 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts
Feb 14, 2022

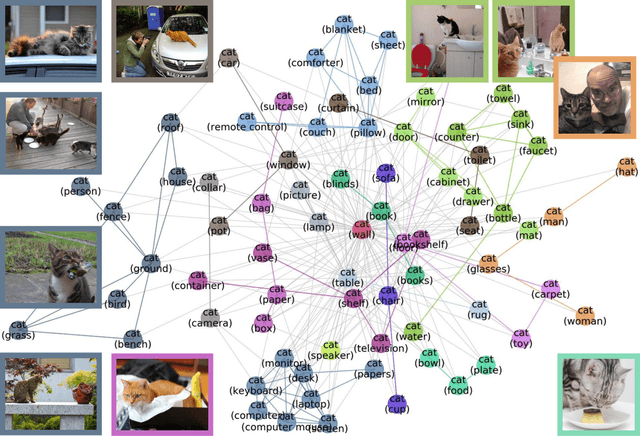
Understanding the performance of machine learning models across diverse data distributions is critically important for reliable applications. Motivated by this, there is a growing focus on curating benchmark datasets that capture distribution shifts. While valuable, the existing benchmarks are limited in that many of them only contain a small number of shifts and they lack systematic annotation about what is different across different shifts. We present MetaShift--a collection of 12,868 sets of natural images across 410 classes--to address this challenge. We leverage the natural heterogeneity of Visual Genome and its annotations to construct MetaShift. The key construction idea is to cluster images using its metadata, which provides context for each image (e.g. "cats with cars" or "cats in bathroom") that represent distinct data distributions. MetaShift has two important benefits: first, it contains orders of magnitude more natural data shifts than previously available. Second, it provides explicit explanations of what is unique about each of its data sets and a distance score that measures the amount of distribution shift between any two of its data sets. We demonstrate the utility of MetaShift in benchmarking several recent proposals for training models to be robust to data shifts. We find that the simple empirical risk minimization performs the best when shifts are moderate and no method had a systematic advantage for large shifts. We also show how MetaShift can help to visualize conflicts between data subsets during model training.
Improving Out-of-Distribution Robustness via Selective Augmentation
Jan 02, 2022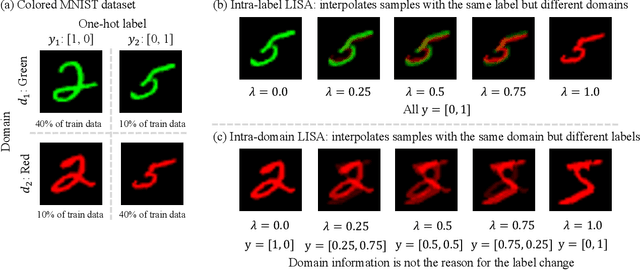
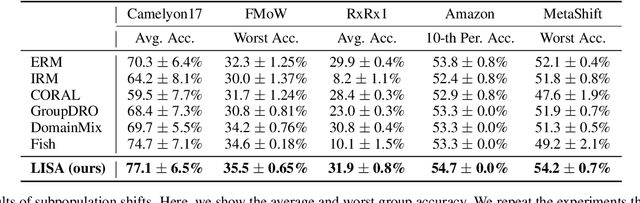
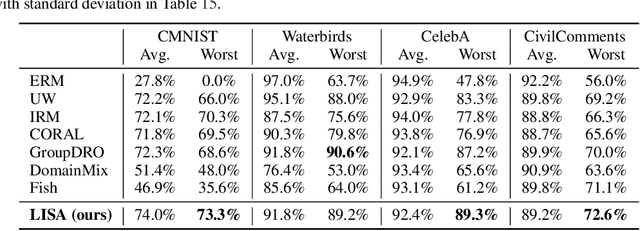
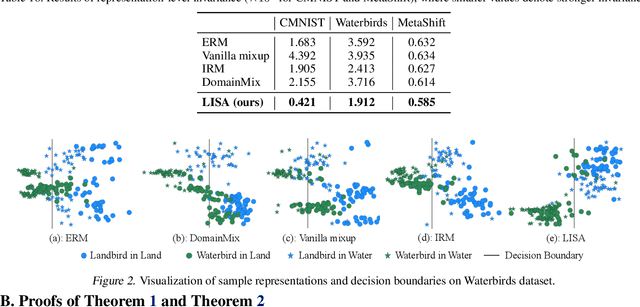
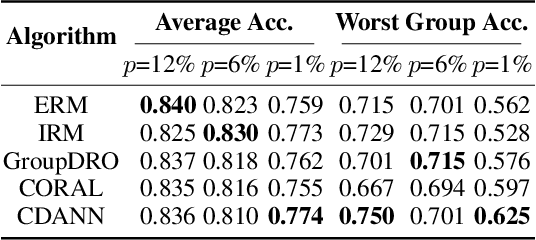
