 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOLAR: Automating Cyber Threat Prioritization through LLM-Powered Assessment
Oct 02, 2025



Large Language Models (LLMs) are intensively used to assist security analysts in counteracting the rapid exploitation of cyber threats, wherein LLMs offer cyber threat intelligence (CTI) to support vulnerability assessment and incident response. While recent work has shown that LLMs can support a wide range of CTI tasks such as threat analysis, vulnerability detection, and intrusion defense, significant performance gaps persist in practical deployments. In this paper, we investigate the intrinsic vulnerabilities of LLMs in CTI, focusing on challenges that arise from the nature of the threat landscape itself rather than the model architecture. Using large-scale evaluations across multiple CTI benchmarks and real-world threat reports, we introduce a novel categorization methodology that integrates stratification, autoregressive refinement, and human-in-the-loop supervision to reliably analyze failure instances. Through extensive experiments and human inspections, we reveal three fundamental vulnerabilities: spurious correlations, contradictory knowledge, and constrained generalization, that limit LLMs in effectively supporting CTI. Subsequently, we provide actionable insights for designing more robust LLM-powered CTI systems to facilitate future research.
Communication is All You Need: Persuasion Dataset Construction via Multi-LLM Communication
Feb 13, 2025



Large Language Models (LLMs) have shown proficiency in generating persuasive dialogue, yet concerns about the fluency and sophistication of their outputs persist. This paper presents a multi-LLM communication framework designed to enhance the generation of persuasive data automatically. This framework facilitates the efficient production of high-quality, diverse linguistic content with minimal human oversight. Through extensive evaluations, we demonstrate that the generated data excels in naturalness, linguistic diversity, and the strategic use of persuasion, even in complex scenarios involving social taboos. The framework also proves adept at generalizing across novel contexts. Our results highlight the framework's potential to significantly advance research in both computational and social science domains concerning persuasive communication.
Is It Navajo? Accurate Language Detection in Endangered Athabaskan Languages
Jan 27, 2025



Endangered languages, such as Navajo - the most widely spoken Native American language - are significantly underrepresented in contemporary language technologies, exacerbating the challenges of their preservation and revitalization. This study evaluates Google's large language model (LLM)-based language identification system, which consistently misidentifies Navajo, exposing inherent limitations when applied to low-resource Native American languages. To address this, we introduce a random forest classifier trained on Navajo and eight frequently confused languages. Despite its simplicity, the classifier achieves near-perfect accuracy (97-100%), significantly outperforming Google's LLM-based system. Additionally, the model demonstrates robustness across other Athabaskan languages - a family of Native American languages spoken primarily in Alaska, the Pacific Northwest, and parts of the Southwestern United States - suggesting its potential for broader application. Our findings underscore the pressing need for NLP systems that prioritize linguistic diversity and adaptability over centralized, one-size-fits-all solutions, especially in supporting underrepresented languages in a multicultural world. This work directly contributes to ongoing efforts to address cultural biases in language models and advocates for the development of culturally localized NLP tools that serve diverse linguistic communities.
NüshuRescue: Revitalization of the endangered Nüshu Language with AI
Dec 03, 2024



The preservation and revitalization of endangered and extinct languages is a meaningful endeavor, conserving cultural heritage while enriching fields like linguistics and anthropology. However, these languages are typically low-resource, making their reconstruction labor-intensive and costly. This challenge is exemplified by N\"ushu, a rare script historically used by Yao women in China for self-expression within a patriarchal society. To address this challenge, we introduce N\"ushuRescue, an AI-driven framework designed to train large language models (LLMs) on endangered languages with minimal data. N\"ushuRescue automates evaluation and expands target corpora to accelerate linguistic revitalization. As a foundational component, we developed NCGold, a 500-sentence N\"ushu-Chinese parallel corpus, the first publicly available dataset of its kind. Leveraging GPT-4-Turbo, with no prior exposure to N\"ushu and only 35 short examples from NCGold, N\"ushuRescue achieved 48.69\% translation accuracy on 50 withheld sentences and generated NCSilver, a set of 98 newly translated modern Chinese sentences of varying lengths. A sample of both NCGold and NCSilver is included in the Supplementary Materials. Additionally, we developed FastText-based and Seq2Seq models to further support research on N\"ushu. N\"ushuRescue provides a versatile and scalable tool for the revitalization of endangered languages, minimizing the need for extensive human input.
