 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSN: Range Sparse Net for Efficient, Accurate LiDAR 3D Object Detection
Jun 25, 2021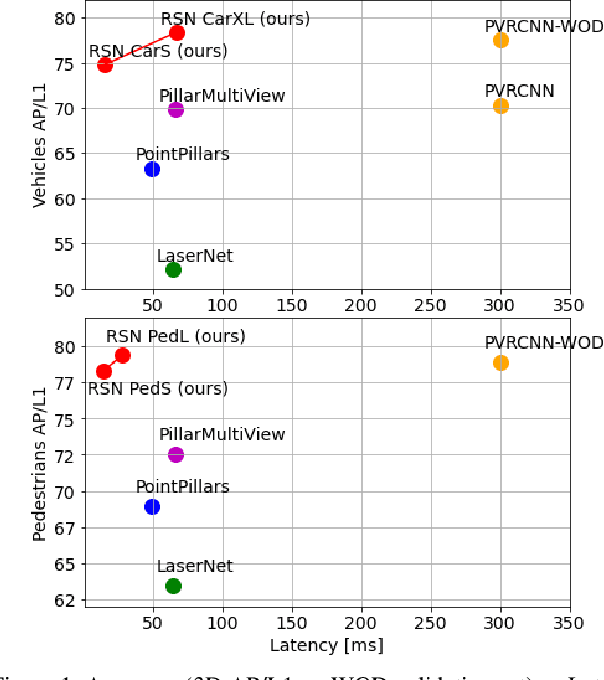
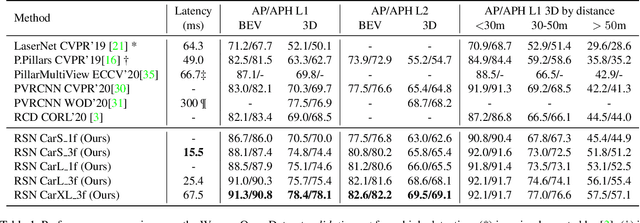
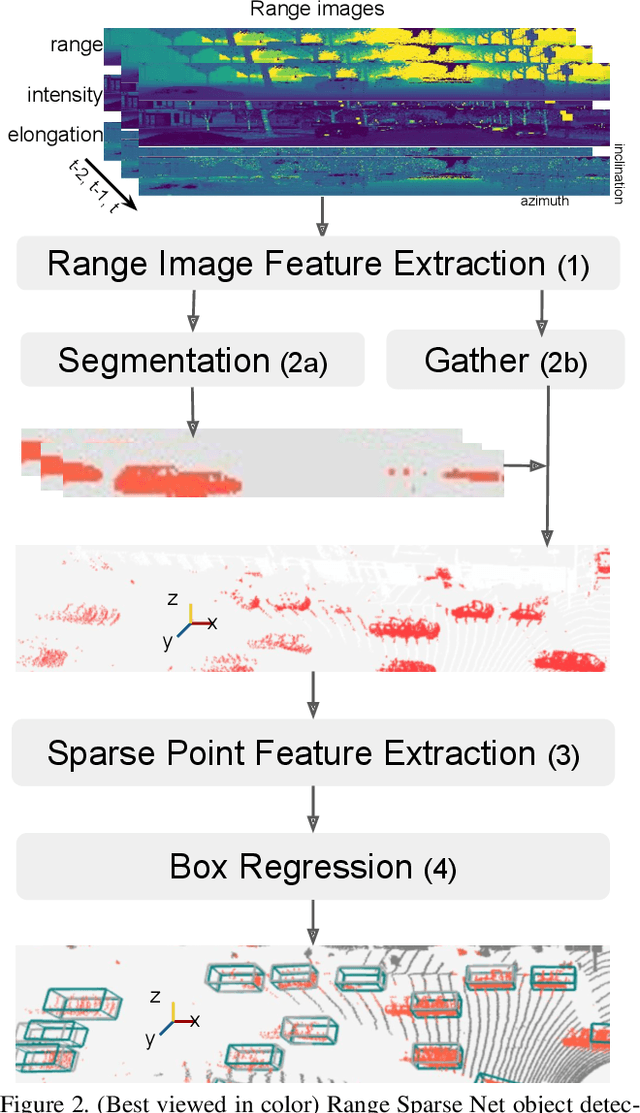
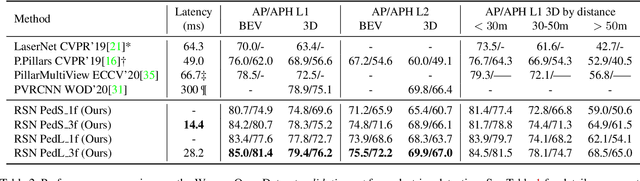
The detection of 3D objects from LiDAR data is a critical component in most autonomous driving systems. Safe, high speed driving needs larger detection ranges, which are enabled by new LiDARs. These larger detection ranges require more efficient and accurate detection models. Towards this goal, we propose Range Sparse Net (RSN), a simple, efficient, and accurate 3D object detector in order to tackle real time 3D object detection in this extended detection regime. RSN predicts foreground points from range images and applies sparse convolutions on the selected foreground points to detect objects. The lightweight 2D convolutions on dense range images results in significantly fewer selected foreground points, thus enabling the later sparse convolutions in RSN to efficiently operate. Combining features from the range image further enhance detection accuracy. RSN runs at more than 60 frames per second on a 150m x 150m detection region on Waymo Open Dataset (WOD) while being more accurate than previously published detectors. As of 11/2020, RSN is ranked first in the WOD leaderboard based on the APH/LEVEL 1 metrics for LiDAR-based pedestrian and vehicle detection, while being several times faster than alternatives.
