 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Search for Job Shop Scheduling via Deep Reinforcement Learning
Nov 27, 2022



Recent studies in using deep reinforcement learning (DRL) to solve Job-shop scheduling problems (JSSP) focus on construction heuristics. However, their performance is still far from optimality, mainly because the underlying graph representation scheme is unsuitable for modeling partial solutions at each construction step. This paper proposes a novel DRL-based method to learn improvement heuristics for JSSP, where graph representation is employed to encode complete solutions. We design a Graph Neural Network based representation scheme, consisting of two modules to effectively capture the information of dynamic topology and different types of nodes in graphs encountered during the improvement process. To speed up solution evaluation during improvement, we design a novel message-passing mechanism that can evaluate multiple solutions simultaneously. Extensive experiments on classic benchmarks show that the improvement policy learned by our method outperforms state-of-the-art DRL-based methods by a large margin.
Learning to Solve Multiple-TSP with Time Window and Rejections via Deep Reinforcement Learning
Sep 13, 2022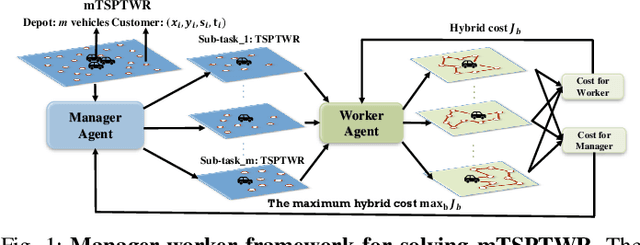
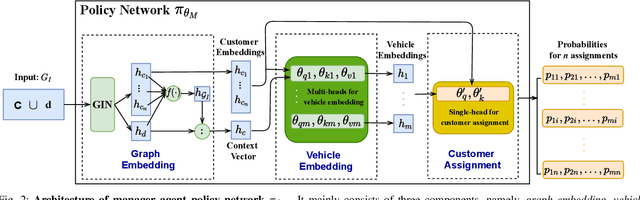
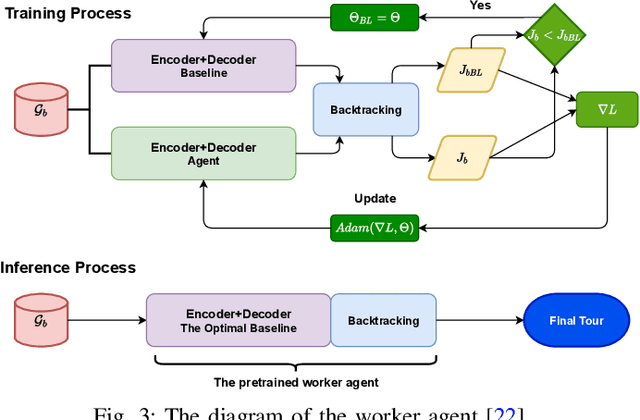
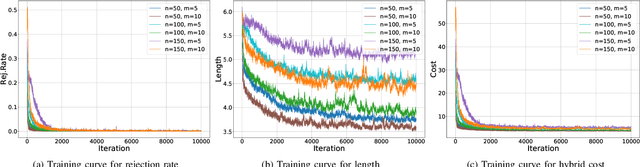
We propose a manager-worker framework based on deep reinforcement learning to tackle a hard yet nontrivial variant of Travelling Salesman Problem (TSP), \ie~multiple-vehicle TSP with time window and rejections (mTSPTWR), where customers who cannot be served before the deadline are subject to rejections. Particularly, in the proposed framework, a manager agent learns to divide mTSPTWR into sub-routing tasks by assigning customers to each vehicle via a Graph Isomorphism Network (GIN) based policy network. A worker agent learns to solve sub-routing tasks by minimizing the cost in terms of both tour length and rejection rate for each vehicle, the maximum of which is then fed back to the manager agent to learn better assignments. Experimental results demonstrate that the proposed framework outperforms strong baselines in terms of higher solution quality and shorter computation time. More importantly, the trained agents also achieve competitive performance for solving unseen larger instances.
