 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGRO: Adversarial Discovery of Error-prone groups for Robust Optimization
Dec 08, 2022Models trained via empirical risk minimization (ERM) are known to rely on spurious correlations between labels and task-independent input features, resulting in poor generalization to distributional shifts. Group distributionally robust optimization (G-DRO) can alleviate this problem by minimizing the worst-case loss over a set of pre-defined groups over training data. G-DRO successfully improves performance of the worst-group, where the correlation does not hold. However, G-DRO assumes that the spurious correlations and associated worst groups are known in advance, making it challenging to apply it to new tasks with potentially multiple unknown spurious correlations. We propose AGRO -- Adversarial Group discovery for Distributionally Robust Optimization -- an end-to-end approach that jointly identifies error-prone groups and improves accuracy on them. AGRO equips G-DRO with an adversarial slicing model to find a group assignment for training examples which maximizes worst-case loss over the discovered groups. On the WILDS benchmark, AGRO results in 8% higher model performance on average on known worst-groups, compared to prior group discovery approaches used with G-DRO. AGRO also improves out-of-distribution performance on SST2, QQP, and MS-COCO -- datasets where potential spurious correlations are as yet uncharacterized. Human evaluation of ARGO groups shows that they contain well-defined, yet previously unstudied spurious correlations that lead to model errors.
Elaboration-Generating Commonsense Question Answering at Scale
Sep 02, 2022
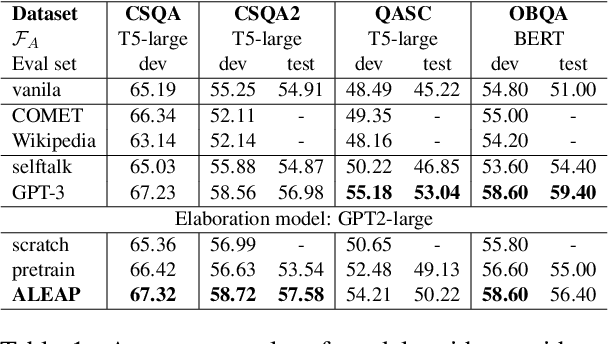
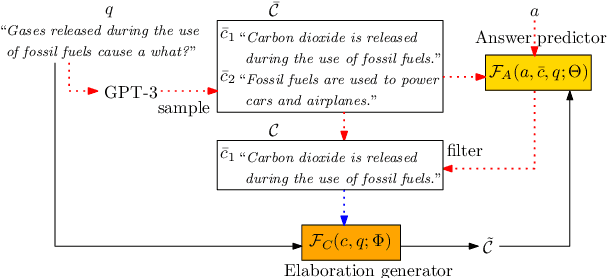

In question answering requiring common sense, language models (e.g., GPT-3) have been used to generate text expressing background knowledge that helps improve performance. Yet the cost of working with such models is very high; in this work, we finetune smaller language models to generate useful intermediate context, referred to here as elaborations. Our framework alternates between updating two language models -- an elaboration generator and an answer predictor -- allowing each to influence the other. Using less than 0.5% of the parameters of GPT-3, our model outperforms alternatives with similar sizes and closes the gap on GPT-3 on four commonsense question answering benchmarks. Human evaluations show that the quality of the generated elaborations is high.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Putting Words in BERT's Mouth: Navigating Contextualized Vector Spaces with Pseudowords
Oct 04, 2021



We present a method for exploring regions around individual points in a contextualized vector space (particularly, BERT space), as a way to investigate how these regions correspond to word senses. By inducing a contextualized "pseudoword" as a stand-in for a static embedding in the input layer, and then performing masked prediction of a word in the sentence, we are able to investigate the geometry of the BERT-space in a controlled manner around individual instances. Using our method on a set of carefully constructed sentences targeting ambiguous English words, we find substantial regularity in the contextualized space, with regions that correspond to distinct word senses; but between these regions there are occasionally "sense voids" -- regions that do not correspond to any intelligible sense.
