes the contextual information of images and introduces a simple but effective early-fusion strategy. Second, due to the weak spatiotemporal synchronization problem, an offset rectification approach is designed to align these two-modality features. The cooperation of these two components leads to the success of the effective camera-LiDAR fusion. Experimental results on the nuScenes dataset show the superiority of the proposed LIF-Seg over existing methods with a large margin. Ablation studies and analyses demonstrate that our proposed LIF-Seg can effectively tackle the weak spatiotemporal synchronization problem.
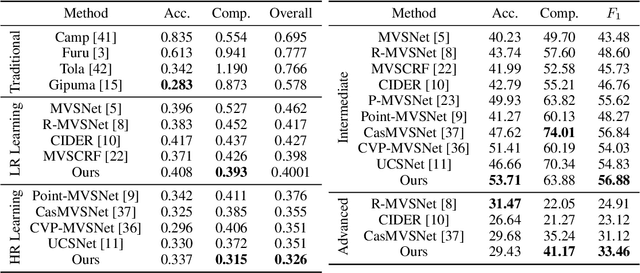
Cascade Network with Guided Loss and Hybrid Attention for Finding Good Correspondences
Jan 31, 2021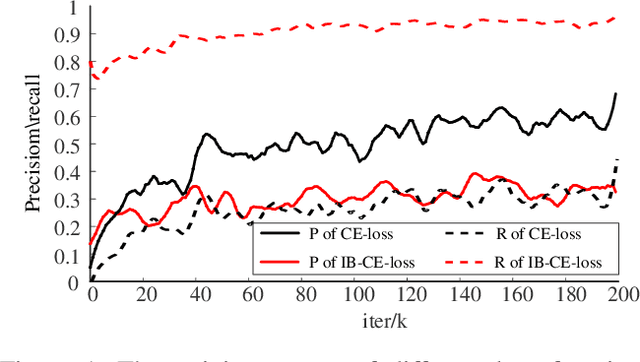
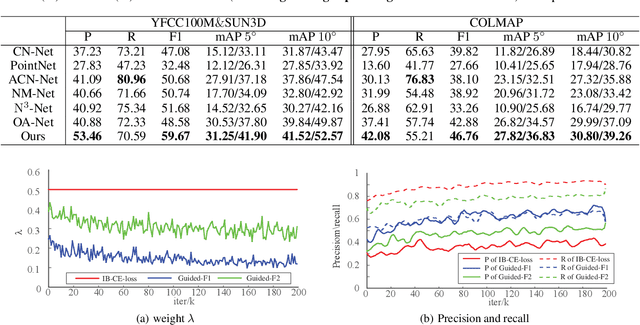
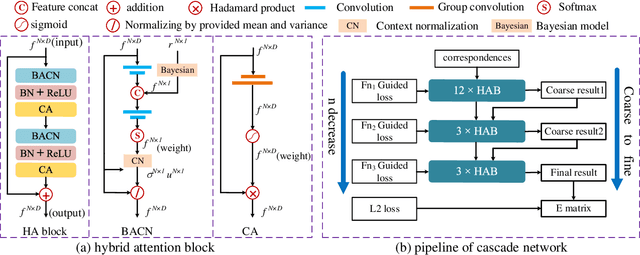
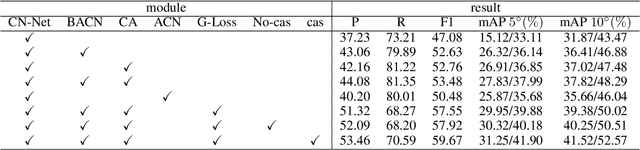
Finding good correspondences is a critical prerequisite in many feature based tasks. Given a putative correspondence set of an image pair, we propose a neural network which finds correct correspondences by a binary-class classifier and estimates relative pose through classified correspondences. First, we analyze that due to the imbalance in the number of correct and wrong correspondences, the loss function has a great impact on the classification results. Thus, we propose a new Guided Loss that can directly use evaluation criterion (Fn-measure) as guidance to dynamically adjust the objective function during training. We theoretically prove that the perfect negative correlation between the Guided Loss and Fn-measure, so that the network is always trained towards the direction of increasing Fn-measure to maximize it. We then propose a hybrid attention block to extract feature, which integrates the Bayesian attentive context normalization (BACN) and channel-wise attention (CA). BACN can mine the prior information to better exploit global context and CA can capture complex channel context to enhance the channel awareness of the network. Finally, based on our Guided Loss and hybrid attention block, a cascade network is designed to gradually optimize the result for more superior performance. Experiments have shown that our network achieves the state-of-the-art performance on benchmark datasets. Our code will be available in https://github.com/wenbingtao/GLHA.
