 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Unsupervised Video Game Playstyle Metric via State Discretization
Oct 03, 2021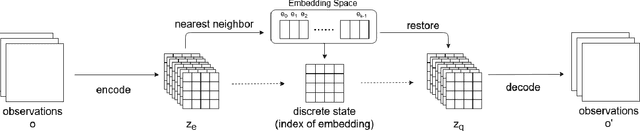
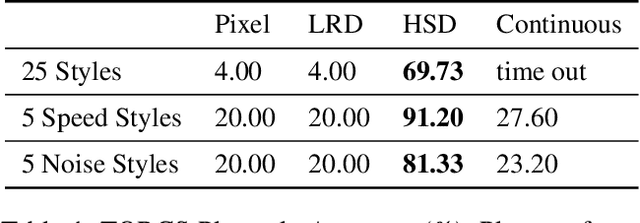
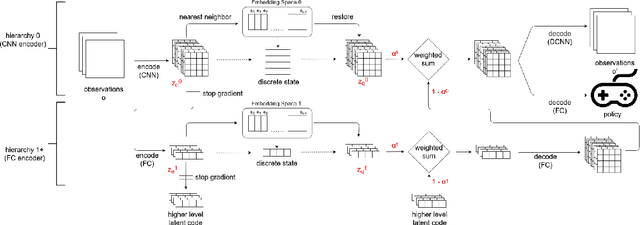
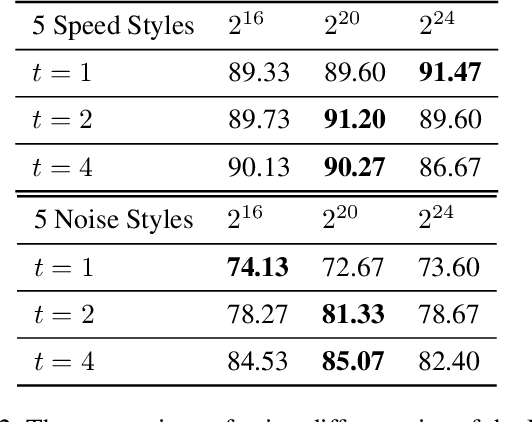
On playing video games, different players usually have their own playstyles. Recently, there have been great improvements for the video game AIs on the playing strength. However, past researches for analyzing the behaviors of players still used heuristic rules or the behavior features with the game-environment support, thus being exhausted for the developers to define the features of discriminating various playstyles. In this paper, we propose the first metric for video game playstyles directly from the game observations and actions, without any prior specification on the playstyle in the target game. Our proposed method is built upon a novel scheme of learning discrete representations that can map game observations into latent discrete states, such that playstyles can be exhibited from these discrete states. Namely, we measure the playstyle distance based on game observations aligned to the same states. We demonstrate high playstyle accuracy of our metric in experiments on some video game platforms, including TORCS, RGSK, and seven Atari games, and for different agents including rule-based AI bots, learning-based AI bots, and human players.
* This version was also published on UAI 2021
Towards Interpretable Deep Networks for Monocular Depth Estimation