REFLACX, a dataset of reports and eye-tracking data for localization of abnormalities in chest x-rays
Sep 29, 2021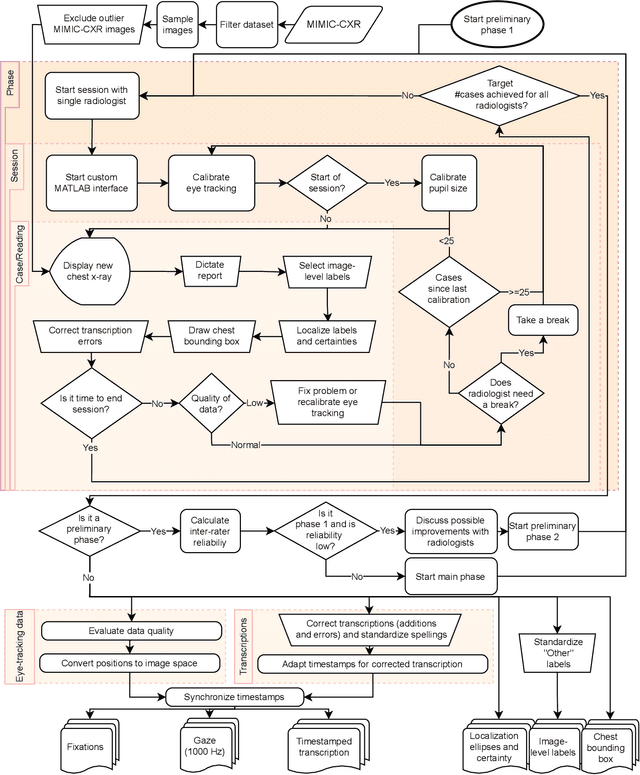
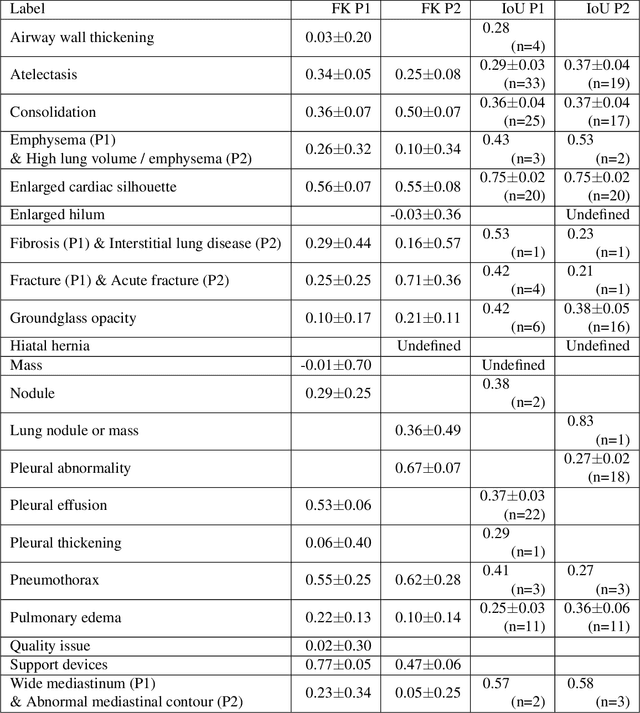
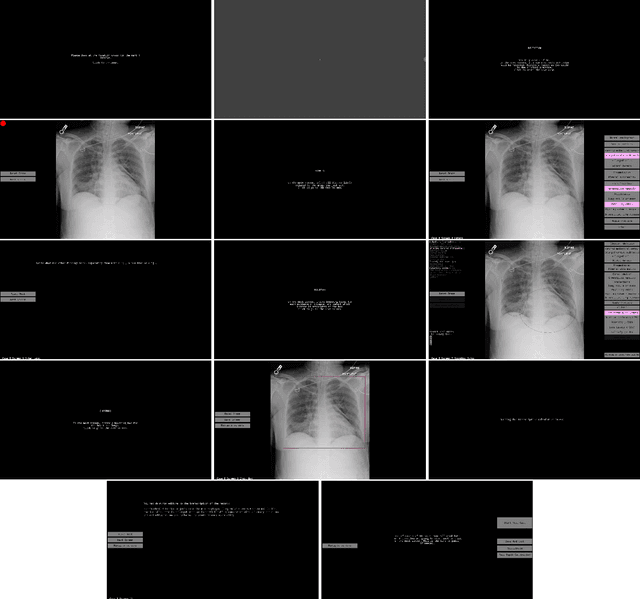
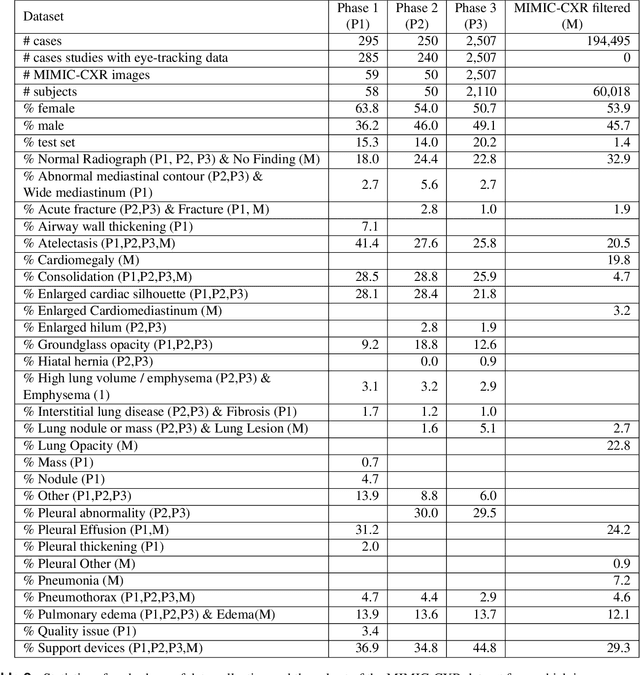
Deep learning has shown recent success in classifying anomalies in chest x-rays, but datasets are still small compared to natural image datasets. Supervision of abnormality localization has been shown to improve trained models, partially compensating for dataset sizes. However, explicitly labeling these anomalies requires an expert and is very time-consuming. We propose a method for collecting implicit localization data using an eye tracker to capture gaze locations and a microphone to capture a dictation of a report, imitating the setup of a reading room, and potentially scalable for large datasets. The resulting REFLACX (Reports and Eye-Tracking Data for Localization of Abnormalities in Chest X-rays) dataset was labeled by five radiologists and contains 3,032 synchronized sets of eye-tracking data and timestamped report transcriptions. We also provide bounding boxes around lungs and heart and validation labels consisting of ellipses localizing abnormalities and image-level labels. Furthermore, a small subset of the data contains readings from all radiologists, allowing for the calculation of inter-rater scores.
