 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConCare: Personalized Clinical Feature Embedding via Capturing the Healthcare Context
Nov 27, 2019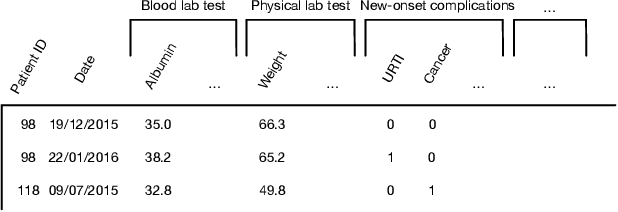
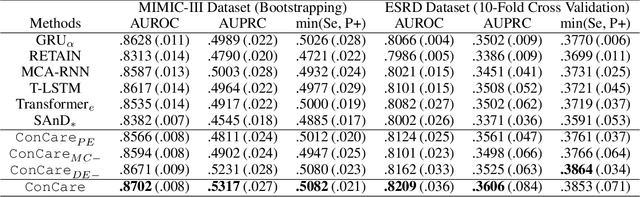
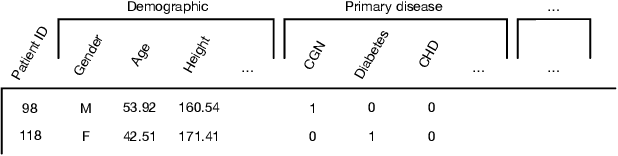
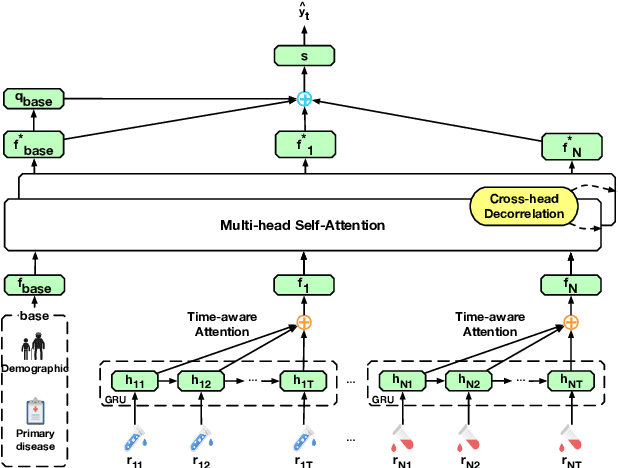
Predicting the patient's clinical outcome from the historical electronic medical records (EMR) is a fundamental research problem in medical informatics. Most deep learning-based solutions for EMR analysis concentrate on learning the clinical visit embedding and exploring the relations between visits. Although those works have shown superior performances in healthcare prediction, they fail to explore the personal characteristics during the clinical visits thoroughly. Moreover, existing works usually assume that the more recent record weights more in the prediction, but this assumption is not suitable for all conditions. In this paper, we propose ConCare to handle the irregular EMR data and extract feature interrelationship to perform individualized healthcare prediction. Our solution can embed the feature sequences separately by modeling the time-aware distribution. ConCare further improves the multi-head self-attention via the cross-head decorrelation, so that the inter-dependencies among dynamic features and static baseline information can be effectively captured to form the personal health context. Experimental results on two real-world EMR datasets demonstrate the effectiveness of ConCare. The medical findings extracted by ConCare are also empirically confirmed by human experts and medical literature.