On the Exploration of LM-Based Soft Modular Robot Design
Nov 01, 2024



Recent large language models (LLMs) have demonstrated promising capabilities in modeling real-world knowledge and enhancing knowledge-based generation tasks. In this paper, we further explore the potential of using LLMs to aid in the design of soft modular robots, taking into account both user instructions and physical laws, to reduce the reliance on extensive trial-and-error experiments typically needed to achieve robot designs that meet specific structural or task requirements. Specifically, we formulate the robot design process as a sequence generation task and find that LLMs are able to capture key requirements expressed in natural language and reflect them in the construction sequences of robots. To simplify, rather than conducting real-world experiments to assess design quality, we utilize a simulation tool to provide feedback to the generative model, allowing for iterative improvements without requiring extensive human annotations. Furthermore, we introduce five evaluation metrics to assess the quality of robot designs from multiple angles including task completion and adherence to instructions, supporting an automatic evaluation process. Our model performs well in evaluations for designing soft modular robots with uni- and bi-directional locomotion and stair-descending capabilities, highlighting the potential of using natural language and LLMs for robot design. However, we also observe certain limitations that suggest areas for further improvement.
Judging the Judges: A Systematic Investigation of Position Bias in Pairwise Comparative Assessments by LLMs
Jun 12, 2024LLM-as-a-Judge offers a promising alternative to human judges across various tasks, yet inherent biases, particularly position bias - a systematic preference for answers based on their position in the prompt - compromise its effectiveness. Our study investigates this issue by developing a framework to systematically study and quantify position bias using metrics such as repetitional consistency, positional consistency, and positional fairness. We conduct experiments with 9 judge models across 22 tasks from the MTBench and DevBench benchmarks and nearly 40 answer-generating models, generating approximately 80,000 evaluation instances. This comprehensive assessment reveals significant variations in bias across judges and tasks. Although GPT-4 often excels in positional consistency and fairness, some more cost-effective models perform comparably or even better in specific tasks, highlighting essential trade-offs between consistency, fairness, and cost. Our results also demonstrate high consistency of judgment across repetitions, confirming that position bias is not due to random variations. This research significantly contributes to the field by introducing new concepts for understanding position bias and providing a multi-dimensional framework for evaluation. These insights guide the selection of optimal judge models, enhance benchmark design, and lay the foundation for future research into effective debiasing strategies, ultimately enhancing the reliability of LLM evaluators.
Graph-Level Embedding for Time-Evolving Graphs
Jun 01, 2023Graph representation learning (also known as network embedding) has been extensively researched with varying levels of granularity, ranging from nodes to graphs. While most prior work in this area focuses on node-level representation, limited research has been conducted on graph-level embedding, particularly for dynamic or temporal networks. However, learning low-dimensional graph-level representations for dynamic networks is critical for various downstream graph retrieval tasks such as temporal graph similarity ranking, temporal graph isomorphism, and anomaly detection. In this paper, we present a novel method for temporal graph-level embedding that addresses this gap. Our approach involves constructing a multilayer graph and using a modified random walk with temporal backtracking to generate temporal contexts for the graph's nodes. We then train a "document-level" language model on these contexts to generate graph-level embeddings. We evaluate our proposed model on five publicly available datasets for the task of temporal graph similarity ranking, and our model outperforms baseline methods. Our experimental results demonstrate the effectiveness of our method in generating graph-level embeddings for dynamic networks.