Investigation of Large-Margin Softmax in Neural Language Modeling
May 20, 2020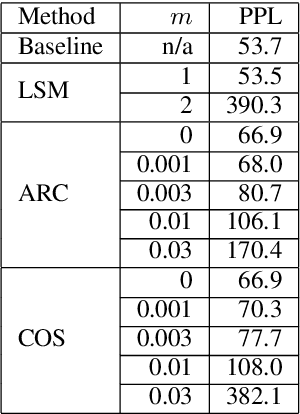
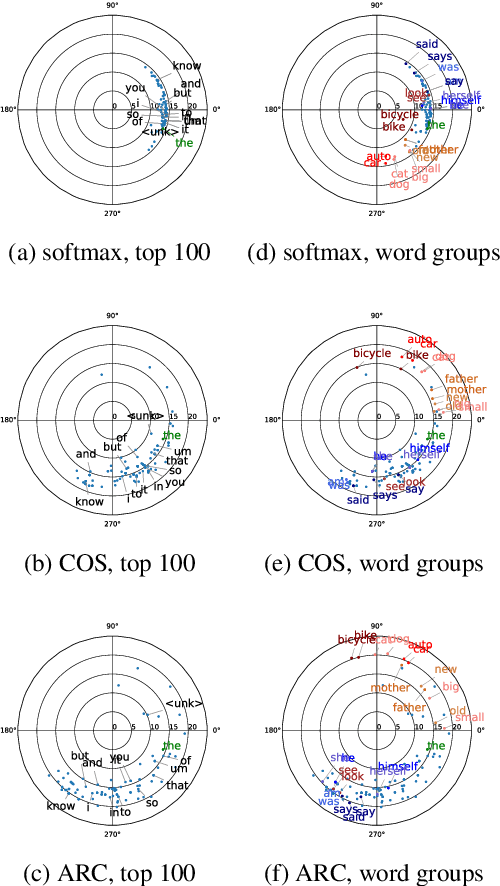
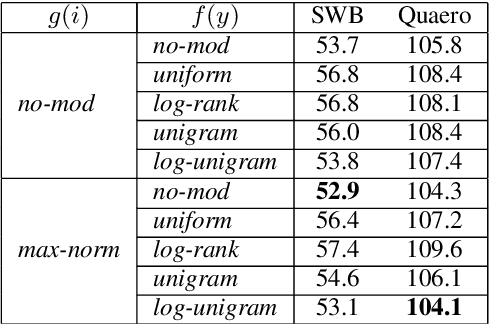
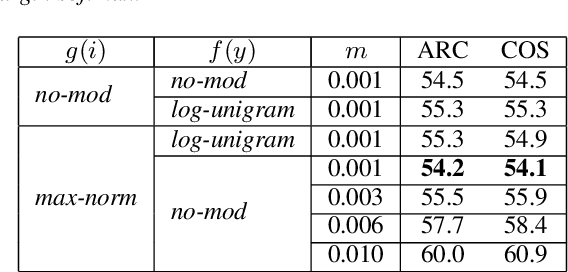
To encourage intra-class compactness and inter-class separability among trainable feature vectors, large-margin softmax methods are developed and widely applied in the face recognition community. The introduction of the large-margin concept into the softmax is reported to have good properties such as enhanced discriminative power, less overfitting and well-defined geometric intuitions. Nowadays, language modeling is commonly approached with neural networks using softmax and cross entropy. In this work, we are curious to see if introducing large-margins to neural language models would improve the perplexity and consequently word error rate in automatic speech recognition. Specifically, we first implement and test various types of conventional margins following the previous works in face recognition. To address the distribution of natural language data, we then compare different strategies for word vector norm-scaling. After that, we apply the best norm-scaling setup in