DeepDT: Learning Geometry From Delaunay Triangulation for Surface Reconstruction
Jan 25, 2021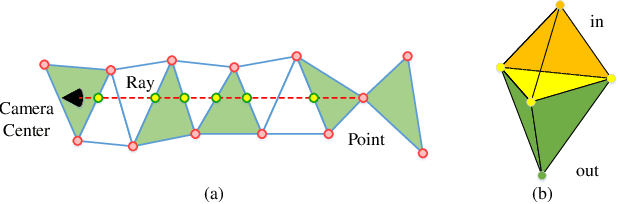

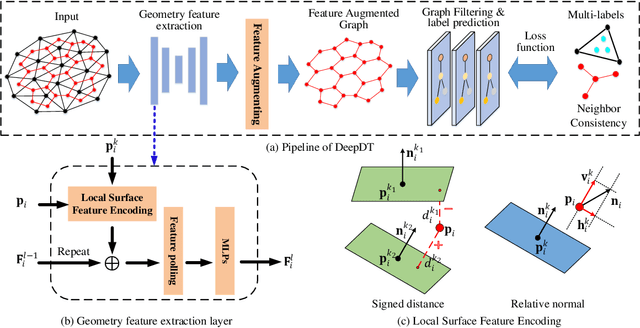

In this paper, a novel learning-based network, named DeepDT, is proposed to reconstruct the surface from Delaunay triangulation of point cloud. DeepDT learns to predict inside/outside labels of Delaunay tetrahedrons directly from a point cloud and corresponding Delaunay triangulation. The local geometry features are first extracted from the input point cloud and aggregated into a graph deriving from the Delaunay triangulation. Then a graph filtering is applied on the aggregated features in order to add structural regularization to the label prediction of tetrahedrons. Due to the complicated spatial relations between tetrahedrons and the triangles, it is impossible to directly generate ground truth labels of tetrahedrons from ground truth surface. Therefore, we propose a multilabel supervision strategy which votes for the label of a tetrahedron with labels of sampling locations inside it. The proposed DeepDT can maintain abundant geometry details without generating overly complex surfaces , especially for inner surfaces of open scenes. Meanwhile, the generalization ability and time consumption of the proposed method is acceptable and competitive compared with the state-of-the-art methods. Experiments demonstrate the superior performance of the proposed DeepDT.
Cascade Network with Guided Loss and Hybrid Attention for Two-view Geometry
Jul 16, 2020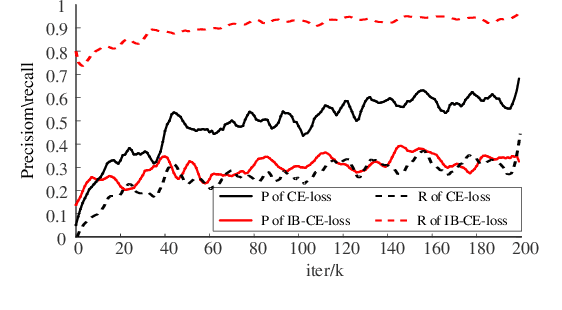
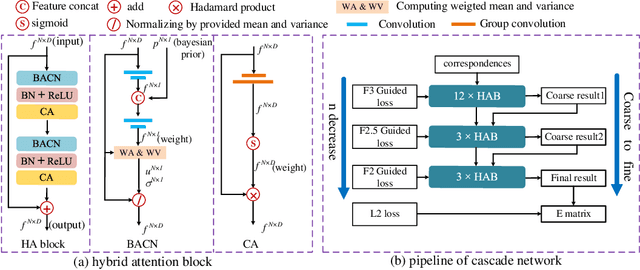

In this paper, we are committed to designing a high-performance network for two-view geometry. We first propose a Guided Loss and theoretically establish the direct negative correlation between the loss and Fn-measure by dynamically adjusting the weights of positive and negative classes during training, so that the network is always trained towards the direction of increasing Fn-measure. By this way, the network can maintain the advantage of the cross-entropy loss while maximizing the Fn-measure. We then propose a hybrid attention block to extract feature, which integrates the bayesian attentive context normalization (BACN) and channel-wise attention (CA). BACN can mine the prior information to better exploit global context and CA can capture complex channel context to enhance the channel awareness of the network. Finally, based on our Guided Loss and hybrid attention block, a cascade network is designed to gradually optimize the result for more superior performance. Experiments have shown that our network achieves the state-of-the-art performance on benchmark datasets.
