 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
Apr 19, 2018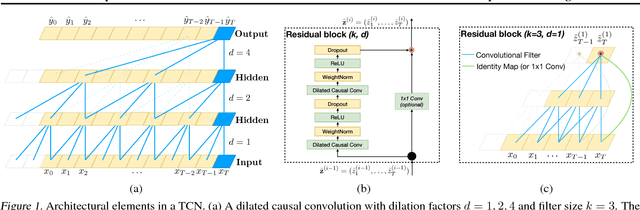
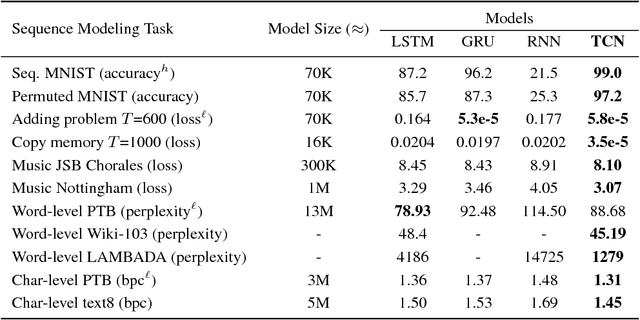
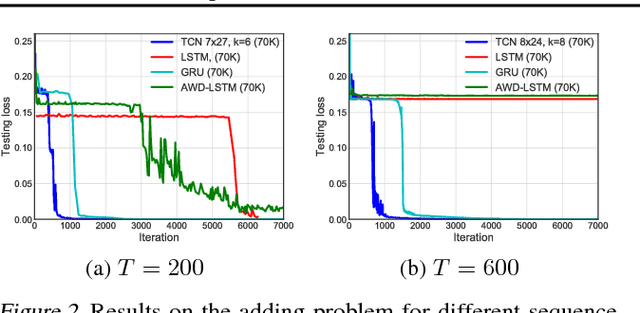
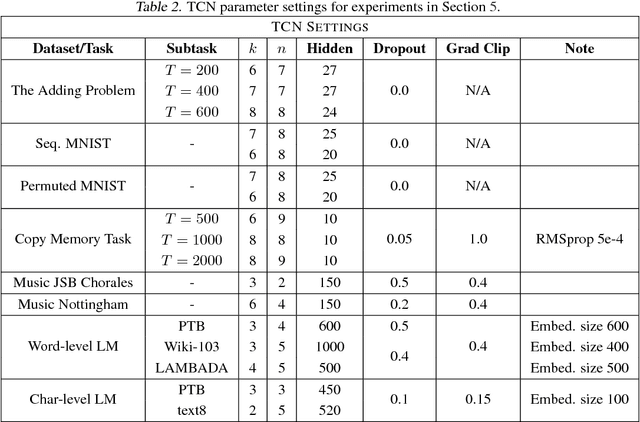
For most deep learning practitioners, sequence modeling is synonymous with recurrent networks. Yet recent results indicate that convolutional architectures can outperform recurrent networks on tasks such as audio synthesis and machine translation. Given a new sequence modeling task or dataset, which architecture should one use? We conduct a systematic evaluation of generic convolutional and recurrent architectures for sequence modeling. The models are evaluated across a broad range of standard tasks that are commonly used to benchmark recurrent networks. Our results indicate that a simple convolutional architecture outperforms canonical recurrent networks such as LSTMs across a diverse range of tasks and datasets, while demonstrating longer effective memory. We conclude that the common association between sequence modeling and recurrent networks should be reconsidered, and convolutional networks should be regarded as a natural starting point for sequence modeling tasks. To assist related work, we have made code available at http://github.com/locuslab/TCN .