AdaCare: Explainable Clinical Health Status Representation Learning via Scale-Adaptive Feature Extraction and Recalibration
Nov 27, 2019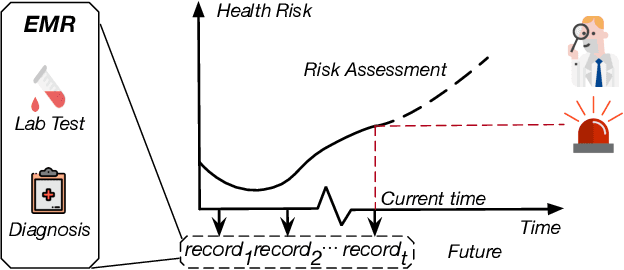

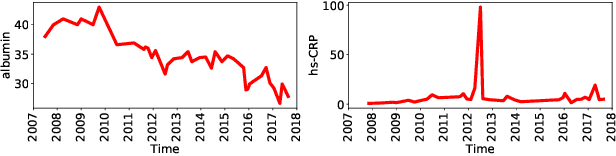
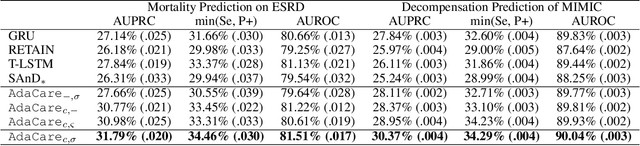
Deep learning-based health status representation learning and clinical prediction have raised much research interest in recent years. Existing models have shown superior performance, but there are still several major issues that have not been fully taken into consideration. First, the historical variation pattern of the biomarker in diverse time scales plays a vital role in indicating the health status, but it has not been explicitly extracted by existing works. Second, key factors that strongly indicate the health risk are different among patients. It is still challenging to adaptively make use of the features for patients in diverse conditions. Third, using prediction models as the black box will limit the reliability in clinical practice. However, none of the existing works can provide satisfying interpretability and meanwhile achieve high prediction performance. In this work, we develop a general health status representation learning model, named AdaCare. It can capture the long and short-term variations of biomarkers as clinical features to depict the health status in multiple time scales. It also models the correlation between clinical features to enhance the ones which strongly indicate the health status and thus can maintain a state-of-the-art performance in terms of prediction accuracy while providing qualitative interpretability. We conduct a health risk prediction experiment on two real-world datasets. Experiment results indicate that AdaCare outperforms state-of-the-art approaches and provides effective interpretability, which is verifiable by clinical experts.
Joint Concept Matching based Learning for Zero-Shot Recognition
Jul 03, 2019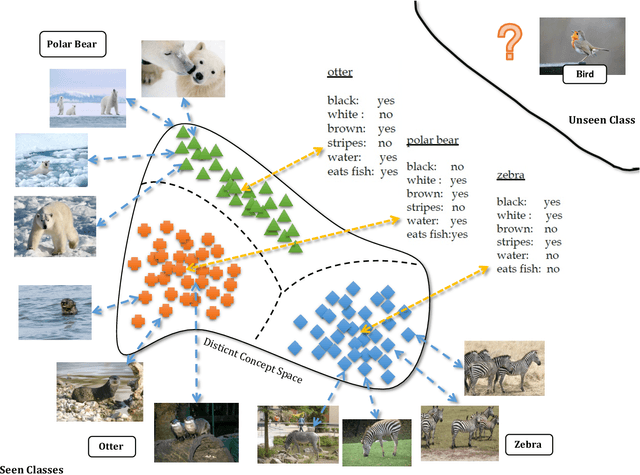
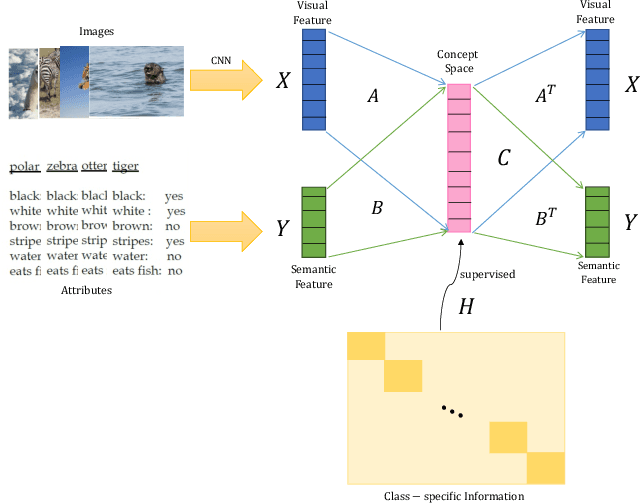
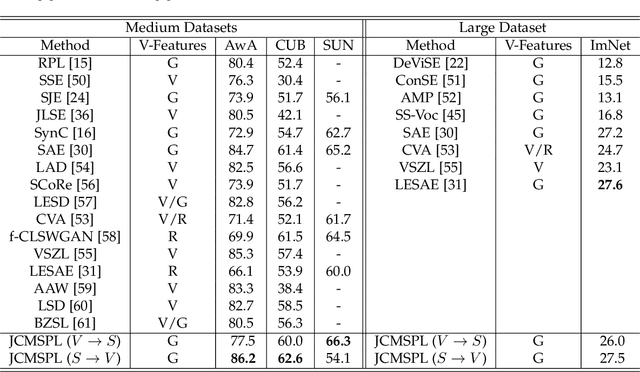
Zero-shot learning (ZSL) which aims to recognize unseen object classes by only training on seen object classes, has increasingly been of great interest in Machine Learning, and has registered with some successes. Most existing ZSL methods typically learn a projection map between the visual feature space and the semantic space and mainly suffer which is prone to a projection domain shift primarily due to a large domain gap between seen and unseen classes. In this paper, we propose a novel inductive ZSL model based on projecting both visual and semantic features into a common distinct latent space with class-specific knowledge, and on reconstructing both visual and semantic features by such a distinct common space to narrow the domain shift gap. We show that all these constraints on the latent space, class-specific knowledge, reconstruction of features and their combinations enhance the robustness against the projection domain shift problem, and improve the generalization ability to unseen object classes. Comprehensive experiments on four benchmark datasets demonstrate that our proposed method is superior to state-of-the-art algorithms.