Machine learning algorithms typically assume that training and test examples are drawn from the same distribution. However, distribution shift is a common problem in real-world applications and can cause models to perform dramatically worse at test time. In this paper, we specifically consider the problems of domain shifts and subpopulation shifts (eg. imbalanced data). While prior works often seek to explicitly regularize internal representations and predictors of the model to be domain invariant, we instead aim to regularize the whole function without restricting the model's internal representations. This leads to a simple mixup-based technique which learns invariant functions via selective augmentation called LISA. LISA selectively interpolates samples either with the same labels but different domains or with the same domain but different labels. We analyze a linear setting and theoretically show how LISA leads to a smaller worst-group error. Empirically, we study the effectiveness of LISA on nine benchmarks ranging from subpopulation shifts to domain shifts, and we find that LISA consistently outperforms other state-of-the-art methods.
Disparities in Dermatology AI: Assessments Using Diverse Clinical Images
Nov 15, 2021
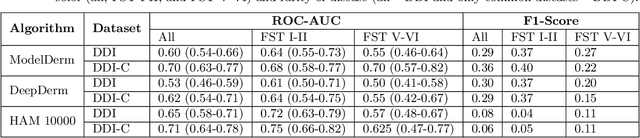

More than 3 billion people lack access to care for skin disease. AI diagnostic tools may aid in early skin cancer detection; however most models have not been assessed on images of diverse skin tones or uncommon diseases. To address this, we curated the Diverse Dermatology Images (DDI) dataset - the first publicly available, pathologically confirmed images featuring diverse skin tones. We show that state-of-the-art dermatology AI models perform substantially worse on DDI, with ROC-AUC dropping 29-40 percent compared to the models' original results. We find that dark skin tones and uncommon diseases, which are well represented in the DDI dataset, lead to performance drop-offs. Additionally, we show that state-of-the-art robust training methods cannot correct for these biases without diverse training data. Our findings identify important weaknesses and biases in dermatology AI that need to be addressed to ensure reliable application to diverse patients and across all disease.
HERALD: An Annotation Efficient Method to Detect User Disengagement in Social Conversations