Is My Model Using The Right Evidence? Systematic Probes for Examining Evidence-Based Tabular Reasoning
Aug 02, 2021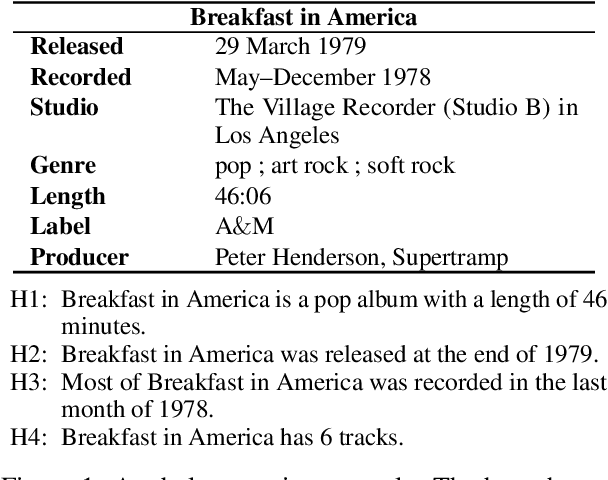
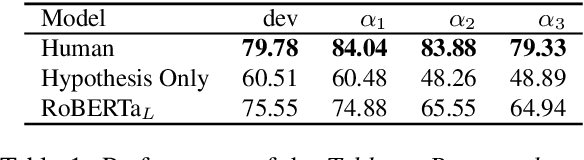
While neural models routinely report state-of-the-art performance across NLP tasks involving reasoning, their outputs are often observed to not properly use and reason on the evidence presented to them in the inputs. A model that reasons properly is expected to attend to the right parts of the input, be self-consistent in its predictions across examples, avoid spurious patterns in inputs, and to ignore biasing from its underlying pre-trained language model in a nuanced, context-sensitive fashion (e.g. handling counterfactuals). Do today's models do so? In this paper, we study this question using the problem of reasoning on tabular data. The tabular nature of the input is particularly suited for the study as it admits systematic probes targeting the properties listed above. Our experiments demonstrate that a BERT-based model representative of today's state-of-the-art fails to properly reason on the following counts: it often (a) misses the relevant evidence, (b) suffers from hypothesis and knowledge biases, and, (c) relies on annotation artifacts and knowledge from pre-trained language models as primary evidence rather than relying on reasoning on the premises in the tabular input.