Aug 11, 2021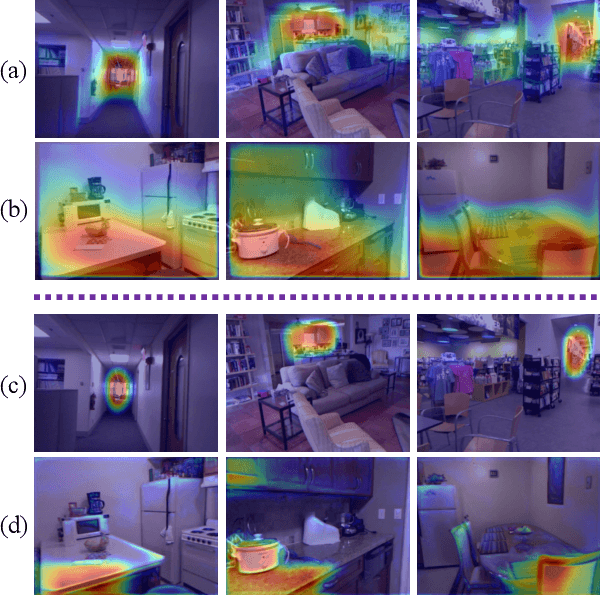

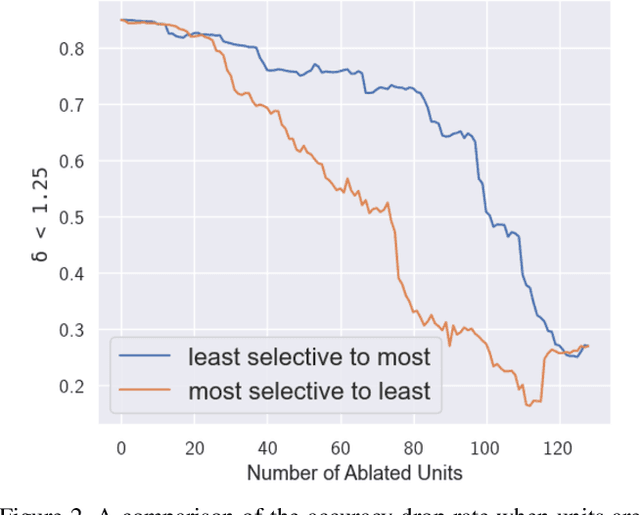
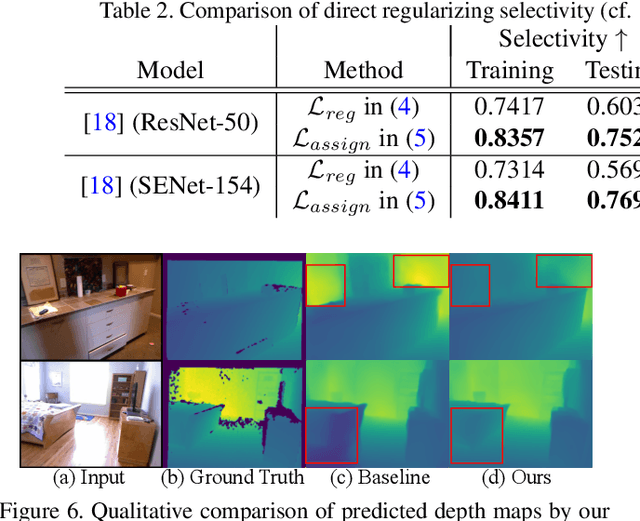
Deep networks for Monocular Depth Estimation (MDE) have achieved promising performance recently and it is of great importance to further understand the interpretability of these networks. Existing methods attempt to provide posthoc explanations by investigating visual cues, which may not explore the internal representations learned by deep networks. In this paper, we find that some hidden units of the network are selective to certain ranges of depth, and thus such behavior can be served as a way to interpret the internal representations. Based on our observations, we quantify the interpretability of a deep MDE network by the depth selectivity of its hidden units. Moreover, we then propose a method to train interpretable MDE deep networks without changing their original architectures, by assigning a depth range for each unit to select. Experimental results demonstrate that our method is able to enhance the interpretability of deep MDE networks by largely improving the depth selectivity of their units, while not harming or even improving the depth estimation accuracy. We further provide a comprehensive analysis to show the reliability of selective units, the applicability of our method on different layers, models, and datasets, and a demonstration on analysis of model error. Source code and models are available at https://github.com/youzunzhi/InterpretableMDE .