PVSNet: Pixelwise Visibility-Aware Multi-View Stereo Network
Jul 15, 2020
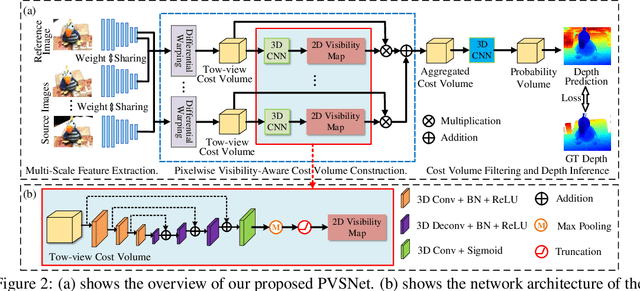
Recently, learning-based multi-view stereo methods have achieved promising results. However, they all overlook the visibility difference among different views, which leads to an indiscriminate multi-view similarity definition and greatly limits their performance on datasets with strong viewpoint variations. In this paper, a Pixelwise Visibility-aware multi-view Stereo Network (PVSNet) is proposed for robust dense 3D reconstruction. We present a pixelwise visibility network to learn the visibility information for different neighboring images before computing the multi-view similarity, and then construct an adaptive weighted cost volume with the visibility information. Moreover, we present an anti-noise training strategy that introduces disturbing views during model training to make the pixelwise visibility network more distinguishable to unrelated views, which is different with the existing learning methods that only use two best neighboring views for training. To the best of our knowledge, PVSNet is the first deep learning framework that is able to capture the visibility information of different neighboring views. In this way, our method can be generalized well to different types of datasets, especially the ETH3D high-res benchmark with strong viewpoint variations. Extensive experiments show that PVSNet achieves the state-of-the-art performance on different datasets.
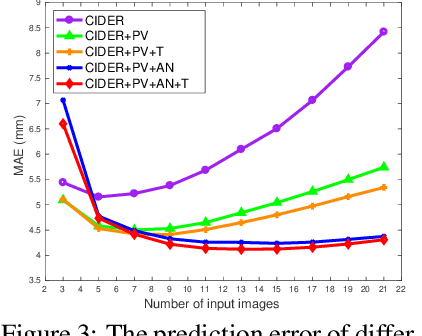