Deep Continuous Clustering
Mar 05, 2018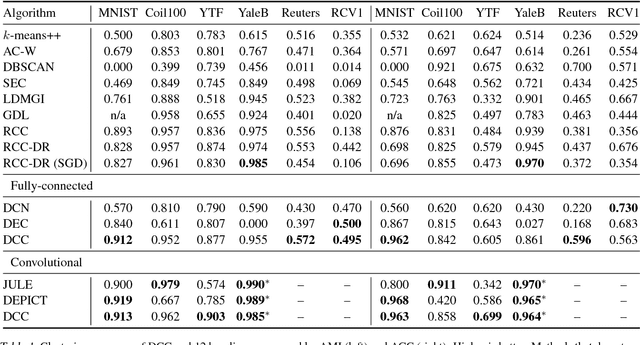

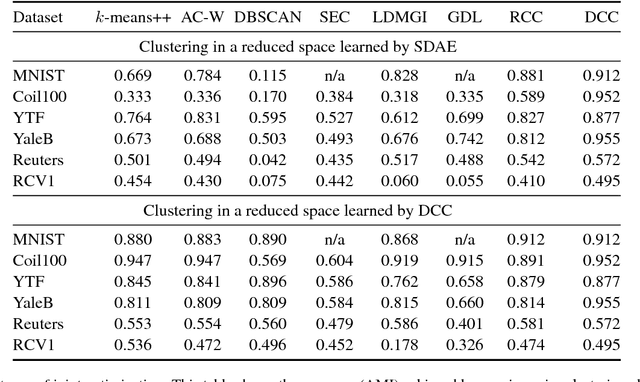
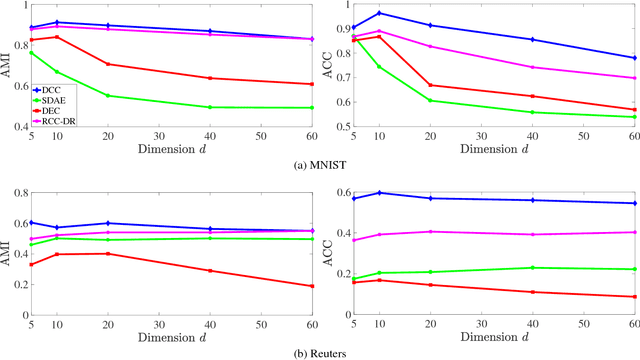
Clustering high-dimensional datasets is hard because interpoint distances become less informative in high-dimensional spaces. We present a clustering algorithm that performs nonlinear dimensionality reduction and clustering jointly. The data is embedded into a lower-dimensional space by a deep autoencoder. The autoencoder is optimized as part of the clustering process. The resulting network produces clustered data. The presented approach does not rely on prior knowledge of the number of ground-truth clusters. Joint nonlinear dimensionality reduction and clustering are formulated as optimization of a global continuous objective. We thus avoid discrete reconfigurations of the objective that characterize prior clustering algorithms. Experiments on datasets from multiple domains demonstrate that the presented algorithm outperforms state-of-the-art clustering schemes, including recent methods that use deep networks.
End-to-end Driving via Conditional Imitation Learning
Mar 02, 2018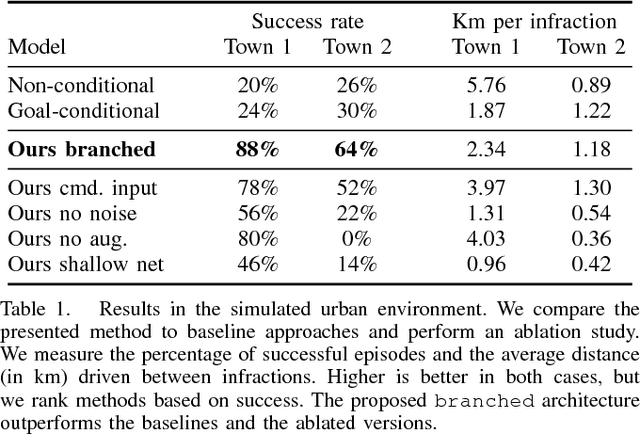
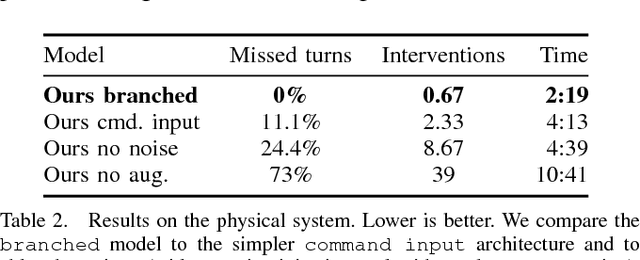
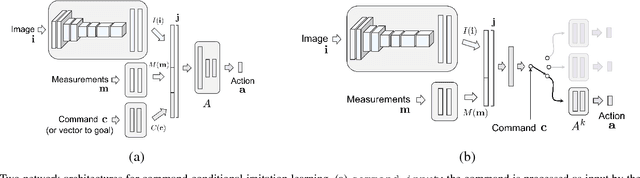
Deep networks trained on demonstrations of human driving have learned to follow roads and avoid obstacles. However, driving policies trained via imitation learning cannot be controlled at test time. A vehicle trained end-to-end to imitate an expert cannot be guided to take a specific turn at an upcoming intersection. This limits the utility of such systems. We propose to condition imitation learning on high-level command input. At test time, the learned driving policy functions as a chauffeur that handles sensorimotor coordination but continues to respond to navigational commands. We evaluate different architectures for conditional imitation learning in vision-based driving. We conduct experiments in realistic three-dimensional simulations of urban driving and on a 1/5 scale robotic truck that is trained to drive in a residential area. Both systems drive based on visual input yet remain responsive to high-level navigational commands. The supplementary video can be viewed at https://youtu.be/cFtnflNe5fM