Learning Facial Representations from the Cycle-consistency of Face
Aug 07, 2021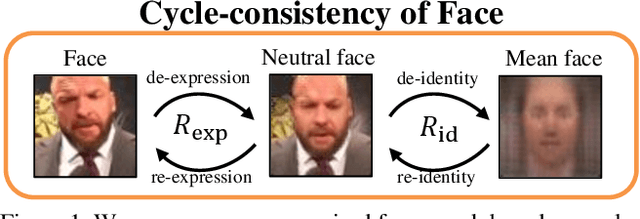
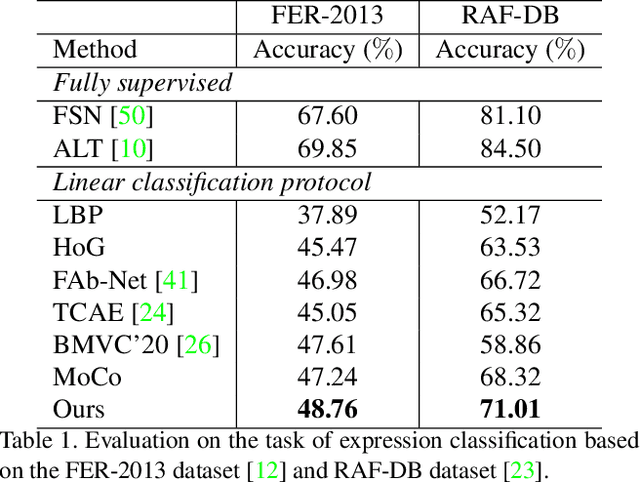
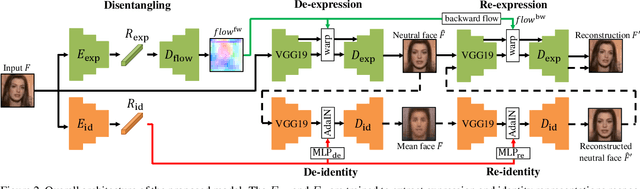
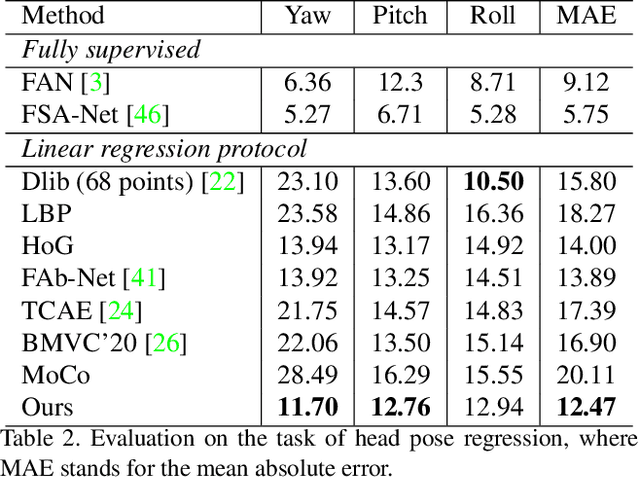
Faces manifest large variations in many aspects, such as identity, expression, pose, and face styling. Therefore, it is a great challenge to disentangle and extract these characteristics from facial images, especially in an unsupervised manner. In this work, we introduce cycle-consistency in facial characteristics as free supervisory signal to learn facial representations from unlabeled facial images. The learning is realized by superimposing the facial motion cycle-consistency and identity cycle-consistency constraints. The main idea of the facial motion cycle-consistency is that, given a face with expression, we can perform de-expression to a neutral face via the removal of facial motion and further perform re-expression to reconstruct back to the original face. The main idea of the identity cycle-consistency is to exploit both de-identity into mean face by depriving the given neutral face of its identity via feature re-normalization and re-identity into neutral face by adding the personal attributes to the mean face. At training time, our model learns to disentangle two distinct facial representations to be useful for performing cycle-consistent face reconstruction. At test time, we use the linear protocol scheme for evaluating facial representations on various tasks, including facial expression recognition and head pose regression. We also can directly apply the learnt facial representations to person recognition, frontalization and image-to-image translation. Our experiments show that the results of our approach is competitive with those of existing methods, demonstrating the rich and unique information embedded in the disentangled representations. Code is available at https://github.com/JiaRenChang/FaceCycle .