Evaluating Relaxations of Logic for Neural Networks: A Comprehensive Study
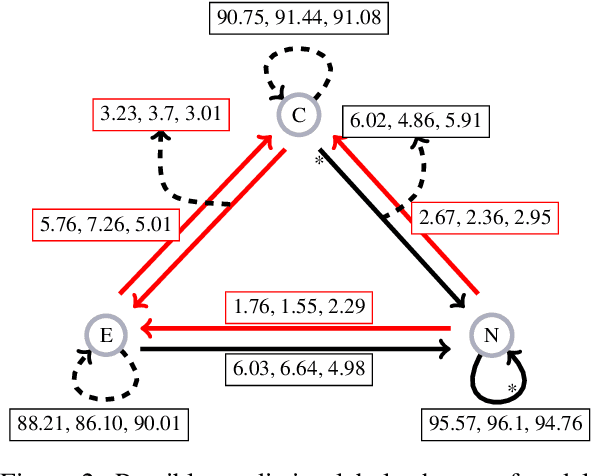
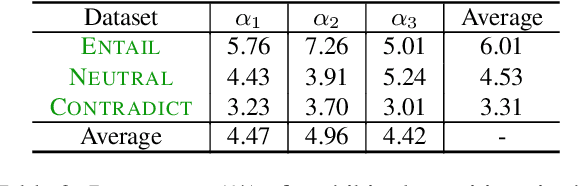
Jul 28, 2021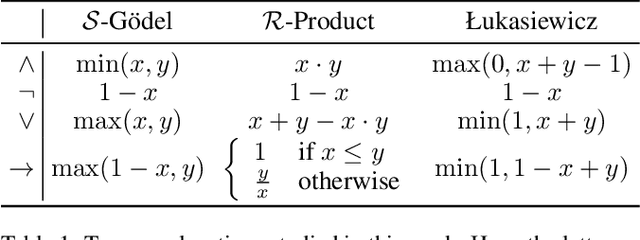
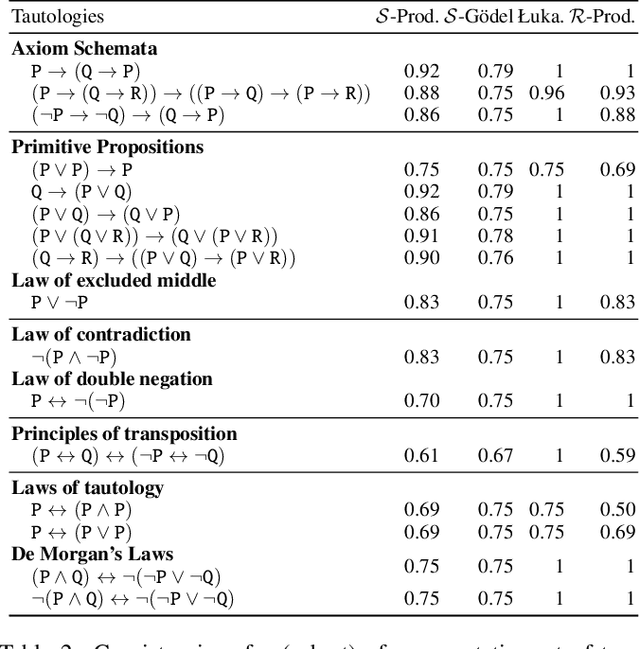

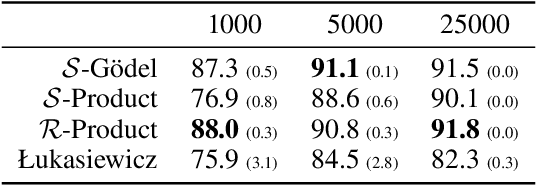
Symbolic knowledge can provide crucial inductive bias for training neural models, especially in low data regimes. A successful strategy for incorporating such knowledge involves relaxing logical statements into sub-differentiable losses for optimization. In this paper, we study the question of how best to relax logical expressions that represent labeled examples and knowledge about a problem; we focus on sub-differentiable t-norm relaxations of logic. We present theoretical and empirical criteria for characterizing which relaxation would perform best in various scenarios. In our theoretical study driven by the goal of preserving tautologies, the Lukasiewicz t-norm performs best. However, in our empirical analysis on the text chunking and digit recognition tasks, the product t-norm achieves best predictive performance. We analyze this apparent discrepancy, and conclude with a list of best practices for defining loss functions via logic.