Semi-parametric Topological Memory for Navigation
Mar 01, 2018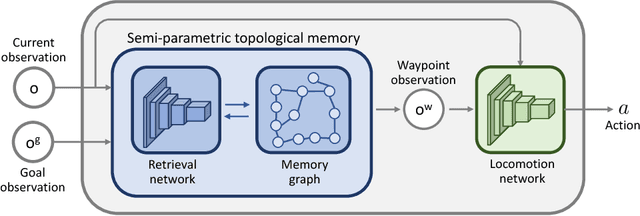

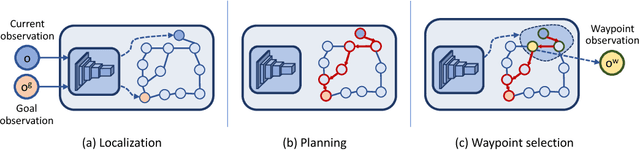

We introduce a new memory architecture for navigation in previously unseen environments, inspired by landmark-based navigation in animals. The proposed semi-parametric topological memory (SPTM) consists of a (non-parametric) graph with nodes corresponding to locations in the environment and a (parametric) deep network capable of retrieving nodes from the graph based on observations. The graph stores no metric information, only connectivity of locations corresponding to the nodes. We use SPTM as a planning module in a navigation system. Given only 5 minutes of footage of a previously unseen maze, an SPTM-based navigation agent can build a topological map of the environment and use it to confidently navigate towards goals. The average success rate of the SPTM agent in goal-directed navigation across test environments is higher than the best-performing baseline by a factor of three. A video of the agent is available at https://youtu.be/vRF7f4lhswo
Open3D: A Modern Library for 3D Data Processing
Jan 30, 2018
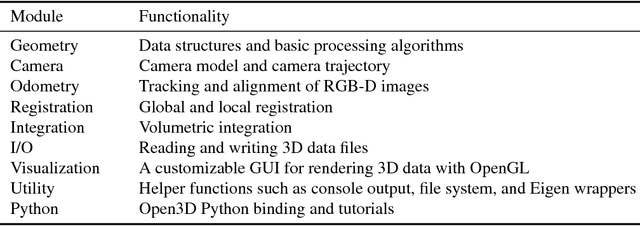
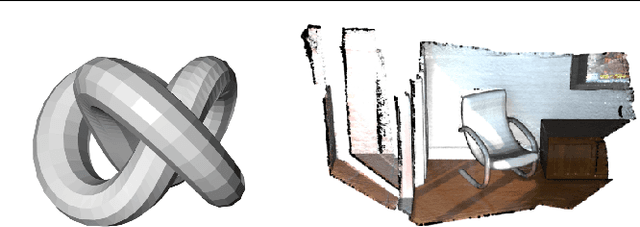
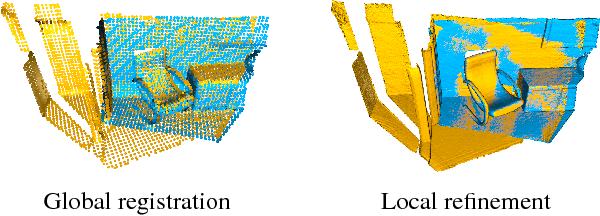
Open3D is an open-source library that supports rapid development of software that deals with 3D data. The Open3D frontend exposes a set of carefully selected data structures and algorithms in both C++ and Python. The backend is highly optimized and is set up for parallelization. Open3D was developed from a clean slate with a small and carefully considered set of dependencies. It can be set up on different platforms and compiled from source with minimal effort. The code is clean, consistently styled, and maintained via a clear code review mechanism. Open3D has been used in a number of published research projects and is actively deployed in the cloud. We welcome contributions from the open-source community.