Jun 02, 2021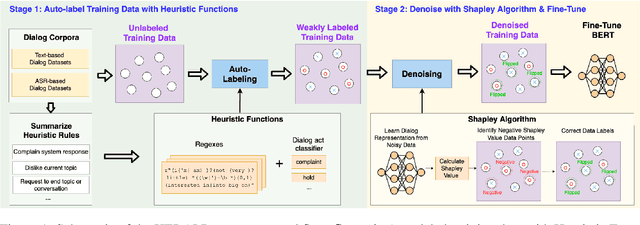
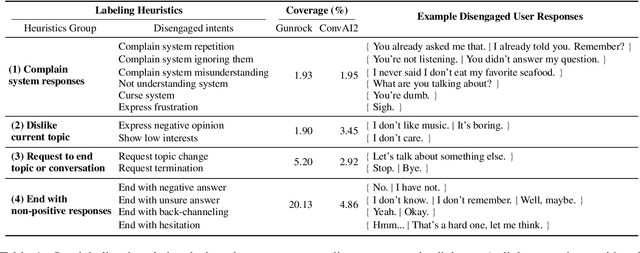
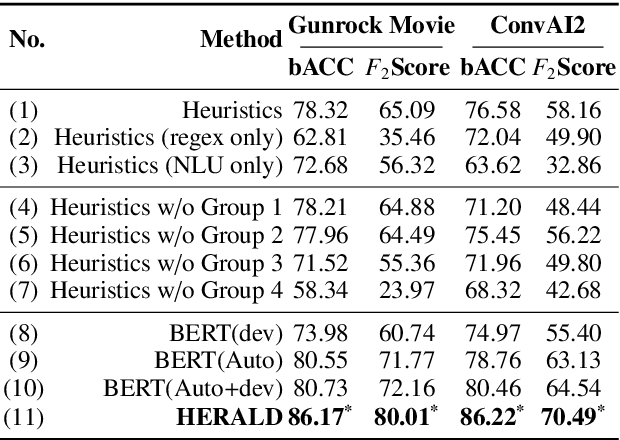
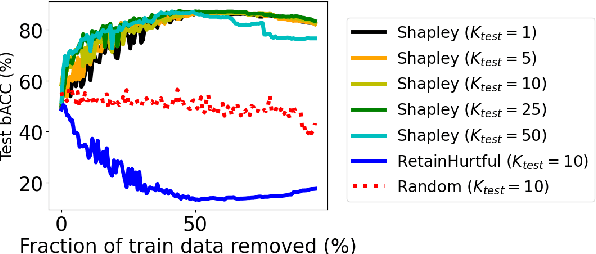
Open-domain dialog systems have a user-centric goal: to provide humans with an engaging conversation experience. User engagement is one of the most important metrics for evaluating open-domain dialog systems, and could also be used as real-time feedback to benefit dialog policy learning. Existing work on detecting user disengagement typically requires hand-labeling many dialog samples. We propose HERALD, an efficient annotation framework that reframes the training data annotation process as a denoising problem. Specifically, instead of manually labeling training samples, we first use a set of labeling heuristics to label training samples automatically. We then denoise the weakly labeled data using the Shapley algorithm. Finally, we use the denoised data to train a user engagement detector. Our experiments show that HERALD improves annotation efficiency significantly and achieves 86% user disengagement detection accuracy in two dialog corpora.
GraghVQA: Language-Guided Graph Neural Networks for Graph-based Visual Question Answering
Apr 20, 2021
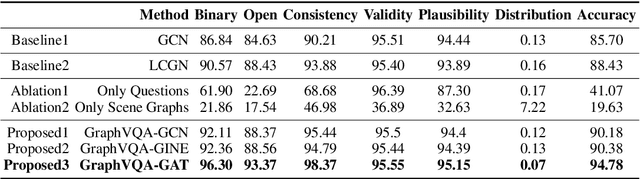
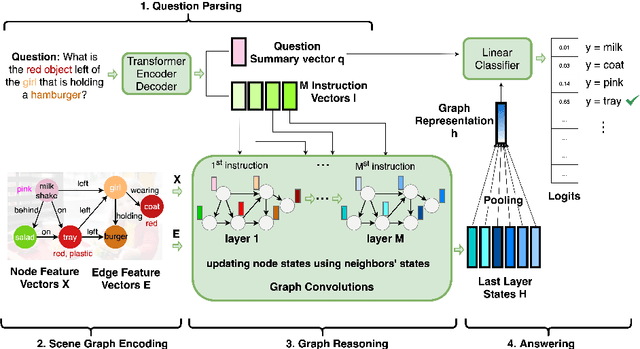

Images are more than a collection of objects or attributes -- they represent a web of relationships among interconnected objects. Scene Graph has emerged as a new modality as a structured graphical representation of images. Scene Graph encodes objects as nodes connected via pairwise relations as edges. To support question answering on scene graphs, we propose GraphVQA, a language-guided graph neural network framework that translates and executes a natural language question as multiple iterations of message passing among graph nodes. We explore the design space of GraphVQA framework, and discuss the trade-off of different design choices. Our experiments on GQA dataset show that GraphVQA outperforms the state-of-the-art accuracy by a large margin (88.43% vs. 94.78%).