combination with various margins and conduct neural language models rescoring experiments in automatic speech recognition. We find that although perplexity is slightly deteriorated, neural language models with large-margin softmax can yield word error rate similar to that of the standard softmax baseline. Finally, expected margins are analyzed through visualization of word vectors, showing that the syntactic and semantic relationships are also preserved.
Exploring Kernel Functions in the Softmax Layer for Contextual Word Classification
Oct 28, 2019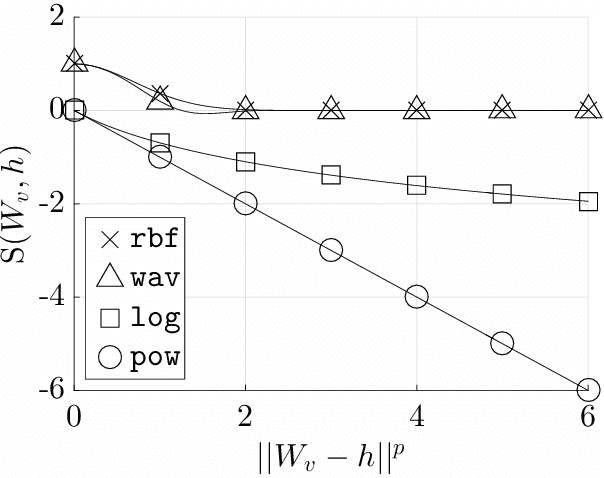
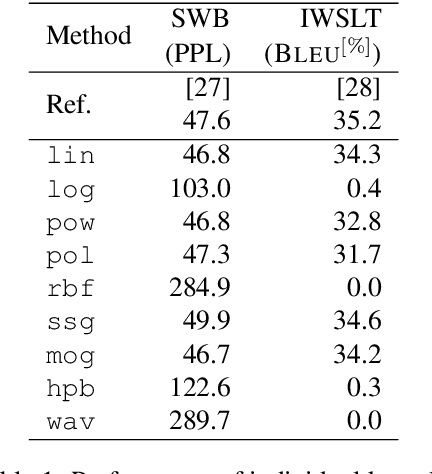
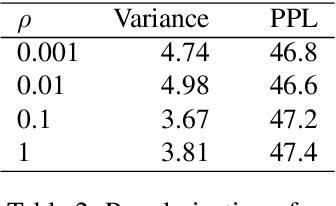

Prominently used in support vector machines and logistic regressions, kernel functions (kernels) can implicitly map data points into high dimensional spaces and make it easier to learn complex decision boundaries. In this work, by replacing the inner product function in the softmax layer, we explore the use of kernels for contextual word classification. In order to compare the individual kernels, experiments are conducted on standard language modeling and machine translation tasks. We observe a wide range of performances across different kernel settings. Extending the results, we look at the gradient properties, investigate various mixture strategies and examine the disambiguation abilities.