Capturing Topic Framing via Masked Language Modeling
Feb 07, 2023Differential framing of issues can lead to divergent world views on important issues. This is especially true in domains where the information presented can reach a large audience, such as traditional and social media. Scalable and reliable measurement of such differential framing is an important first step in addressing them. In this work, based on the intuition that framing affects the tone and word choices in written language, we propose a framework for modeling the differential framing of issues through masked token prediction via large-scale fine-tuned language models (LMs). Specifically, we explore three key factors for our framework: 1) prompt generation methods for the masked token prediction; 2) methods for normalizing the output of fine-tuned LMs; 3) robustness to the choice of pre-trained LMs used for fine-tuning. Through experiments on a dataset of articles from traditional media outlets covering five diverse and politically polarized topics, we show that our framework can capture differential framing of these topics with high reliability.
* In Findings of EMNLP 2022
EnCBP: A New Benchmark Dataset for Finer-Grained Cultural Background Prediction in English
Mar 28, 2022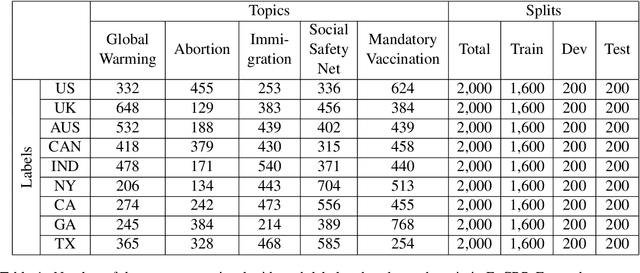

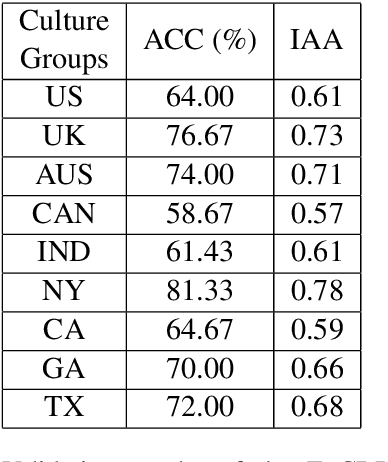
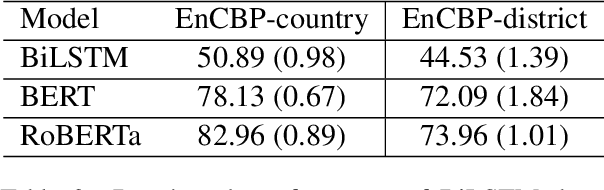
While cultural backgrounds have been shown to affect linguistic expressions, existing natural language processing (NLP) research on culture modeling is overly coarse-grained and does not examine cultural differences among speakers of the same language. To address this problem and augment NLP models with cultural background features, we collect, annotate, manually validate, and benchmark EnCBP, a finer-grained news-based cultural background prediction dataset in English. Through language modeling (LM) evaluations and manual analyses, we confirm that there are noticeable differences in linguistic expressions among five English-speaking countries and across four states in the US. Additionally, our evaluations on nine syntactic (CoNLL-2003), semantic (PAWS-Wiki, QNLI, STS-B, and RTE), and psycholinguistic tasks (SST-5, SST-2, Emotion, and Go-Emotions) show that, while introducing cultural background information does not benefit the Go-Emotions task due to text domain conflicts, it noticeably improves deep learning (DL) model performance on other tasks. Our findings strongly support the importance of cultural background modeling to a wide variety of NLP tasks and demonstrate the applicability of EnCBP in culture-related research.