MUSEFood: Multi-sensor-based Food Volume Estimation on Smartphones
Mar 19, 2019
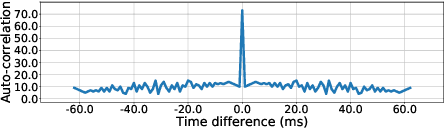
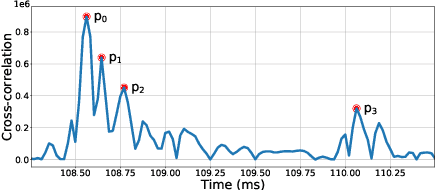
Researches have shown that diet recording can help people increase awareness of food intake and improve nutrition management, and thereby maintain a healthier life. Recently, researchers have been working on smartphone-based diet recording methods and applications that help users accomplish two tasks: record what they eat and how much they eat. Although the former task has made great progress through adopting image recognition technology, it is still a challenge to estimate the volume of foods accurately and conveniently. In this paper, we propose a novel method, named MUSEFood, for food volume estimation. MUSEFood uses the camera to capture photos of the food, but unlike existing volume measurement methods, MUSEFood requires neither training images with volume information nor placing a reference object of known size while taking photos. In addition, considering the impact of different containers on the contour shape of foods, MUSEFood uses a multi-task learning framework to improve the accuracy of food segmentation, and uses a differential model applicable for various containers to further reduce the negative impact of container differences on volume estimation accuracy. Furthermore, MUSEFood uses the microphone and the speaker to accurately measure the vertical distance from the camera to the food in a noisy environment, thus scaling the size of food in the image to its actual size. The experiments on real foods indicate that MUSEFood outperforms state-of-the-art approaches, and highly improves the speed of food volume estimation.
Analysis Dictionary Learning: An Efficient and Discriminative Solution
Mar 07, 2019
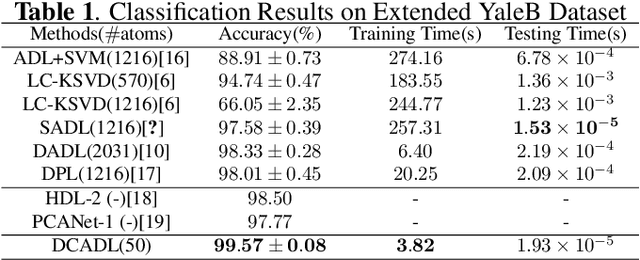
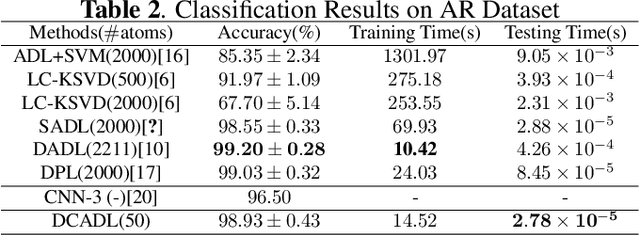

Discriminative Dictionary Learning (DL) methods have been widely advocated for image classification problems. To further sharpen their discriminative capabilities, most state-of-the-art DL methods have additional constraints included in the learning stages. These various constraints, however, lead to additional computational complexity. We hence propose an efficient Discriminative Convolutional Analysis Dictionary Learning (DCADL) method, as a lower cost Discriminative DL framework, to both characterize the image structures and refine the interclass structure representations. The proposed DCADL jointly learns a convolutional analysis dictionary and a universal classifier, while greatly reducing the time complexity in both training and testing phases, and achieving a competitive accuracy, thus demonstrating great performance in many experiments with standard databases.