MAML is a Noisy Contrastive Learner
Jun 29, 2021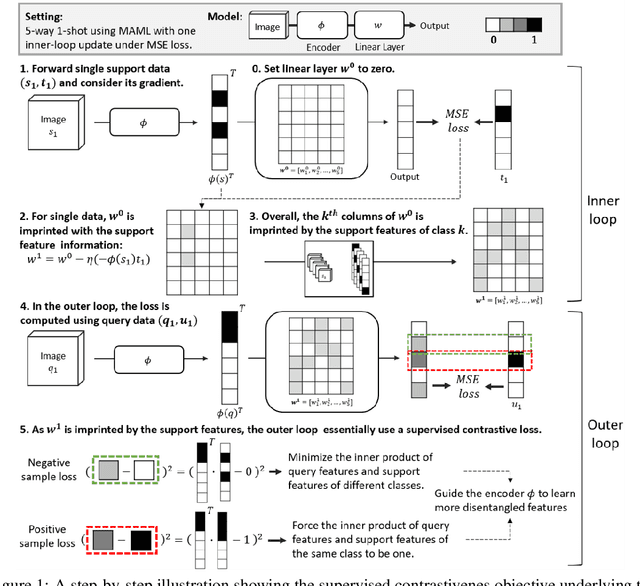
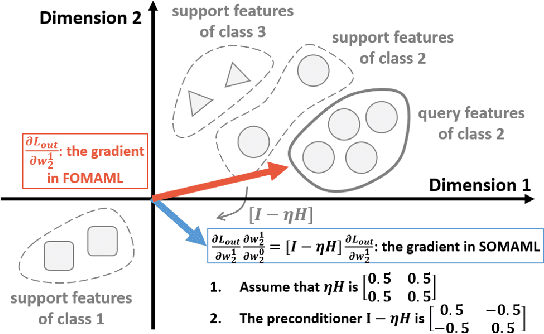
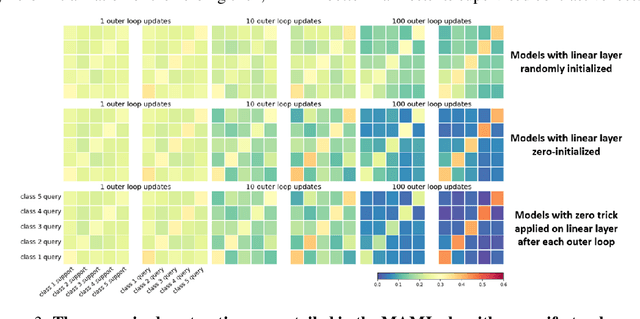
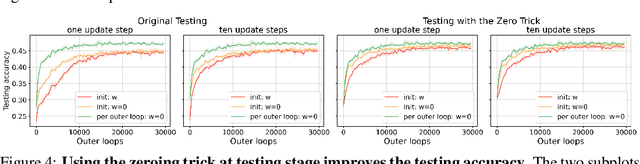
Model-agnostic meta-learning (MAML) is one of the most popular and widely-adopted meta-learning algorithms nowadays, which achieves remarkable success in various learning problems. Yet, with the unique design of nested inner-loop and outer-loop updates which respectively govern the task-specific and meta-model-centric learning, the underlying learning objective of MAML still remains implicit and thus impedes a more straightforward understanding of it. In this paper, we provide a new perspective to the working mechanism of MAML and discover that: MAML is analogous to a meta-learner using a supervised contrastive objective function, where the query features are pulled towards the support features of the same class and against those of different classes, in which such contrastiveness is experimentally verified via an analysis based on the cosine similarity. Moreover, our analysis reveals that the vanilla MAML algorithm has an undesirable interference term originating from the random initialization and the cross-task interaction. We therefore propose a simple but effective technique, zeroing trick, to alleviate such interference, where the extensive experiments are then conducted on both miniImagenet and Omniglot datasets to demonstrate the consistent improvement brought by our proposed technique thus well validating its effectiveness.
Stylizing 3D Scene via Implicit Representation and HyperNetwork
Jun 05, 2021
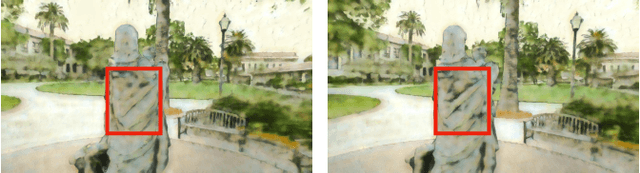
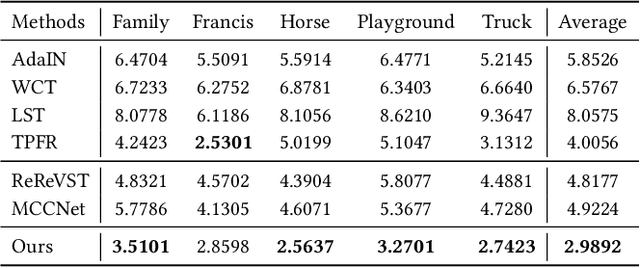
In this work, we aim to address the 3D scene stylization problem - generating stylized images of the scene at arbitrary novel view angles. A straightforward solution is to combine existing novel view synthesis and image/video style transfer approaches, which often leads to blurry results or inconsistent appearance. Inspired by the high quality results of the neural radiance fields (NeRF) method, we propose a joint framework to directly render novel views with the desired style. Our framework consists of two components: an implicit representation of the 3D scene with the neural radiance field model, and a hypernetwork to transfer the style information into the scene representation. In particular, our implicit representation model disentangles the scene into the geometry and appearance branches, and the hypernetwork learns to predict the parameters of the appearance branch from the reference style image. To alleviate the training difficulties and memory burden, we propose a two-stage training procedure and a patch sub-sampling approach to optimize the style and content losses with the neural radiance field model. After optimization, our model is able to render consistent novel views at arbitrary view angles with arbitrary style. Both quantitative evaluation and human subject study have demonstrated that the proposed method generates faithful stylization results with consistent appearance across different views.