A Closer Look at How Fine-tuning Changes BERT
Jun 27, 2021
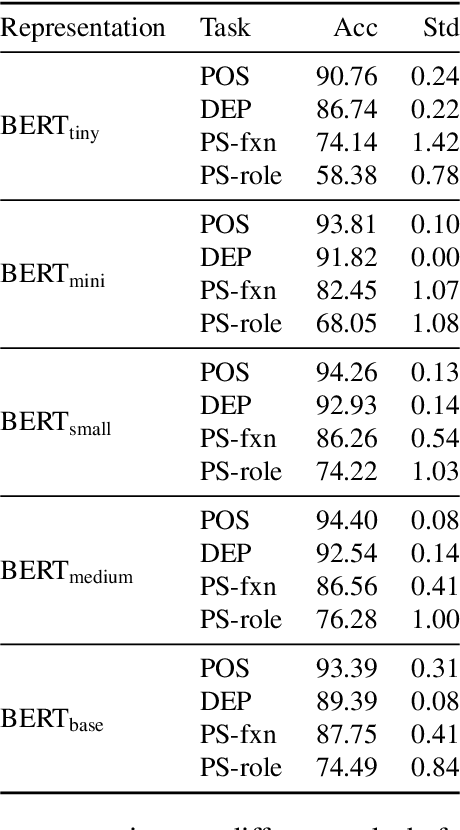
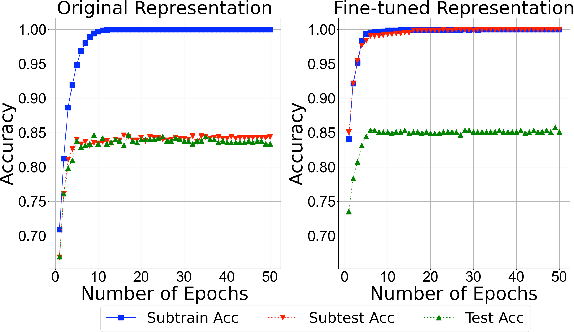
Given the prevalence of pre-trained contextualized representations in today's NLP, there have been several efforts to understand what information such representations contain. A common strategy to use such representations is to fine-tune them for an end task. However, how fine-tuning for a task changes the underlying space is less studied. In this work, we study the English BERT family and use two probing techniques to analyze how fine-tuning changes the space. Our experiments reveal that fine-tuning improves performance because it pushes points associated with a label away from other labels. By comparing the representations before and after fine-tuning, we also discover that fine-tuning does not change the representations arbitrarily; instead, it adjusts the representations to downstream tasks while preserving the original structure. Finally, using carefully constructed experiments, we show that fine-tuning can encode training sets in a representation, suggesting an overfitting problem of a new kind.
X-FACT: A New Benchmark Dataset for Multilingual Fact Checking
Jun 17, 2021
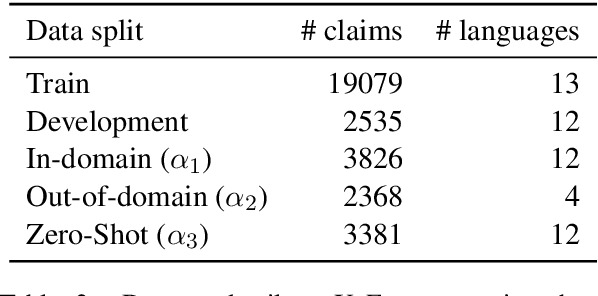
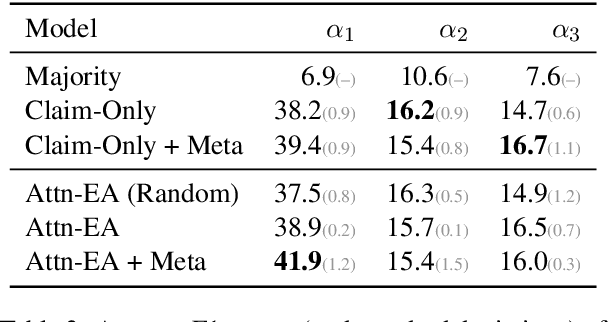
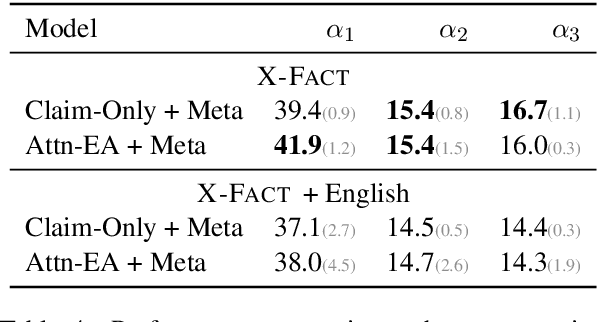
In this work, we introduce X-FACT: the largest publicly available multilingual dataset for factual verification of naturally existing real-world claims. The dataset contains short statements in 25 languages and is labeled for veracity by expert fact-checkers. The dataset includes a multilingual evaluation benchmark that measures both out-of-domain generalization, and zero-shot capabilities of the multilingual models. Using state-of-the-art multilingual transformer-based models, we develop several automated fact-checking models that, along with textual claims, make use of additional metadata and evidence from news stories retrieved using a search engine. Empirically, our best model attains an F-score of around 40%, suggesting that our dataset is a challenging benchmark for evaluation of multilingual fact-checking models.