Analysis Dictionary Learning based Classification: Structure for Robustness
Jul 13, 2018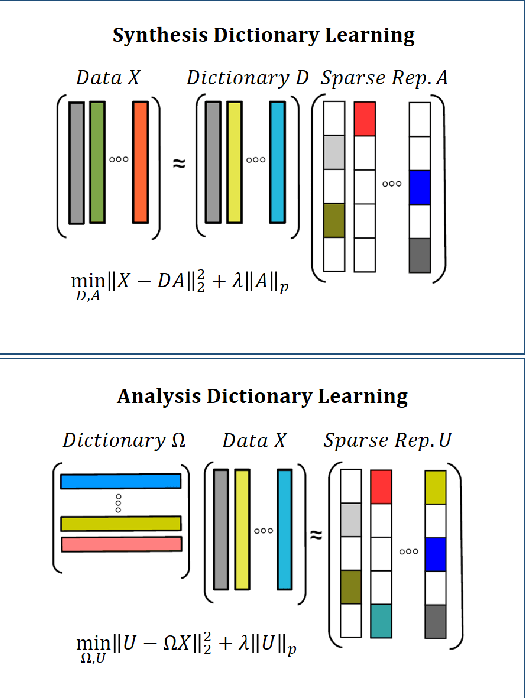
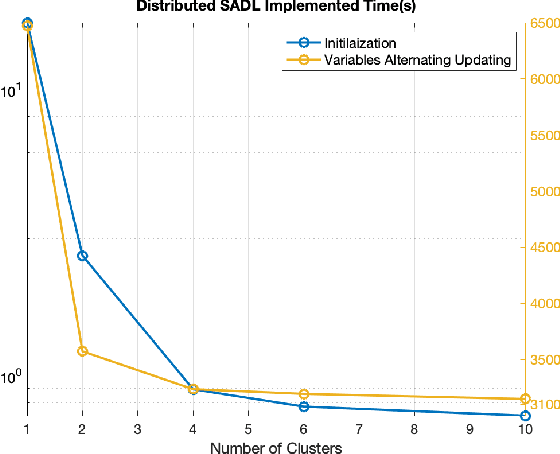


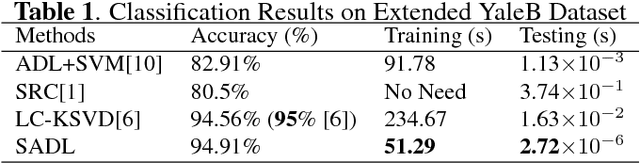
A discriminative structured analysis dictionary is proposed for the classification task. A structure of the union of subspaces (UoS) is integrated into the conventional analysis dictionary learning to enhance the capability of discrimination. A simple classifier is also simultaneously included into the formulated functional to ensure a more complete consistent classification. The solution of the algorithm is efficiently obtained by the linearized alternating direction method of multipliers. Moreover, a distributed structured analysis dictionary learning is also presented to address large scale datasets. It can group-(class-) independently train the structured analysis dictionaries by different machines/cores/threads, and therefore avoid a high computational cost. A consensus structured analysis dictionary and a global classifier are jointly learned in the distributed approach to safeguard the discriminative power and the efficiency of classification. Experiments demonstrate that our method achieves a comparable or better performance than the state-of-the-art algorithms in a variety of visual classification tasks. In addition, the training and testing computational complexity are also greatly reduced.
