 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyTask: an Automated Task and Data Generation Framework for Advancing Sim-to-Real Policy Learning
Dec 19, 2025Generalist robot learning remains constrained by data: large-scale, diverse, and high-quality interaction data are expensive to collect in the real world. While simulation has become a promising way for scaling up data collection, the related tasks, including simulation task design, task-aware scene generation, expert demonstration synthesis, and sim-to-real transfer, still demand substantial human effort. We present AnyTask, an automated framework that pairs massively parallel GPU simulation with foundation models to design diverse manipulation tasks and synthesize robot data. We introduce three AnyTask agents for generating expert demonstrations aiming to solve as many tasks as possible: 1) ViPR, a novel task and motion planning agent with VLM-in-the-loop Parallel Refinement; 2) ViPR-Eureka, a reinforcement learning agent with generated dense rewards and LLM-guided contact sampling; 3) ViPR-RL, a hybrid planning and learning approach that jointly produces high-quality demonstrations with only sparse rewards. We train behavior cloning policies on generated data, validate them in simulation, and deploy them directly on real robot hardware. The policies generalize to novel object poses, achieving 44% average success across a suite of real-world pick-and-place, drawer opening, contact-rich pushing, and long-horizon manipulation tasks. Our project website is at https://anytask.rai-inst.com .
Dream2Real: Zero-Shot 3D Object Rearrangement with Vision-Language Models
Dec 07, 2023



We introduce Dream2Real, a robotics framework which integrates vision-language models (VLMs) trained on 2D data into a 3D object rearrangement pipeline. This is achieved by the robot autonomously constructing a 3D representation of the scene, where objects can be rearranged virtually and an image of the resulting arrangement rendered. These renders are evaluated by a VLM, so that the arrangement which best satisfies the user instruction is selected and recreated in the real world with pick-and-place. This enables language-conditioned rearrangement to be performed zero-shot, without needing to collect a training dataset of example arrangements. Results on a series of real-world tasks show that this framework is robust to distractors, controllable by language, capable of understanding complex multi-object relations, and readily applicable to both tabletop and 6-DoF rearrangement tasks.
SceneScore: Learning a Cost Function for Object Arrangement
Nov 14, 2023Arranging objects correctly is a key capability for robots which unlocks a wide range of useful tasks. A prerequisite for creating successful arrangements is the ability to evaluate the desirability of a given arrangement. Our method "SceneScore" learns a cost function for arrangements, such that desirable, human-like arrangements have a low cost. We learn the distribution of training arrangements offline using an energy-based model, solely from example images without requiring environment interaction or human supervision. Our model is represented by a graph neural network which learns object-object relations, using graphs constructed from images. Experiments demonstrate that the learned cost function can be used to predict poses for missing objects, generalise to novel objects using semantic features, and can be composed with other cost functions to satisfy constraints at inference time.
DALL-E-Bot: Introducing Web-Scale Diffusion Models to Robotics
Oct 05, 2022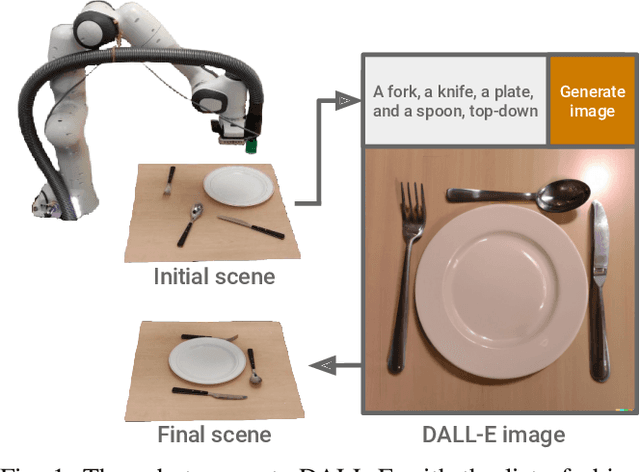
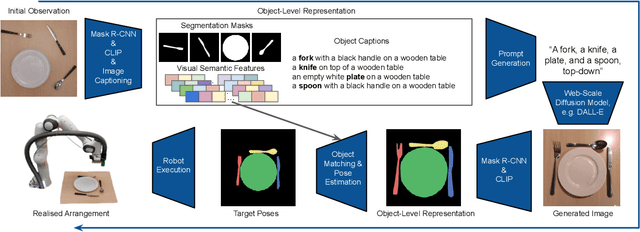

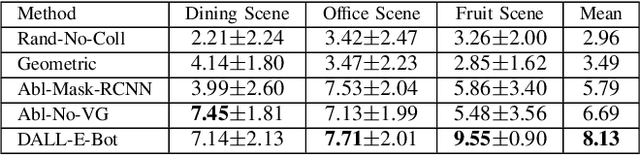
We introduce the first work to explore web-scale diffusion models for robotics. DALL-E-Bot enables a robot to rearrange objects in a scene, by first inferring a text description of those objects, then generating an image representing a natural, human-like arrangement of those objects, and finally physically arranging the objects according to that image. The significance is that we achieve this zero-shot using DALL-E, without needing any further data collection or training. Encouraging real-world results with human studies show that this is an exciting direction for the future of web-scale robot learning algorithms. We also propose a list of recommendations to the text-to-image community, to align further developments of these models with applications to robotics. Videos are available at: https://www.robot-learning.uk/dall-e-bot
My House, My Rules: Learning Tidying Preferences with Graph Neural Networks
Nov 04, 2021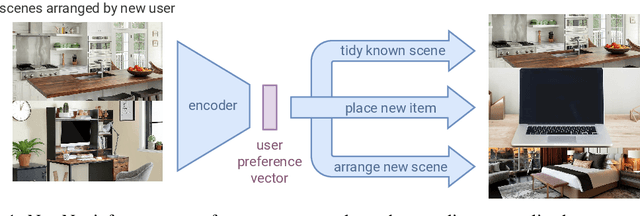
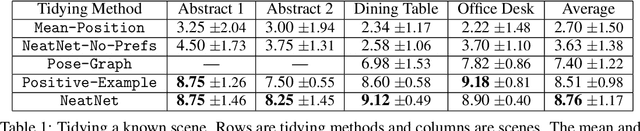
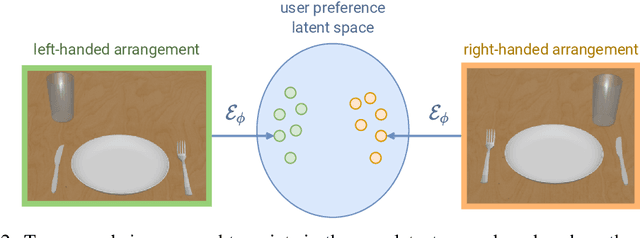

Robots that arrange household objects should do so according to the user's preferences, which are inherently subjective and difficult to model. We present NeatNet: a novel Variational Autoencoder architecture using Graph Neural Network layers, which can extract a low-dimensional latent preference vector from a user by observing how they arrange scenes. Given any set of objects, this vector can then be used to generate an arrangement which is tailored to that user's spatial preferences, with word embeddings used for generalisation to new objects. We develop a tidying simulator to gather rearrangement examples from 75 users, and demonstrate empirically that our method consistently produces neat and personalised arrangements across a variety of rearrangement scenarios.