RPG: Learning Recursive Point Cloud Generation
May 29, 2021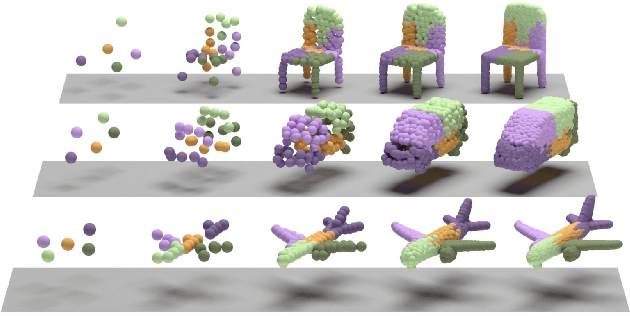
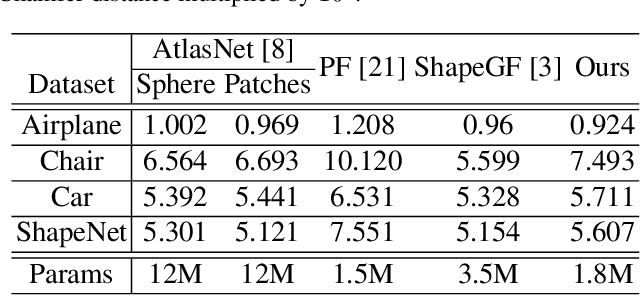
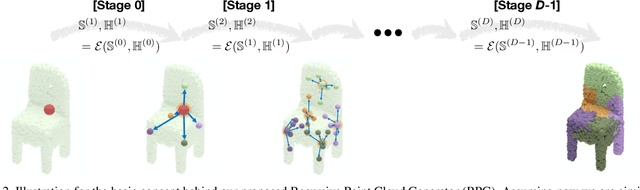
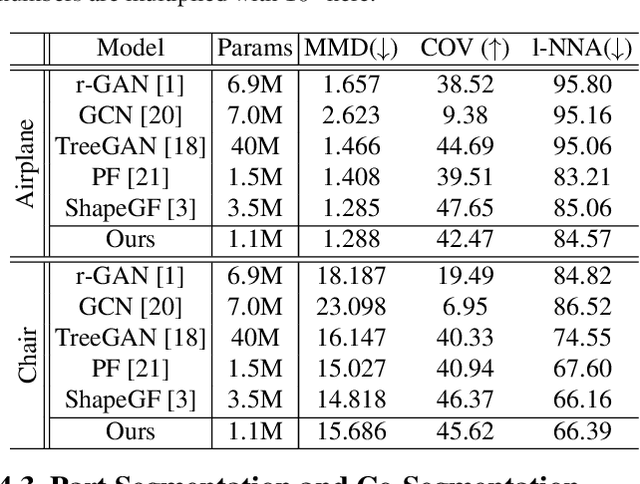
In this paper we propose a novel point cloud generator that is able to reconstruct and generate 3D point clouds composed of semantic parts. Given a latent representation of the target 3D model, the generation starts from a single point and gets expanded recursively to produce the high-resolution point cloud via a sequence of point expansion stages. During the recursive procedure of generation, we not only obtain the coarse-to-fine point clouds for the target 3D model from every expansion stage, but also unsupervisedly discover the semantic segmentation of the target model according to the hierarchical/parent-child relation between the points across expansion stages. Moreover, the expansion modules and other elements used in our recursive generator are mostly sharing weights thus making the overall framework light and efficient. Extensive experiments are conducted to demonstrate that our proposed point cloud generator has comparable or even superior performance on both generation and reconstruction tasks in comparison to various baselines, as well as provides the consistent co-segmentation among 3D instances of the same object class.