MINOS: Multimodal Indoor Simulator for Navigation in Complex Environments
Dec 11, 2017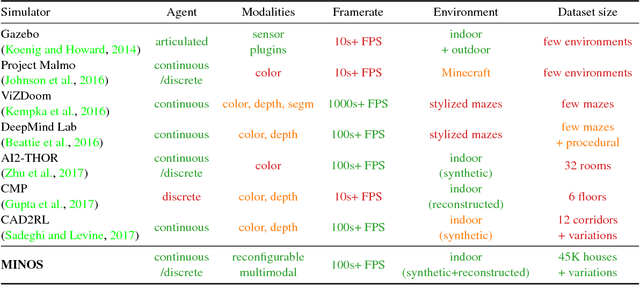
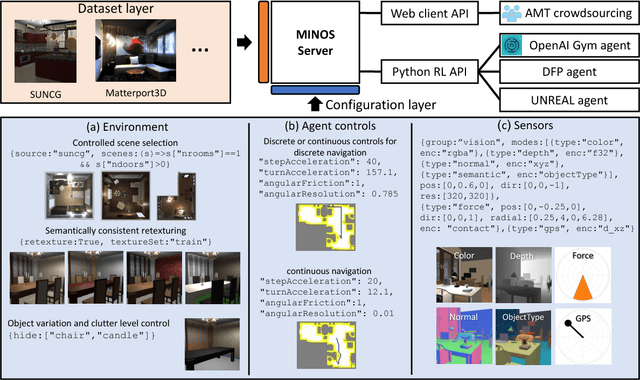

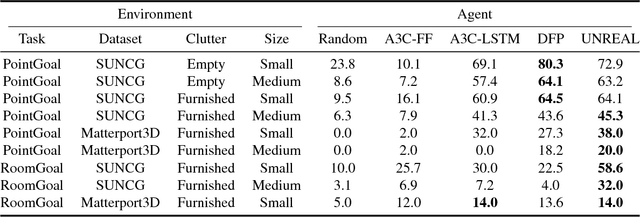
We present MINOS, a simulator designed to support the development of multisensory models for goal-directed navigation in complex indoor environments. The simulator leverages large datasets of complex 3D environments and supports flexible configuration of multimodal sensor suites. We use MINOS to benchmark deep-learning-based navigation methods, to analyze the influence of environmental complexity on navigation performance, and to carry out a controlled study of multimodality in sensorimotor learning. The experiments show that current deep reinforcement learning approaches fail in large realistic environments. The experiments also indicate that multimodality is beneficial in learning to navigate cluttered scenes. MINOS is released open-source to the research community at http://minosworld.org . A video that shows MINOS can be found at https://youtu.be/c0mL9K64q84
CARLA: An Open Urban Driving Simulator
Nov 10, 2017
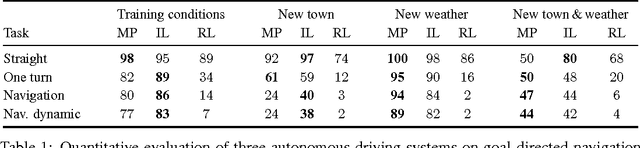

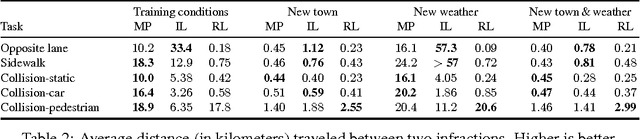
We introduce CARLA, an open-source simulator for autonomous driving research. CARLA has been developed from the ground up to support development, training, and validation of autonomous urban driving systems. In addition to open-source code and protocols, CARLA provides open digital assets (urban layouts, buildings, vehicles) that were created for this purpose and can be used freely. The simulation platform supports flexible specification of sensor suites and environmental conditions. We use CARLA to study the performance of three approaches to autonomous driving: a classic modular pipeline, an end-to-end model trained