 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^3$-Impute: Mask-guided Representation Learning for Missing Value Imputation
Oct 11, 2024



Missing values are a common problem that poses significant challenges to data analysis and machine learning. This problem necessitates the development of an effective imputation method to fill in the missing values accurately, thereby enhancing the overall quality and utility of the datasets. Existing imputation methods, however, fall short of explicitly considering the `missingness' information in the data during the embedding initialization stage and modeling the entangled feature and sample correlations during the learning process, thus leading to inferior performance. We propose M$^3$-Impute, which aims to explicitly leverage the missingness information and such correlations with novel masking schemes. M$^3$-Impute first models the data as a bipartite graph and uses a graph neural network to learn node embeddings, where the refined embedding initialization process directly incorporates the missingness information. They are then optimized through M$^3$-Impute's novel feature correlation unit (FRU) and sample correlation unit (SRU) that effectively captures feature and sample correlations for imputation. Experiment results on 25 benchmark datasets under three different missingness settings show the effectiveness of M$^3$-Impute by achieving 20 best and 4 second-best MAE scores on average.
CATGNN: Cost-Efficient and Scalable Distributed Training for Graph Neural Networks
Apr 02, 2024Graph neural networks have been shown successful in recent years. While different GNN architectures and training systems have been developed, GNN training on large-scale real-world graphs still remains challenging. Existing distributed systems load the entire graph in memory for graph partitioning, requiring a huge memory space to process large graphs and thus hindering GNN training on such large graphs using commodity workstations. In this paper, we propose CATGNN, a cost-efficient and scalable distributed GNN training system which focuses on scaling GNN training to billion-scale or larger graphs under limited computational resources. Among other features, it takes a stream of edges as input, instead of loading the entire graph in memory, for partitioning. We also propose a novel streaming partitioning algorithm named SPRING for distributed GNN training. We verify the correctness and effectiveness of CATGNN with SPRING on 16 open datasets. In particular, we demonstrate that CATGNN can handle the largest publicly available dataset with limited memory, which would have been infeasible without increasing the memory space. SPRING also outperforms state-of-the-art partitioning algorithms significantly, with a 50% reduction in replication factor on average.
A Multi-Scale Decomposition MLP-Mixer for Time Series Analysis
Oct 18, 2023



Time series data, often characterized by unique composition and complex multi-scale temporal variations, requires special consideration of decomposition and multi-scale modeling in its analysis. Existing deep learning methods on this best fit to only univariate time series, and have not sufficiently accounted for sub-series level modeling and decomposition completeness. To address this, we propose MSD-Mixer, a Multi-Scale Decomposition MLP-Mixer which learns to explicitly decompose the input time series into different components, and represents the components in different layers. To handle multi-scale temporal patterns and inter-channel dependencies, we propose a novel temporal patching approach to model the time series as multi-scale sub-series, i.e., patches, and employ MLPs to mix intra- and inter-patch variations and channel-wise correlations. In addition, we propose a loss function to constrain both the magnitude and autocorrelation of the decomposition residual for decomposition completeness. Through extensive experiments on various real-world datasets for five common time series analysis tasks (long- and short-term forecasting, imputation, anomaly detection, and classification), we demonstrate that MSD-Mixer consistently achieves significantly better performance in comparison with other state-of-the-art task-general and task-specific approaches.
FIS-ONE: Floor Identification System with One Label for Crowdsourced RF Signals
Jul 12, 2023Floor labels of crowdsourced RF signals are crucial for many smart-city applications, such as multi-floor indoor localization, geofencing, and robot surveillance. To build a prediction model to identify the floor number of a new RF signal upon its measurement, conventional approaches using the crowdsourced RF signals assume that at least few labeled signal samples are available on each floor. In this work, we push the envelope further and demonstrate that it is technically feasible to enable such floor identification with only one floor-labeled signal sample on the bottom floor while having the rest of signal samples unlabeled. We propose FIS-ONE, a novel floor identification system with only one labeled sample. FIS-ONE consists of two steps, namely signal clustering and cluster indexing. We first build a bipartite graph to model the RF signal samples and obtain a latent representation of each node (each signal sample) using our attention-based graph neural network model so that the RF signal samples can be clustered more accurately. Then, we tackle the problem of indexing the clusters with proper floor labels, by leveraging the observation that signals from an access point can be detected on different floors, i.e., signal spillover. Specifically, we formulate a cluster indexing problem as a combinatorial optimization problem and show that it is equivalent to solving a traveling salesman problem, whose (near-)optimal solution can be found efficiently. We have implemented FIS-ONE and validated its effectiveness on the Microsoft dataset and in three large shopping malls. Our results show that FIS-ONE outperforms other baseline algorithms significantly, with up to 23% improvement in adjusted rand index and 25% improvement in normalized mutual information using only one floor-labeled signal sample.
Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks
Mar 07, 2023To design fast neural networks, many works have been focusing on reducing the number of floating-point operations (FLOPs). We observe that such reduction in FLOPs, however, does not necessarily lead to a similar level of reduction in latency. This mainly stems from inefficiently low floating-point operations per second (FLOPS). To achieve faster networks, we revisit popular operators and demonstrate that such low FLOPS is mainly due to frequent memory access of the operators, especially the depthwise convolution. We hence propose a novel partial convolution (PConv) that extracts spatial features more efficiently, by cutting down redundant computation and memory access simultaneously. Building upon our PConv, we further propose FasterNet, a new family of neural networks, which attains substantially higher running speed than others on a wide range of devices, without compromising on accuracy for various vision tasks. For example, on ImageNet-1k, our tiny FasterNet-T0 is $3.1\times$, $3.1\times$, and $2.5\times$ faster than MobileViT-XXS on GPU, CPU, and ARM processors, respectively, while being $2.9\%$ more accurate. Our large FasterNet-L achieves impressive $83.5\%$ top-1 accuracy, on par with the emerging Swin-B, while having $49\%$ higher inference throughput on GPU, as well as saving $42\%$ compute time on CPU. Code is available at \url{https://github.com/JierunChen/FasterNet}.