Robust 360-8PA: Redesigning The Normalized 8-point Algorithm for 360-FoV Images
Apr 22, 2021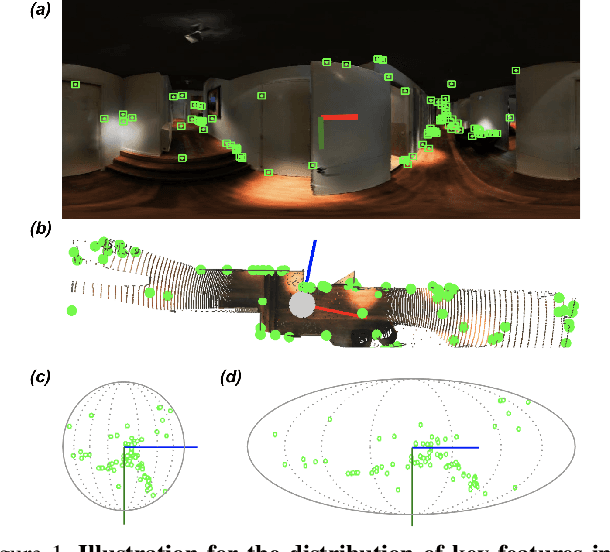
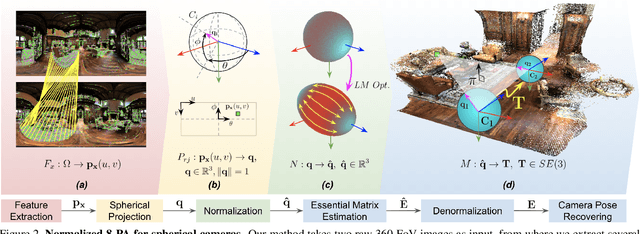
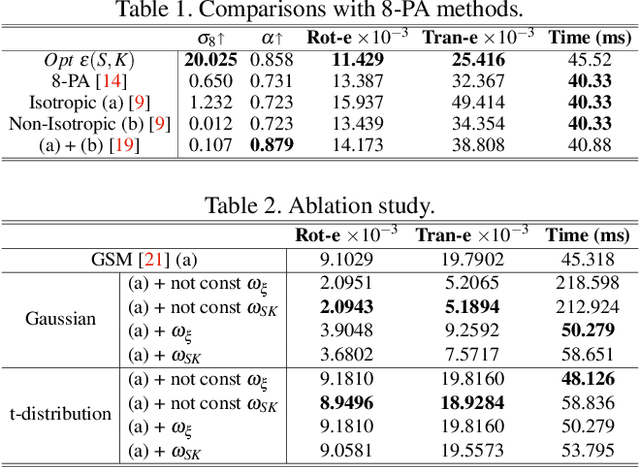
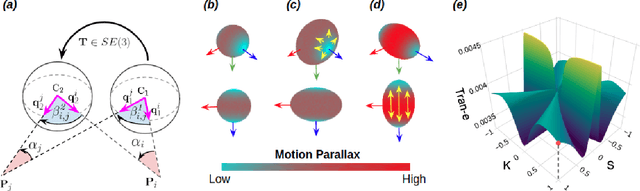
This paper presents a novel preconditioning strategy for the classic 8-point algorithm (8-PA) for estimating an essential matrix from 360-FoV images (i.e., equirectangular images) in spherical projection. To alleviate the effect of uneven key-feature distributions and outlier correspondences, which can potentially decrease the accuracy of an essential matrix, our method optimizes a non-rigid transformation to deform a spherical camera into a new spatial domain, defining a new constraint and a more robust and accurate solution for an essential matrix. Through several experiments using random synthetic points, 360-FoV, and fish-eye images, we demonstrate that our normalization can increase the camera pose accuracy by about 20% without significantly overhead the computation time. In addition, we present further benefits of our method through both a constant weighted least-square optimization that improves further the well known Gold Standard Method (GSM) (i.e., the non-linear optimization by using epipolar errors); and a relaxation of the number of RANSAC iterations, both showing that our normalization outcomes a more reliable, robust, and accurate solution.