uniblock: Scoring and Filtering Corpus with Unicode Block Information
Aug 26, 2019
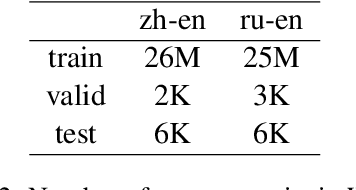
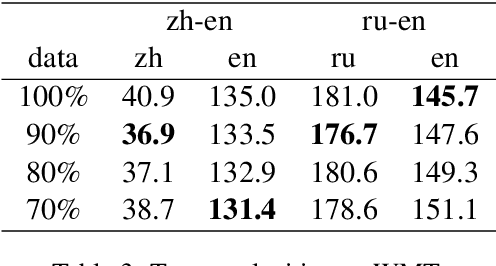
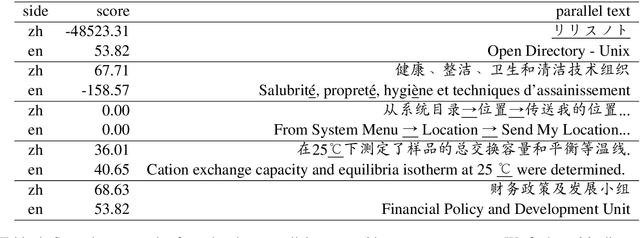
The preprocessing pipelines in Natural Language Processing usually involve a step of removing sentences consisted of illegal characters. The definition of illegal characters and the specific removal strategy depend on the task, language, domain, etc, which often lead to tiresome and repetitive scripting of rules. In this paper, we introduce a simple statistical method, uniblock, to overcome this problem. For each sentence, uniblock generates a fixed-size feature vector using Unicode block information of the characters. A Gaussian mixture model is then estimated on some clean corpus using variational inference. The learned model can then be used to score sentences and filter corpus. We present experimental results on Sentiment Analysis, Language Modeling and Machine Translation, and show the simplicity and effectiveness of our method.
DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction
May 26, 2019
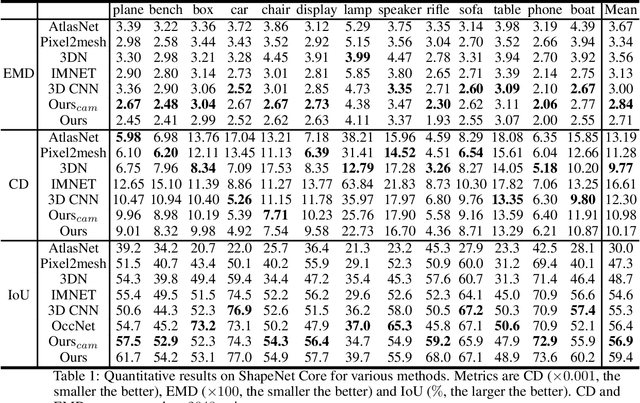
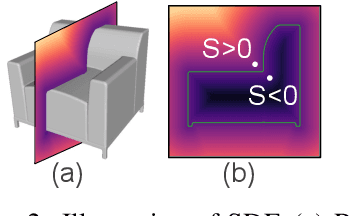
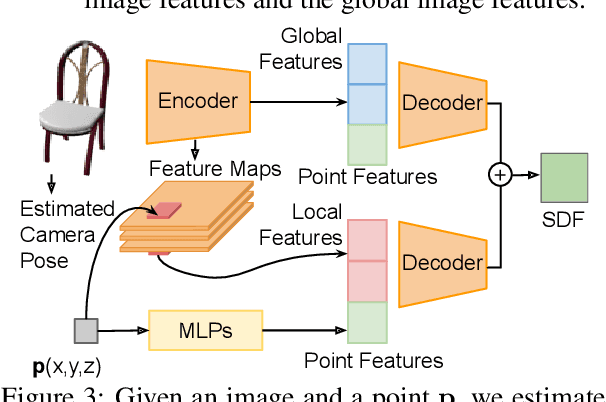
Reconstructing 3D shapes from single-view images has been a long-standing research problem and has attracted a lot of attention. In this paper, we present DISN, a Deep Implicit Surface Network that generates a high-quality 3D shape given an input image by predicting the underlying signed distance field. In addition to utilizing global image features, DISN also predicts the local image patch each 3D point sample projects onto and extracts local features from the patch. Combining global and local features significantly improves the accuracy of the predicted signed distance field. To the best of our knowledge, DISN is the first method that constantly captures details such as holes and thin structures present in 3D shapes from single-view images. DISN achieves state-of-the-art single-view reconstruction performance on a variety of shape categories reconstructed from both synthetic and real images. Code is available at github.com/laughtervv/DISN.