Database Workload Characterization with Query Plan Encoders
May 26, 2021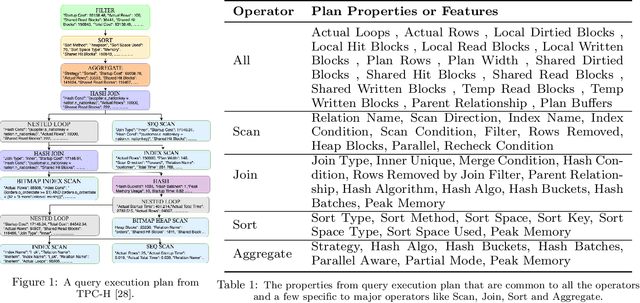
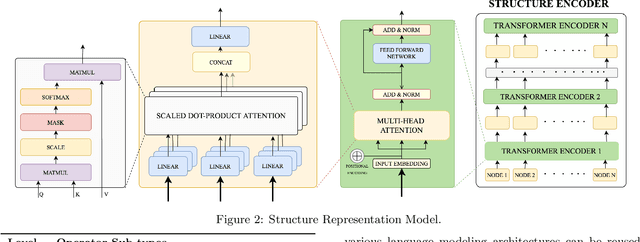

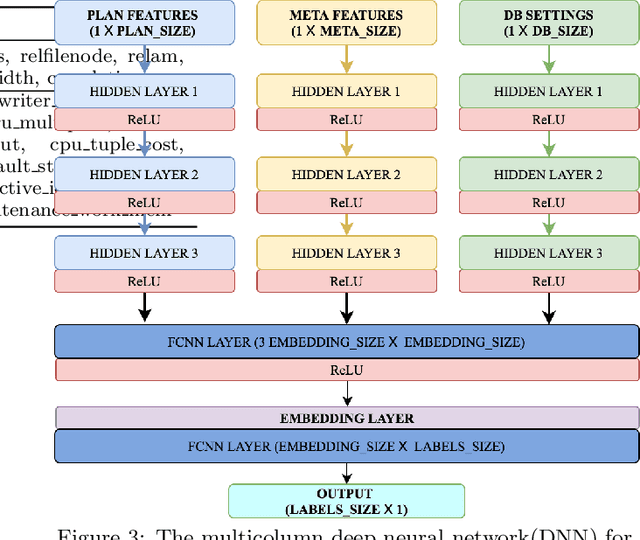
Smart databases are adopting artificial intelligence (AI) technologies to achieve {\em instance optimality}, and in the future, databases will come with prepackaged AI models within their core components. The reason is that every database runs on different workloads, demands specific resources, and settings to achieve optimal performance. It prompts the necessity to understand workloads running in the system along with their features comprehensively, which we dub as workload characterization. To address this workload characterization problem, we propose our query plan encoders that learn essential features and their correlations from query plans. Our pretrained encoders capture the {\em structural} and the {\em computational performance} of queries independently. We show that our pretrained encoders are adaptable to workloads that expedite the transfer learning process. We performed independent assessments of structural encoder and performance encoders with multiple downstream tasks. For the overall evaluation of our query plan encoders, we architect two downstream tasks (i) query latency prediction and (ii) query classification. These tasks show the importance of feature-based workload characterization. We also performed extensive experiments on individual encoders to verify the effectiveness of representation learning and domain adaptability.