Efficient Neural Neighborhood Search for Pickup and Delivery Problems
Apr 25, 2022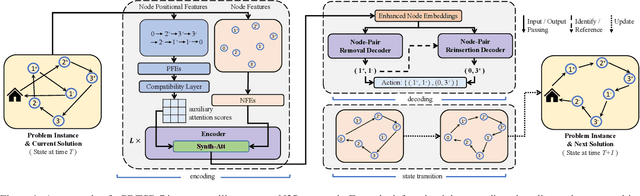


We present an efficient Neural Neighborhood Search (N2S) approach for pickup and delivery problems (PDPs). In specific, we design a powerful Synthesis Attention that allows the vanilla self-attention to synthesize various types of features regarding a route solution. We also exploit two customized decoders that automatically learn to perform removal and reinsertion of a pickup-delivery node pair to tackle the precedence constraint. Additionally, a diversity enhancement scheme is leveraged to further ameliorate the performance. Our N2S is generic, and extensive experiments on two canonical PDP variants show that it can produce state-of-the-art results among existing neural methods. Moreover, it even outstrips the well-known LKH3 solver on the more constrained PDP variant. Our implementation for N2S is available online.
Learning Large Neighborhood Search Policy for Integer Programming
Nov 01, 2021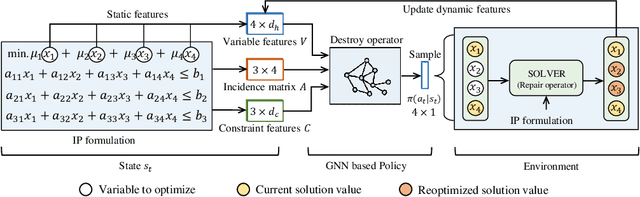

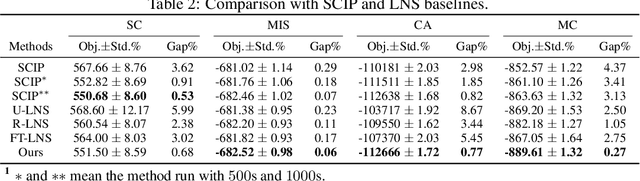
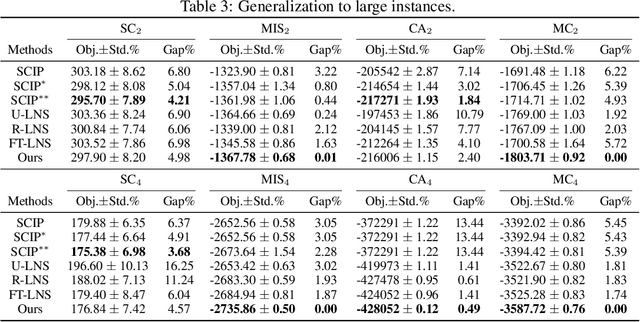
We propose a deep reinforcement learning (RL) method to learn large neighborhood search (LNS) policy for integer programming (IP). The RL policy is trained as the destroy operator to select a subset of variables at each step, which is reoptimized by an IP solver as the repair operator. However, the combinatorial number of variable subsets prevents direct application of typical RL algorithms. To tackle this challenge, we represent all subsets by factorizing them into binary decisions on each variable. We then design a neural network to learn policies for each variable in parallel, trained by a customized actor-critic algorithm. We evaluate the proposed method on four representative IP problems. Results show that it can find better solutions than SCIP in much less time, and significantly outperform other LNS baselines with the same runtime. Moreover, these advantages notably persist when the policies generalize to larger problems. Further experiments with Gurobi also reveal that our method can outperform this state-of-the-art commercial solver within the same time limit.