Embedding Node Structural Role Identity Using Stress Majorization
Sep 14, 2021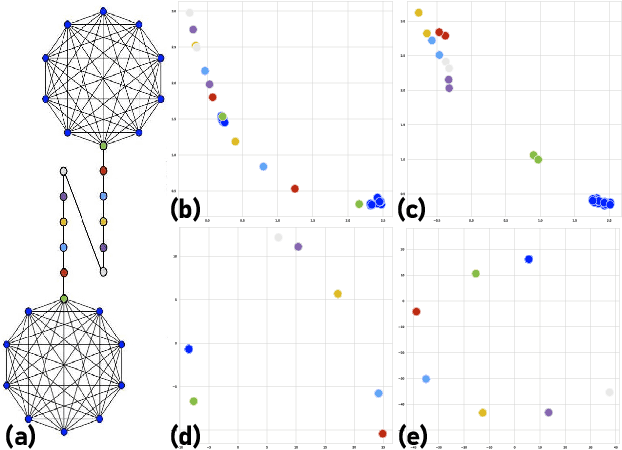
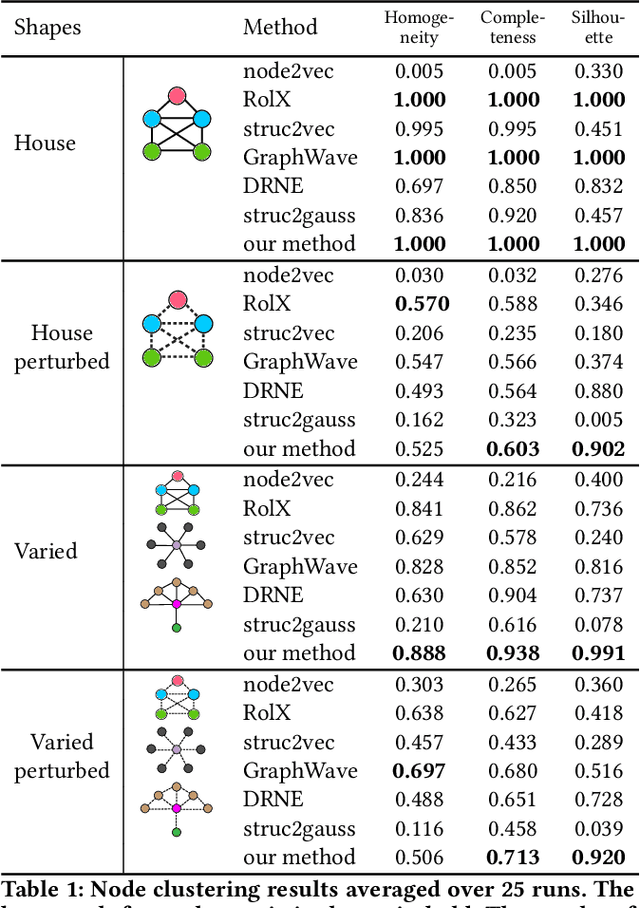
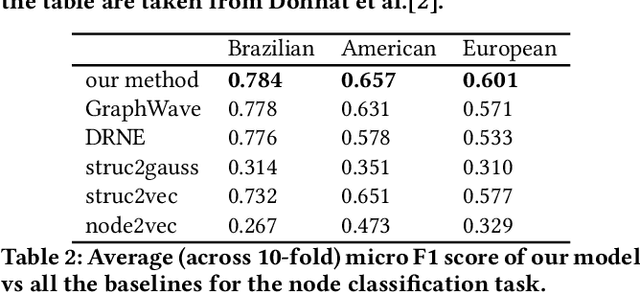
Nodes in networks may have one or more functions that determine their role in the system. As opposed to local proximity, which captures the local context of nodes, the role identity captures the functional "role" that nodes play in a network, such as being the center of a group, or the bridge between two groups. This means that nodes far apart in a network can have similar structural role identities. Several recent works have explored methods for embedding the roles of nodes in networks. However, these methods all rely on either approximating or indirect modeling of structural equivalence. In this paper, we present a novel and flexible framework using stress majorization, to transform the high-dimensional role identities in networks directly (without approximation or indirect modeling) to a low-dimensional embedding space. Our method is also flexible, in that it does not rely on specific structural similarity definitions. We evaluated our method on the tasks of node classification, clustering, and visualization, using three real-world and five synthetic networks. Our experiments show that our framework achieves superior results than existing methods in learning node role representations.