3DN: 3D Deformation Network
Mar 08, 2019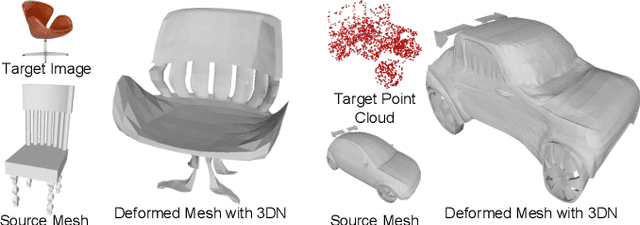
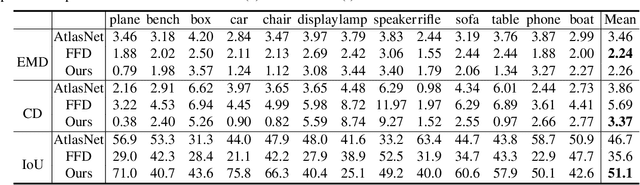
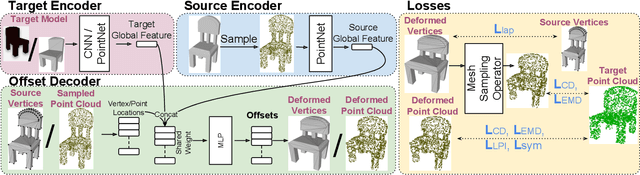
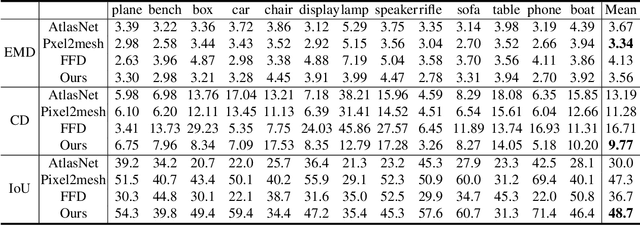
Applications in virtual and augmented reality create a demand for rapid creation and easy access to large sets of 3D models. An effective way to address this demand is to edit or deform existing 3D models based on a reference, e.g., a 2D image which is very easy to acquire. Given such a source 3D model and a target which can be a 2D image, 3D model, or a point cloud acquired as a depth scan, we introduce 3DN, an end-to-end network that deforms the source model to resemble the target. Our method infers per-vertex offset displacements while keeping the mesh connectivity of the source model fixed. We present a training strategy which uses a novel differentiable operation, mesh sampling operator, to generalize our method across source and target models with varying mesh densities. Mesh sampling operator can be seamlessly integrated into the network to handle meshes with different topologies. Qualitative and quantitative results show that our method generates higher quality results compared to the state-of-the art learning-based methods for 3D shape generation. Code is available at github.com/laughtervv/3DN.