NeuroLKH: Combining Deep Learning Model with Lin-Kernighan-Helsgaun Heuristic for Solving the Traveling Salesman Problem
Oct 15, 2021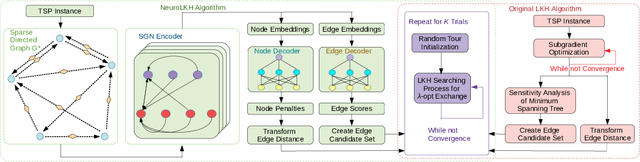
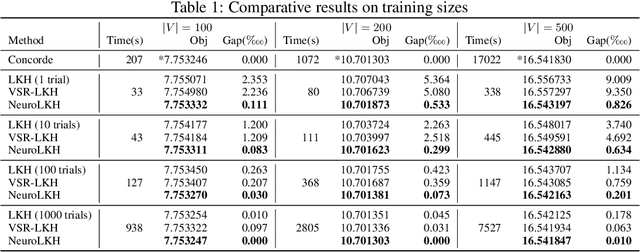
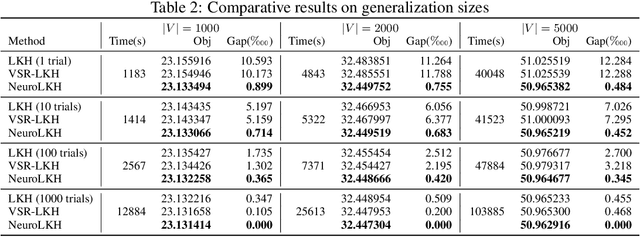
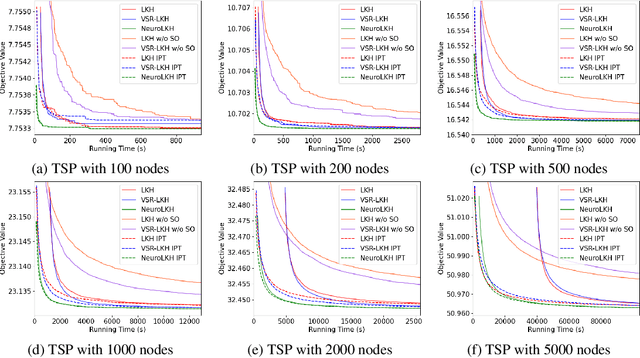
We present NeuroLKH, a novel algorithm that combines deep learning with the strong traditional heuristic Lin-Kernighan-Helsgaun (LKH) for solving Traveling Salesman Problem. Specifically, we train a Sparse Graph Network (SGN) with supervised learning for edge scores and unsupervised learning for node penalties, both of which are critical for improving the performance of LKH. Based on the output of SGN, NeuroLKH creates the edge candidate set and transforms edge distances to guide the searching process of LKH. Extensive experiments firmly demonstrate that, by training one model on a wide range of problem sizes, NeuroLKH significantly outperforms LKH and generalizes well to much larger sizes. Also, we show that NeuroLKH can be applied to other routing problems such as Capacitated Vehicle Routing Problem (CVRP), Pickup and Delivery Problem (PDP), and CVRP with Time Windows (CVRPTW).
Heterogeneous Attentions for Solving Pickup and Delivery Problem via Deep Reinforcement Learning
Oct 06, 2021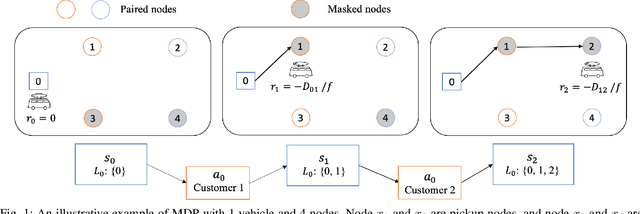
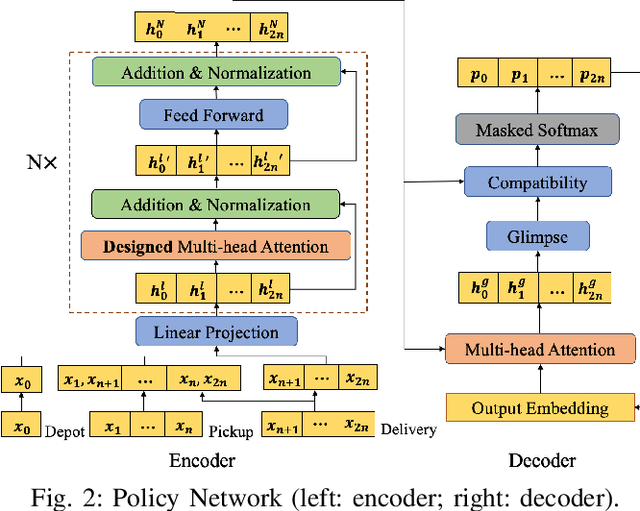
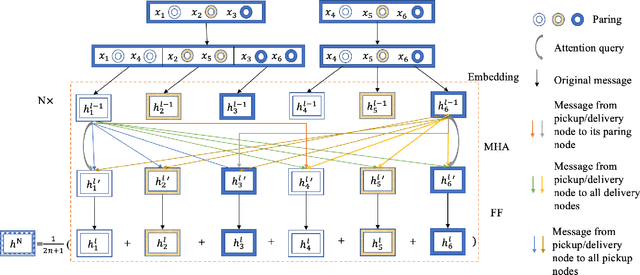
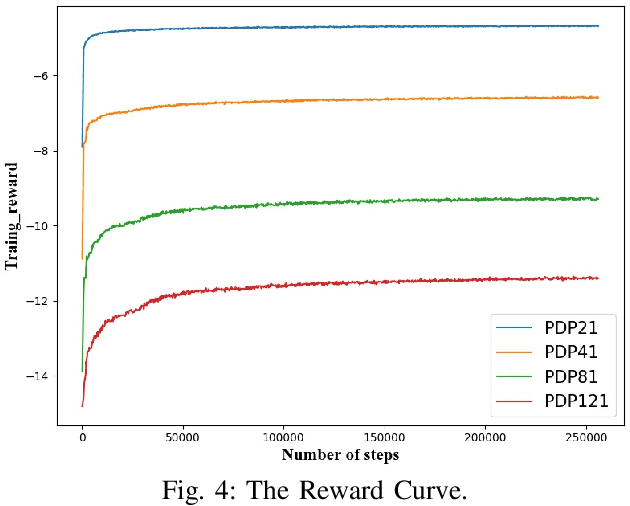
Recently, there is an emerging trend to apply deep reinforcement learning to solve the vehicle routing problem (VRP), where a learnt policy governs the selection of next node for visiting. However, existing methods could not handle well the pairing and precedence relationships in the pickup and delivery problem (PDP), which is a representative variant