Structured Analysis Dictionary Learning for Image Classification
May 02, 2018
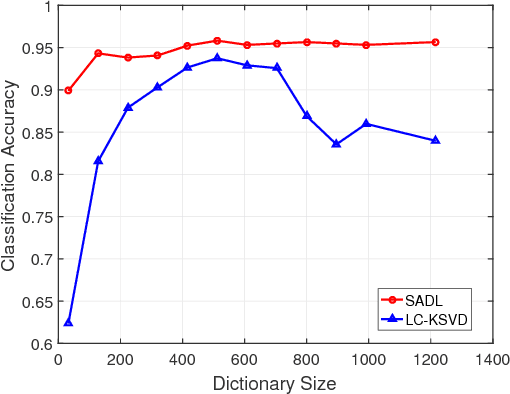
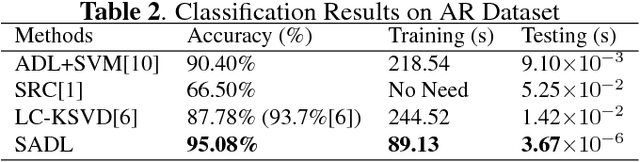
We propose a computationally efficient and high-performance classification algorithm by incorporating class structural information in analysis dictionary learning. To achieve more consistent classification, we associate a class characteristic structure of independent subspaces and impose it on the classification error constrained analysis dictionary learning. Experiments demonstrate that our method achieves a comparable or better performance than the state-of-the-art algorithms in a variety of visual classification tasks. In addition, our method greatly reduces the training and testing computational complexity.
Semantic Augmented Reality Environment with Material-Aware Physical Interactions
Mar 16, 2018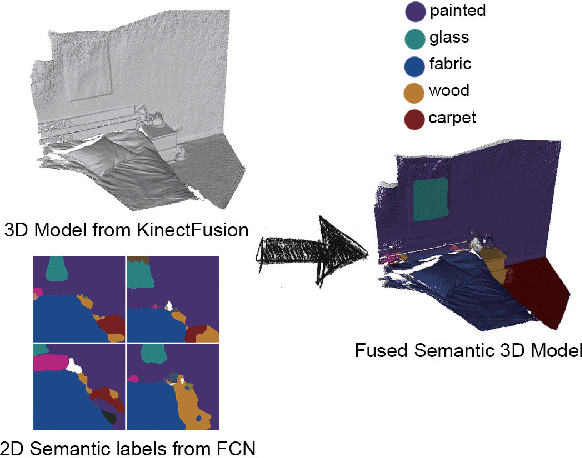

In Augmented Reality (AR) environment, realistic interactions between the virtual and real objects play a crucial role in user experience. Much of recent advances in AR has been largely focused on developing geometry-aware environment, but little has been done in dealing with interactions at the semantic level. High-level scene understanding and semantic descriptions in AR would allow effective design of complex applications and enhanced user experience. In this paper, we present a novel approach and a prototype system that enables the deeper understanding of semantic properties of the real world environment, so that realistic physical interactions between the real and the virtual objects can be generated. A material-aware AR environment has been created based on the deep material learning using a fully convolutional network (FCN). The state-of-the-art dense Simultaneous Localisation and Mapping (SLAM) has been used for the semantic mapping. Together with efficient accelerated 3D ray casting, natural and realistic physical interactions are generated for interactive AR games. Our approach has significant impact on the future development of advanced AR systems and applications.