Stochastic Video Long-term Interpolation
Sep 07, 2018
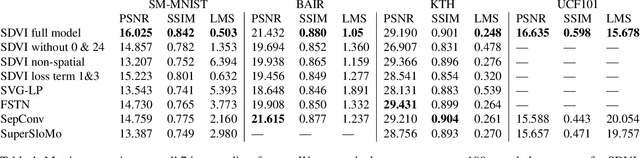
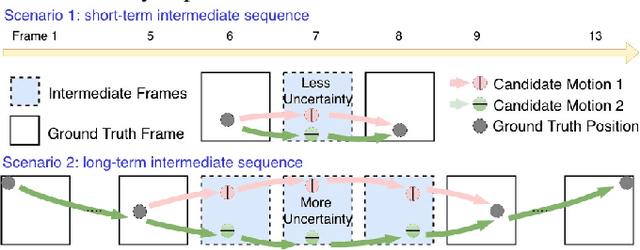
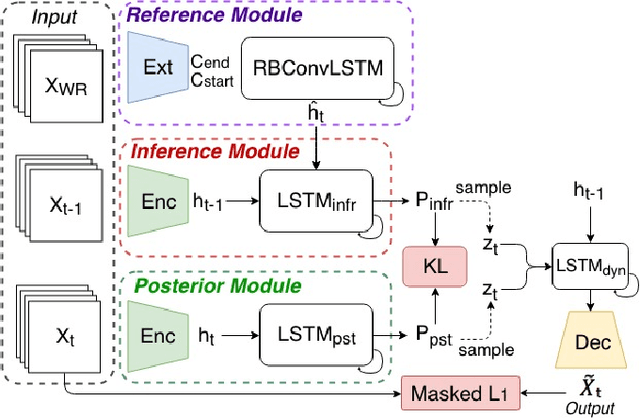
In this paper, we introduce a stochastic learning framework for long-term video interpolation. While most existing interpolation models require two reference frames with a short interval, our framework predicts a plausible intermediate sequence between a long interval. Our model consists of two parts: (1) a deterministic estimation to guarantee the spatial and temporal coherency among frames, (2) a stochastic sampling process to generate dynamics from inferred distributions. Experimental results show that our model is able to generate sharp and clear sequences with variations. Moreover, motions in the generated sequence are realistic and able to transfer smoothly from the referenced start frame to the end frame.
Recurrent Slice Networks for 3D Segmentation of Point Clouds
Mar 29, 2018

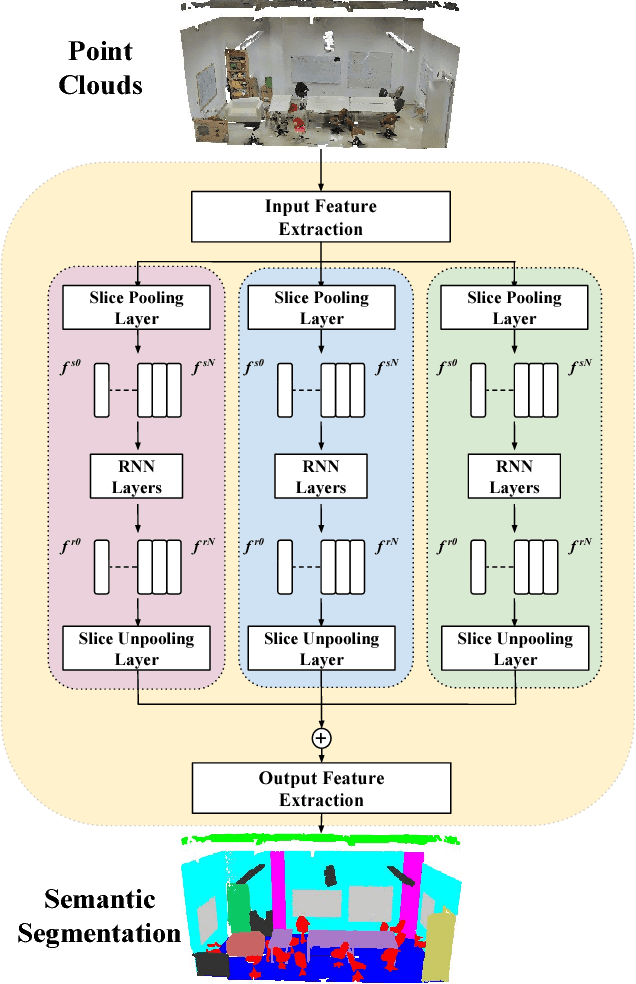
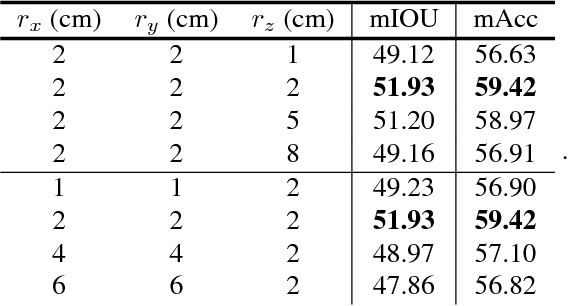
Point clouds are an efficient data format for 3D data. However, existing 3D segmentation methods for point clouds either do not model local dependencies \cite{pointnet} or require added computations \cite{kd-net,pointnet2}. This work presents a novel 3D segmentation framework, RSNet\footnote{Codes are released here https://github.com/qianguih/RSNet}, to efficiently model local structures in point clouds. The key component of the RSNet is a lightweight local dependency module. It is a combination of a novel slice pooling layer, Recurrent Neural Network (RNN) layers, and a slice unpooling layer. The slice pooling layer is designed to