of VRP. To address this challenging issue, we leverage a novel neural network integrated with a heterogeneous attention mechanism to empower the policy in deep reinforcement learning to automatically select the nodes. In particular, the heterogeneous attention mechanism specifically prescribes attentions for each role of the nodes while taking into account the precedence constraint, i.e., the pickup node must precede the pairing delivery node. Further integrated with a masking scheme, the learnt policy is expected to find higher-quality solutions for solving PDP. Extensive experimental results show that our method outperforms the state-of-the-art heuristic and deep learning model, respectively, and generalizes well to different distributions and problem sizes.
Deep Reinforcement Learning for Solving the Heterogeneous Capacitated Vehicle Routing Problem
Oct 06, 2021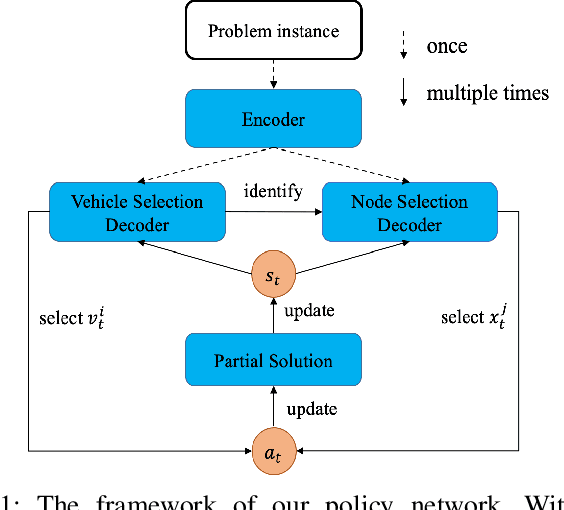
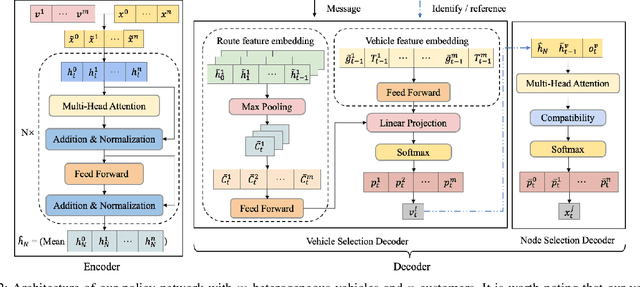
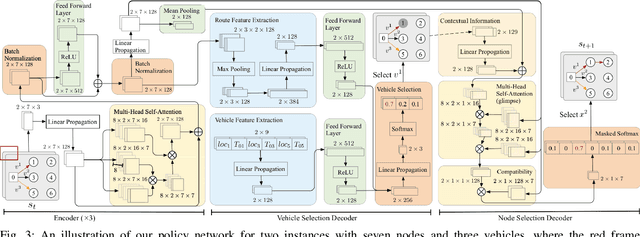
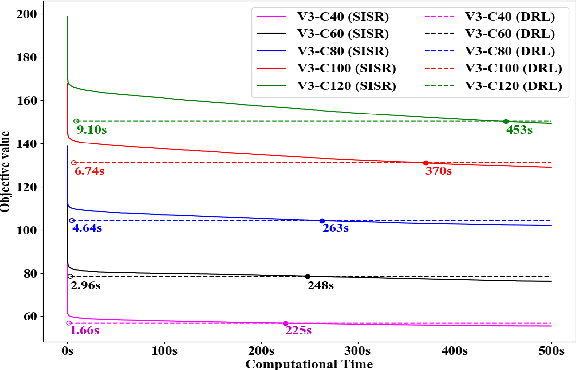
Existing deep reinforcement learning (DRL) based methods for solving the capacitated vehicle routing problem (CVRP) intrinsically cope with homogeneous vehicle fleet, in which the fleet is assumed as repetitions of a single vehicle. Hence, their key to construct a solution solely lies in the selection of the next node (customer) to visit excluding the selection of vehicle. However, vehicles in real-world scenarios are likely to be heterogeneous with different characteristics that affect their capacity (or travel speed), rendering existing DRL methods less effective. In this paper, we tackle heterogeneous CVRP (HCVRP), where vehicles are mainly characterized by different capacities. We consider both min-max and min-sum objectives for HCVRP, which aim to minimize