LRTA: A Transparent Neural-Symbolic Reasoning Framework with Modular Supervision for Visual Question Answering
Nov 21, 2020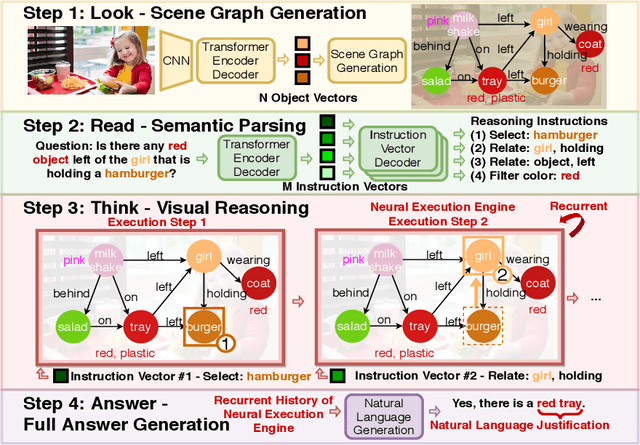
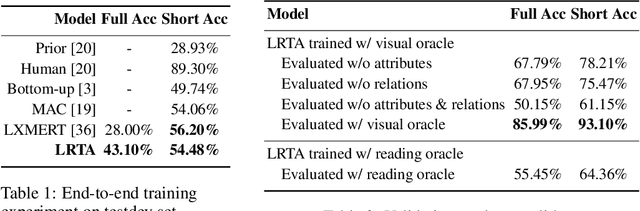
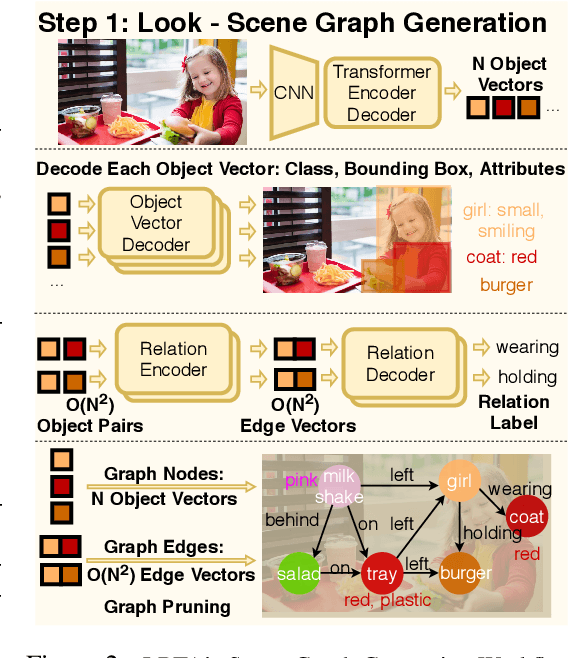
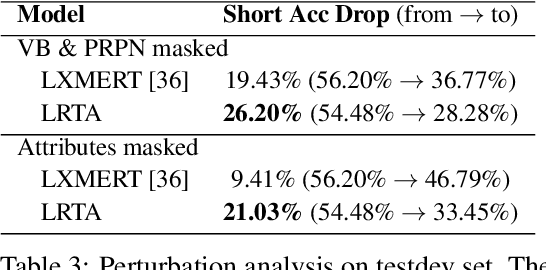
The predominant approach to visual question answering (VQA) relies on encoding the image and question with a "black-box" neural encoder and decoding a single token as the answer like "yes" or "no". Despite this approach's strong quantitative results, it struggles to come up with intuitive, human-readable forms of justification for the prediction process. To address this insufficiency, we reformulate VQA as a full answer generation task, which requires the model to justify its predictions in natural language. We propose LRTA [Look, Read, Think, Answer], a transparent neural-symbolic reasoning framework for visual question answering that solves the problem step-by-step like humans and provides human-readable form of justification at each step. Specifically, LRTA learns to first convert an image into a scene graph and parse a question into multiple reasoning instructions. It then executes the reasoning instructions one at a time by traversing the scene graph using a recurrent neural-symbolic execution module. Finally, it generates a full answer to the given question with natural language justifications. Our experiments on GQA dataset show that LRTA outperforms the state-of-the-art model by a large margin (43.1% v.s. 28.0%) on the full answer generation task. We also create a perturbed GQA test set by removing linguistic cues (attributes and relations) in the questions for analyzing whether a model is having a smart guess with superficial data correlations. We show that LRTA makes a step towards truly understanding the question while the state-of-the-art model tends to learn superficial correlations from the training data.