via imitation learning, and an end-to-end model trained via reinforcement learning. The approaches are evaluated in controlled scenarios of increasing difficulty, and their performance is examined via metrics provided by CARLA, illustrating the platform's utility for autonomous driving research. The supplementary video can be viewed at https://youtu.be/Hp8Dz-Zek2E
Learning to Inpaint for Image Compression
Nov 10, 2017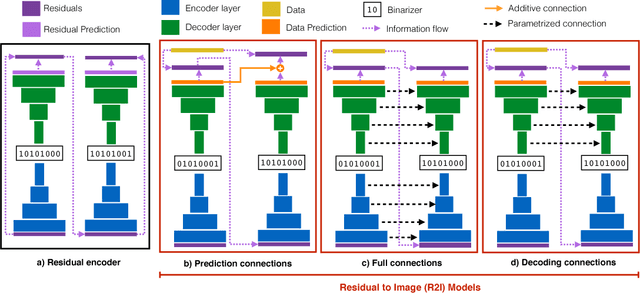

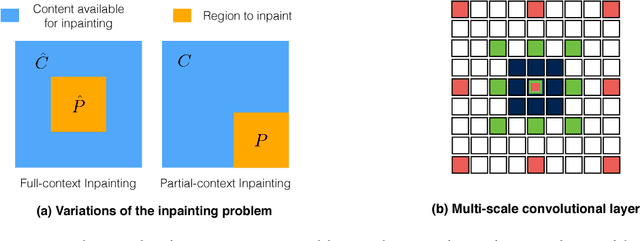
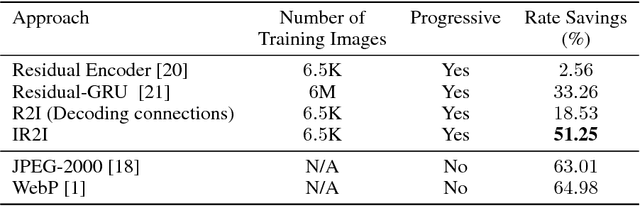
We study the design of deep architectures for lossy image compression. We present two architectural recipes in the context of multi-stage progressive encoders and empirically demonstrate their importance on compression performance. Specifically, we show that: (a) predicting the original image data from residuals in a multi-stage progressive architecture facilitates learning and leads to improved performance at approximating the original content and (b) learning to inpaint (from neighboring image pixels) before performing compression reduces the amount of information that must be stored to achieve a high-quality approximation. Incorporating these design choices in a baseline progressive encoder yields an average reduction of over $60\%$ in file size with similar quality compared to the original residual encoder.
Playing for Benchmarks
Sep 21, 2017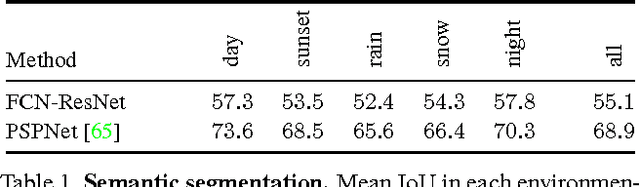
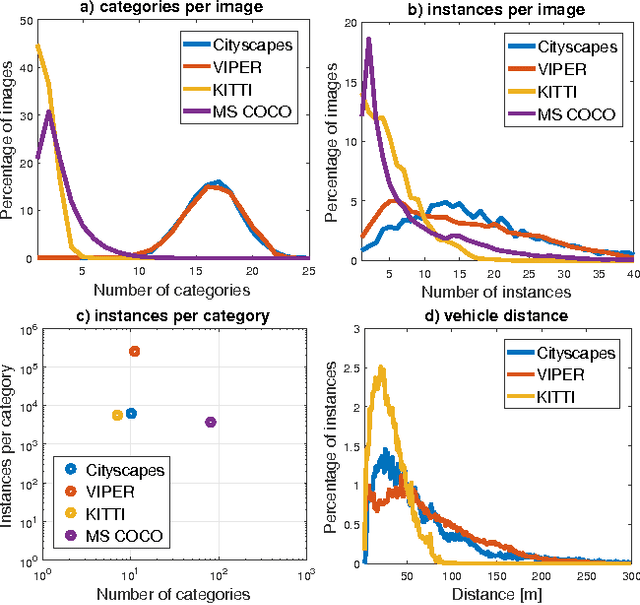
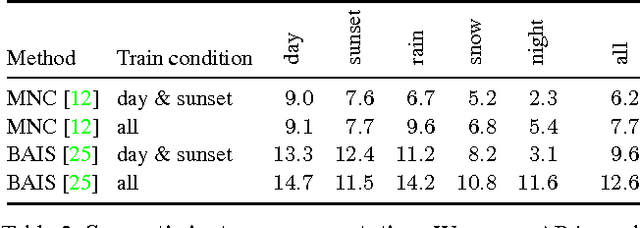
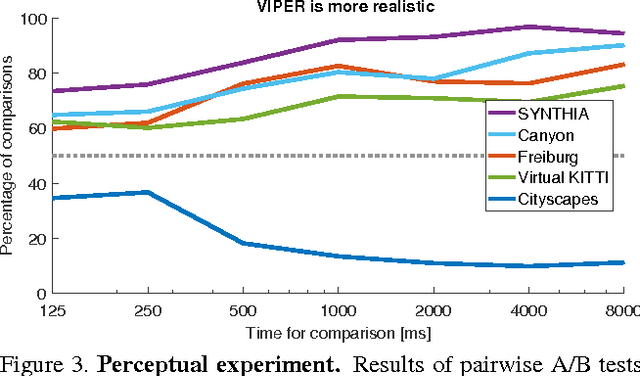