project features of unordered points onto an ordered sequence of feature vectors so that traditional end-to-end learning algorithms (RNNs) can be applied. The performance of RSNet is validated by comprehensive experiments on the S3DIS\cite{stanford}, ScanNet\cite{scannet}, and ShapeNet \cite{shapenet} datasets. In its simplest form, RSNets surpass all previous state-of-the-art methods on these benchmarks. And comparisons against previous state-of-the-art methods \cite{pointnet, pointnet2} demonstrate the efficiency of RSNets.
Depth-aware CNN for RGB-D Segmentation
Mar 19, 2018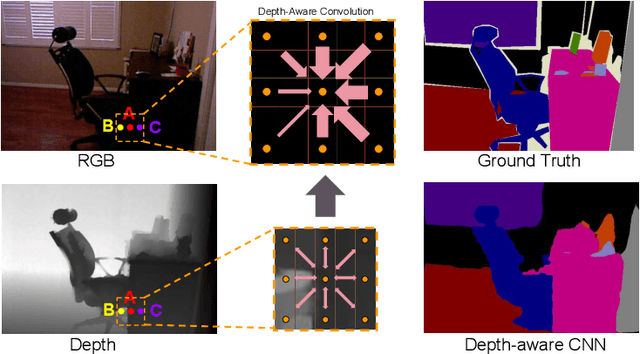

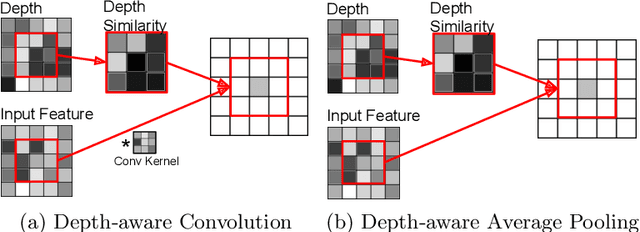
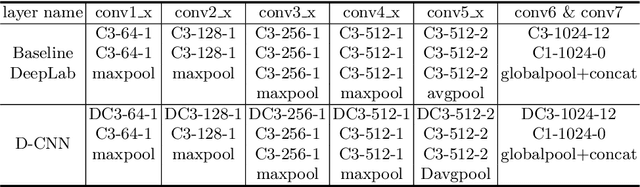
Convolutional neural networks (CNN) are limited by the lack of capability to handle geometric information due to the fixed grid kernel structure. The availability of depth data enables progress in RGB-D semantic segmentation with CNNs. State-of-the-art methods either use depth as additional images or process spatial information in 3D volumes or point clouds. These methods suffer from high computation and memory cost. To address these issues, we present Depth-aware CNN by introducing two intuitive, flexible and effective operations: depth-aware convolution and depth-aware average pooling. By leveraging depth similarity between pixels in the process of information propagation, geometry is seamlessly incorporated into CNN. Without introducing any additional parameters, both operators can be easily integrated into existing CNNs. Extensive experiments and ablation studies on challenging RGB-D semantic segmentation benchmarks validate the effectiveness and flexibility of our approach.
SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation
Nov 23, 2017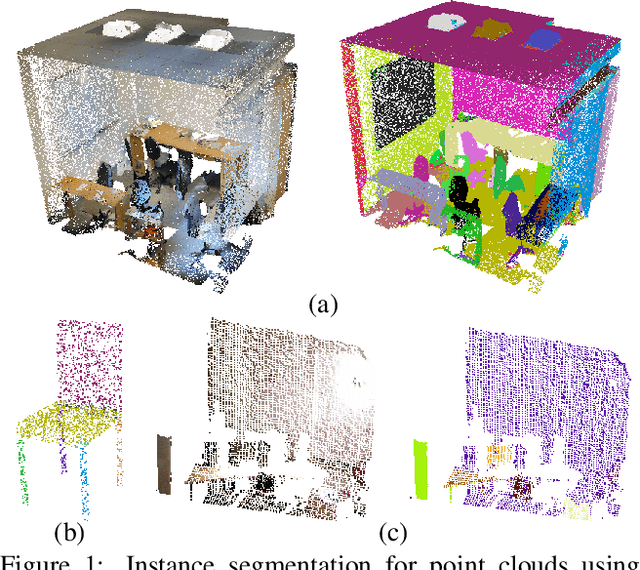

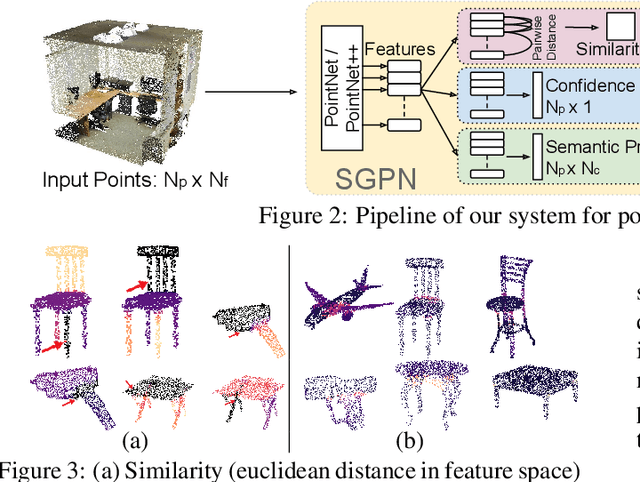

We introduce Similarity Group Proposal Network (SGPN), a simple and intuitive deep learning framework for 3D object instance segmentation on point clouds. SGPN uses a single network to predict point grouping proposals and a corresponding semantic class for each proposal, from which we can directly extract instance segmentation results. Important to the effectiveness of SGPN is its novel representation of 3D instance segmentation results in the form of a similarity matrix that indicates the similarity between each pair of points in embedded feature space, thus producing an accurate grouping proposal for each point. To the best of our knowledge, SGPN is the first framework to learn 3D instance-aware semantic segmentation on point clouds. Experimental results on various 3D scenes show the effectiveness of our method on 3D instance segmentation, and we also evaluate the capability of SGPN to improve 3D object detection and semantic segmentation results. We also demonstrate its flexibility by seamlessly incorporating 2D CNN features into the framework to boost performance.