Neural Group Testing to Accelerate Deep Learning
Nov 21, 2020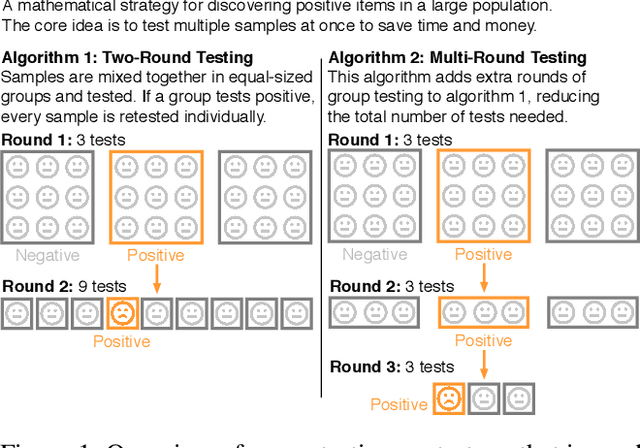
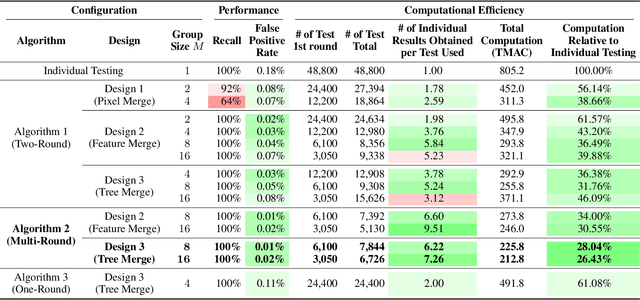
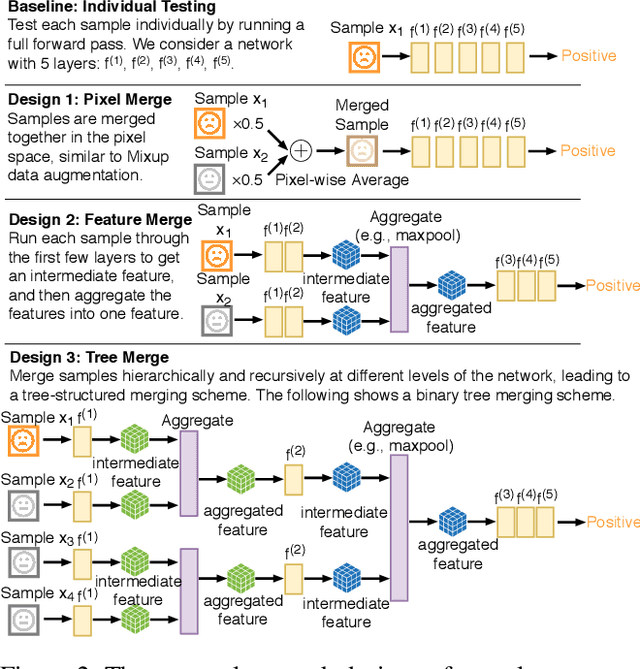
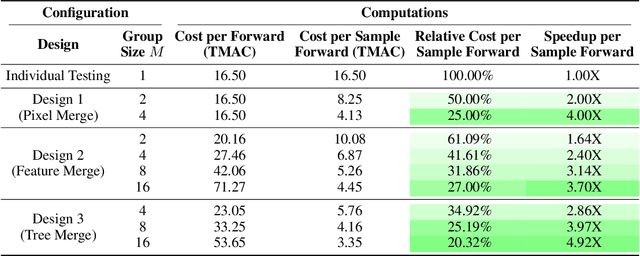
Recent advances in deep learning have made the use of large, deep neural networks with tens of millions of parameters. The sheer size of these networks imposes a challenging computational burden during inference. Existing work focuses primarily on accelerating each forward pass of a neural network. Inspired by the group testing strategy for efficient disease testing, we propose neural group testing, which accelerates by testing a group of samples in one forward pass. Groups of samples that test negative are ruled out. If a group tests positive, samples in that group are then retested adaptively. A key challenge of neural group testing is to modify a deep neural network so that it could test multiple samples in one forward pass. We propose three designs to achieve this without introducing any new parameters and evaluate their performances. We applied neural group testing in an image moderation task to detect rare but inappropriate images. We found that neural group testing can group up to 16 images in one forward pass and reduce the overall computation cost by over 73% while improving detection performance.