We present a benchmark suite for visual perception. The benchmark is based on more than 250K high-resolution video frames, all annotated with ground-truth data for both low-level and high-level vision tasks, including optical flow, semantic instance segmentation, object detection and tracking, object-level 3D scene layout, and visual odometry. Ground-truth data for all tasks is available for every frame. The data was collected while driving, riding, and walking a total of 184 kilometers in diverse ambient conditions in a realistic virtual world. To create the benchmark, we have developed a new approach to collecting ground-truth data from simulated worlds without access to their source code or content. We conduct statistical analyses that show that the composition of the scenes in the benchmark closely matches the composition of corresponding physical environments. The realism of the collected data is further validated via perceptual experiments. We analyze the performance of state-of-the-art methods for multiple tasks, providing reference baselines and highlighting challenges for future research. The supplementary video can be viewed at https://youtu.be/T9OybWv923Y
Learning Compact Geometric Features
Sep 15, 2017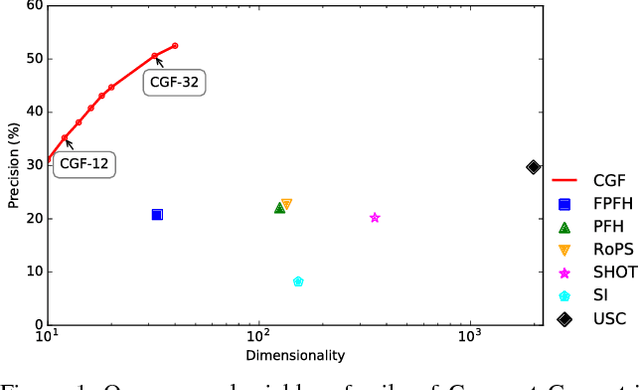

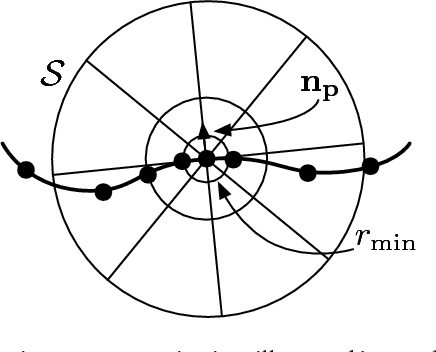
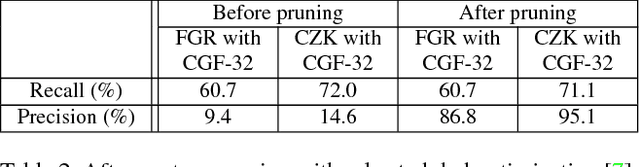
We present an approach to learning features that represent the local geometry around a point in an unstructured point cloud. Such features play a central role in geometric registration, which supports diverse applications in robotics and 3D vision. Current state-of-the-art local features for unstructured point clouds have been manually crafted and none combines the desirable properties of precision, compactness, and robustness. We show that features with these properties can be learned from data, by optimizing deep networks that map high-dimensional histograms into low-dimensional Euclidean spaces. The presented approach yields a family of features, parameterized by dimension, that are both more compact and more accurate than existing descriptors.