the longest or total travel time of the vehicle(s) in the fleet. To solve those problems, we propose a DRL method based on the attention mechanism with a vehicle selection decoder accounting for the heterogeneous fleet constraint and a node selection decoder accounting for the route construction, which learns to construct a solution by automatically selecting both a vehicle and a node for this vehicle at each step. Experimental results based on randomly generated instances show that, with desirable generalization to various problem sizes, our method outperforms the state-of-the-art DRL method and most of the conventional heuristics, and also delivers competitive performance against the state-of-the-art heuristic method, i.e., SISR. Additionally, the results of extended experiments demonstrate that our method is also able to solve CVRPLib instances with satisfactory performance.
Learning to Iteratively Solve Routing Problems with Dual-Aspect Collaborative Transformer
Oct 06, 2021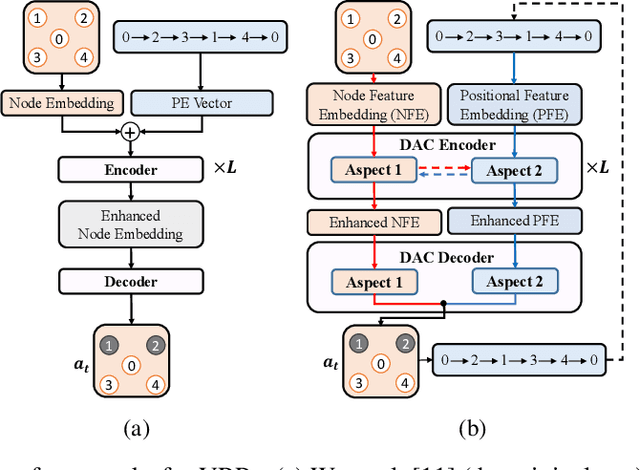
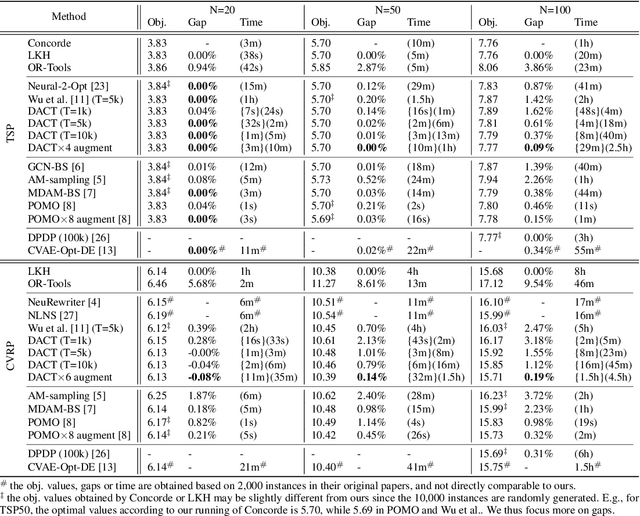

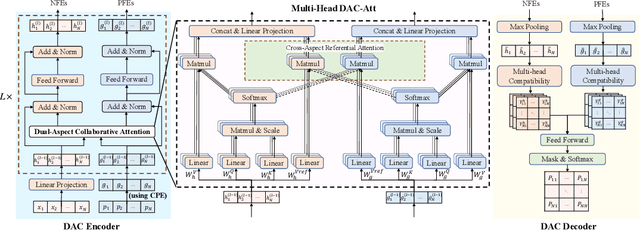
Recently, Transformer has become a prevailing deep architecture for solving vehicle routing problems (VRPs). However, it is less effective in learning improvement models for VRP because its positional encoding (PE) method is not suitable in representing VRP solutions. This paper presents a novel Dual-Aspect Collaborative Transformer (DACT) to learn embeddings for the node and positional features separately, instead of fusing them together as done in existing ones, so as to avoid potential noises and incompatible correlations. Moreover, the positional features are embedded through a novel cyclic positional encoding (CPE) method to allow Transformer to effectively capture the circularity