ALICE: Active Learning with Contrastive Natural Language Explanations
Sep 22, 2020

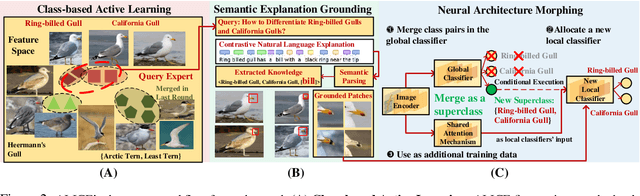
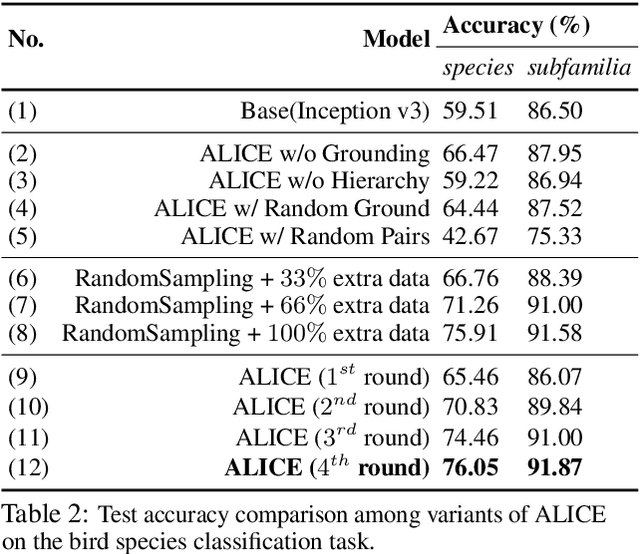
Training a supervised neural network classifier typically requires many annotated training samples. Collecting and annotating a large number of data points are costly and sometimes even infeasible. Traditional annotation process uses a low-bandwidth human-machine communication interface: classification labels, each of which only provides several bits of information. We propose Active Learning with Contrastive Explanations (ALICE), an expert-in-the-loop training framework that utilizes contrastive natural language explanations to improve data efficiency in learning. ALICE learns to first use active learning to select the most informative pairs of label classes to elicit contrastive natural language explanations from experts. Then it extracts knowledge from these explanations using a semantic parser. Finally, it incorporates the extracted knowledge through dynamically changing the learning model's structure. We applied ALICE in two visual recognition tasks, bird species classification and social relationship classification. We found by incorporating contrastive explanations, our models outperform baseline models that are trained with 40-100% more training data. We found that adding 1 explanation leads to similar performance gain as adding 13-30 labeled training data points.
Beyond User Self-Reported Likert Scale Ratings: A Comparison Model for Automatic Dialog Evaluation
Jun 12, 2020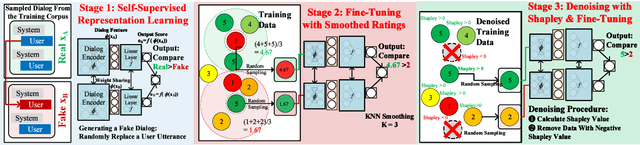
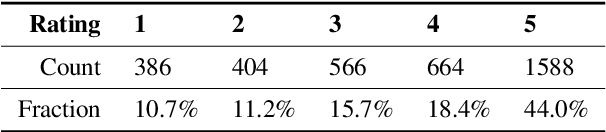

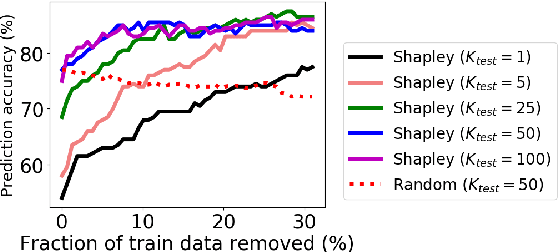
Open Domain dialog system evaluation is one of the most important challenges in dialog research. Existing automatic evaluation metrics, such as BLEU are mostly reference-based. They calculate the difference between the generated response and a limited number of available references. Likert-score based self-reported user rating is widely adopted by social conversational systems, such as Amazon Alexa Prize chatbots. However, self-reported user rating suffers from bias and variance among different users. To alleviate this problem, we formulate dialog evaluation as a comparison task. We also propose an automatic evaluation model CMADE (Comparison Model for Automatic Dialog Evaluation) that automatically cleans self-reported user ratings as it trains on them. Specifically, we first use a self-supervised method to learn better dialog feature representation, and then use KNN and Shapley to remove confusing samples. Our experiments show that CMADE achieves 89.2% accuracy in the dialog comparison task.