Learning Inverse Depth Regression for Multi-View Stereo with Correlation Cost Volume
Dec 26, 2019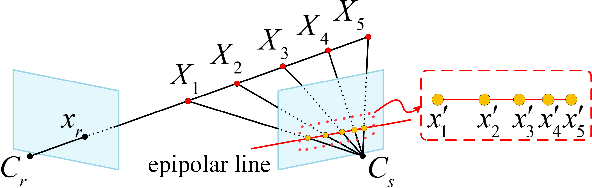
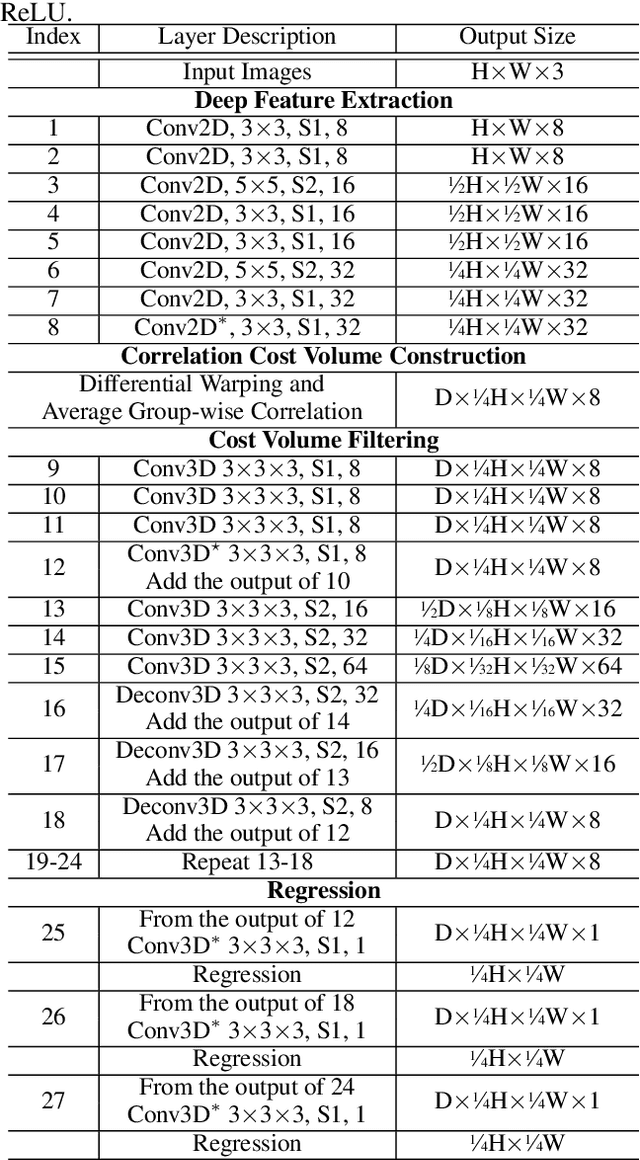
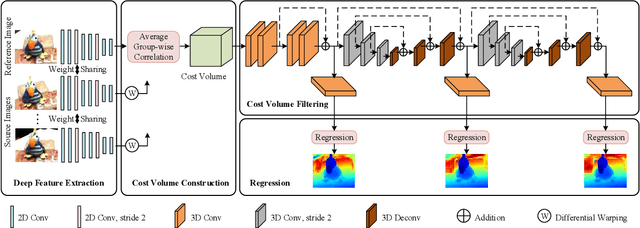
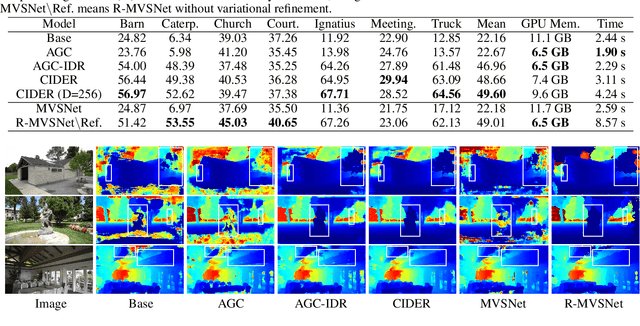
Deep learning has shown to be effective for depth inference in multi-view stereo (MVS). However, the scalability and accuracy still remain an open problem in this domain. This can be attributed to the memory-consuming cost volume representation and inappropriate depth inference. Inspired by the group-wise correlation in stereo matching, we propose an average group-wise correlation similarity measure to construct a lightweight cost volume. This can not only reduce the memory consumption but also reduce the computational burden in the cost volume filtering. Based on our effective cost volume representation, we propose a cascade 3D U-Net module to regularize the cost volume to further boost the performance. Unlike the previous methods that treat multi-view depth inference as a depth regression problem or an inverse depth classification problem, we recast multi-view depth inference as an inverse depth regression task. This allows our network to achieve sub-pixel estimation and be applicable to large-scale scenes. Through extensive experiments on DTU dataset and Tanks and Temples dataset, we show that our proposed network with Correlation cost volume and Inverse DEpth Regression (CIDER), achieves state-of-the-art results, demonstrating its superior performance on scalability and accuracy.