TVConv: Efficient Translation Variant Convolution for Layout-aware Visual Processing
Mar 22, 2022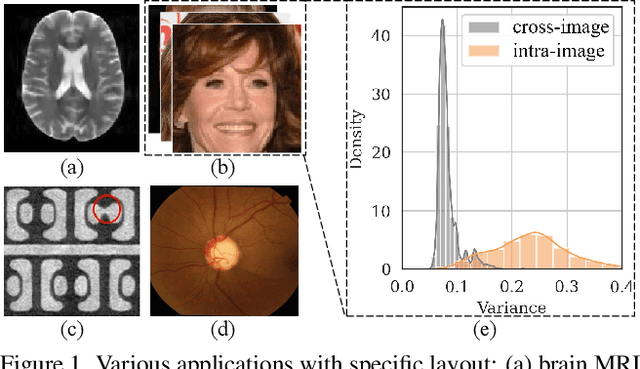
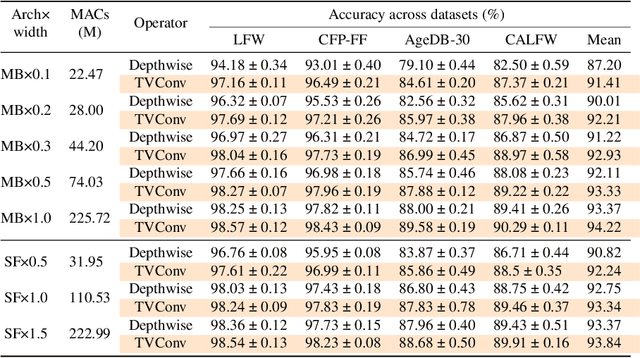
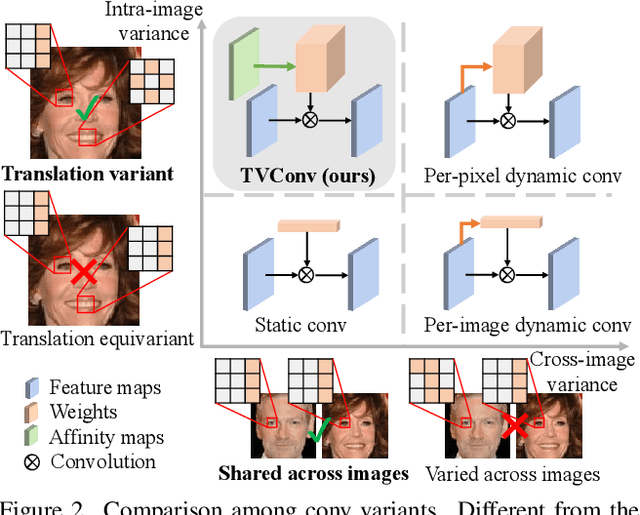
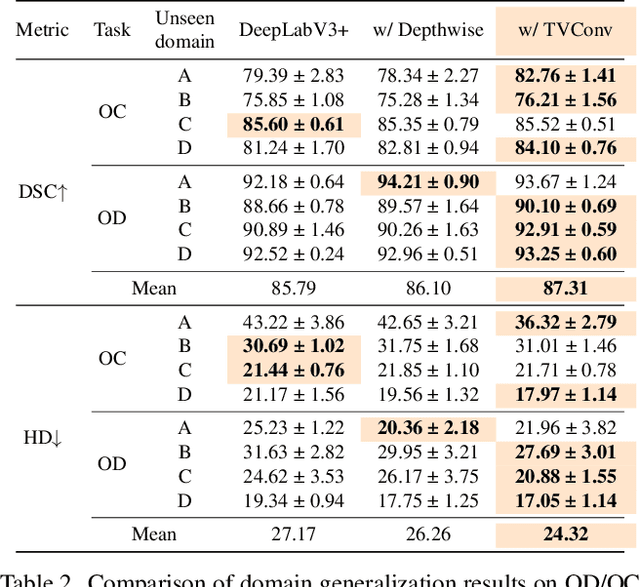
As convolution has empowered many smart applications, dynamic convolution further equips it with the ability to adapt to diverse inputs. However, the static and dynamic convolutions are either layout-agnostic or computation-heavy, making it inappropriate for layout-specific applications, e.g., face recognition and medical image segmentation. We observe that these applications naturally exhibit the characteristics of large intra-image (spatial) variance and small cross-image variance. This observation motivates our efficient translation variant convolution (TVConv) for layout-aware visual processing. Technically, TVConv is composed of affinity maps and a weight-generating block. While affinity maps depict pixel-paired relationships gracefully, the weight-generating block can be explicitly overparameterized for better training while maintaining efficient inference. Although conceptually simple, TVConv significantly improves the efficiency of the convolution and can be readily plugged into various network architectures. Extensive experiments on face recognition show that TVConv reduces the computational cost by up to 3.1x and improves the corresponding throughput by 2.3x while maintaining a high accuracy compared to the depthwise convolution. Moreover, for the same computation cost, we boost the mean accuracy by up to 4.21%. We also conduct experiments on the optic disc/cup segmentation task and obtain better generalization performance, which helps mitigate the critical data scarcity issue. Code is available at https://github.com/JierunChen/TVConv.