 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Thousand Tasks in a Day
Nov 13, 2025Humans are remarkably efficient at learning tasks from demonstrations, but today's imitation learning methods for robot manipulation often require hundreds or thousands of demonstrations per task. We investigate two fundamental priors for improving learning efficiency: decomposing manipulation trajectories into sequential alignment and interaction phases, and retrieval-based generalisation. Through 3,450 real-world rollouts, we systematically study this decomposition. We compare different design choices for the alignment and interaction phases, and examine generalisation and scaling trends relative to today's dominant paradigm of behavioural cloning with a single-phase monolithic policy. In the few-demonstrations-per-task regime (<10 demonstrations), decomposition achieves an order of magnitude improvement in data efficiency over single-phase learning, with retrieval consistently outperforming behavioural cloning for both alignment and interaction. Building on these insights, we develop Multi-Task Trajectory Transfer (MT3), an imitation learning method based on decomposition and retrieval. MT3 learns everyday manipulation tasks from as little as a single demonstration each, whilst also generalising to novel object instances. This efficiency enables us to teach a robot 1,000 distinct everyday tasks in under 24 hours of human demonstrator time. Through 2,200 additional real-world rollouts, we reveal MT3's capabilities and limitations across different task families. Videos of our experiments can be found on at https://www.robot-learning.uk/learning-1000-tasks.
* This is the author's version of the work. It is posted here by permission of the AAAS for personal use, not for redistribution. The definitive version was published in Science Robotics on 12 November 2025, DOI: https://www.science.org/doi/10.1126/scirobotics.adv7594. Link to project website: https://www.robot-learning.uk/learning-1000-tasks
Instant Policy: In-Context Imitation Learning via Graph Diffusion
Nov 19, 2024



Following the impressive capabilities of in-context learning with large transformers, In-Context Imitation Learning (ICIL) is a promising opportunity for robotics. We introduce Instant Policy, which learns new tasks instantly (without further training) from just one or two demonstrations, achieving ICIL through two key components. First, we introduce inductive biases through a graph representation and model ICIL as a graph generation problem with a learned diffusion process, enabling structured reasoning over demonstrations, observations, and actions. Second, we show that such a model can be trained using pseudo-demonstrations - arbitrary trajectories generated in simulation - as a virtually infinite pool of training data. Simulated and real experiments show that Instant Policy enables rapid learning of various everyday robot tasks. We also show how it can serve as a foundation for cross-embodiment and zero-shot transfer to language-defined tasks. Code and videos are available at https://www.robot-learning.uk/instant-policy.
Adapting Skills to Novel Grasps: A Self-Supervised Approach
Jul 31, 2024



In this paper, we study the problem of adapting manipulation trajectories involving grasped objects (e.g. tools) defined for a single grasp pose to novel grasp poses. A common approach to address this is to define a new trajectory for each possible grasp explicitly, but this is highly inefficient. Instead, we propose a method to adapt such trajectories directly while only requiring a period of self-supervised data collection, during which a camera observes the robot's end-effector moving with the object rigidly grasped. Importantly, our method requires no prior knowledge of the grasped object (such as a 3D CAD model), it can work with RGB images, depth images, or both, and it requires no camera calibration. Through a series of real-world experiments involving 1360 evaluations, we find that self-supervised RGB data consistently outperforms alternatives that rely on depth images including several state-of-the-art pose estimation methods. Compared to the best-performing baseline, our method results in an average of 28.5% higher success rate when adapting manipulation trajectories to novel grasps on several everyday tasks. Videos of the experiments are available on our webpage at https://www.robot-learning.uk/adapting-skills
Render and Diffuse: Aligning Image and Action Spaces for Diffusion-based Behaviour Cloning
May 28, 2024In the field of Robot Learning, the complex mapping between high-dimensional observations such as RGB images and low-level robotic actions, two inherently very different spaces, constitutes a complex learning problem, especially with limited amounts of data. In this work, we introduce Render and Diffuse (R&D) a method that unifies low-level robot actions and RGB observations within the image space using virtual renders of the 3D model of the robot. Using this joint observation-action representation it computes low-level robot actions using a learnt diffusion process that iteratively updates the virtual renders of the robot. This space unification simplifies the learning problem and introduces inductive biases that are crucial for sample efficiency and spatial generalisation. We thoroughly evaluate several variants of R&D in simulation and showcase their applicability on six everyday tasks in the real world. Our results show that R&D exhibits strong spatial generalisation capabilities and is more sample efficient than more common image-to-action methods.
Few-Shot In-Context Imitation Learning via Implicit Graph Alignment
Oct 18, 2023Consider the following problem: given a few demonstrations of a task across a few different objects, how can a robot learn to perform that same task on new, previously unseen objects? This is challenging because the large variety of objects within a class makes it difficult to infer the task-relevant relationship between the new objects and the objects in the demonstrations. We address this by formulating imitation learning as a conditional alignment problem between graph representations of objects. Consequently, we show that this conditioning allows for in-context learning, where a robot can perform a task on a set of new objects immediately after the demonstrations, without any prior knowledge about the object class or any further training. In our experiments, we explore and validate our design choices, and we show that our method is highly effective for few-shot learning of several real-world, everyday tasks, whilst outperforming baselines. Videos are available on our project webpage at https://www.robot-learning.uk/implicit-graph-alignment.
Where To Start? Transferring Simple Skills to Complex Environments
Dec 12, 2022Robot learning provides a number of ways to teach robots simple skills, such as grasping. However, these skills are usually trained in open, clutter-free environments, and therefore would likely cause undesirable collisions in more complex, cluttered environments. In this work, we introduce an affordance model based on a graph representation of an environment, which is optimised during deployment to find suitable robot configurations to start a skill from, such that the skill can be executed without any collisions. We demonstrate that our method can generalise a priori acquired skills to previously unseen cluttered and constrained environments, in simulation and in the real world, for both a grasping and a placing task.
DALL-E-Bot: Introducing Web-Scale Diffusion Models to Robotics
Oct 05, 2022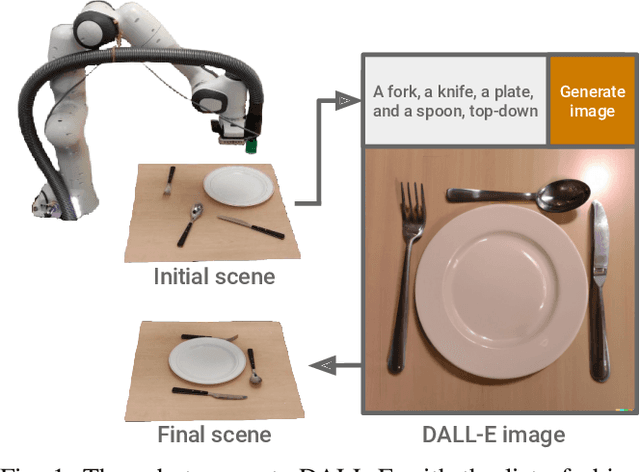
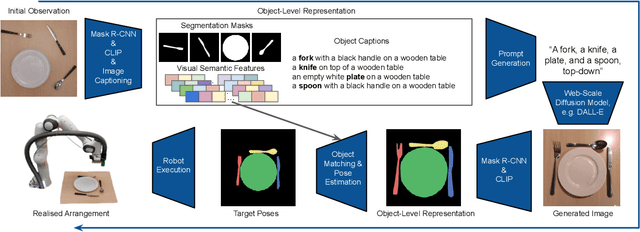