DAWSON: A Domain Adaptive Few Shot Generation Framework
Jan 02, 2020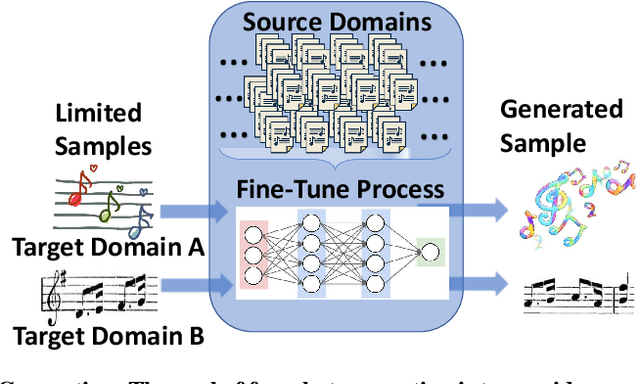
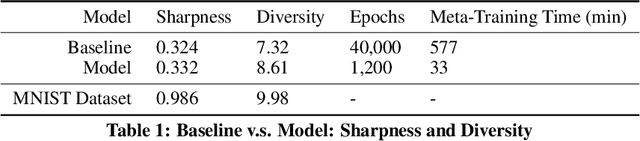
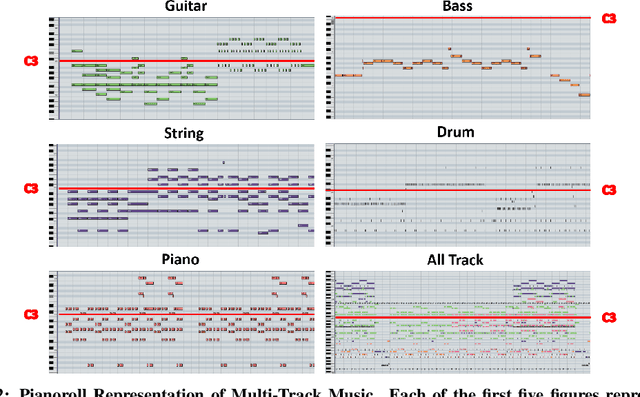
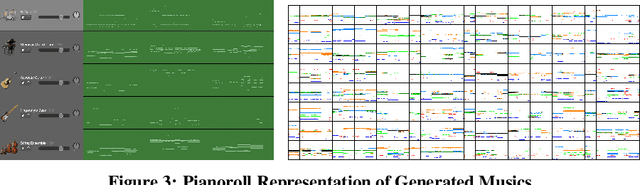
Training a Generative Adversarial Networks (GAN) for a new domain from scratch requires an enormous amount of training data and days of training time. To this end, we propose DAWSON, a Domain Adaptive FewShot Generation FrameworkFor GANs based on meta-learning. A major challenge of applying meta-learning GANs is to obtain gradients for the generator from evaluating it on development sets due to the likelihood-free nature of GANs. To address this challenge, we propose an alternative GAN training procedure that naturally combines the two-step training procedure of GANs and the two-step training procedure of meta-learning algorithms. DAWSON is a plug-and-play framework that supports a broad family of meta-learning algorithms and various GANs with architectural-variants. Based on DAWSON, We also propose MUSIC MATINEE, which is the first few-shot music generation model. Our experiments show that MUSIC MATINEE could quickly adapt to new domains with only tens of songs from the target domains. We also show that DAWSON can learn to generate new digits with only four samples in the MNIST dataset. We release source codes implementation of DAWSON in both PyTorch and Tensorflow, generated music samples on two genres and the lightning video.