and symmetry of VRP solutions (i.e., cyclic sequences). We train DACT using Proximal Policy Optimization and design a curriculum learning strategy for better sample efficiency. We apply DACT to solve the traveling salesman problem (TSP) and capacitated vehicle routing problem (CVRP). Results show that our DACT outperforms existing Transformer based improvement models, and exhibits much better generalization performance across different problem sizes on synthetic and benchmark instances, respectively.
Dual Aspect Self-Attention based on Transformer for Remaining Useful Life Prediction
Jun 30, 2021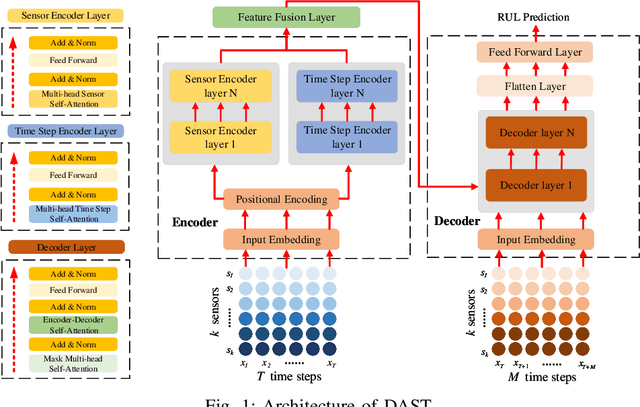
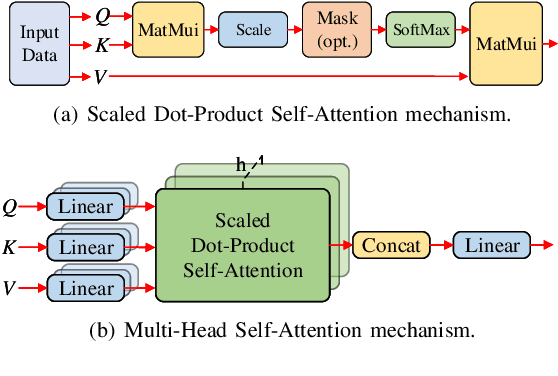
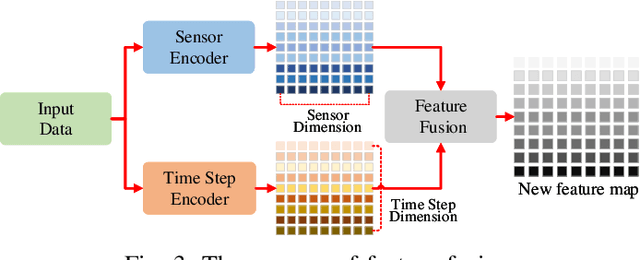
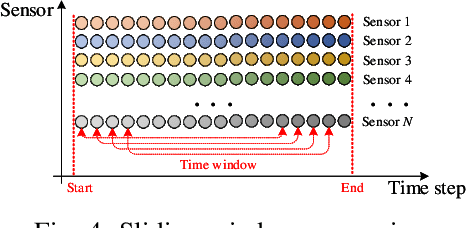
Remaining useful life prediction (RUL) is one of the key technologies of condition-based maintenance, which is important to maintain the reliability and safety of industrial equipments. While deep learning has achieved great success in RUL prediction, existing methods have difficulties in processing long sequences and extracting information from the sensor and time step aspects. In this paper, we propose Dual Aspect Self-attention based on Transformer (DAST), a novel deep RUL prediction method. DAST consists of two encoders, which work in parallel to simultaneously extract features of different sensors and time steps. Solely based on self-attention, the DAST encoders are more effective in processing long data sequences, and are capable of adaptively learning to focus on more important parts of input. Moreover, the parallel feature extraction design avoids mutual influence of information from two aspects. Experimental results on two real turbofan engine datasets show that our method significantly outperforms state-of-the-art methods.