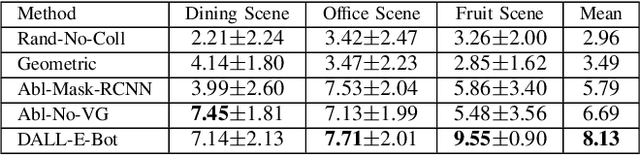
We introduce the first work to explore web-scale diffusion models for robotics. DALL-E-Bot enables a robot to rearrange objects in a scene, by first inferring a text description of those objects, then generating an image representing a natural, human-like arrangement of those objects, and finally physically arranging the objects according to that image. The significance is that we achieve this zero-shot using DALL-E, without needing any further data collection or training. Encouraging real-world results with human studies show that this is an exciting direction for the future of web-scale robot learning algorithms. We also propose a list of recommendations to the text-to-image community, to align further developments of these models with applications to robotics. Videos are available at: https://www.robot-learning.uk/dall-e-bot
Geometric Deep Learning for Post-Menstrual Age Prediction based on the Neonatal White Matter Cortical Surface
Aug 13, 2020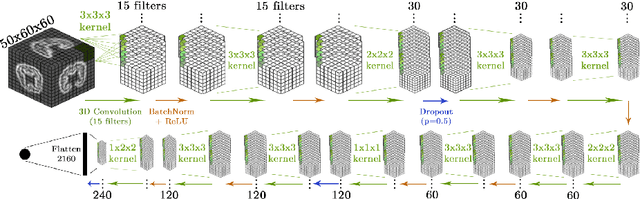
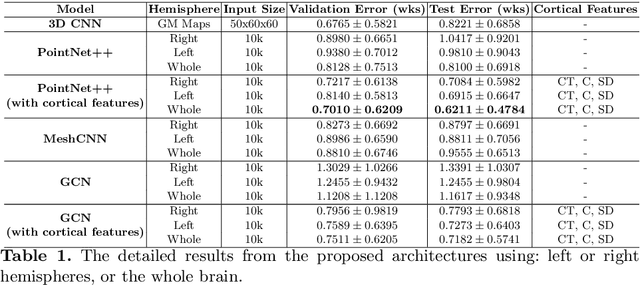

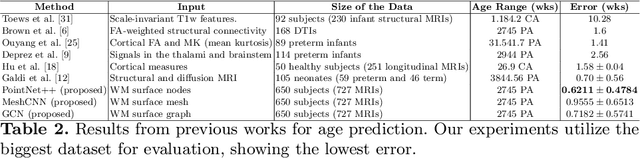
Accurate estimation of the age in neonates is essential for measuring neurodevelopmental, medical, and growth outcomes. In this paper, we propose a novel approach to predict the post-menstrual age (PA) at scan, using techniques from geometric deep learning, based on the neonatal white matter cortical surface. We utilize and compare multiple specialized neural network architectures that predict the age using different geometric representations of the cortical surface; we compare MeshCNN, Pointnet++, GraphCNN, and a volumetric benchmark. The dataset is part of the Developing Human Connectome Project (dHCP), and is a cohort of healthy and premature neonates. We evaluate our approach on 650 subjects (727scans) with PA ranging from 27 to 45 weeks. Our results show accurate prediction of the estimated PA, with mean error less than one week.