LED2-Net: Monocular 360 Layout Estimation via Differentiable Depth Rendering
Apr 03, 2021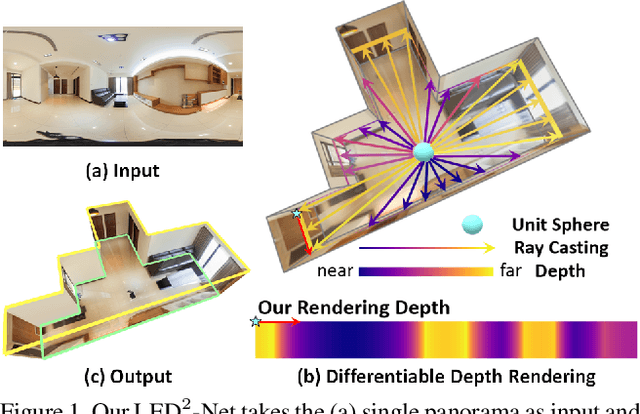
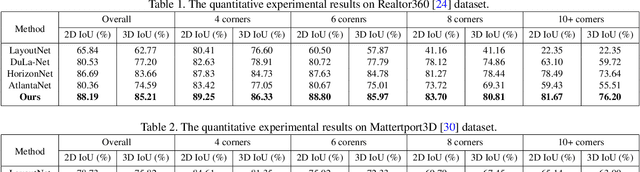


Although significant progress has been made in room layout estimation, most methods aim to reduce the loss in the 2D pixel coordinate rather than exploiting the room structure in the 3D space. Towards reconstructing the room layout in 3D, we formulate the task of 360 layout estimation as a problem of predicting depth on the horizon line of a panorama. Specifically, we propose the Differentiable Depth Rendering procedure to make the conversion from layout to depth prediction differentiable, thus making our proposed model end-to-end trainable while leveraging the 3D geometric information, without the need of providing the ground truth depth. Our method achieves state-of-the-art performance on numerous 360 layout benchmark datasets. Moreover, our formulation enables a pre-training step on the depth dataset, which further improves the generalizability of our layout estimation model.
Bridging the Visual Gap: Wide-Range Image Blending
Mar 30, 2021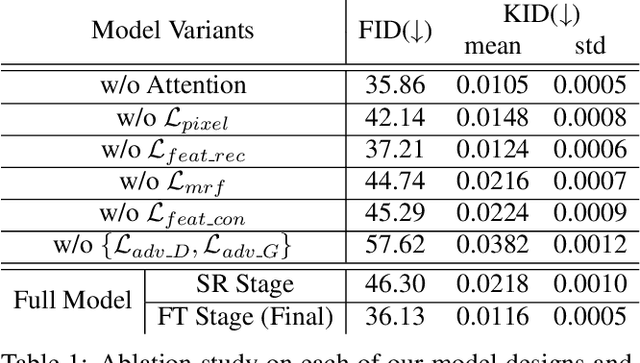
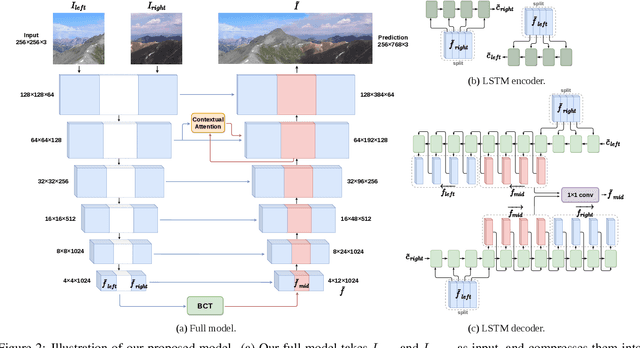
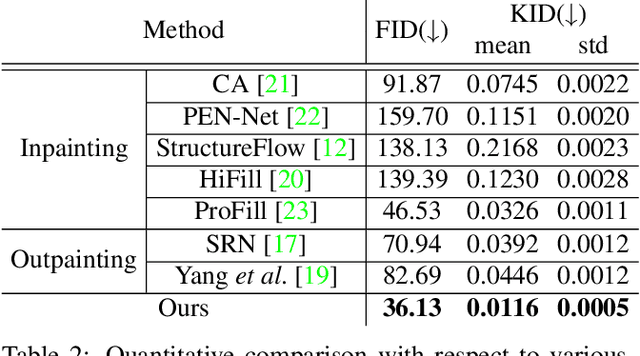

In this paper we propose a new problem scenario in image processing, wide-range image blending, which aims to smoothly merge two different input photos into a panorama by generating novel image content for the intermediate region between them. Although such problem is closely related to the topics of image inpainting, image outpainting, and image blending, none of the approaches from these topics is able to easily address it. We introduce an effective deep-learning model to realize wide-range image blending, where a novel Bidirectional Content Transfer module is proposed to perform the conditional prediction for the feature representation of the intermediate region via recurrent neural networks. In addition to ensuring the spatial and semantic consistency during the blending, we also adopt the contextual attention mechanism as well as the adversarial learning scheme in our proposed method for improving the visual quality of the resultant panorama. We experimentally demonstrate that our proposed method is not only able to produce visually appealing results for wide-range image blending, but also able to provide superior performance with respect to several baselines built upon the state-of-the-art image inpainting and outpainting approaches.