Multi-Decoder Attention Model with Embedding Glimpse for Solving Vehicle Routing Problems
Dec 19, 2020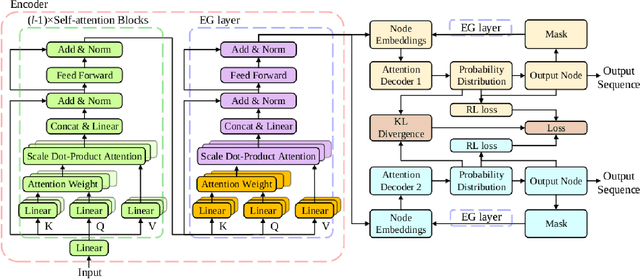
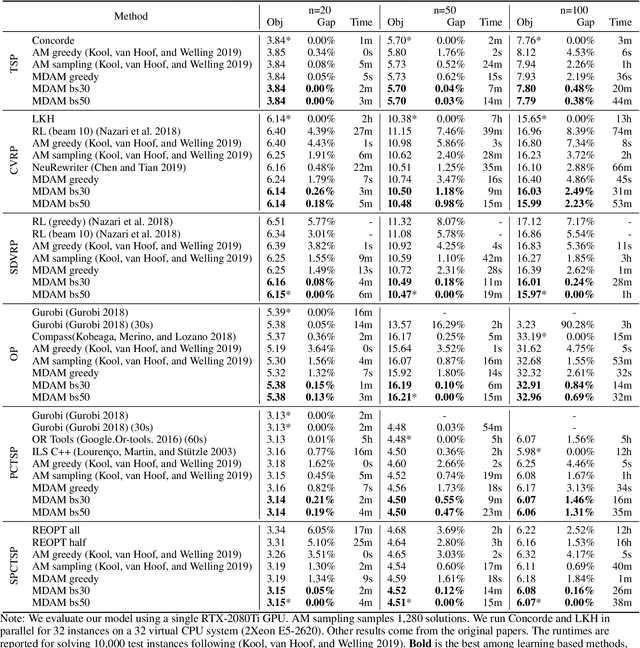
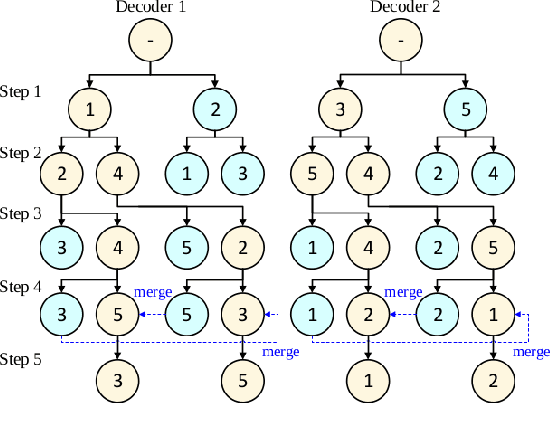
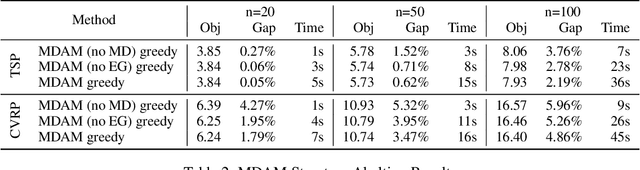
We present a novel deep reinforcement learning method to learn construction heuristics for vehicle routing problems. In specific, we propose a Multi-Decoder Attention Model (MDAM) to train multiple diverse policies, which effectively increases the chance of finding good solutions compared with existing methods that train only one policy. A customized beam search strategy is designed to fully exploit the diversity of MDAM. In addition, we propose an Embedding Glimpse layer in MDAM based on the recursive nature of construction, which can improve the quality of each policy by providing more informative embeddings. Extensive experiments on six different routing problems show that our method significantly outperforms the state-of-the-art deep learning based models.