Context-Aware Mixed Reality: A Framework for Ubiquitous Interaction
Mar 14, 2018
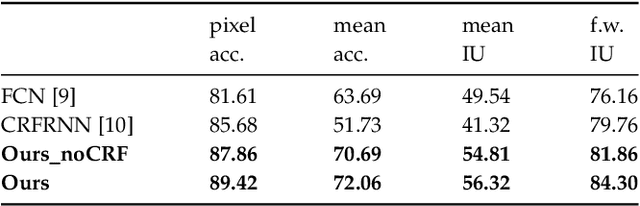
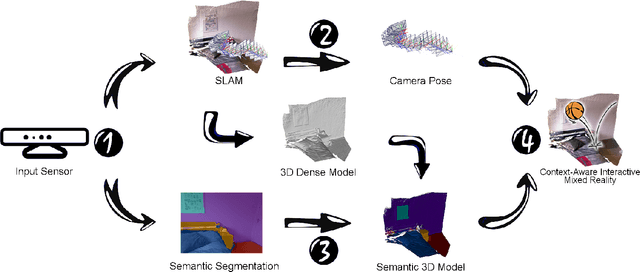
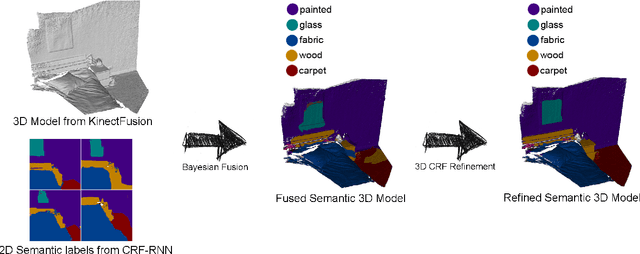
Mixed Reality (MR) is a powerful interactive technology that yields new types of user experience. We present a semantic based interactive MR framework that exceeds the current geometry level approaches, a step change in generating high-level context-aware interactions. Our key insight is to build semantic understanding in MR that not only can greatly enhance user experience through object-specific behaviours, but also pave the way for solving complex interaction design challenges. The framework generates semantic properties of the real world environment through dense scene reconstruction and deep image understanding. We demonstrate our approach with a material-aware prototype system for generating context-aware physical interactions between the real and the virtual objects. Quantitative and qualitative evaluations are carried out and the results show that the framework delivers accurate and fast semantic information in interactive MR environment, providing effective semantic level interactions.
Self-Supervised Monocular Image Depth Learning and Confidence Estimation
Mar 14, 2018
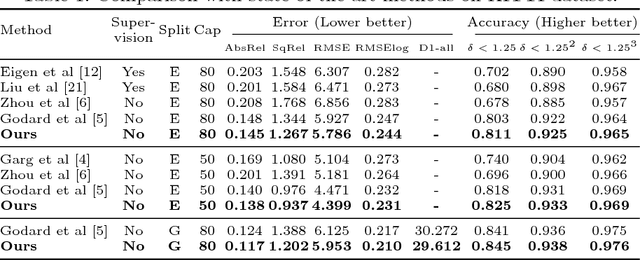
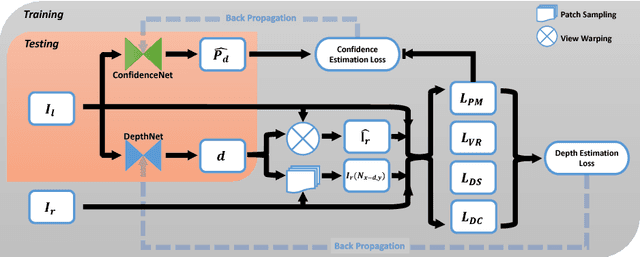
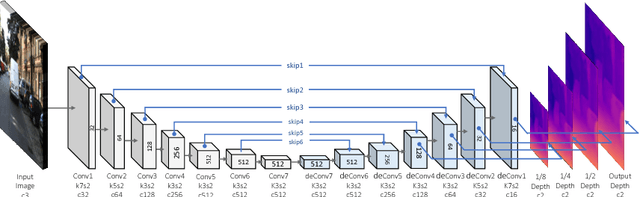
Convolutional Neural Networks (CNNs) need large amounts of data with ground truth annotation, which is a challenging problem that has limited the development and fast deployment of CNNs for many computer vision tasks. We propose a novel framework for depth estimation from monocular images with corresponding confidence in a self-supervised manner. A fully differential patch-based cost function is proposed by using the Zero-Mean Normalized Cross Correlation (ZNCC) that takes multi-scale patches as a matching strategy. This approach greatly increases the accuracy and robustness of the depth learning. In addition, the proposed patch-based cost function can provide a 0 to 1 confidence, which is then used to supervise the training of a parallel network for confidence map learning and estimation. Evaluation on KITTI dataset shows that our method outperforms the state-of-the-art results.