Domain Adaptation for Learning Generator from Paired Few-Shot Data
Feb 25, 2021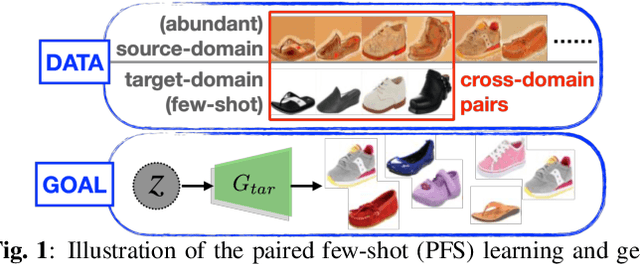
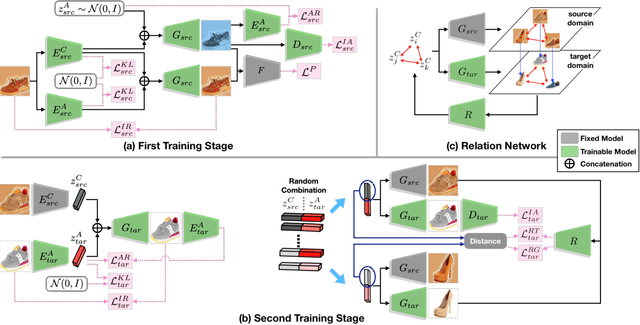
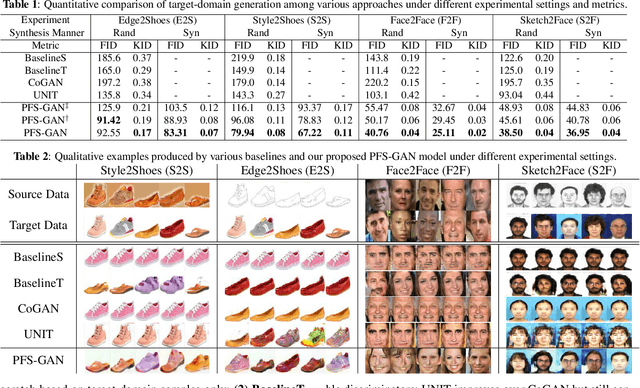
We propose a Paired Few-shot GAN (PFS-GAN) model for learning generators with sufficient source data and a few target data. While generative model learning typically needs large-scale training data, our PFS-GAN not only uses the concept of few-shot learning but also domain shift to transfer the knowledge across domains, which alleviates the issue of obtaining low-quality generator when only trained with target domain data. The cross-domain datasets are assumed to have two properties: (1) each target-domain sample has its source-domain correspondence and (2) two domains share similar content information but different appearance. Our PFS-GAN aims to learn the disentangled representation from images, which composed of domain-invariant content features and domain-specific appearance features. Furthermore, a relation loss is introduced on the content features while shifting the appearance features to increase the structural diversity. Extensive experiments show that our method has better quantitative and qualitative results on the generated target-domain data with higher diversity in comparison to several baselines.